Modèles linéaires généralisés (GLM)#
Un seul cadre pour des réponses très différentes — comptages, proportions, coûts, durées.
Introduction#
La régression linéaire ordinaire repose sur deux hypothèses fortes : la réponse est continue et les résidus sont gaussiens homoscédastiques. En pratique, de nombreuses variables réponse violent ces hypothèses :
Comptages (nombre d’accidents, d’appels, de sinistres) : entiers positifs, asymétriques
Coûts et durées : continus mais strictement positifs et souvent très asymétriques
Proportions : bornées dans \([0, 1]\)
Les modèles linéaires généralisés (GLM, Nelder & Wedderburn, 1972) unifient régression linéaire, logistique, de Poisson et bien d’autres dans un cadre cohérent.
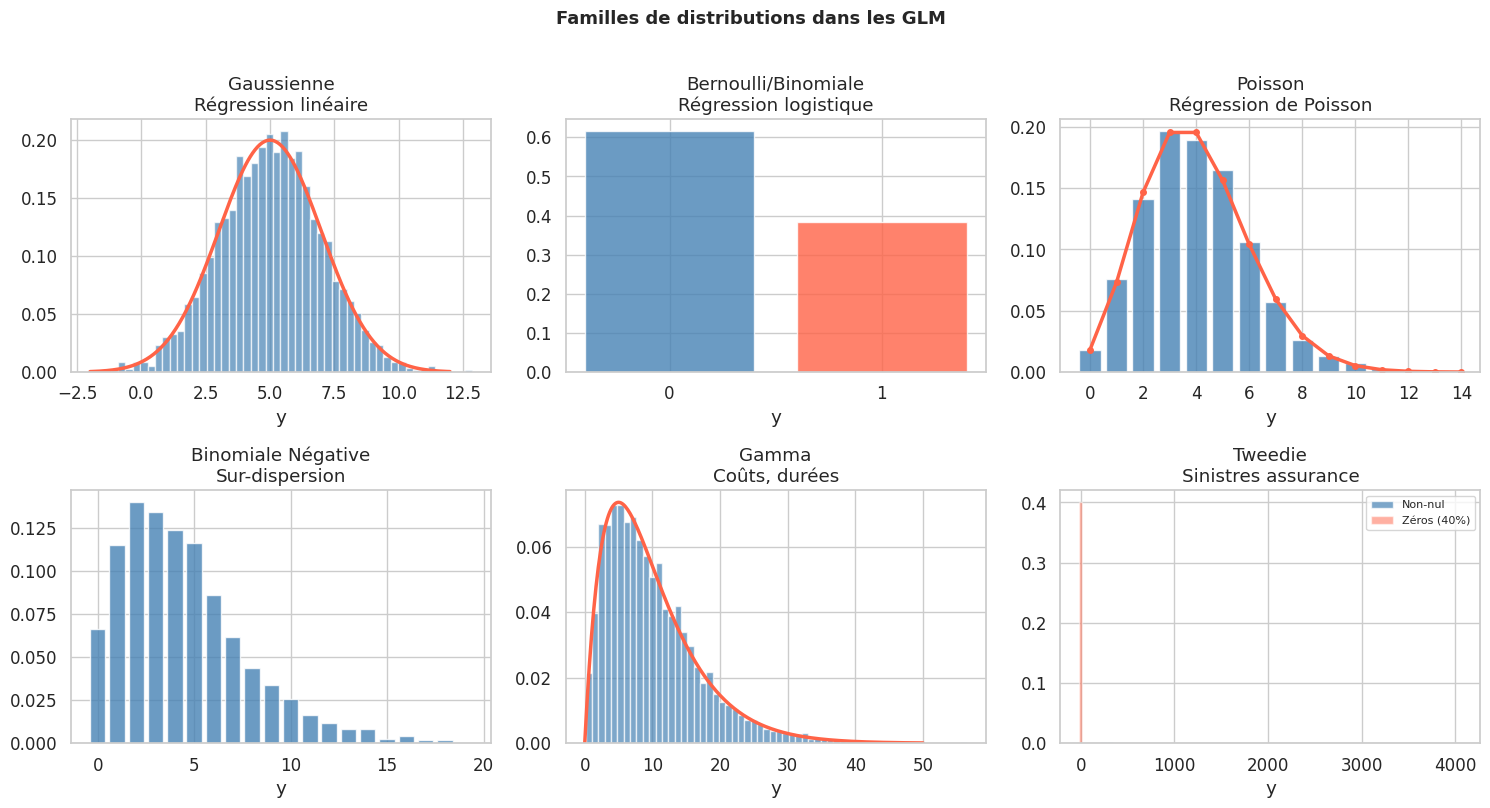
Structure d’un GLM#
Un GLM est défini par trois composantes :
1. Composante aléatoire (famille)#
La variable réponse \(Y_i\) suit une distribution de la famille exponentielle :
Les principales familles sont : Gaussienne, Binomiale, Poisson, Gamma, Gaussienne inverse, Tweedie.
2. Composante systématique (prédicteur linéaire)#
3. Fonction de lien#
La fonction de lien \(g\) relie l’espérance \(\mu_i = E[Y_i]\) au prédicteur linéaire :
Famille |
Lien canonique |
Liens alternatifs |
Usage |
|---|---|---|---|
Gaussienne |
Identité |
— |
Continu non borné |
Binomiale |
Logit |
Probit, complémentaire log-log |
Binaire/proportion |
Poisson |
Log |
Racine carrée, identité |
Comptages |
Gamma |
Inverse |
Log, identité |
Coûts, durées |
Gaussienne inverse |
Inverse carré |
Log, identité |
Extrêmement asymétrique |
Régression de Poisson : modéliser les comptages#
Modèle et interprétation#
Pour un comptage \(Y_i \sim \text{Poisson}(\mu_i)\) :
Le coefficient \(\beta_j\) représente la variation du log-espérance. L”Incidence Rate Ratio (IRR = \(e^{\beta_j}\)) est le ratio multiplicatif sur le taux attendu pour une augmentation unitaire de \(x_j\).
# Exemple : nombre d'accidents de travail
np.random.seed(2024)
n = 500
anciennete = np.random.uniform(0, 20, n) # années d'expérience
formation = np.random.binomial(1, 0.6, n) # formation reçue ou non
risque_secteur = np.random.choice([1, 2, 3], n, p=[0.4, 0.35, 0.25]) # 1=faible, 3=élevé
log_mu = (1.2
- 0.06 * anciennete
- 0.7 * formation
+ 0.5 * (risque_secteur - 1)
+ np.random.normal(0, 0.1, n))
mu = np.exp(log_mu)
accidents = np.random.poisson(mu)
df_pois = pd.DataFrame({
'accidents': accidents,
'anciennete': anciennete.round(1),
'formation': formation,
'risque_secteur': risque_secteur
})
print(f"Distribution des accidents :")
print(df_pois['accidents'].describe())
print(f"\nVariance / Moyenne = {df_pois['accidents'].var():.2f} / {df_pois['accidents'].mean():.2f}"
f" = {df_pois['accidents'].var()/df_pois['accidents'].mean():.2f}")
print("(ratio proche de 1 → Poisson bien ajusté)")
Distribution des accidents :
count 500.000000
mean 2.226000
std 2.181844
min 0.000000
25% 1.000000
50% 2.000000
75% 3.000000
max 11.000000
Name: accidents, dtype: float64
Variance / Moyenne = 4.76 / 2.23 = 2.14
(ratio proche de 1 → Poisson bien ajusté)
# Modèle Poisson avec statsmodels
model_pois = smf.glm(
'accidents ~ anciennete + formation + C(risque_secteur)',
data=df_pois,
family=sm.families.Poisson()
).fit()
print(model_pois.summary())
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: accidents No. Observations: 500
Model: GLM Df Residuals: 495
Model Family: Poisson Df Model: 4
Link Function: Log Scale: 1.0000
Method: IRLS Log-Likelihood: -831.05
Date: Wed, 01 Apr 2026 Deviance: 583.04
Time: 20:38:57 Pearson chi2: 509.
No. Iterations: 5 Pseudo R-squ. (CS): 0.5992
Covariance Type: nonrobust
==========================================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------------------
Intercept 1.3077 0.080 16.252 0.000 1.150 1.465
C(risque_secteur)[T.2] 0.5076 0.080 6.366 0.000 0.351 0.664
C(risque_secteur)[T.3] 1.0552 0.077 13.760 0.000 0.905 1.206
anciennete -0.0738 0.006 -12.996 0.000 -0.085 -0.063
formation -0.6985 0.061 -11.543 0.000 -0.817 -0.580
==========================================================================================
# IRR avec intervalles de confiance
conf_pois = model_pois.conf_int()
irr = pd.DataFrame({
'IRR': np.exp(model_pois.params),
'IRR_IC_inf': np.exp(conf_pois[0]),
'IRR_IC_sup': np.exp(conf_pois[1]),
'p_valeur': model_pois.pvalues
})
print("Incidence Rate Ratios :")
print(irr.round(4))
Incidence Rate Ratios :
IRR IRR_IC_inf IRR_IC_sup p_valeur
Intercept 3.6978 3.1583 4.3294 0.0
C(risque_secteur)[T.2] 1.6613 1.4209 1.9423 0.0
C(risque_secteur)[T.3] 2.8727 2.4718 3.3386 0.0
anciennete 0.9289 0.9186 0.9393 0.0
formation 0.4973 0.4417 0.5600 0.0
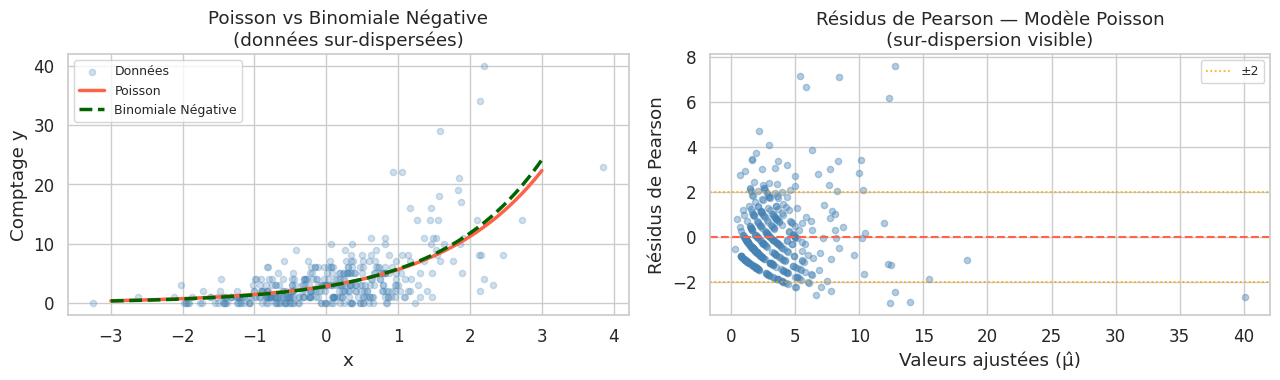
Sur-dispersion et binomiale négative#
L’hypothèse fondamentale de Poisson est \(\text{Var}(Y) = E[Y]\) (équidispersion). En pratique, les comptages réels ont souvent \(\text{Var}(Y) > E[Y]\) : c’est la sur-dispersion.
# Simuler un jeu de données sur-dispersé
np.random.seed(42)
n_od = 400
x_od = np.random.normal(0, 1, n_od)
# Sur-dispersion via mélange (paramètre de dispersion r = 3)
mu_od = np.exp(1.0 + 0.8 * x_od)
r_od = 3 # paramètre de dispersion
p_od = r_od / (r_od + mu_od)
y_od = np.random.negative_binomial(r_od, p_od, n_od)
df_od = pd.DataFrame({'y': y_od, 'x': x_od})
print(f"Variance / Moyenne = {y_od.var():.1f} / {y_od.mean():.1f} = {y_od.var()/y_od.mean():.1f}")
print("(ratio >> 1 → sur-dispersion !!)")
# Comparer Poisson vs Binomiale Négative
model_pois_od = smf.glm('y ~ x', data=df_od, family=sm.families.Poisson()).fit()
model_nb = smf.glm('y ~ x', data=df_od,
family=sm.families.NegativeBinomial()).fit()
print(f"\nAIC Poisson : {model_pois_od.aic:.1f}")
print(f"AIC Binomiale Neg. : {model_nb.aic:.1f}")
print(f"(AIC plus bas = meilleur ajustement)")
Variance / Moyenne = 21.4 / 3.6 = 5.9
(ratio >> 1 → sur-dispersion !!)
AIC Poisson : 1960.7
AIC Binomiale Neg. : 1786.8
(AIC plus bas = meilleur ajustement)
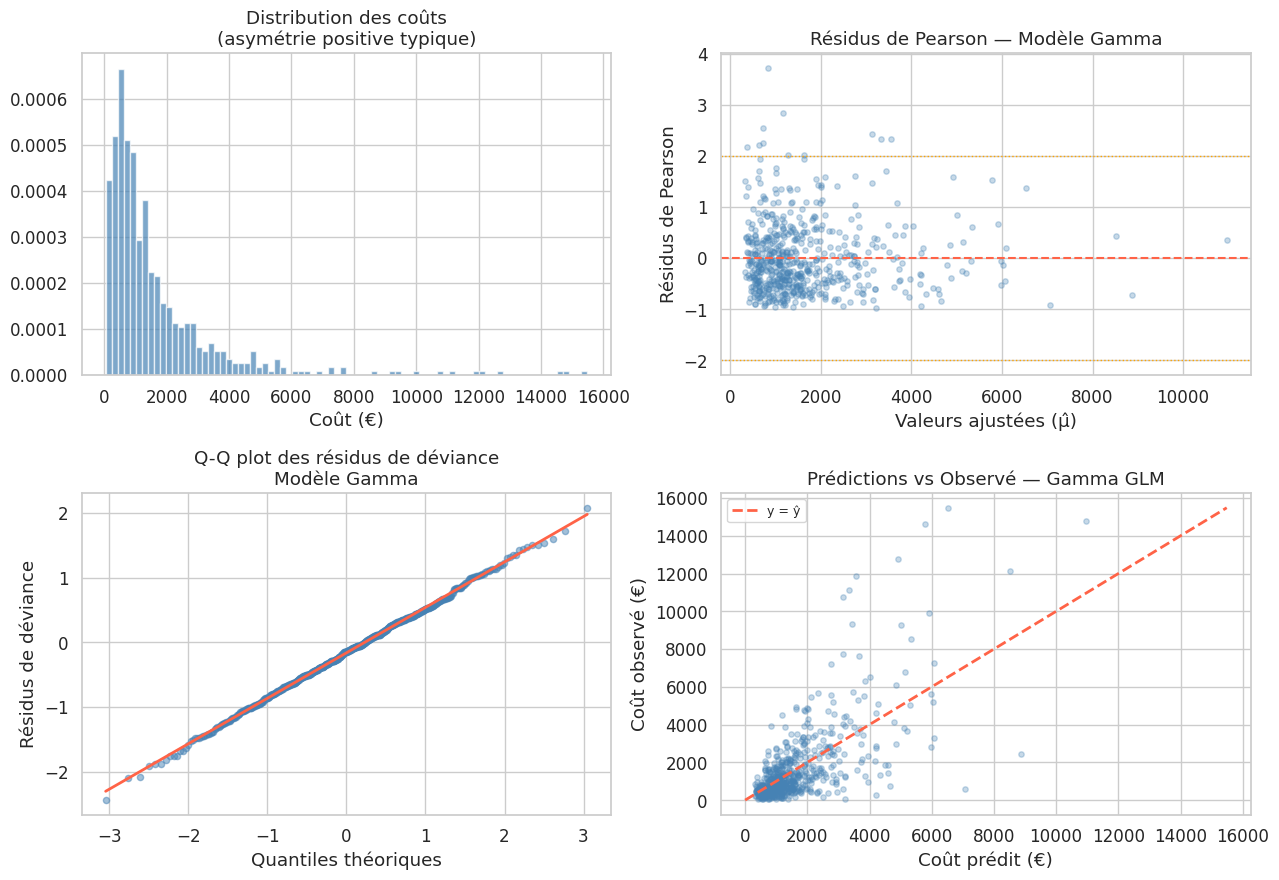
Régression Gamma : coûts et durées#
La loi Gamma est adaptée aux variables continues, strictement positives et asymétriques (coûts médicaux, durées de vie, primes d’assurance). Elle peut prendre des formes exponentielles, peaked ou très asymétriques selon ses paramètres.
# Exemple : modéliser des coûts hospitaliers
np.random.seed(2024)
n_gamma = 600
age_pat = np.random.uniform(20, 80, n_gamma)
comorbidites = np.random.poisson(1.5, n_gamma)
urgence = np.random.binomial(1, 0.3, n_gamma)
# Coût log-linéaire avec distribution Gamma
log_mu_cout = (6.5
+ 0.02 * (age_pat - 50)
+ 0.3 * comorbidites
+ 0.8 * urgence
+ np.random.normal(0, 0.1, n_gamma))
mu_cout = np.exp(log_mu_cout)
# Gamma(shape=2) : coûts avec variance = mu²/2
shape_cout = 2.0
cout = np.random.gamma(shape_cout, mu_cout / shape_cout)
df_gamma = pd.DataFrame({
'cout': cout.round(2),
'age': age_pat.round(1),
'comorbidites': comorbidites,
'urgence': urgence
})
print(f"Coût médian : {np.median(cout):.0f} €")
print(f"Coût moyen : {cout.mean():.0f} €")
print(f"Skewness : {stats.skew(cout):.2f}")
Coût médian : 1003 €
Coût moyen : 1651 €
Skewness : 3.40
# Modèle Gamma avec lien log
model_gamma = smf.glm(
'cout ~ age + comorbidites + urgence',
data=df_gamma,
family=sm.families.Gamma(link=sm.families.links.Log())
).fit()
print(model_gamma.summary())
# Comparaison avec OLS sur log(cout)
model_ols_log = smf.ols('np.log(cout) ~ age + comorbidites + urgence',
data=df_gamma).fit()
print(f"\nComparaison AIC :")
print(f" Gamma GLM : {model_gamma.aic:.1f}")
print(f" OLS log(y): {model_ols_log.aic:.1f}")
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: cout No. Observations: 600
Model: GLM Df Residuals: 596
Model Family: Gamma Df Model: 3
Link Function: Log Scale: 0.47638
Method: IRLS Log-Likelihood: -4826.2
Date: Wed, 01 Apr 2026 Deviance: 309.97
Time: 20:38:58 Pearson chi2: 284.
No. Iterations: 14 Pseudo R-squ. (CS): 0.6298
Covariance Type: nonrobust
================================================================================
coef std err z P>|z| [0.025 0.975]
--------------------------------------------------------------------------------
Intercept 5.3493 0.097 55.129 0.000 5.159 5.540
age 0.0226 0.002 13.387 0.000 0.019 0.026
comorbidites 0.2863 0.023 12.410 0.000 0.241 0.332
urgence 0.8500 0.062 13.612 0.000 0.728 0.972
================================================================================
Comparaison AIC :
Gamma GLM : 9660.5
OLS log(y): 1421.3
Déviance et AIC pour les GLM#
En régression linéaire, le \(R^2\) mesure la part de variance expliquée. Pour les GLM, on utilise la déviance :
Déviance nulle : modèle sans prédicteur (intercept seul)
Déviance résiduelle : modèle ajusté
\(R^2\) de McFadden : \(1 - D_{\text{résid}}/D_{\text{nulle}}\)
Le critère d’information d’Akaike (AIC) permet la comparaison de modèles :
# Comparaison de modèles par AIC
models_compare = {
'Intercepte seul': smf.glm('accidents ~ 1', data=df_pois, family=sm.families.Poisson()).fit(),
'Ancienneté': smf.glm('accidents ~ anciennete', data=df_pois, family=sm.families.Poisson()).fit(),
'Ancienneté + Formation': smf.glm('accidents ~ anciennete + formation', data=df_pois,
family=sm.families.Poisson()).fit(),
'Modèle complet': model_pois
}
comparaison = pd.DataFrame({
'AIC': {k: v.aic for k, v in models_compare.items()},
'Déviance résid.': {k: v.deviance for k, v in models_compare.items()},
'df résid.': {k: v.df_resid for k, v in models_compare.items()}
})
print("Comparaison de modèles GLM Poisson :")
print(comparaison.round(2))
Comparaison de modèles GLM Poisson :
AIC Déviance résid. df résid.
Intercepte seul 2121.24 1040.19 499
Ancienneté 1998.53 915.48 498
Ancienneté + Formation 1866.94 781.89 497
Modèle complet 1672.09 583.04 495
Quasi-vraisemblance et correction de sur-dispersion#
Quand la sur-dispersion est modérée, on peut ajuster les erreurs standard sans changer la famille via la quasi-vraisemblance :
# Quasi-Poisson : même estimation, erreurs standard corrigées
model_qpois = smf.glm(
'accidents ~ anciennete + formation + C(risque_secteur)',
data=df_pois,
family=sm.families.Poisson()
).fit(cov_type='HC3') # erreurs robustes
# Comparaison des erreurs standard
se_pois = model_pois.bse
se_qpois = model_qpois.bse
print("Comparaison des erreurs standard :")
print(pd.DataFrame({
'SE Poisson': se_pois,
'SE Quasi-Poisson (robuste)': se_qpois,
'Ratio': se_qpois / se_pois
}).round(4))
Comparaison des erreurs standard :
SE Poisson SE Quasi-Poisson (robuste) Ratio
Intercept 0.0805 0.0745 0.9262
C(risque_secteur)[T.2] 0.0797 0.0795 0.9972
C(risque_secteur)[T.3] 0.0767 0.0745 0.9720
anciennete 0.0057 0.0060 1.0530
formation 0.0605 0.0621 1.0262
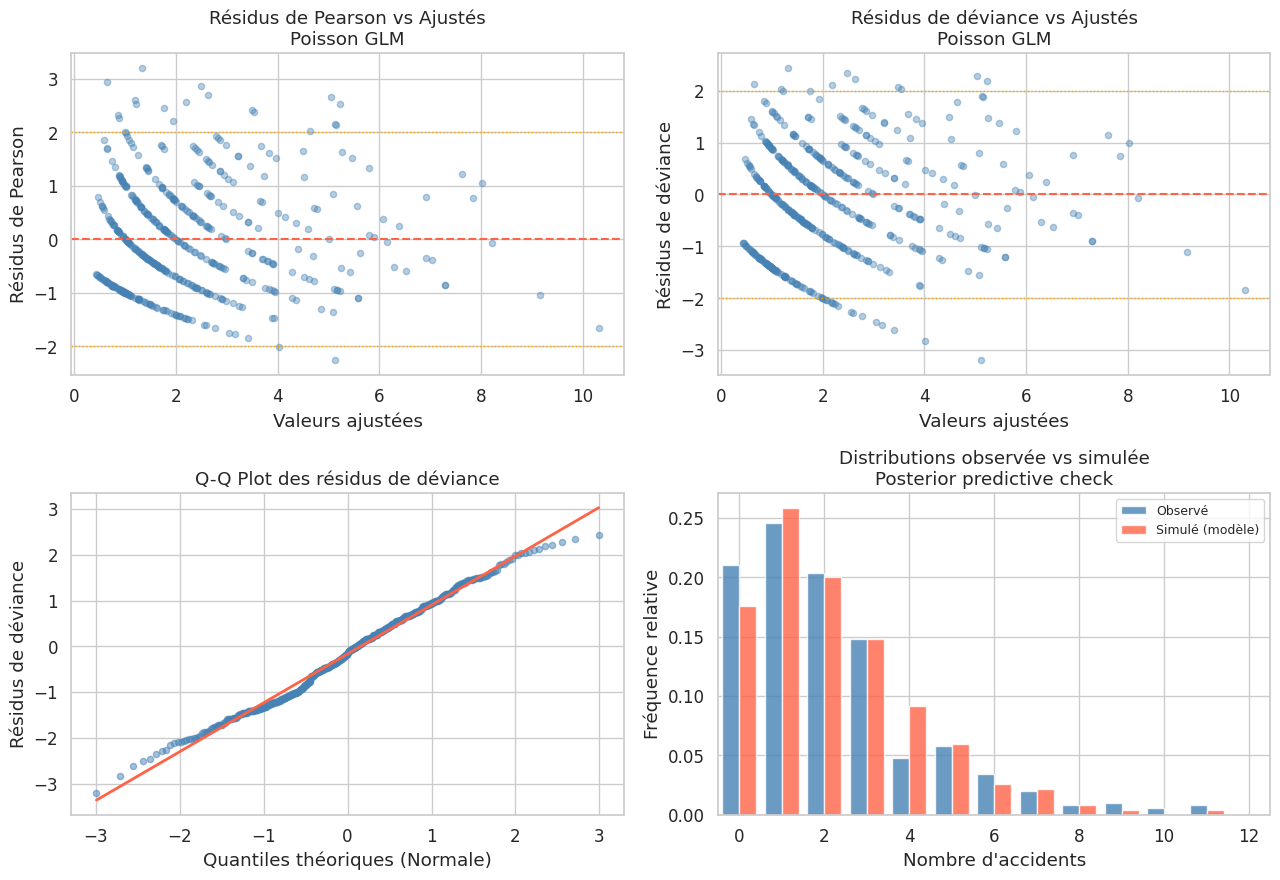
Diagnostics GLM complets#
Régression de Tweedie#
La distribution de Tweedie est une famille générale paramétrisée par un indice de puissance \(p\) :
Paramètre p |
Distribution |
|---|---|
\(p = 0\) |
Gaussienne |
\(p = 1\) |
Poisson |
\(1 < p < 2\) |
Tweedie compound (mélange Poisson-Gamma) |
\(p = 2\) |
Gamma |
\(p = 3\) |
Gaussienne inverse |
# Modèle Tweedie pour sinistres assurance
np.random.seed(42)
n_tw = 700
prime = np.random.lognormal(6, 0.4, n_tw) # prime annuelle
anciennete_contrat = np.random.uniform(0, 10, n_tw)
age_conducteur = np.random.uniform(18, 75, n_tw)
log_mu_tw = (4.5
+ 0.3 * np.log(prime / 500)
- 0.02 * anciennete_contrat
+ 0.01 * np.abs(age_conducteur - 40))
mu_tw = np.exp(log_mu_tw)
# Tweedie p=1.5 : mélange Poisson-Gamma
n_sinistres = np.random.poisson(mu_tw / 200)
sinistre_total = np.array([
np.random.gamma(2, 100, max(ns, 0)).sum() if ns > 0 else 0.0
for ns in n_sinistres
])
df_tw = pd.DataFrame({
'sinistre': sinistre_total,
'log_prime': np.log(prime),
'anciennete': anciennete_contrat,
'age': age_conducteur
})
print(f"Proportion zéros : {(sinistre_total == 0).mean():.1%}")
print(f"Montant médian (non-nuls) : {sinistre_total[sinistre_total > 0].mean():.0f} €")
model_tw = smf.glm(
'sinistre ~ log_prime + anciennete + age',
data=df_tw,
family=sm.families.Tweedie(var_power=1.5, link=sm.families.links.Log())
).fit()
print(f"\nAIC Tweedie : {model_tw.aic:.1f}")
print(model_tw.params.round(4))
Proportion zéros : 65.4%
Montant médian (non-nuls) : 244 €
AIC Tweedie : 4083.4
Intercept 2.1735
log_prime 0.3748
anciennete -0.0198
age 0.0021
dtype: float64
Résumé comparatif#
Choisir la bonne famille GLM
Réponse |
Famille |
Lien |
Paramètre |
|---|---|---|---|
Continu non borné |
Gaussienne |
Identité |
σ² |
Binaire (0/1) |
Binomiale |
Logit |
— |
Comptage (Var ≈ µ) |
Poisson |
Log |
— |
Comptage (Var >> µ) |
Binomiale Négative |
Log |
r (dispersion) |
Continu positif asymétrique |
Gamma |
Log |
φ (dispersion) |
Mélange zéros + continu |
Tweedie |
Log |
p (puissance) |
Règle pratique : commencer par visualiser la distribution de la réponse, calculer ratio Var/Moyenne, puis choisir la famille. Valider avec les résidus de Pearson et un Q-Q plot.
# Tableau récapitulatif avec test de sur-dispersion pour Poisson
from scipy.stats import chi2
deviance = model_pois.deviance
df_res = model_pois.df_resid
ratio_dispers = deviance / df_res
print(f"Test de sur-dispersion (Poisson) :")
print(f" Déviance résiduelle : {deviance:.1f}")
print(f" Degrés de liberté : {df_res}")
print(f" Ratio (D/df) : {ratio_dispers:.3f}")
print(f" p-valeur : {chi2.sf(deviance, df_res):.4f}")
if ratio_dispers > 1.5:
print(" → Possible sur-dispersion, envisager Binomiale Négative ou Quasi-Poisson")
else:
print(" → Pas de sur-dispersion significative, Poisson convenable")
Test de sur-dispersion (Poisson) :
Déviance résiduelle : 583.0
Degrés de liberté : 495
Ratio (D/df) : 1.178
p-valeur : 0.0038
→ Pas de sur-dispersion significative, Poisson convenable