Régression linéaire simple#
La corrélation décrit une relation ; la régression la modélise. Régresse-t-on la surface habitable sur le prix d’un logement, la dose d’un médicament sur la réponse biologique, ou les heures de travail sur la performance ? Dans chaque cas, on cherche non seulement à quantifier la relation, mais à prédire, à expliquer, et à quantifier l’incertitude de ces prédictions. Ce chapitre présente la régression linéaire simple — une variable explicative — en insistant sur les diagnostics et l’interprétation.
Motivation : prédire et expliquer#
La régression linéaire simple modélise la relation entre une variable explicative (prédicteur) \(X\) et une variable réponse \(Y\) :
\(\beta_0\) : ordonnée à l’origine (valeur de \(Y\) quand \(X = 0\))
\(\beta_1\) : pente — changement moyen de \(Y\) pour une augmentation d’une unité de \(X\)
\(\varepsilon_i\) : terme d’erreur, non observable, capturant tout ce que le modèle ne prédit pas
Moindres Carrés Ordinaires (MCO)#
Intuition géométrique#
Les estimateurs MCO minimisent la somme des carrés des résidus : $\(\min_{\beta_0, \beta_1} \sum_{i=1}^n (y_i - \beta_0 - \beta_1 x_i)^2 = \min_{\beta_0, \beta_1} \|y - X\beta\|^2\)$
Les résidus \(\hat{\varepsilon}_i = y_i - \hat{y}_i\) sont les distances verticales entre les points et la droite ajustée.
Formules et propriétés BLUE#
Les estimateurs MCO sont : $\(\hat{\beta}_1 = \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^n (x_i - \bar{x})^2} = \frac{S_{XY}}{S_{XX}} \qquad \hat{\beta}_0 = \bar{y} - \hat{\beta}_1 \bar{x}\)$
Le théorème de Gauss-Markov établit que sous les hypothèses classiques (linéarité, homoscédasticité, erreurs non corrélées, \(X\) non stochastique ou exogène), les estimateurs MCO sont BLUE (Best Linear Unbiased Estimators) : ils ont la variance minimale parmi tous les estimateurs linéaires sans biais.
# Ajustement MCO avec statsmodels
model = smf.ols('prix ~ surface', data=df_immo).fit()
print(model.summary())
OLS Regression Results
==============================================================================
Dep. Variable: prix R-squared: 0.962
Model: OLS Adj. R-squared: 0.962
Method: Least Squares F-statistic: 1987.
Date: Wed, 01 Apr 2026 Prob (F-statistic): 2.99e-57
Time: 22:06:21 Log-Likelihood: -364.72
No. Observations: 80 AIC: 733.4
Df Residuals: 78 BIC: 738.2
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 38.1162 7.780 4.899 0.000 22.628 53.604
surface 3.5970 0.081 44.571 0.000 3.436 3.758
==============================================================================
Omnibus: 3.950 Durbin-Watson: 1.522
Prob(Omnibus): 0.139 Jarque-Bera (JB): 3.155
Skew: 0.411 Prob(JB): 0.207
Kurtosis: 3.520 Cond. No. 287.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
# Extraire les coefficients et leurs intervalles de confiance
beta0_est = model.params['Intercept']
beta1_est = model.params['surface']
ic_95 = model.conf_int(alpha=0.05)
print(f"\nEstimations MCO :")
print(f" β₀ = {beta0_est:.2f} (vrai : {beta_0_vrai})")
print(f" β₁ = {beta1_est:.2f} (vrai : {beta_1_vrai})")
print(f" σ̂ = {np.sqrt(model.mse_resid):.2f} (vrai : {sigma_vrai})")
print(f"\nIntervalles de confiance à 95% :")
print(f" β₀ ∈ [{ic_95.loc['Intercept', 0]:.2f}, {ic_95.loc['Intercept', 1]:.2f}]")
print(f" β₁ ∈ [{ic_95.loc['surface', 0]:.2f}, {ic_95.loc['surface', 1]:.2f}]")
Estimations MCO :
β₀ = 38.12 (vrai : 50)
β₁ = 3.60 (vrai : 3.5)
σ̂ = 23.40 (vrai : 25)
Intervalles de confiance à 95% :
β₀ ∈ [22.63, 53.60]
β₁ ∈ [3.44, 3.76]
Coefficient de détermination R²#
Le \(R^2\) mesure la proportion de variance de \(Y\) expliquée par le modèle :
ss_total = np.sum((prix - prix.mean())**2)
ss_res = np.sum(model.resid**2)
ss_reg = ss_total - ss_res
r2 = model.rsquared
r2_adj = model.rsquared_adj
print(f"Décomposition de la variance :")
print(f" SS total = {ss_total:.1f}")
print(f" SS régression= {ss_reg:.1f}")
print(f" SS résidus = {ss_res:.1f}")
print(f"\nR² = {r2:.4f} → le modèle explique {r2*100:.1f}% de la variance du prix")
print(f"R² ajusté = {r2_adj:.4f} (pénalise les paramètres superflus)")
Décomposition de la variance :
SS total = 1130398.0
SS régression= 1087691.2
SS résidus = 42706.9
R² = 0.9622 → le modèle explique 96.2% de la variance du prix
R² ajusté = 0.9617 (pénalise les paramètres superflus)
Limites du R²
Un R² élevé ne garantit pas que le modèle est correct (les résidus peuvent montrer des patterns)
Un R² faible ne signifie pas que la relation est sans intérêt pratique (en sciences sociales, R² = 0,10 peut être remarquable)
Le R² augmente mécaniquement avec le nombre de prédicteurs — utiliser le R² ajusté pour comparer des modèles
Le R² ne mesure pas la qualité des prédictions hors-échantillon
Intervalles de confiance et de prédiction#
Deux types d’intervalles répondent à des questions différentes :
IC sur la moyenne \(E[Y|X=x^*]\) : où se situe la valeur moyenne pour \(X = x^*\) ?
IP (Intervalle de Prédiction) sur une nouvelle observation \(Y^*\) : quel est le prix d”une maison spécifique de surface \(x^*\) ?
L’IP est toujours plus large que l’IC, car il incorpore l’incertitude sur la valeur individuelle en plus de l’incertitude sur la moyenne.
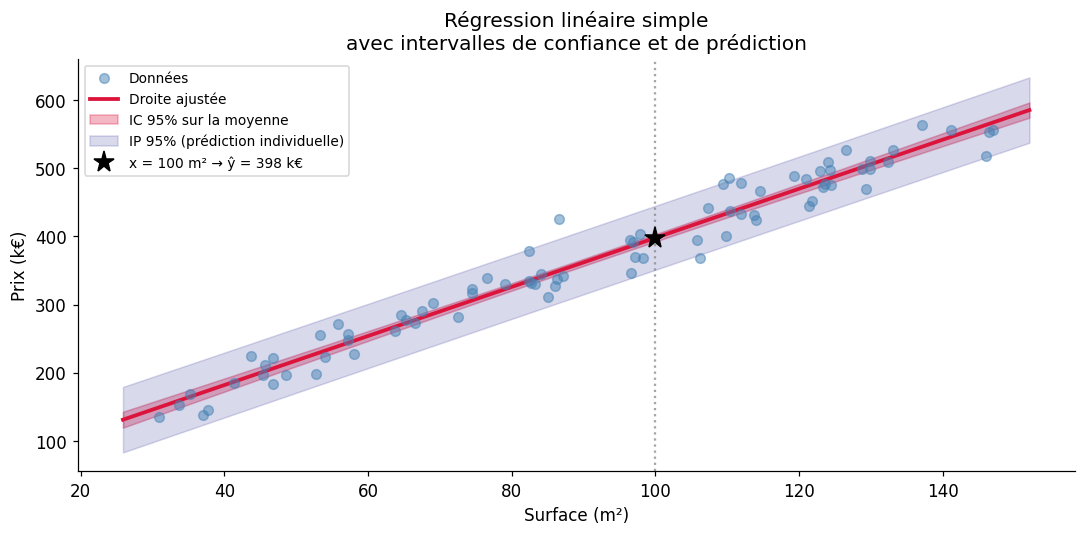
À surface = 89 m² :
Largeur IC (moyenne) = 10.4 k€
Largeur IP (individuel) = 93.8 k€
L'IP est 9.0× plus large que l'IC
Hypothèses du modèle linéaire#
Les quatre hypothèses classiques (acronyme LINE) :
Linéarité : \(E[Y|X] = \beta_0 + \beta_1 X\) (la relation est linéaire)
Indépendance : les résidus sont indépendants
Normalité : les résidus suivent \(\mathcal{N}(0, \sigma^2)\)
Egalité des variances (homoscédasticité) : \(\text{Var}(\varepsilon_i) = \sigma^2\) constant
Ces hypothèses sont testables via les diagnostics graphiques et formels.
Diagnostics graphiques#
Les quatre graphiques de diagnostic classiques révèlent les violations des hypothèses :
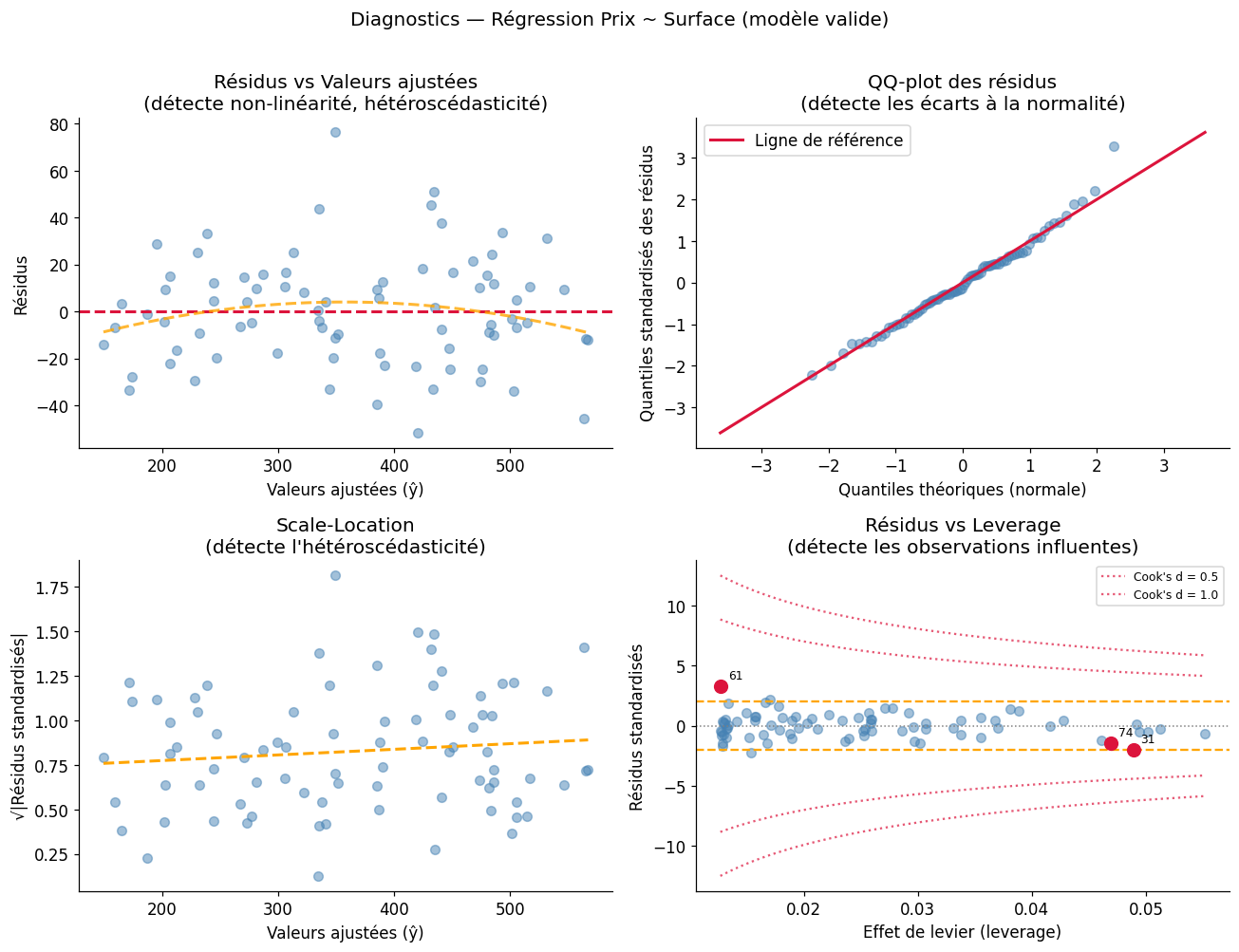
# Test formel d'homoscédasticité : Breusch-Pagan
bp_stat, bp_p, _, _ = het_breuschpagan(model.resid, model.model.exog)
print(f"Test de Breusch-Pagan (homoscédasticité) :")
print(f" χ² = {bp_stat:.3f}, p = {bp_p:.4f}")
print(f" → {'Hétéroscédasticité détectée' if bp_p < 0.05 else 'Pas d\'hétéroscédasticité détectée'}")
print()
# Test de normalité des résidus
stat_sw, p_sw = stats.shapiro(model.resid)
print(f"Test de Shapiro-Wilk sur les résidus :")
print(f" W = {stat_sw:.4f}, p = {p_sw:.4f}")
print(f" → {'Non-normalité détectée' if p_sw < 0.05 else 'Résidus compatible avec la normalité'}")
Test de Breusch-Pagan (homoscédasticité) :
χ² = 0.689, p = 0.4066
→ Pas d'hétéroscédasticité détectée
Test de Shapiro-Wilk sur les résidus :
W = 0.9868, p = 0.5850
→ Résidus compatible avec la normalité
Violations des hypothèses : exemples#
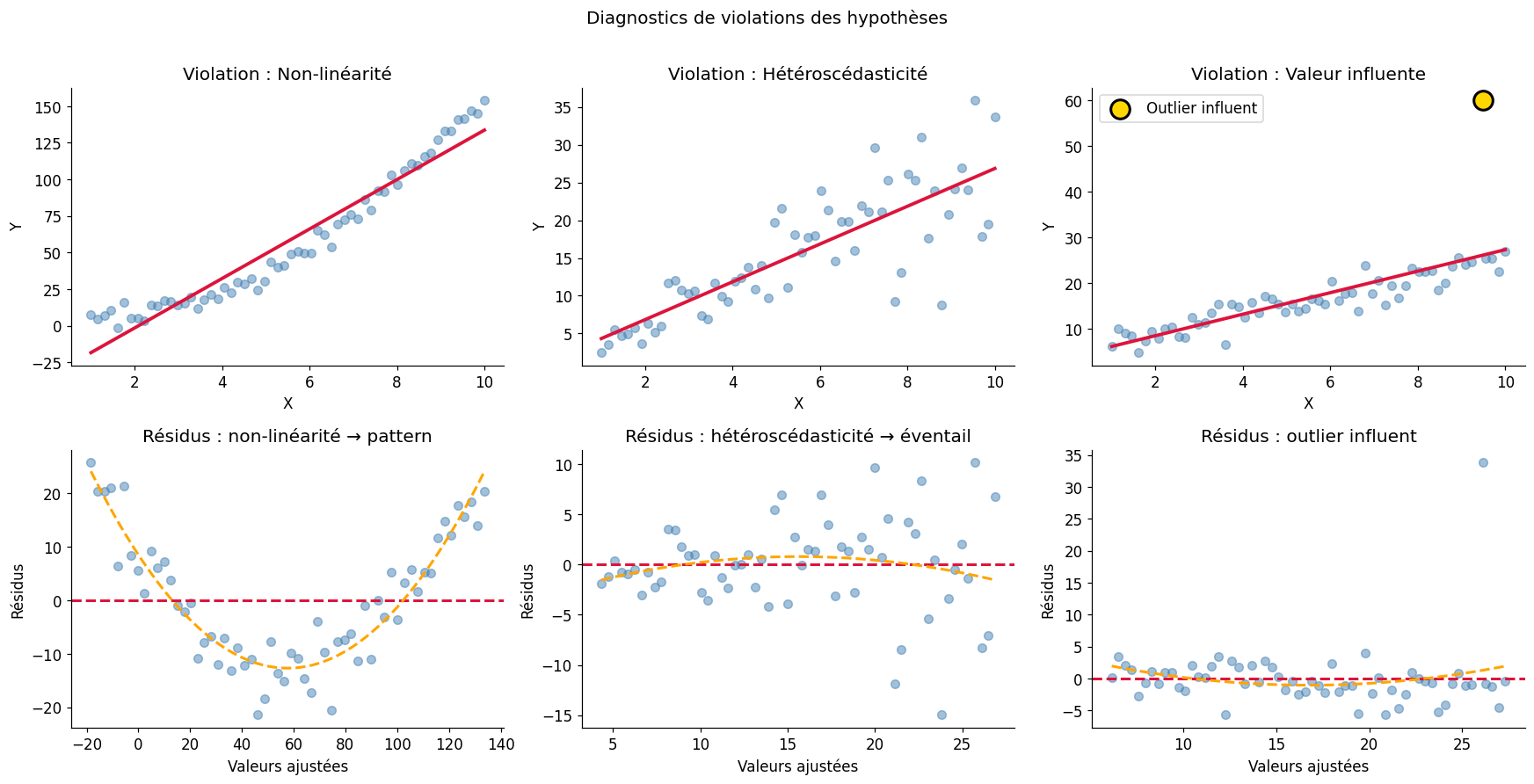
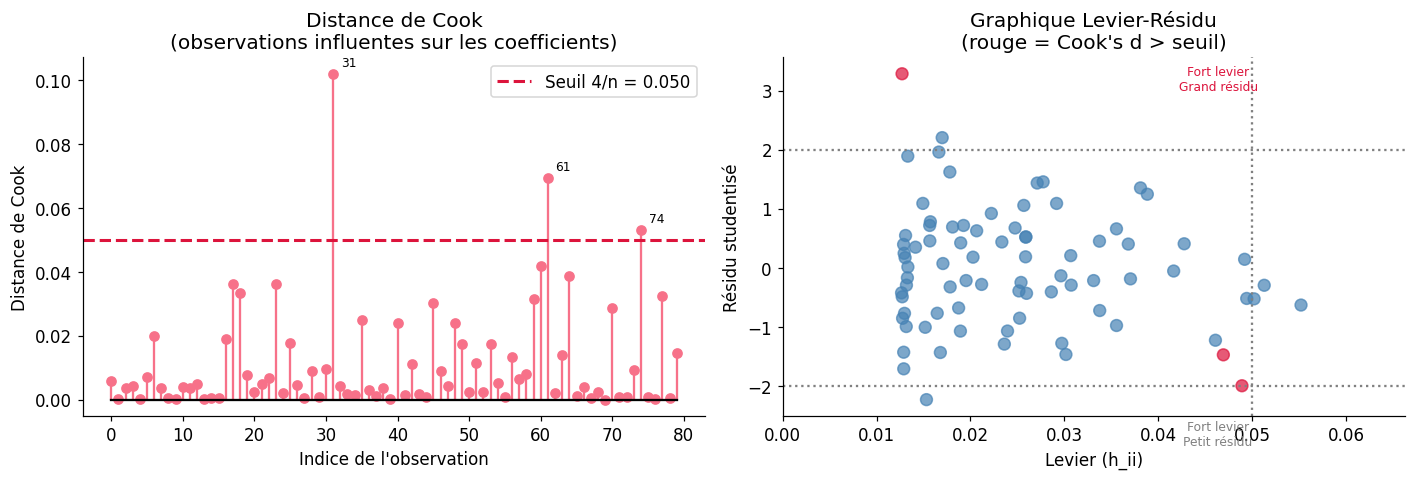
Valeurs influentes et outliers#
Effet de levier et distance de Cook#
Effet de levier \(h_{ii}\) : mesure à quel point \(x_i\) est éloigné du centre du nuage. Un \(h_{ii} > 2p/n\) est considéré comme élevé.
Distance de Cook \(D_i\) : combine le levier et le résidu standardisé. Elle mesure l’influence de l’observation \(i\) sur l’ensemble des coefficients estimés.
# Analyse des observations influentes
influence = model.get_influence()
summary_inf = influence.summary_frame()
# Identifier les cas remarquables
seuil_cook = 4 / n
seuil_leverage = 2 * 2 / n # 2p/n
obs_influentes = summary_inf[summary_inf['cooks_d'] > seuil_cook]
obs_levier = summary_inf[summary_inf['hat_diag'] > seuil_leverage]
print(f"Seuil Cook's distance : {seuil_cook:.4f}")
print(f"Seuil levier : {seuil_leverage:.4f}")
print(f"\n{len(obs_influentes)} observations avec Cook's d > seuil :")
if len(obs_influentes) > 0:
print(obs_influentes[['hat_diag', 'cooks_d', 'student_resid']].head(10))
else:
print(" Aucune")
print(f"\n{len(obs_levier)} observations à fort levier :")
print(obs_levier[['hat_diag', 'cooks_d', 'student_resid']].head(5))
Seuil Cook's distance : 0.0500
Seuil levier : 0.0500
3 observations avec Cook's d > seuil :
hat_diag cooks_d student_resid
31 0.048896 0.102039 -2.031949
61 0.012715 0.069424 3.514201
74 0.046916 0.053155 -1.480771
3 observations à fort levier :
hat_diag cooks_d student_resid
5 0.050189 0.007220 -0.520298
51 0.055183 0.011504 -0.625181
68 0.051266 0.002325 -0.291637
Analyse complète : exemple biologique#
Appliquons l’ensemble de la démarche sur un exemple biologique : concentration d’un médicament en fonction du temps après injection.
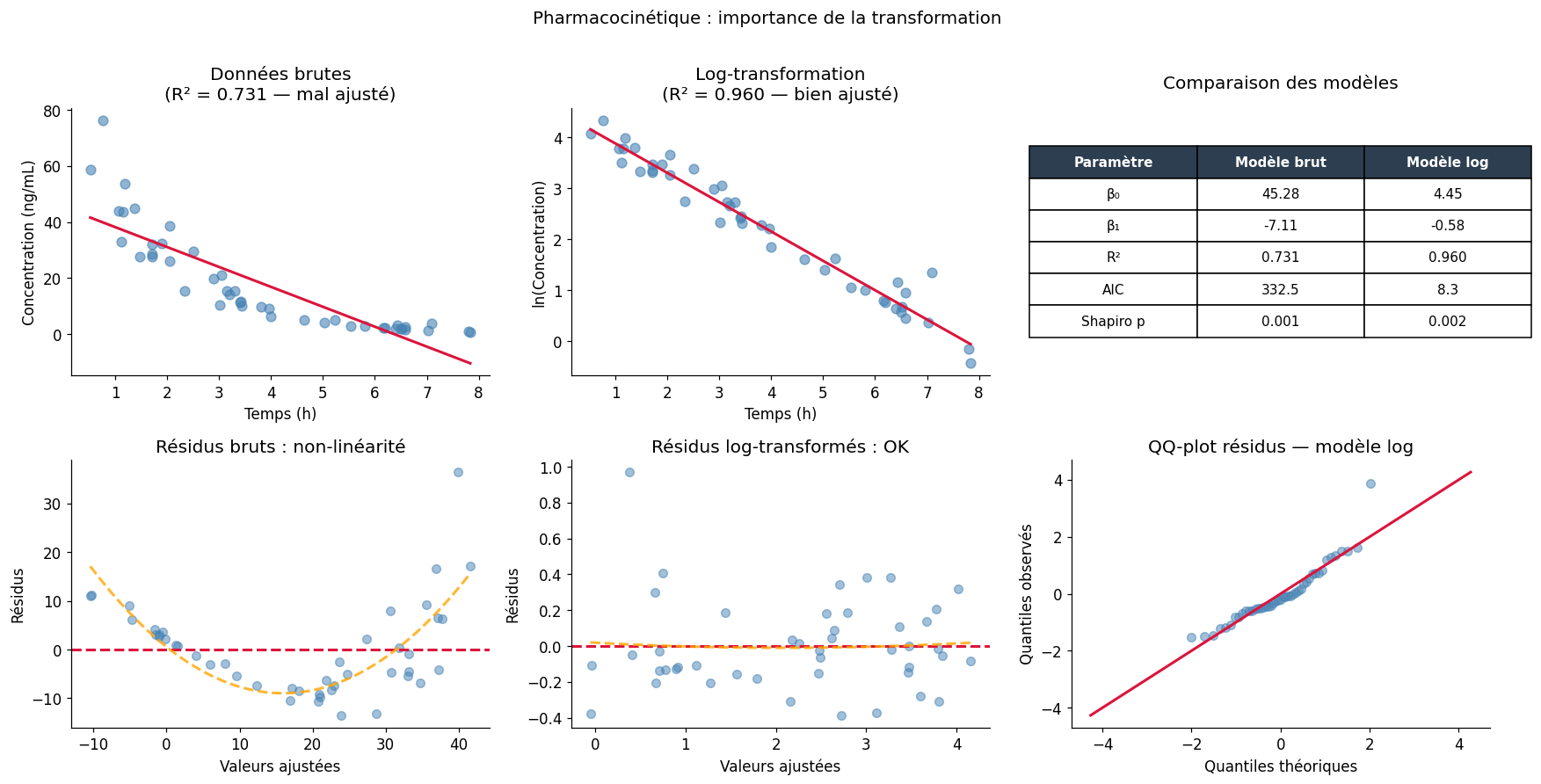
Interprétation du modèle log :
β₁ = -0.575
→ La concentration diminue de 57.5% par heure
(demi-vie estimée : 1.21h)
Checklist d’une régression linéaire simple
Explorer les données : nuage de points, corrélation, outliers évidents
Transformer si nécessaire (log, racine carrée) pour linéariser la relation
Ajuster le modèle MCO
Examiner le summary : coefficients, IC, R², test F global
Vérifier les diagnostics : résidus vs fitted, QQ-plot, scale-location, leverage
Tester formellement : Shapiro-Wilk (normalité), Breusch-Pagan (homoscédasticité)
Identifier les observations influentes (Cook’s distance, levier)
Interpréter avec IC et tailles d’effet, pas seulement p-valeurs
Distinguer IC sur la moyenne et IP sur une nouvelle observation