Visualisation statistique#
Visualiser des données, c’est traduire des nombres abstraits en formes perçues par l’œil. Un bon graphique révèle une structure ; un mauvais graphique la cache ou en invente une. Ce chapitre couvre les principes qui distinguent les deux, les outils seaborn pour les mettre en œuvre, et les erreurs visuelles à éviter absolument.
Principes de Tufte#
Edward Tufte, dans The Visual Display of Quantitative Information (1983), a posé les fondements d’une éthique de la visualisation statistique. Ses principes restent la référence.
Data-ink ratio. Chaque trait d’encre devrait servir à représenter des données. Tout trait décoratif (grilles épaisses, ombres, dégradés, cadres 3D) dilue ce ratio. Le but est de maximiser le ratio données/encre.
Chartjunk. Les éléments non informatifs — hatching, moiré, logos, légendes inutiles — distraient et polluent. Tufte les appelle le chartjunk.
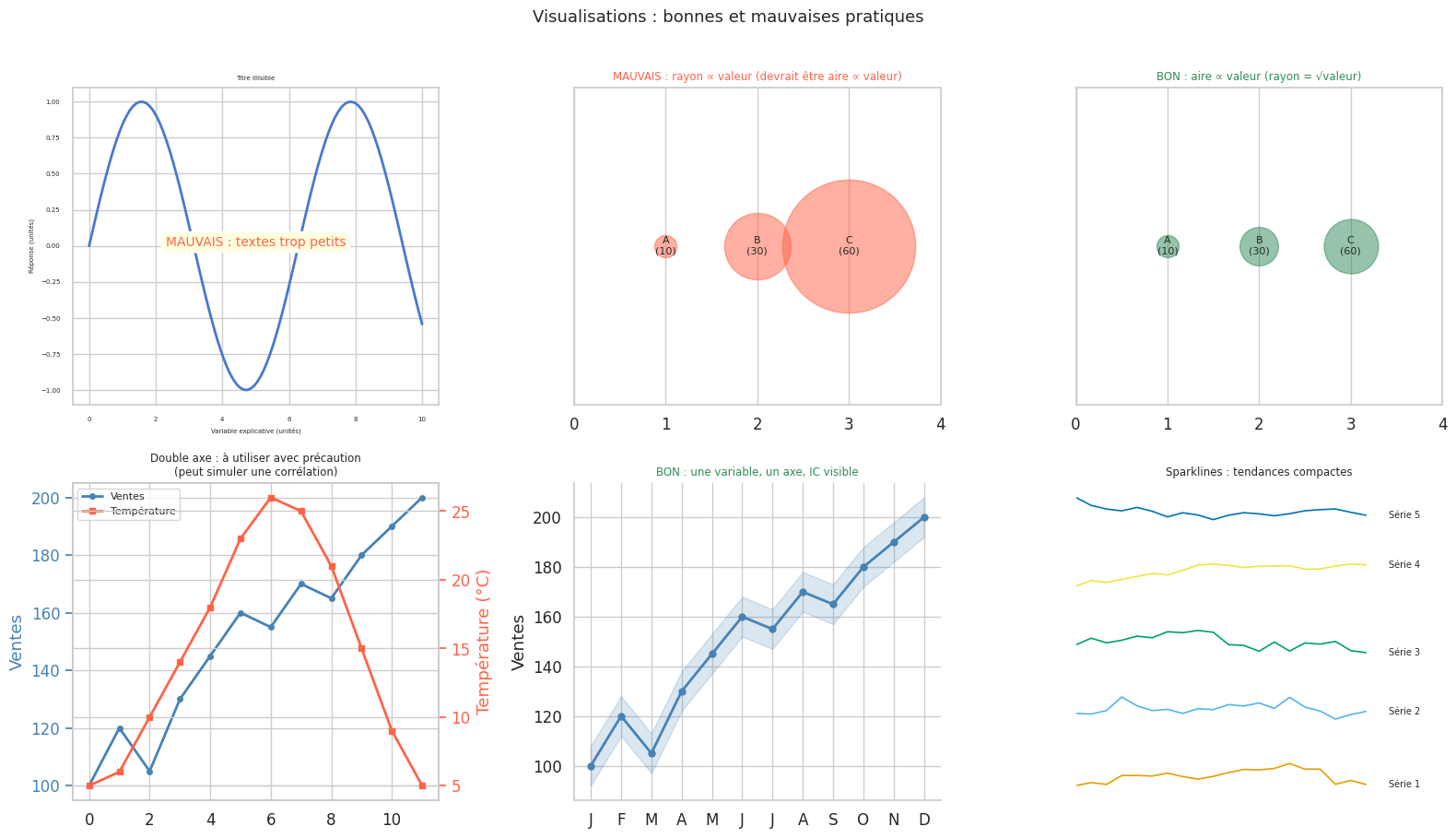
Mensonges visuels. Un axe tronqué qui commence à 97 % au lieu de 0 % pour exagérer une variation de 2 % est un mensonge visuel. L’aire représentée doit être proportionnelle aux données.
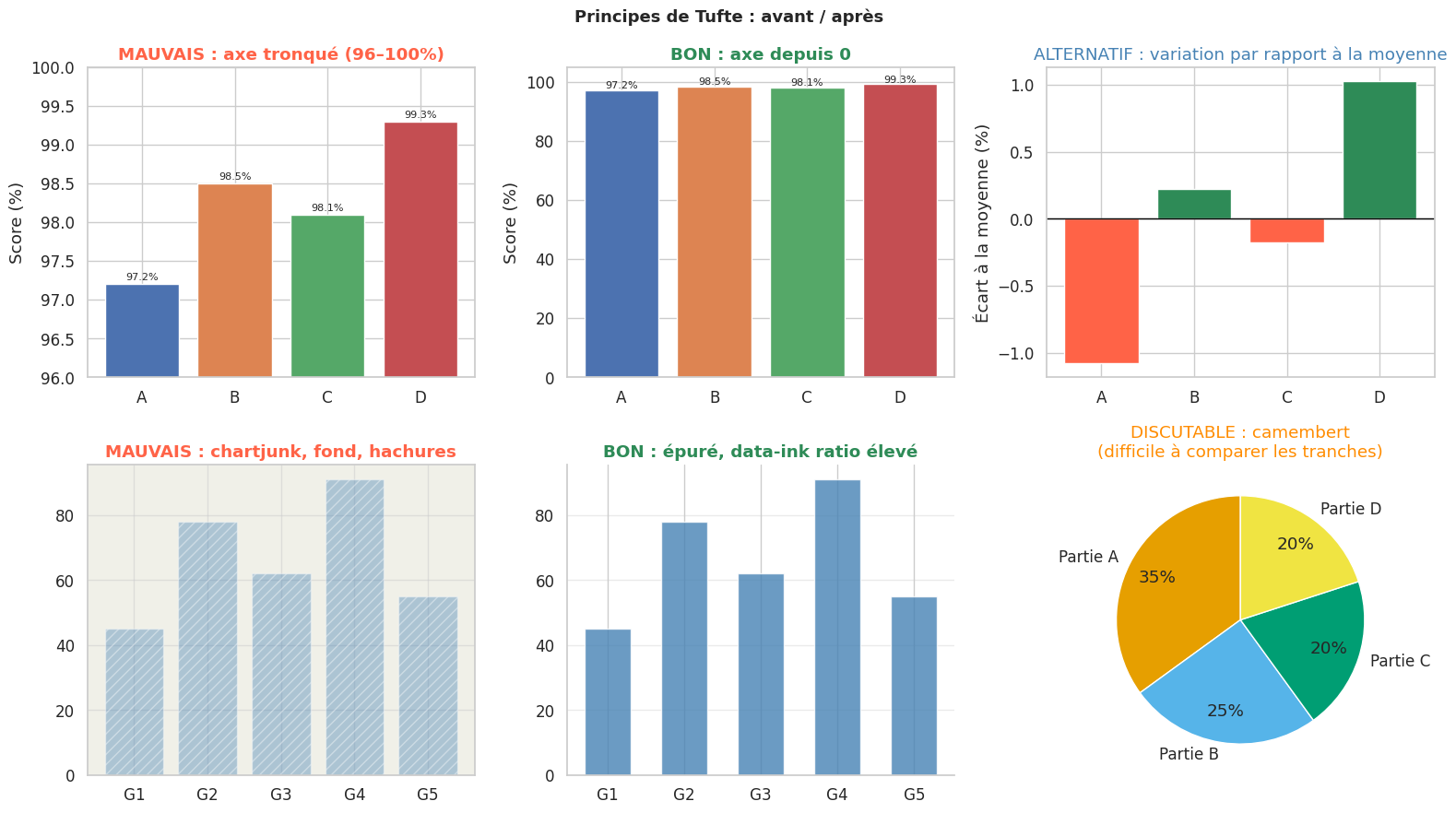
Quand le camembert est-il acceptable ?
Le camembert fonctionne bien uniquement lorsqu’il y a 2 à 3 catégories, que l’on veut montrer qu’une partie représente environ la moitié ou un tiers du tout, et qu’une comparaison précise n’est pas requise. Pour comparer des valeurs proches, un bar chart horizontal est toujours plus lisible.
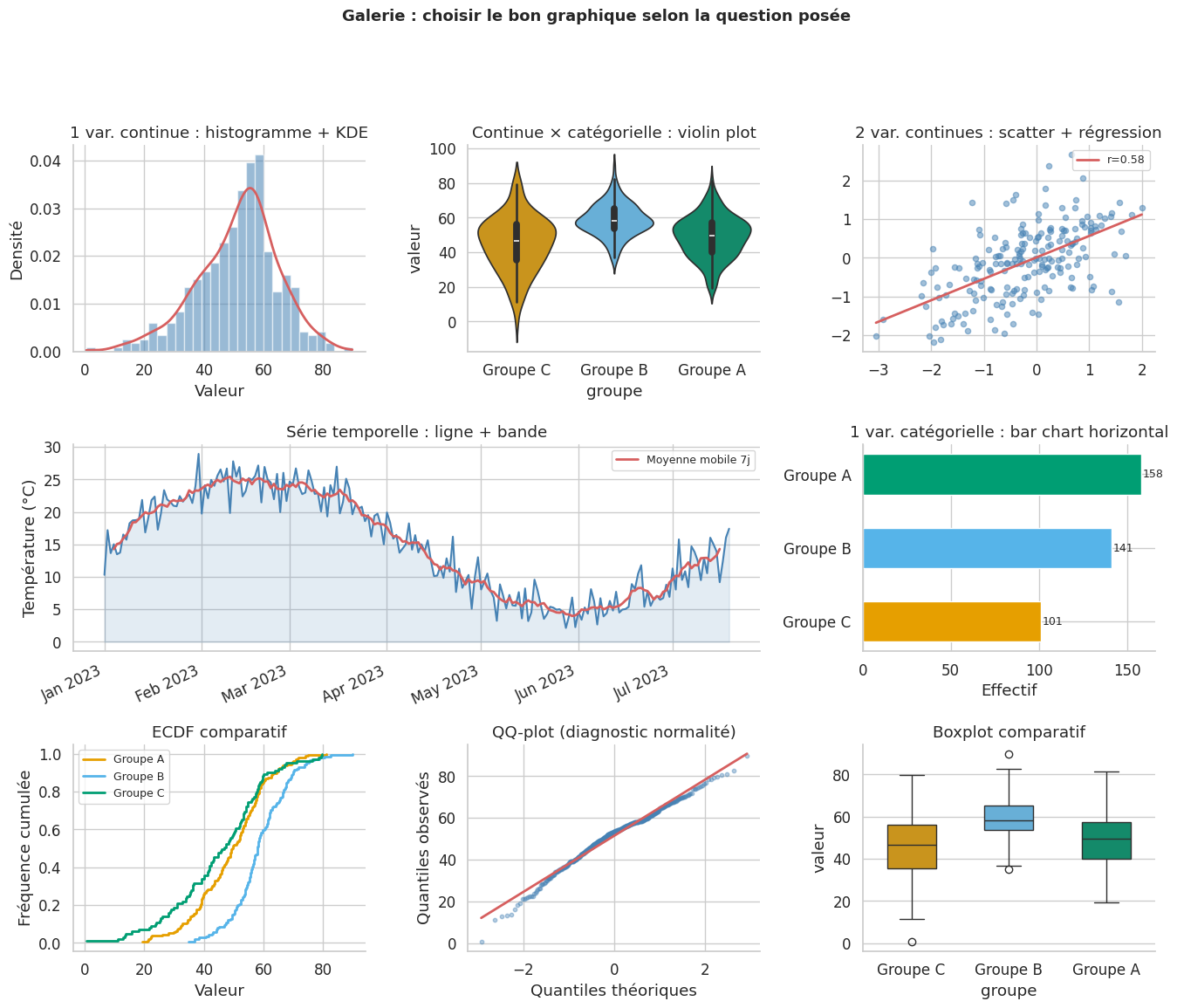
Choisir le bon graphique#
Le choix du graphique dépend de la nature des variables et de la question posée.
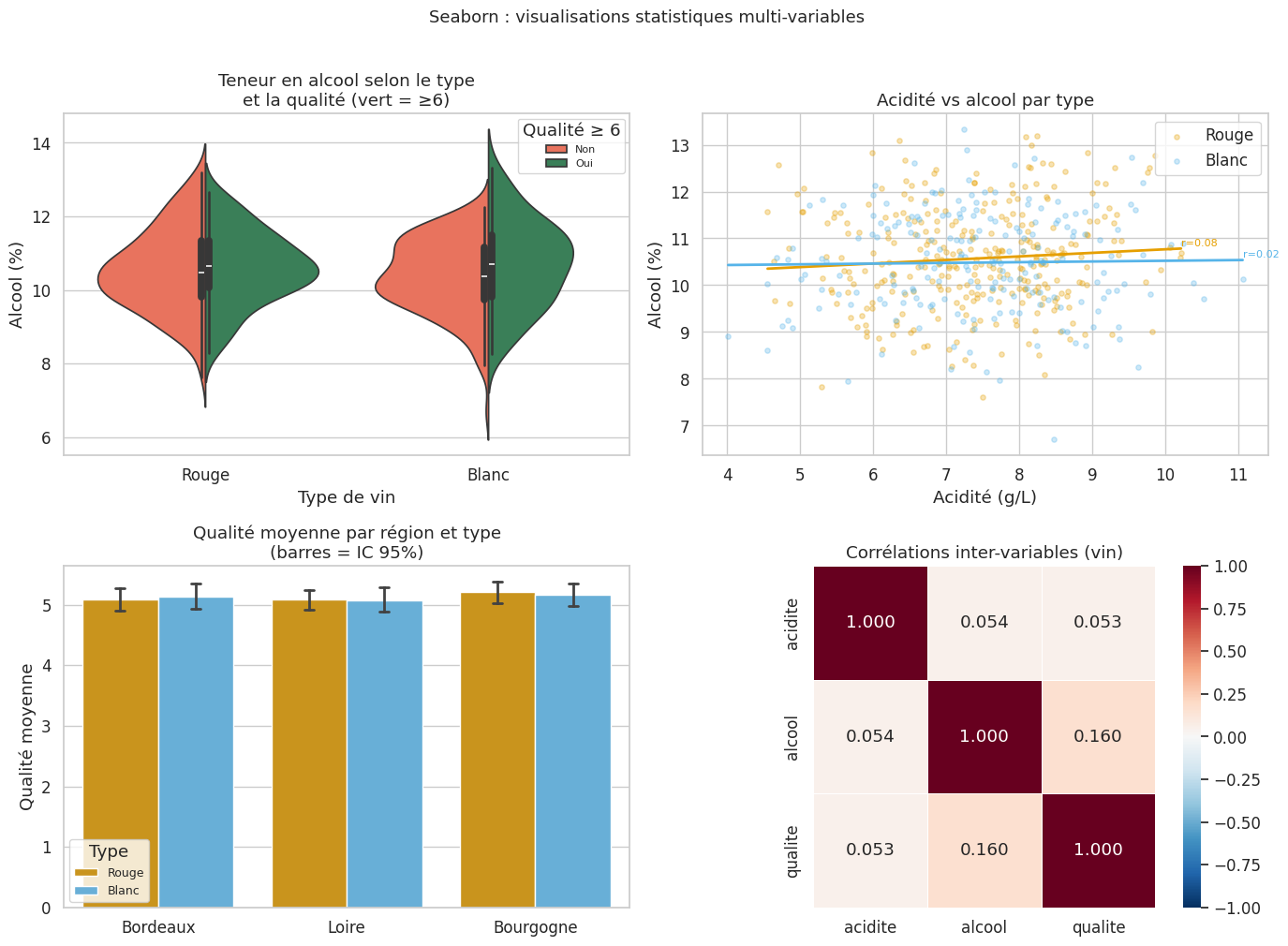
Intervalles de confiance visuels#
Une erreur fréquente est de confondre écart-type, erreur standard et intervalle de confiance dans les barres d’erreur.
Écart-type (\(\sigma\)) : dispersion des observations individuelles.
Erreur standard (\(\sigma / \sqrt{n}\)) : incertitude sur la moyenne estimée.
IC 95% : l’intervalle contient la vraie moyenne avec probabilité 95 % (sur des répétitions infinies).
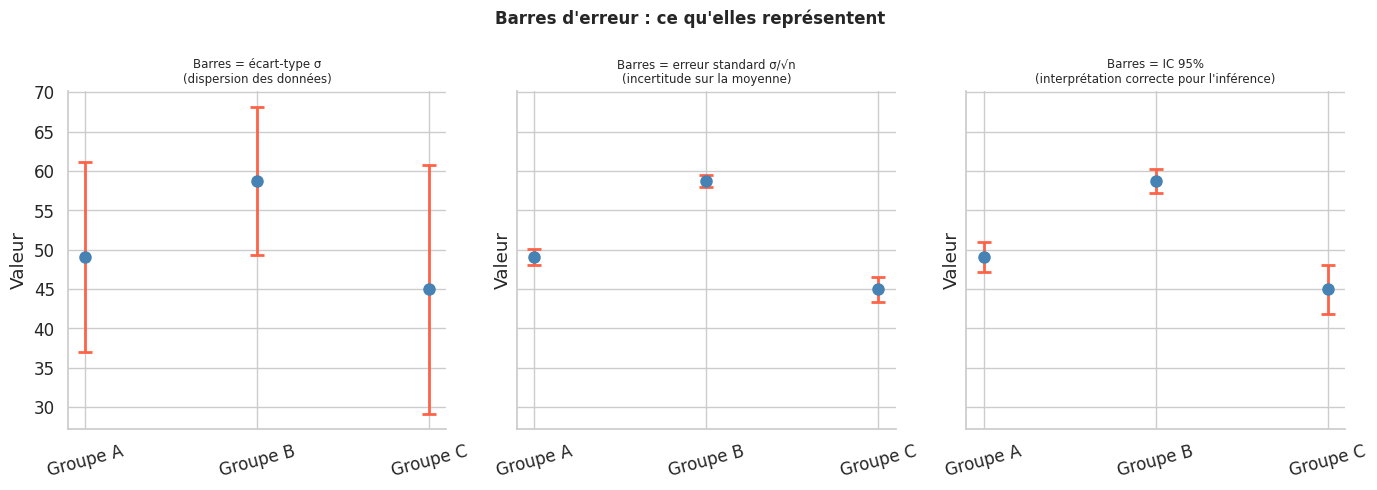
Règle d’or pour les barres d’erreur
Indiquez toujours explicitement dans la légende ce que représentent vos barres d’erreur (écart-type, SE, IC 95 %). L’absence de cette information rend le graphique ambigu. Pour l’inférence statistique (comparaison de groupes), les IC 95 % sont les plus informatifs : deux IC qui se chevauchent légèrement peuvent correspondre à une différence statistiquement significative si les variances sont différentes.
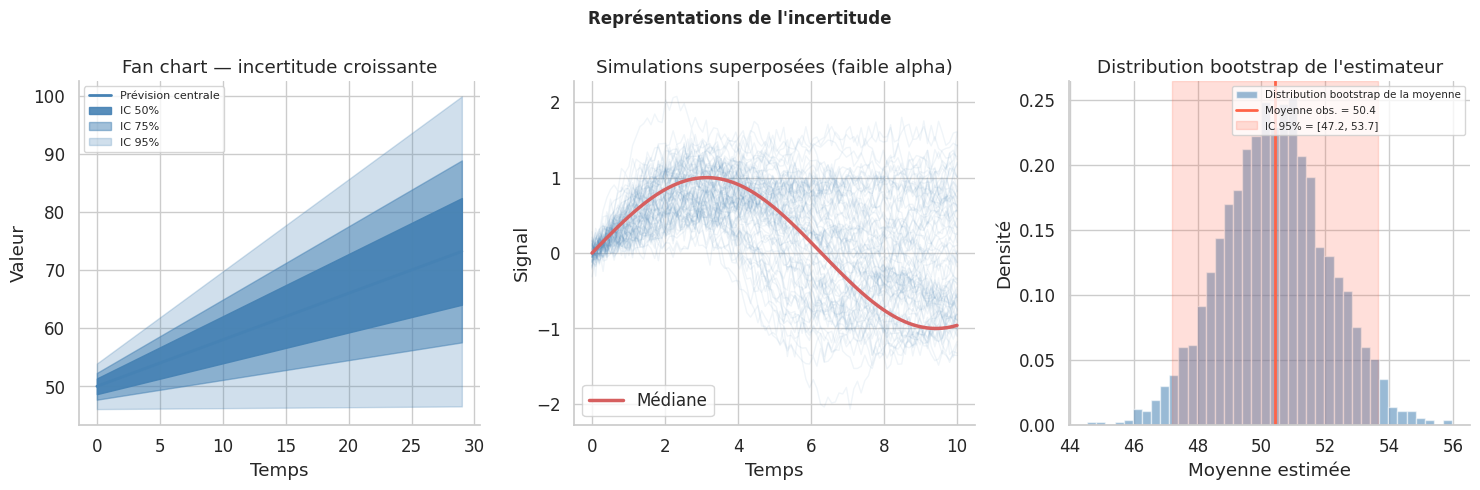
Représentation de l’incertitude#
Au-delà des simples barres d’erreur, les distributions a posteriori, les fan charts et les simulations offrent des représentations plus riches de l’incertitude.
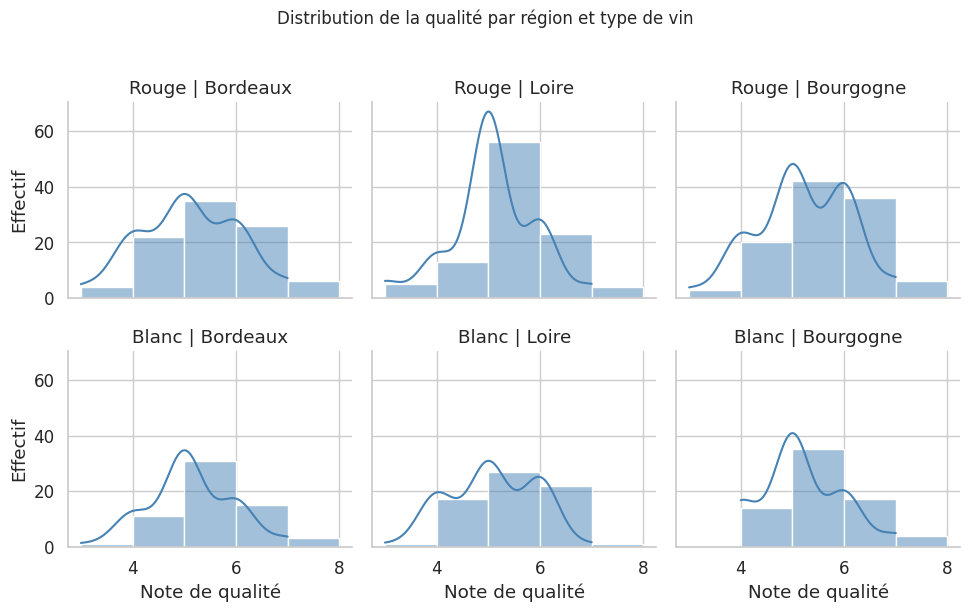
Seaborn : FacetGrid, catplot, displot#
Seaborn offre une grammaire des graphiques qui permet de décomposer facilement les visualisations selon des variables catégorielles.
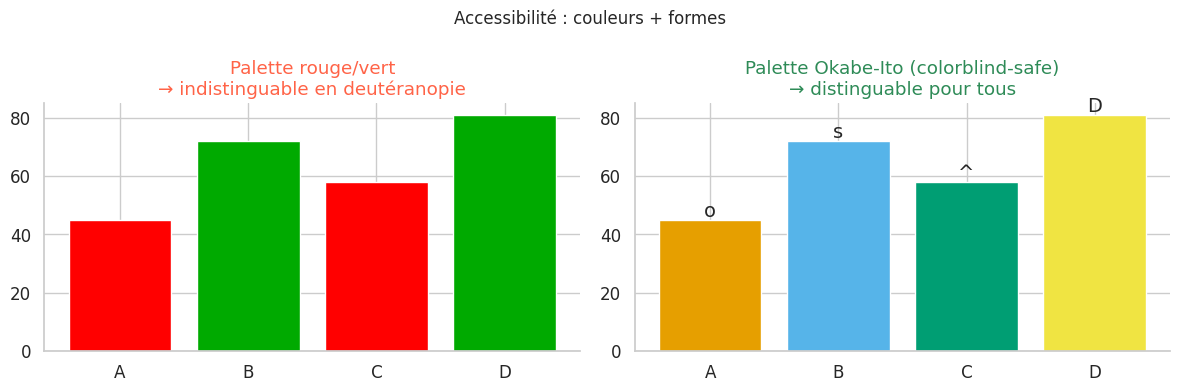
Accessibilité : palettes daltonisme-friendly#
Environ 8 % des hommes et 0,5 % des femmes présentent un déficit de perception des couleurs. La deutéranopie (insensibilité au vert) et la protanopie (insensibilité au rouge) sont les formes les plus fréquentes.

Graphiques trompeurs vs corrects : galerie#
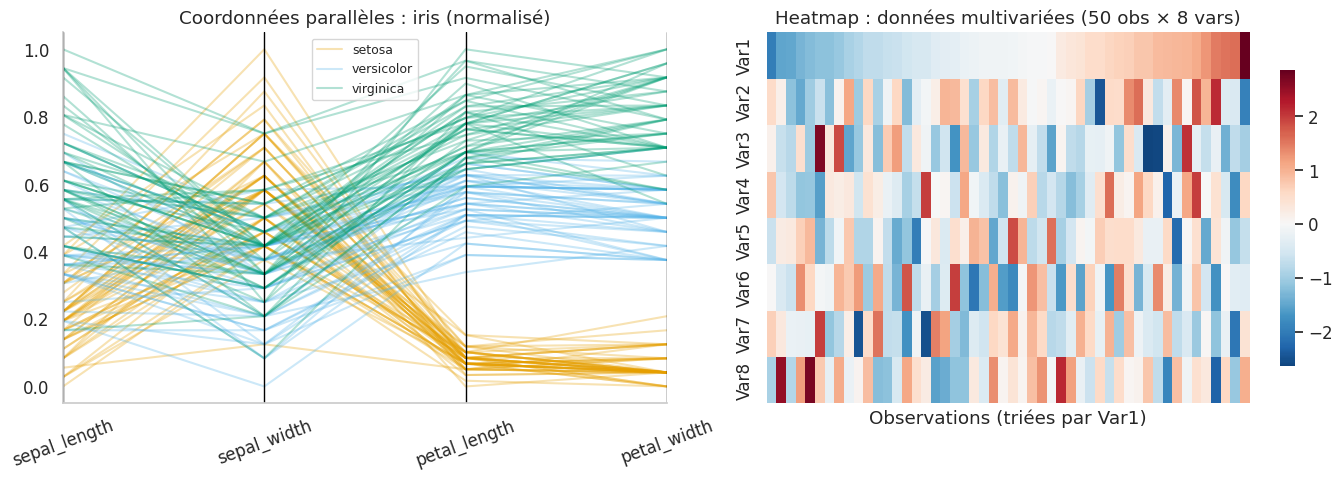
Coordonnées parallèles et données multivariées#
Pour des données avec de nombreuses variables, les coordonnées parallèles permettent de visualiser les relations multivariées.
Principes d’accessibilité en visualisation
Couleurs : utiliser des palettes colorblind-safe (Okabe-Ito, colorblind de seaborn, viridis). Ne pas coder une information uniquement par la couleur — ajouter une forme, un motif ou un label.
Polices : taille minimale de 10pt pour les labels, 12pt pour les titres dans un article. Les titres doivent décrire la conclusion, pas seulement le contenu.
Contraste : ratio de contraste ≥ 4.5:1 pour le texte (norme WCAG AA).
Titre informatif : un titre du type « Les ventes ont augmenté de 40 % depuis janvier » est plus utile que « Évolution des ventes ».
Pas de 3D décoratif : les graphiques en relief ou en perspective distordent les perceptions de longueur et d’aire.
Une bonne visualisation statistique n’est pas un exercice artistique. C’est un acte de communication : elle doit permettre au lecteur d’extraire rapidement et fidèlement l’information pertinente, sans induire en erreur. Les principes de Tufte, les palettes accessibles et le choix rigoureux du type de graphique sont les outils de ce travail.