Statistiques bayésiennes#
Dans un monde incertain, toute croyance est une distribution — non un point.
Introduction : deux visions de la probabilité#
Les statistiques fréquentistes et bayésiennes posent la même question — que nous apprennent les données ? — mais y répondent avec des philosophies radicalement différentes.
Vision fréquentiste : la probabilité est la fréquence limite d’un événement dans des répétitions infinies d’une expérience. Les paramètres \(\theta\) sont des valeurs fixes (inconnues mais non aléatoires). On construit des estimateurs et des intervalles qui ont de bonnes propriétés en répétition.
Vision bayésienne : la probabilité est un degré de croyance (degree of belief). Les paramètres \(\theta\) sont des variables aléatoires représentant notre incertitude. On met à jour nos croyances grâce aux données.
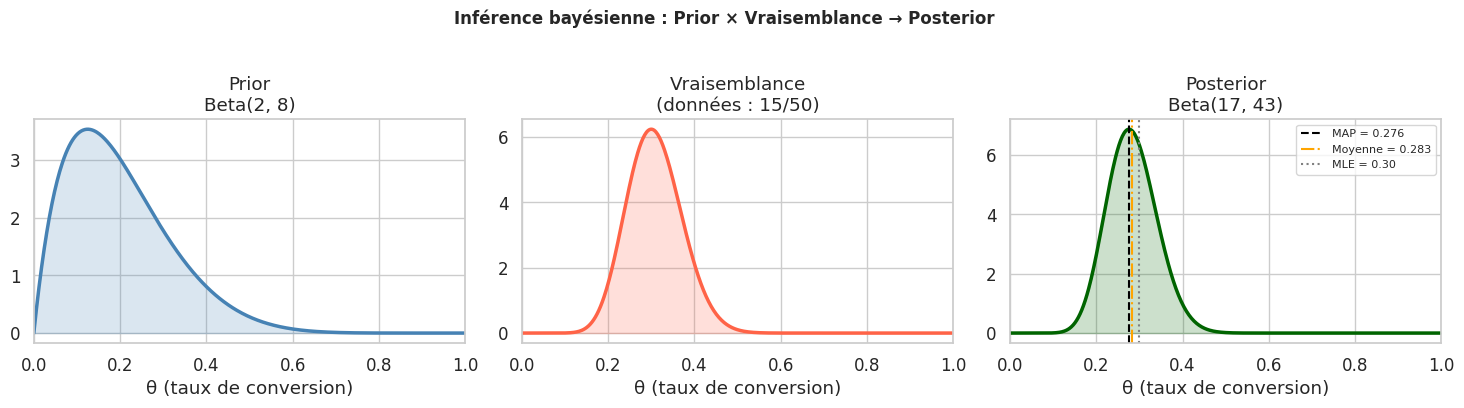
Le théorème de Bayes#
Le théorème de Bayes est le cœur de toute inférence bayésienne :
En notation proportionnelle (on ignore souvent l’evidence, une constante de normalisation) :
Rôle de chaque composante#
Prior \(P(\theta)\) : encode les croyances avant d’observer les données. Peut être informatif (expertise métier) ou non-informatif (maximum d’incertitude).
Vraisemblance \(P(\mathbf{y} \mid \theta)\) : quantifie à quel point les données sont compatibles avec chaque valeur de \(\theta\).
Posterior \(P(\theta \mid \mathbf{y})\) : la distribution mise à jour après observation — c’est notre incertitude sur \(\theta\) compte tenu des données.
Priors informatifs vs non-informatifs
Un prior non-informatif (ou diffus) laisse les données parler : Beta(1,1) = uniforme sur [0,1], ou prior de Jeffreys. Un prior informatif intègre des connaissances métier préalables : si une étude précédente estimait le taux à ~20%, on peut poser Beta(4,16) pour encoder cette information avec un certain degré de confiance.
Distributions conjuguées#
Une famille de priors \(\mathcal{P}\) est conjuguée à une vraisemblance \(\mathcal{L}\) si le posterior appartient à la même famille que le prior. La conjugaison permet un calcul analytique exact du posterior.
Conjugaison Beta–Binomiale#
Modèle :
Prior : \(\theta \sim \text{Beta}(\alpha, \beta)\)
Vraisemblance : \(Y \mid \theta \sim \text{Binomiale}(n, \theta)\)
Posterior : \(\theta \mid Y=k \sim \text{Beta}(\alpha + k, \beta + n - k)\)
def posterior_beta_binomial(alpha_prior, beta_prior, n_obs, k_obs):
"""Calcule le posterior Beta-Binomial."""
return alpha_prior + k_obs, beta_prior + n_obs - k_obs
# Exemple numérique
print("Conjugaison Beta-Binomiale")
print("="*40)
print(f"Prior : Beta({2}, {8})")
print(f" Moyenne a priori : {2/(2+8):.2f}")
print(f" Variance a priori : {2*8/((2+8)**2*(2+8+1)):.4f}")
print()
observations = [(10, 2), (20, 6), (50, 16), (200, 64)]
alpha_p, beta_p = 2, 8
for n, k in observations:
a_post, b_post = posterior_beta_binomial(alpha_p, beta_p, n, k)
print(f"Données : {k}/{n} (MLE = {k/n:.2f})")
print(f" → Posterior Beta({a_post}, {b_post})")
print(f" Moyenne post : {a_post/(a_post+b_post):.3f}")
print(f" Écart-type : {np.sqrt(a_post*b_post/((a_post+b_post)**2*(a_post+b_post+1))):.3f}")
print()
Conjugaison Beta-Binomiale
========================================
Prior : Beta(2, 8)
Moyenne a priori : 0.20
Variance a priori : 0.0145
Données : 2/10 (MLE = 0.20)
→ Posterior Beta(4, 16)
Moyenne post : 0.200
Écart-type : 0.087
Données : 6/20 (MLE = 0.30)
→ Posterior Beta(8, 22)
Moyenne post : 0.267
Écart-type : 0.079
Données : 16/50 (MLE = 0.32)
→ Posterior Beta(18, 42)
Moyenne post : 0.300
Écart-type : 0.059
Données : 64/200 (MLE = 0.32)
→ Posterior Beta(66, 144)
Moyenne post : 0.314
Écart-type : 0.032
Conjugaison Normale–Normale#
Pour une moyenne gaussienne avec variance connue \(\sigma^2\) :
Prior : \(\mu \sim \mathcal{N}(\mu_0, \tau_0^2)\)
Vraisemblance : \(Y_i \mid \mu \sim \mathcal{N}(\mu, \sigma^2)\)
Le posterior est :
avec :
def posterior_normal_normal(mu0, tau0_sq, sigma_sq, data):
"""Posterior Normal-Normal pour la moyenne (variance connue)."""
n = len(data)
y_bar = np.mean(data)
tau_n_sq = 1 / (1/tau0_sq + n/sigma_sq)
mu_n = tau_n_sq * (mu0/tau0_sq + n*y_bar/sigma_sq)
return mu_n, tau_n_sq
np.random.seed(42)
# Scénario : estimer la durée moyenne d'un traitement (jours)
# Prior : mu0=10 jours, tau0=3 (incertitude a priori importante)
# Données : 25 patients, vraie moyenne = 7 jours, sigma = 2 jours
true_mu = 7.0
sigma = 2.0
n_patients = 25
data_durees = np.random.normal(true_mu, sigma, n_patients)
mu0, tau0_sq = 10.0, 9.0
mu_post, tau_post_sq = posterior_normal_normal(mu0, tau0_sq, sigma**2, data_durees)
print("Conjugaison Normale-Normale (durée de traitement)")
print(f"Prior : N({mu0}, {tau0_sq:.1f}) → μ ~ [7.1, 12.9] à 95%")
print(f"Données : n={n_patients}, ȳ={data_durees.mean():.2f}")
print(f"Posterior : N({mu_post:.3f}, {tau_post_sq:.4f})")
print(f" σ posterior : {np.sqrt(tau_post_sq):.4f}")
print(f" IC 95% post : [{mu_post - 1.96*np.sqrt(tau_post_sq):.2f}, "
f"{mu_post + 1.96*np.sqrt(tau_post_sq):.2f}]")
Conjugaison Normale-Normale (durée de traitement)
Prior : N(10.0, 9.0) → μ ~ [7.1, 12.9] à 95%
Données : n=25, ȳ=6.67
Posterior : N(6.731, 0.1572)
σ posterior : 0.3965
IC 95% post : [5.95, 7.51]
Conjugaison Gamma–Poisson#
Pour un taux de Poisson \(\lambda\) :
Prior : \(\lambda \sim \text{Gamma}(\alpha, \beta)\)
Vraisemblance : \(Y_i \mid \lambda \sim \text{Poisson}(\lambda)\)
Posterior : \(\lambda \mid \mathbf{y} \sim \text{Gamma}(\alpha + \sum y_i, \beta + n)\)
def posterior_gamma_poisson(alpha_prior, beta_prior, data):
"""Posterior Gamma-Poisson pour le taux lambda."""
n = len(data)
sum_y = np.sum(data)
return alpha_prior + sum_y, beta_prior + n
np.random.seed(2024)
true_lambda = 3.5
data_counts = np.random.poisson(true_lambda, 30)
alpha_g, beta_g = 2.0, 1.0 # prior Gamma(2,1)
alpha_g_post, beta_g_post = posterior_gamma_poisson(alpha_g, beta_g, data_counts)
print("Conjugaison Gamma-Poisson (taux d'événements)")
print(f"Prior : Gamma({alpha_g}, {beta_g}) → E[λ] = {alpha_g/beta_g:.1f}")
print(f"Données : n={len(data_counts)}, Σy={data_counts.sum()}, ȳ={data_counts.mean():.2f}")
print(f"Posterior: Gamma({alpha_g_post}, {beta_g_post})")
print(f" E[λ|y] : {alpha_g_post/beta_g_post:.3f}")
print(f" MAP : {(alpha_g_post-1)/beta_g_post:.3f}")
Conjugaison Gamma-Poisson (taux d'événements)
Prior : Gamma(2.0, 1.0) → E[λ] = 2.0
Données : n=30, Σy=121, ȳ=4.03
Posterior: Gamma(123.0, 31.0)
E[λ|y] : 3.968
MAP : 3.935
Mise à jour séquentielle#
Une propriété fondamentale de l’inférence bayésienne : le posterior d’aujourd’hui devient le prior de demain. Les données peuvent arriver par vagues sans tout retraiter.
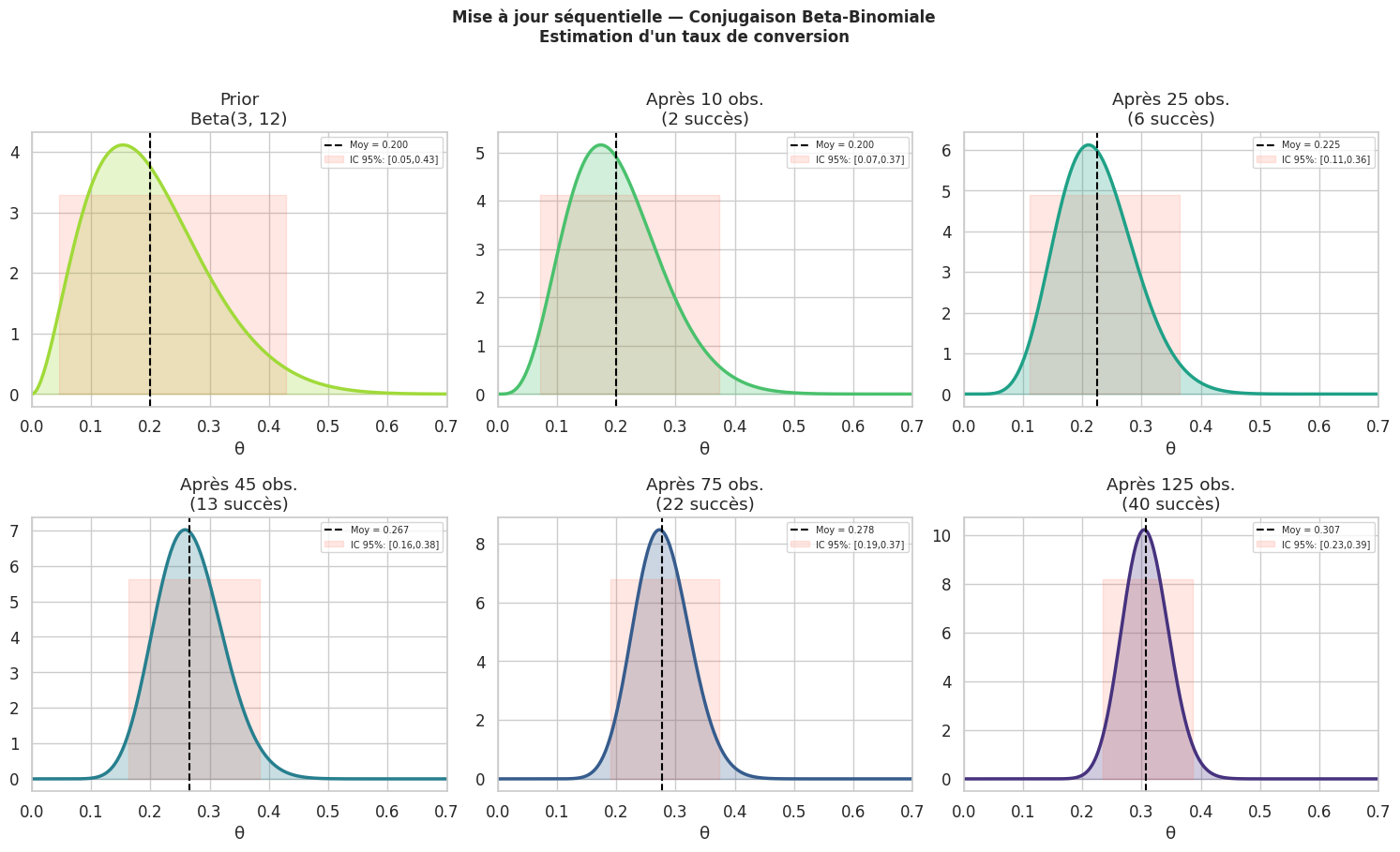
Estimation bayésienne ponctuelle#
Deux estimateurs ponctuels naturels émergent du posterior :
MAP (Maximum A Posteriori) : mode du posterior — équivalent au MLE avec un prior comme régularisateur.
Moyenne du posterior (EAP, Expected A Posteriori) : minimise l’erreur quadratique moyenne bayésienne.
Médiane : minimise l’erreur absolue moyenne bayésienne.
# Comparaison MAP, moyenne, MLE
alpha_ex, beta_ex = 3, 12 # prior
n_ex, k_ex = 100, 35 # données
alpha_post_ex = alpha_ex + k_ex
beta_post_ex = beta_ex + n_ex - k_ex
mle = k_ex / n_ex
map_est = (alpha_post_ex - 1) / (alpha_post_ex + beta_post_ex - 2)
mean_post_ex = alpha_post_ex / (alpha_post_ex + beta_post_ex)
median_post_ex = stats.beta.ppf(0.5, alpha_post_ex, beta_post_ex)
print("Estimateurs ponctuels (n=100, k=35)")
print(f" MLE : {mle:.4f}")
print(f" MAP : {map_est:.4f}")
print(f" Moyenne post. : {mean_post_ex:.4f}")
print(f" Médiane post. : {median_post_ex:.4f}")
print(f"\n (Prior Beta(3,12) tire vers 3/15 = {3/15:.2f})")
print(f" La moyenne du posterior est un mélange entre MLE et prior.")
Estimateurs ponctuels (n=100, k=35)
MLE : 0.3500
MAP : 0.3274
Moyenne post. : 0.3304
Médiane post. : 0.3294
(Prior Beta(3,12) tire vers 3/15 = 0.20)
La moyenne du posterior est un mélange entre MLE et prior.
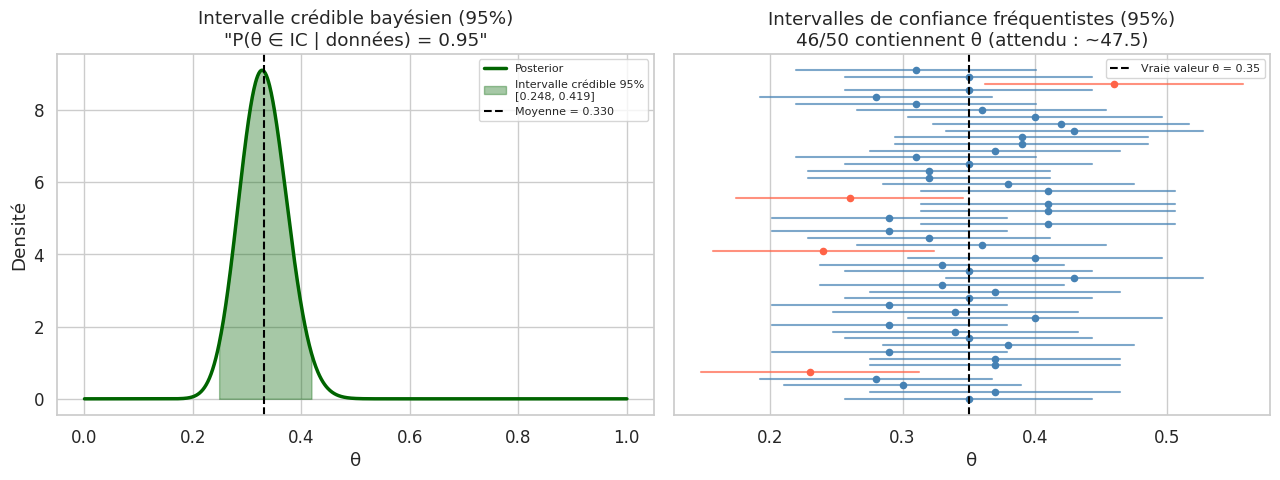
Intervalles crédibles vs intervalles de confiance#
C’est l’une des différences conceptuelles les plus importantes entre les deux approches.
Différence fondamentale
Intervalle de confiance (fréquentiste) : « Si je répète cette expérience de nombreuses fois, 95% des intervalles construits contiendront la vraie valeur de θ. » Le paramètre θ est fixe ; c’est l’intervalle qui est aléatoire.
Intervalle crédible (bayésien) : « Étant donné les données observées, il y a 95% de probabilité que θ soit dans cet intervalle. » C’est l’interprétation intuitive que beaucoup donnent à tort à l’IC fréquentiste !
Facteur de Bayes#
Le facteur de Bayes permet de comparer deux modèles \(M_1\) et \(M_2\) :
L’échelle de Jeffreys d’interprétation :
BF₁₂ |
Preuve en faveur de M₁ |
|---|---|
1–3 |
Anecdotique |
3–10 |
Modérée |
10–30 |
Forte |
30–100 |
Très forte |
> 100 |
Décisive |
# Facteur de Bayes analytique pour le modèle Beta-Binomial
def log_marginal_beta_binomial(k, n, alpha, beta):
"""Log-vraisemblance marginale pour Beta-Binomial."""
from scipy.special import gammaln
log_binom = gammaln(n+1) - gammaln(k+1) - gammaln(n-k+1)
log_beta_prior = betaln(alpha, beta)
log_beta_post = betaln(alpha + k, beta + n - k)
return log_binom + log_beta_post - log_beta_prior
# Comparer M1: theta ~ Beta(1,1) vs M2: theta ~ Beta(2,8)
k_obs_bf, n_obs_bf = 20, 50
log_m1 = log_marginal_beta_binomial(k_obs_bf, n_obs_bf, 1, 1) # prior uniforme
log_m2 = log_marginal_beta_binomial(k_obs_bf, n_obs_bf, 2, 8) # prior concentré ~20%
log_bf = log_m1 - log_m2
bf = np.exp(log_bf)
print(f"Facteur de Bayes BF₁₂ = {bf:.3f}")
print(f" M1 : Prior Beta(1,1) (uniforme)")
print(f" M2 : Prior Beta(2,8) (concentré autour de 20%)")
if bf > 1:
print(f" → Les données favorisent M1 (prior non-informatif)")
else:
print(f" → Les données favorisent M2 (prior informatif)")
Facteur de Bayes BF₁₂ = 1.140
M1 : Prior Beta(1,1) (uniforme)
M2 : Prior Beta(2,8) (concentré autour de 20%)
→ Les données favorisent M1 (prior non-informatif)
Exemple complet : A/B testing bayésien#
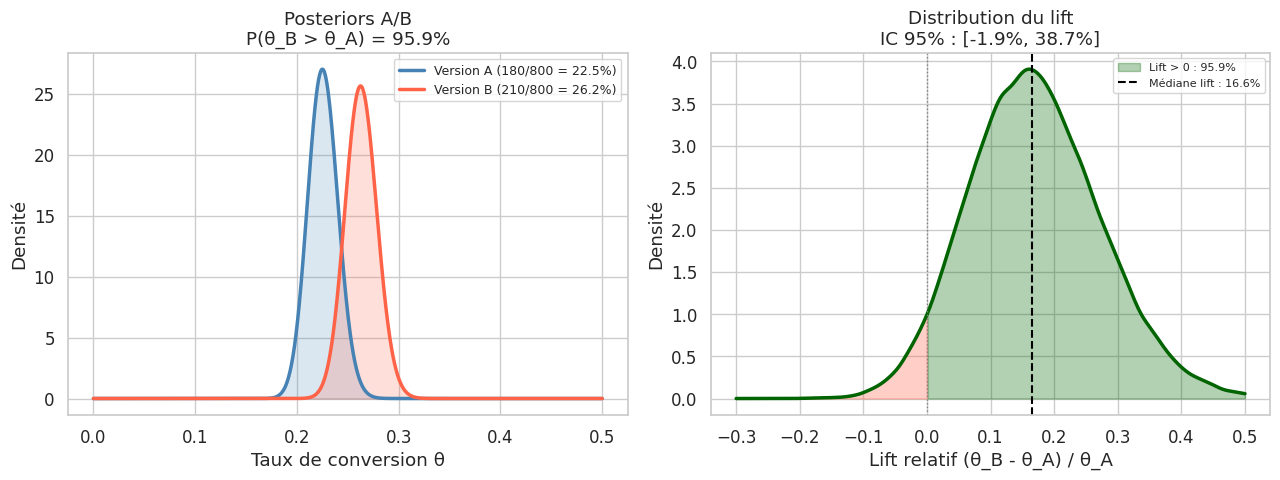
P(Version B meilleure que A) = 95.9%
Lift médian = 16.6%
IC crédible 95% du lift = [-1.9%, 38.7%]
Comparaison avec l’approche fréquentiste#
from scipy.stats import chi2_contingency, norm
# Test du chi-2 fréquentiste pour le même A/B test
table = np.array([[kA, nA - kA], [kB, nB - kB]])
chi2, p_val, _, _ = chi2_contingency(table)
# Intervalle de confiance fréquentiste sur la différence
pA_hat = kA / nA
pB_hat = kB / nB
se_diff = np.sqrt(pA_hat*(1-pA_hat)/nA + pB_hat*(1-pB_hat)/nB)
diff = pB_hat - pA_hat
ci_freq = (diff - 1.96*se_diff, diff + 1.96*se_diff)
print("Comparaison fréquentiste vs bayésienne — A/B Test")
print("="*50)
print("\nApproche FRÉQUENTISTE :")
print(f" Différence : {diff:.4f} ({diff:.1%})")
print(f" IC 95% : [{ci_freq[0]:.4f}, {ci_freq[1]:.4f}]")
print(f" χ² = {chi2:.3f}, p-valeur = {p_val:.4f}")
print(f" Conclusion : {'Différence significative' if p_val < 0.05 else 'Pas significatif'}")
print("\nApproche BAYÉSIENNE (prior Beta(1,1)) :")
print(f" Différence médiane : {lift_median:.1%}")
print(f" IC crédible 95% : [{lift_ci[0]:.1%}, {lift_ci[1]:.1%}]")
print(f" P(B>A) = {prob_B_better:.1%}")
print(f" Conclusion : Version B meilleure avec probabilité {prob_B_better:.1%}")
print("\n→ L'approche bayésienne donne une probabilité directe, plus intuitive.")
Comparaison fréquentiste vs bayésienne — A/B Test
==================================================
Approche FRÉQUENTISTE :
Différence : 0.0375 (3.8%)
IC 95% : [-0.0045, 0.0795]
χ² = 2.851, p-valeur = 0.0913
Conclusion : Pas significatif
Approche BAYÉSIENNE (prior Beta(1,1)) :
Différence médiane : 16.6%
IC crédible 95% : [-1.9%, 38.7%]
P(B>A) = 95.9%
Conclusion : Version B meilleure avec probabilité 95.9%
→ L'approche bayésienne donne une probabilité directe, plus intuitive.
Résumé#
Points clés — Statistiques bayésiennes
Le théorème de Bayes : posterior ∝ vraisemblance × prior. On met à jour les croyances grâce aux données.
La conjugaison permet un calcul analytique exact : Beta-Binomiale, Normale-Normale, Gamma-Poisson.
La mise à jour séquentielle est naturelle : le posterior courant devient le prior pour la prochaine vague de données.
L”intervalle crédible donne directement une probabilité sur θ (contrairement à l’IC fréquentiste).
Le facteur de Bayes compare des modèles sans se restreindre aux hypothèses nulles.
L’A/B testing bayésien fournit P(B > A), plus actionnable que la p-valeur.
Quand les posteriors n’ont pas de forme analytique, on recourt au MCMC (chapitre suivant).