Bonnes pratiques et reproductibilité#
Ce dernier chapitre prend du recul sur l’ensemble du livre pour aborder les questions qui conditionnent la valeur réelle d’une analyse statistique : est-ce que je teste ce que je crois tester ? Mon résultat sera-t-il reproductible ? Mes conclusions sont-elles solides ou fragiles ? La statistique moderne traverse une crise profonde — la crise de la réplication — dont les causes sont largement liées à de mauvaises pratiques que ce chapitre cherche à identifier et corriger.
La crise de la réplication#
Des exemples marquants#
Psychologie sociale (2011-2015). L’étude de « priming » de Bargh et al. (1996), qui prétendait que lire des mots liés à la vieillesse ralentissait la marche, a échoué à se reproduire à grande échelle. Le projet Reproducibility Project (OSC, 2015) a tenté de reproduire 100 expériences de psychologie publiées : seulement 39% des effets ont été répliqués avec un résultat significatif.
Médecine. Ioannidis (2005) dans le célèbre article « Why Most Published Research Findings Are False » démontre que dans de nombreux domaines biomédicaux, avec des puissances typiques de 20-40%, des biais de publication et des comparaisons multiples, la majorité des p-valeurs significatives publiées sont des faux positifs.
Économie. Camerer et al. (2016) ont tenté de reproduire 18 expériences en économie publiées dans Science et Nature : 61% se sont répliquées.
Les causes structurelles#
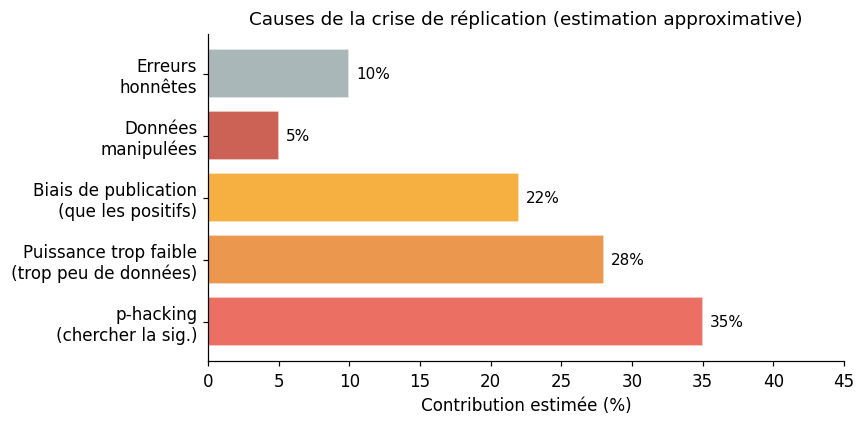
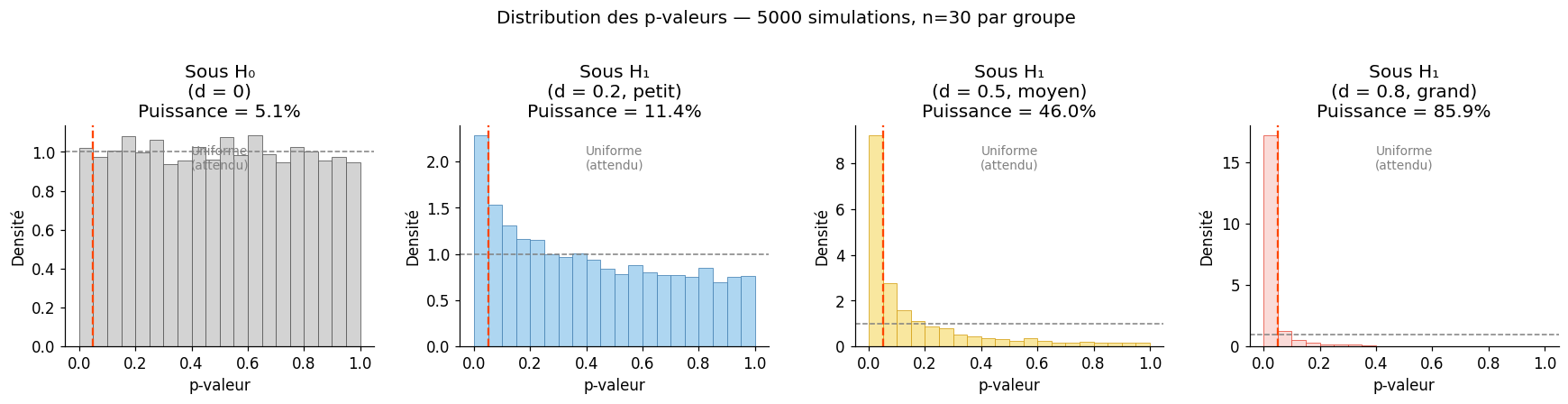
La p-valeur : ce qu’elle est, ce qu’elle n’est pas#
Définition correcte#
La p-valeur est la probabilité d’observer une statistique de test aussi ou plus extrême que celle obtenue, si H₀ est vraie :
Ce que la p-valeur N’EST PAS#
Mythes courants sur la p-valeur
FAUX : « p < 0.05 signifie que mon résultat est vrai avec 95% de probabilité »
FAUX : « p = 0.04 est plus important que p = 0.06 »
FAUX : « p > 0.05 prouve que l’effet est nul »
FAUX : « La p-valeur mesure la taille de l’effet »
FAUX : « p < 0.05 signifie que le résultat est important pratiquement »
VRAI : La p-valeur mesure la compatibilité des données avec H₀. Une p-valeur faible dit « ces données seraient rares sous H₀ », rien de plus.
L’ASA Statement de 2016#
L’American Statistical Association a publié en 2016 un communiqué officiel listant six principes sur les p-valeurs :
Les p-valeurs peuvent indiquer l’incompatibilité des données avec un modèle statistique spécifié
Les p-valeurs ne mesurent pas la probabilité que H₀ soit vraie, ni la probabilité que les résultats soient dus au hasard
Les conclusions scientifiques et décisions ne devraient pas être basées uniquement sur le franchissement d’un seuil de p-valeur
L’inférence correcte requiert un reporting complet et transparent
Une p-valeur n’est pas une mesure de la taille de l’effet ou de l’importance d’un résultat
En elle-même, une p-valeur ne mesure pas l’évidence pour un modèle ou une hypothèse
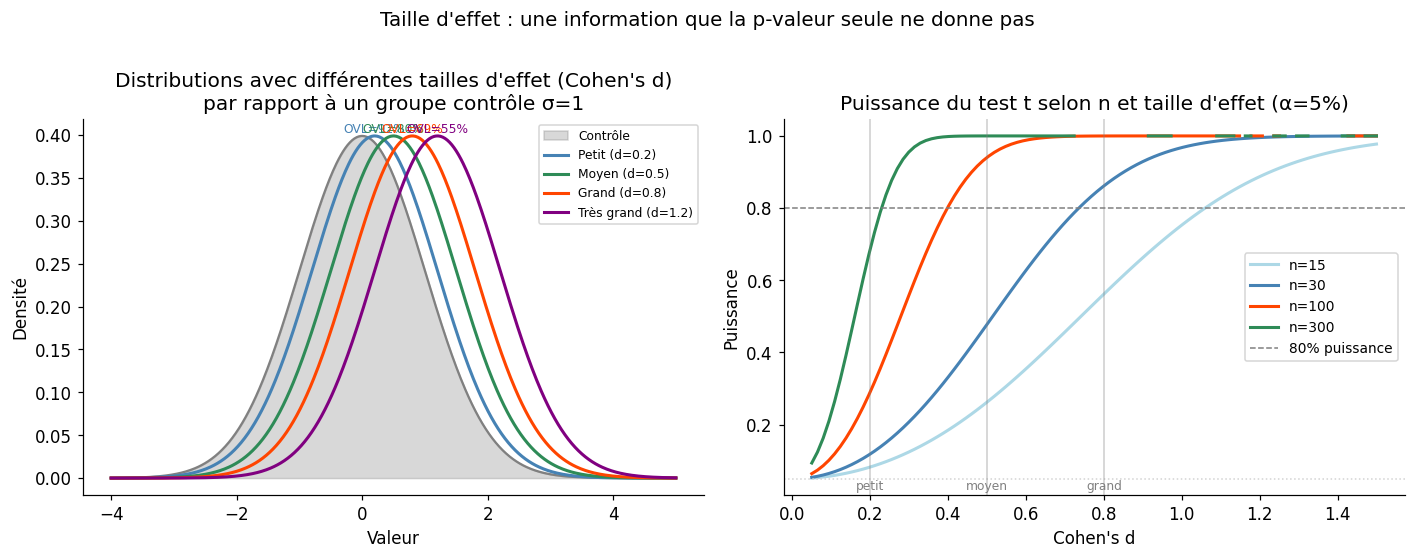
Taille d’effet : pourquoi c’est plus informatif#
Les mesures de taille d’effet#
Cohen’s d (deux groupes, variable continue) : $\(d = \frac{\mu_1 - \mu_2}{\sigma_{\text{poolé}}} \quad \text{avec } \sigma_{\text{poolé}} = \sqrt{\frac{(n_1-1)s_1^2 + (n_2-1)s_2^2}{n_1+n_2-2}}\)$
Convention de Cohen : \(d = 0.2\) (petit), \(d = 0.5\) (moyen), \(d = 0.8\) (grand).
r de Pearson (mesure d’association ou d’effet pour le test t) : $\(r = \frac{t}{\sqrt{t^2 + df}}\)$
η² (eta carré) et ω² (omega carré) pour l’ANOVA : $\(\eta^2 = \frac{SS_{\text{effet}}}{SS_{\text{total}}}, \quad \omega^2 = \frac{SS_{\text{effet}} - df_{\text{effet}} \cdot MS_{\text{résidu}}}{SS_{\text{total}} + MS_{\text{résidu}}}\)$
η² surestime la taille d’effet (biais positif) ; ω² est un estimateur sans biais, recommandé.
Impact de n sur la p-valeur — même taille d'effet Cohen's d = 0.5
n/groupe | Cohen's d | p-valeur | Signif.
----------------------------------------------
10 | -1.690 | 0.0014 | Oui ✓
30 | -0.797 | 0.0031 | Oui ✓
100 | -0.600 | 0.0000 | Oui ✓
500 | -0.430 | 0.0000 | Oui ✓
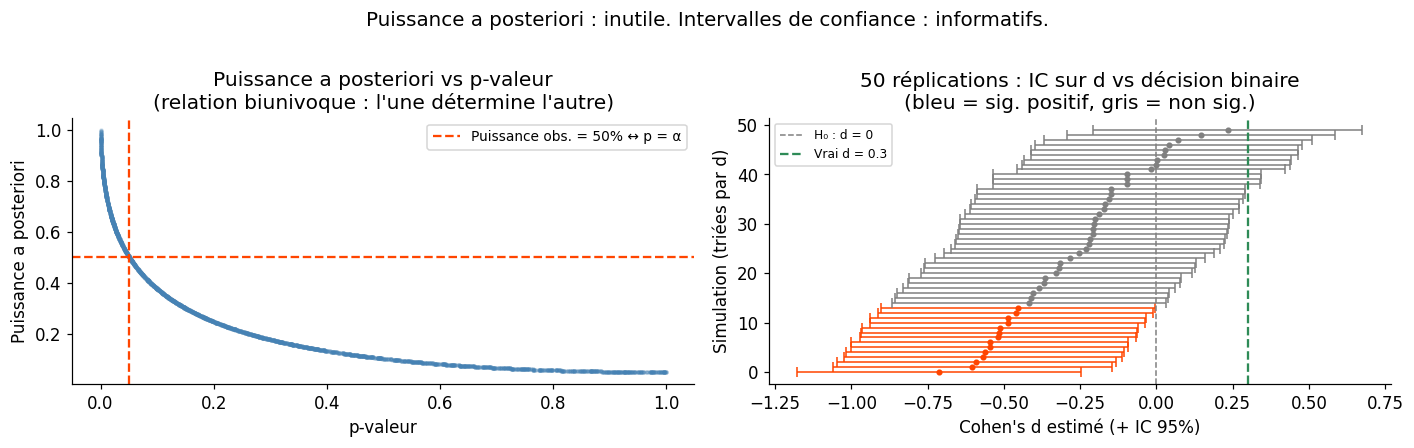
Puissance a priori vs a posteriori#
Puissance a priori#
Calculée avant la collecte des données, elle détermine la taille d’échantillon nécessaire pour détecter un effet minimal d’intérêt (SESOI, Smallest Effect Size of Interest) avec une probabilité suffisante (généralement 80% ou 90%).
Puissance a posteriori : inutile et trompeuse#
La puissance a posteriori (ou observed power) consiste à calculer la puissance en utilisant l’effet observé dans les données. C’est une erreur conceptuelle grave :
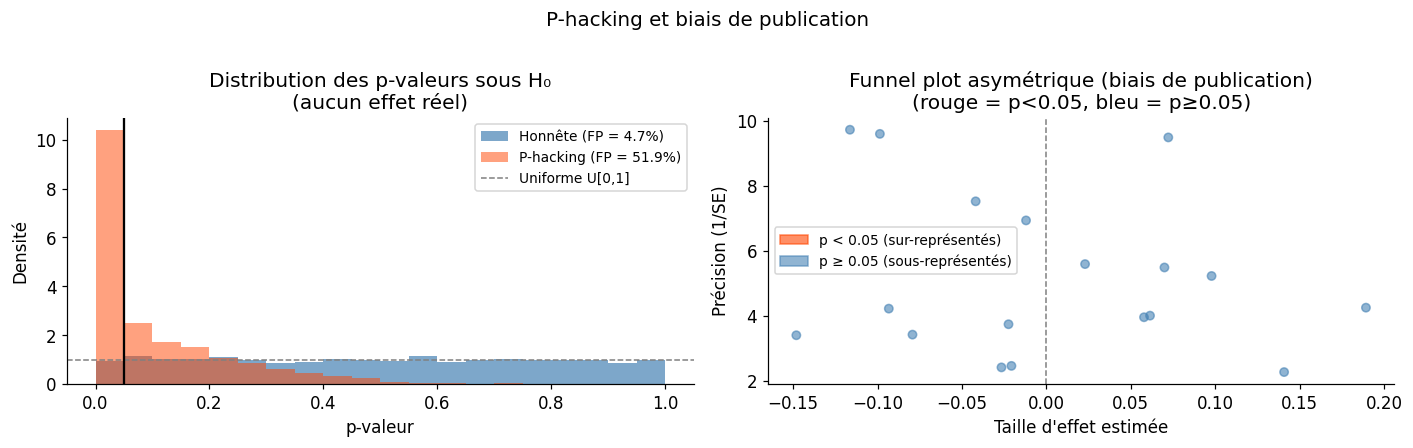
P-hacking et ses conséquences#
Simulation du p-hacking#
Le p-hacking désigne l’ensemble des pratiques qui augmentent artificiellement la probabilité d’obtenir \(p < 0.05\) : chercher plusieurs analyses, supprimer des données gênantes, ajouter des covariables jusqu’à la significativité, etc.
Taux de faux positifs (analyse honnête) : 4.7%
Taux de faux positifs (p-hacking × 10) : 51.9%
Inflation du taux de faux positifs : ×11.1
Rapport statistique complet#
Ce qu’un rapport doit contenir#
Les recommandations APA (7e édition), CONSORT (essais cliniques) et STROBE (études observationnelles) convergent vers les éléments suivants :
Statistiques descriptives : moyenne ± écart-type (ou médiane [IQR]) selon la distribution
Statistique de test : valeur de la statistique et degrés de liberté (ex : t(58) = 2.34)
P-valeur exacte : ne pas écrire « p < 0.05 » mais « p = 0.023 »
Taille d’effet avec IC 95% : Cohen’s d, r, η²…
Puissance a priori ou taille d’échantillon justifiée
Hypothèse exacte testée (bilatérale ? unilatérale ?)
Violations des hypothèses vérifiées et signalées
# Exemple de rapport complet avec pingouin (ou manual si non disponible)
rng_r = np.random.default_rng(2025)
groupe_trt = rng_r.normal(8.2, 1.5, 35) # score qualité de vie après traitement
groupe_ctl = rng_r.normal(7.1, 1.6, 38) # score qualité de vie groupe contrôle
# Test t
t_s, p_t = stats.ttest_ind(groupe_trt, groupe_ctl)
df_t = len(groupe_trt) + len(groupe_ctl) - 2
d_obs = cohen_d(groupe_trt, groupe_ctl)
r_obs = r_depuis_t(t_s, df_t)
# IC sur Cohen's d (approximation)
se_d = np.sqrt((len(groupe_trt)+len(groupe_ctl))/(len(groupe_trt)*len(groupe_ctl))
+ d_obs**2/(2*(len(groupe_trt)+len(groupe_ctl)-2)))
ic_d_low = d_obs - 1.96 * se_d
ic_d_high = d_obs + 1.96 * se_d
print("═" * 60)
print(" RAPPORT STATISTIQUE COMPLET")
print("═" * 60)
print(f"\n STATISTIQUES DESCRIPTIVES")
print(f" Traitement : M = {groupe_trt.mean():.2f}, SD = {groupe_trt.std(ddof=1):.2f}, n = {len(groupe_trt)}")
print(f" Contrôle : M = {groupe_ctl.mean():.2f}, SD = {groupe_ctl.std(ddof=1):.2f}, n = {len(groupe_ctl)}")
print()
print(f" HYPOTHÈSE TESTÉE")
print(f" H₀ : μ_traitement = μ_contrôle (test bilatéral, α = 0.05)")
print()
print(f" RÉSULTAT DU TEST")
print(f" Test t de Student pour groupes indépendants")
print(f" t({df_t}) = {t_s:.3f}, p = {p_t:.4f}")
print()
print(f" TAILLE D'EFFET")
print(f" Cohen's d = {d_obs:.3f} (IC 95% : [{ic_d_low:.3f}, {ic_d_high:.3f}])")
print(f" r = {r_obs:.3f} ({'petit' if abs(r_obs) < 0.3 else 'moyen' if abs(r_obs) < 0.5 else 'grand'})")
print()
print(f" VÉRIFICATION DES HYPOTHÈSES")
levene_s, levene_p = stats.levene(groupe_trt, groupe_ctl)
shapiro_t, shapiro_pt = stats.shapiro(groupe_trt)
shapiro_c, shapiro_pc = stats.shapiro(groupe_ctl)
print(f" Égalité des variances (Levene) : F = {levene_s:.3f}, p = {levene_p:.4f}")
print(f" Normalité traitement (Shapiro) : W = {shapiro_t:.3f}, p = {shapiro_pt:.4f}")
print(f" Normalité contrôle (Shapiro) : W = {shapiro_c:.3f}, p = {shapiro_pc:.4f}")
print()
print(f" INTERPRÉTATION")
verdict = 'Rejet de H₀' if p_t < 0.05 else 'Non rejet de H₀'
print(f" {verdict} : {'un' if p_t < 0.05 else 'aucun'} effet significatif du traitement sur la qualité de vie")
print(f" (différence de {groupe_trt.mean()-groupe_ctl.mean():.2f} points, {d_obs:.2f} écart-types)")
print("═" * 60)
if PINGOUIN_DISPO:
print("\n Résultat pingouin :")
df_pg = pd.DataFrame({
'score': np.concatenate([groupe_trt, groupe_ctl]),
'groupe': ['traitement']*len(groupe_trt) + ['contrôle']*len(groupe_ctl)
})
result_pg = pg.ttest(groupe_trt, groupe_ctl)
print(result_pg.to_string())
════════════════════════════════════════════════════════════
RAPPORT STATISTIQUE COMPLET
════════════════════════════════════════════════════════════
STATISTIQUES DESCRIPTIVES
Traitement : M = 8.12, SD = 1.64, n = 35
Contrôle : M = 6.96, SD = 1.79, n = 38
HYPOTHÈSE TESTÉE
H₀ : μ_traitement = μ_contrôle (test bilatéral, α = 0.05)
RÉSULTAT DU TEST
Test t de Student pour groupes indépendants
t(71) = 2.879, p = 0.0053
TAILLE D'EFFET
Cohen's d = 0.674 (IC 95% : [0.202, 1.147])
r = 0.323 (moyen)
VÉRIFICATION DES HYPOTHÈSES
Égalité des variances (Levene) : F = 0.407, p = 0.5254
Normalité traitement (Shapiro) : W = 0.970, p = 0.4484
Normalité contrôle (Shapiro) : W = 0.980, p = 0.7302
INTERPRÉTATION
Rejet de H₀ : un effet significatif du traitement sur la qualité de vie
(différence de 1.16 points, 0.67 écart-types)
════════════════════════════════════════════════════════════
Résultat pingouin :
T dof alternative p_val CI95 cohen_d power BF10
T_test 2.888947 70.999602 two-sided 0.005122 [0.36, 1.96] 0.674414 0.810452 7.835
Reproductibilité computationnelle#
Bonnes pratiques Python#
# Rapport d'environnement reproductible
import sys
import importlib
def rapport_environnement():
"""Génère un rapport des versions des packages utilisés."""
packages = ['numpy', 'scipy', 'pandas', 'matplotlib', 'seaborn',
'sklearn', 'statsmodels']
print("ENVIRONNEMENT D'EXÉCUTION")
print(f" Python : {sys.version.split()[0]}")
for pkg in packages:
try:
mod = importlib.import_module(pkg)
version = getattr(mod, '__version__', '?')
print(f" {pkg:<15} : {version}")
except ImportError:
print(f" {pkg:<15} : non installé")
rapport_environnement()
ENVIRONNEMENT D'EXÉCUTION
Python : 3.13.5
numpy : 2.3.5
scipy : 1.17.0
pandas : 3.0.0
matplotlib : 3.10.8
seaborn : 0.13.2
sklearn : 1.8.0
statsmodels : 0.14.6
Pré-enregistrement#
Le pré-enregistrement consiste à déposer publiquement, avant la collecte des données, le protocole complet de l’étude : hypothèses, plan d’analyse, taille d’échantillon, méthodes statistiques. Cela sépare :
Phase confirmatoire : tester les hypothèses pré-enregistrées → les p-valeurs sont interprétables
Phase exploratoire : générer de nouvelles hypothèses → les p-valeurs sont exploratoires
Plateformes : Open Science Framework (osf.io), AsPredicted (aspredicted.org).
Principes FAIR#
Les données et le code doivent être :
Findable (trouvables) : identifiants permanents (DOI), métadonnées
Accessible : accessible en ligne, format ouvert
Interoperable (interopérable) : formats standards (CSV, JSON)
Reusable : licence claire, documentation
Checklist finale#

Récapitulatif visuel du livre#
fig, ax = plt.subplots(figsize=(14, 7))
ax.axis('off')
etapes_livre = [
("Partie I\nExplorer", ["Statistiques\ndescriptives", "Distributions\nen pratique",
"Corrélation", "Visualisation"], '#2980b9'),
("Partie II\nInférence", ["Estimation\n& IC", "Tests\nparamétriques",
"Tests non-\nparamétriques", "Comparaisons\nmultiples"], '#27ae60'),
("Partie III\nModélisation", ["Régression\nlinéaire", "Régression\nmultiple",
"Régression\nlogistique", "GLM"], '#8e44ad'),
("Partie IV\nAvancé", ["Bayésien", "MCMC", "Séries\ntemp.", "Multivarié"], '#e67e22'),
("Partie V\nPratique", ["A/B testing", "Données\nmanquantes",
"Monte Carlo", "Bonnes\npratiques"], '#e74c3c'),
]
x_start = 0.01
y_main = 0.75
y_sub = 0.35
for i, (titre, sous_titres, col) in enumerate(etapes_livre):
x = x_start + i * 0.20
# Boîte principale
fancy = mpatches.FancyBboxPatch((x, y_main - 0.08), 0.18, 0.22,
boxstyle='round,pad=0.02',
facecolor=col, alpha=0.2, edgecolor=col, linewidth=2,
transform=ax.transAxes)
ax.add_patch(fancy)
ax.text(x + 0.09, y_main + 0.08, titre, ha='center', va='center',
fontsize=10, fontweight='bold', color=col, transform=ax.transAxes)
# Flèche vers sous-éléments
ax.annotate('', xy=(x + 0.09, y_sub + 0.15), xytext=(x + 0.09, y_main - 0.08),
xycoords='axes fraction', textcoords='axes fraction',
arrowprops=dict(arrowstyle='->', color=col, lw=1.5))
# Sous-éléments
for j, st in enumerate(sous_titres):
xj = x + (j % 2) * 0.09
yj = y_sub + 0.10 - (j // 2) * 0.12
ax.text(xj + 0.04, yj, st, ha='center', va='center',
fontsize=8, color=col, transform=ax.transAxes,
bbox=dict(boxstyle='round,pad=0.2', facecolor='white',
edgecolor=col, alpha=0.8))
# Flèche de progression
ax.annotate('', xy=(0.99, y_main + 0.03), xytext=(0.01, y_main + 0.03),
xycoords='axes fraction', textcoords='axes fraction',
arrowprops=dict(arrowstyle='->', color='gray', lw=2))
ax.text(0.5, 0.05, 'De l\'exploration à la reproductibilité : un parcours complet en statistiques appliquées',
ha='center', va='center', fontsize=11, style='italic', color='#555555',
transform=ax.transAxes)
ax.set_title('Statistiques appliquées — Lôc Cosnier\nRécapitulatif du livre',
fontsize=14, pad=10)
plt.tight_layout()
plt.show()
Conclusion#
La statistique n’est pas une boîte noire qui transforme des données en vérités. C’est un langage de quantification de l’incertitude qui, utilisé correctement, permet de tirer des conclusions robustes et reproductibles depuis des observations imparfaites.
Les meilleures pratiques ne sont pas un fardeau bureaucratique — elles sont la condition nécessaire pour que les résultats soient utiles au-delà du bureau de celui qui les a produits. Pré-enregistrer, rapporter les tailles d’effet, archiver le code et les données, distinguer exploration et confirmation : ces habitudes transforment une analyse anecdotique en contribution scientifique durable.
Les cinq leçons de ce livre
Décrire avant de tester : les statistiques descriptives et les visualisations révèlent ce que les tests ne peuvent pas.
La p-valeur seule ne suffit pas : toujours accompagner d’un intervalle de confiance et d’une taille d’effet.
La puissance est une décision de design : se poser la question avant, pas après.
Exploration ≠ Confirmation : les hypothèses nées des données ne peuvent pas être testées sur les mêmes données.
La reproductibilité est une responsabilité collective : code, données, protocoles — tout documenter, tout partager.