Statistiques descriptives#
Les statistiques descriptives ont un objectif modeste en apparence — résumer un jeu de données en quelques chiffres ou graphiques — mais cet objectif est en réalité fondamental. Avant tout test, toute modélisation, toute inférence, il faut comprendre ses données : leur forme, leurs valeurs atypiques, leur dispersion, leur asymétrie. Un modèle appliqué à des données mal comprises produit des résultats mal compris. Ce chapitre couvre les outils essentiels pour explorer des données numériques, en partant d’un jeu de données concret et en progressant vers les diagnostics avancés.
Un jeu de données réaliste : salaires dans une entreprise#
Imaginons une entreprise de 500 employés. Les salaires annuels (en milliers d’euros) suivent une distribution réaliste : la grande majorité tourne autour de 35 à 60 k€, avec quelques cadres supérieurs et dirigeants qui tirent la queue droite vers le haut.
# Génération de salaires réalistes : mélange de deux populations
n_employes = 400
n_cadres = 80
n_dirigeants = 20
salaires_employes = rng.normal(loc=38, scale=8, size=n_employes)
salaires_cadres = rng.normal(loc=65, scale=12, size=n_cadres)
salaires_dirigeants = rng.normal(loc=130, scale=30, size=n_dirigeants)
salaires = np.concatenate([salaires_employes, salaires_cadres, salaires_dirigeants])
salaires = np.clip(salaires, 22, 350) # salaires plausibles
departements = (
["Technique"] * 150 + ["Ventes"] * 120 + ["RH"] * 80 + ["Finance"] * 50 +
["Technique"] * 30 + ["Ventes"] * 20 + ["Finance"] * 20 + ["RH"] * 10 +
["Direction"] * 20
)
df = pd.DataFrame({
"salaire": salaires,
"departement": departements,
"anciennete": rng.integers(1, 25, size=500),
"age": np.clip(rng.normal(38, 9, 500).astype(int), 22, 62),
})
print(df.shape)
df.head()
(500, 4)
| salaire | departement | anciennete | age | |
|---|---|---|---|---|
| 0 | 40.437737 | Technique | 10 | 48 |
| 1 | 29.680127 | Technique | 9 | 28 |
| 2 | 44.003610 | Technique | 18 | 22 |
| 3 | 45.524518 | Technique | 4 | 38 |
| 4 | 22.391718 | Technique | 6 | 46 |
Tendance centrale : quelle est la valeur « typique » ?#
Trois mesures coexistent pour résumer le centre d’une distribution. Elles coïncident pour une distribution symétrique, mais divergent dès qu’apparaît de l’asymétrie ou des valeurs aberrantes.
La moyenne arithmétique \(\bar{x} = \frac{1}{n}\sum_{i=1}^n x_i\) est sensible à tous les points, y compris les extrêmes. Elle minimise la somme des carrés des écarts.
La médiane est la valeur qui partage l’échantillon en deux moitiés égales. Elle est robuste aux outliers : on peut multiplier le salaire du PDG par dix sans déplacer la médiane d’un centime.
Le mode est la valeur la plus fréquente. Utile pour des données catégorielles ou discrètes ; pour des données continues, on parle plutôt de pic de la densité estimée.
moyenne = df["salaire"].mean()
mediane = df["salaire"].median()
mode_val = float(stats.mode(df["salaire"].round(), keepdims=True).mode[0])
print(f"Moyenne : {moyenne:.1f} k€")
print(f"Médiane : {mediane:.1f} k€")
print(f"Mode (arrondi) : {mode_val:.0f} k€")
print(f"Écart moyenne-médiane : {moyenne - mediane:.1f} k€ → asymétrie droite")
Moyenne : 45.8 k€
Médiane : 40.2 k€
Mode (arrondi) : 35 k€
Écart moyenne-médiane : 5.6 k€ → asymétrie droite
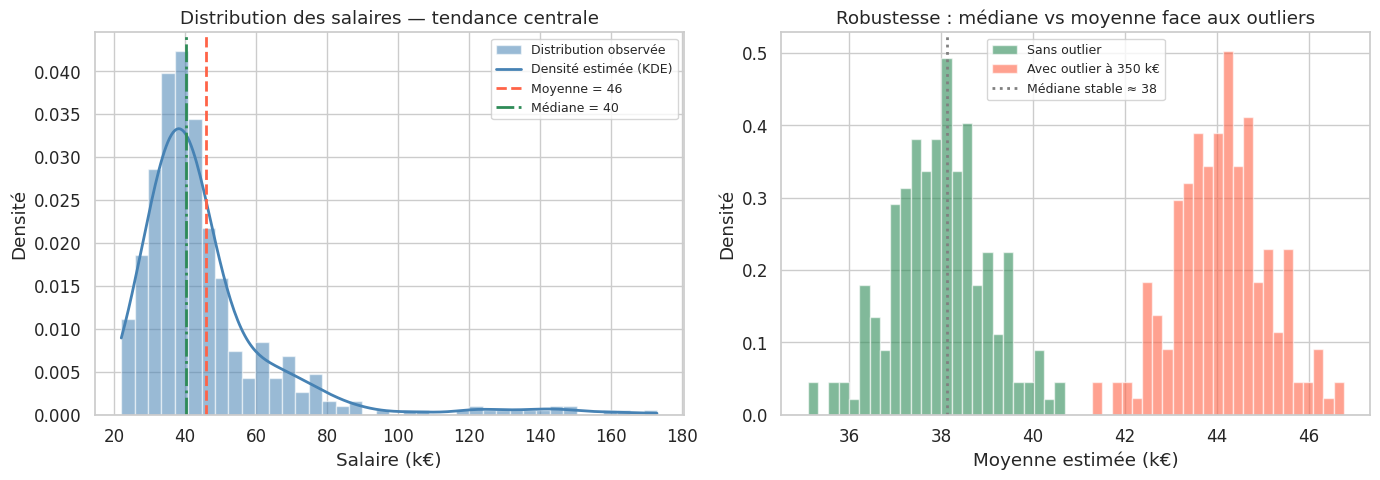
La figure de droite illustre un fait fondamental : la moyenne fluctue énormément en présence d’un seul outlier, alors que la médiane reste stable. Pour des données salariales, il est donc préférable de rapporter la médiane comme mesure de tendance centrale.
Règle pratique
Choisissez la médiane dès que la distribution est asymétrique ou contient des valeurs aberrantes probables : revenus, prix immobiliers, durées de vie, tailles de fichiers. Réservez la moyenne aux distributions approximativement symétriques et bornées.
Dispersion : à quel point les valeurs s’étalent-elles ?#
La dispersion mesure la variabilité. Connaître la tendance centrale sans la dispersion ne suffit pas : deux entreprises peuvent avoir la même masse salariale médiane avec des inégalités très différentes.
Variance et écart-type. La variance \(s^2 = \frac{1}{n-1}\sum (x_i - \bar{x})^2\) est la moyenne des carrés des écarts à la moyenne (divisée par \(n-1\) pour l’estimateur sans biais). L’écart-type \(s\) est sa racine carrée, dans la même unité que les données.
IQR (interquartile range). L’IQR = Q3 − Q1 est la longueur de la boîte du boxplot. Il mesure l’étendue des 50 % centraux et est insensible aux valeurs extrêmes.
MAD (median absolute deviation). \(\text{MAD} = \text{médiane}(|x_i - \text{médiane}(x)|)\). Encore plus robuste que l’IQR, c’est l’estimateur de dispersion de référence pour les données contaminées. On le normalise parfois par 1,4826 pour l’aligner sur l’écart-type d’une gaussienne.
s = df["salaire"]
variance = s.var() # ddof=1 par défaut dans pandas
ecart_type = s.std()
iqr = s.quantile(0.75) - s.quantile(0.25)
mad = stats.median_abs_deviation(s)
mad_normalise = stats.median_abs_deviation(s, scale="normal") # ≈ σ pour gaussienne
print(f"Variance : {variance:.1f} k€²")
print(f"Écart-type : {ecart_type:.1f} k€")
print(f"IQR : {iqr:.1f} k€")
print(f"MAD : {mad:.1f} k€")
print(f"MAD normalisé : {mad_normalise:.1f} k€ (comparable à l'écart-type)")
print(f"\nRatio σ/MAD_norm : {ecart_type/mad_normalise:.2f} (> 1 → queue droite lourde)")
Variance : 470.2 k€²
Écart-type : 21.7 k€
IQR : 14.4 k€
MAD : 6.9 k€
MAD normalisé : 10.3 k€ (comparable à l'écart-type)
Ratio σ/MAD_norm : 2.12 (> 1 → queue droite lourde)
Le ratio écart-type / MAD normalisé supérieur à 1 indique que l’écart-type est gonflé par les valeurs extrêmes. C’est une signature d’asymétrie ou de queues lourdes.
Forme de la distribution : asymétrie et aplatissement#
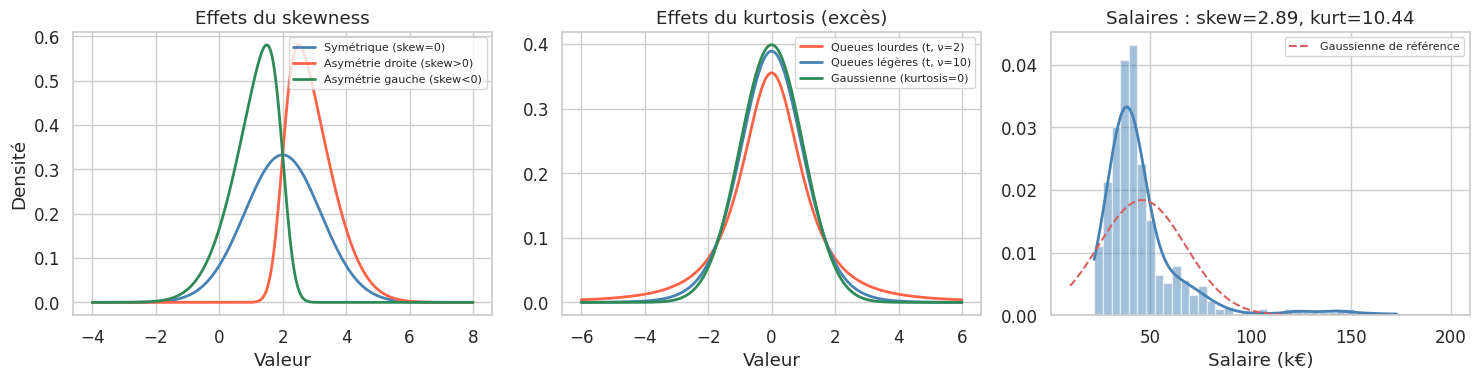
Deux distributions peuvent avoir la même moyenne et le même écart-type tout en différant radicalement de forme. Le skewness (asymétrie) et le kurtosis (aplatissement) capturent ces différences.
Skewness. Le coefficient d’asymétrie \(\gamma_1 = \frac{\mu_3}{\sigma^3}\) où \(\mu_3 = E[(X-\mu)^3]\) est le moment centré d’ordre 3. Un skewness positif signifie une queue étalée à droite (revenus, temps d’attente) ; négatif, à gauche (âge au décès dans un pays développé).
Kurtosis. Le coefficient d’aplatissement \(\gamma_2 = \frac{\mu_4}{\sigma^4} - 3\) (excès de kurtosis, nul pour la gaussienne). Un kurtosis positif (leptokurtique) indique des queues plus épaisses et un pic plus prononcé que la normale. Attention : scipy.stats.kurtosis retourne l’excès de kurtosis par défaut.
skewness = stats.skew(df["salaire"])
kurt = stats.kurtosis(df["salaire"]) # excès de kurtosis
print(f"Skewness : {skewness:.3f}")
print(f"Kurtosis (excès) : {kurt:.3f}")
print()
print("Interprétation :")
print(f" → Skewness {skewness:.2f} > 0 : queue droite étalée (salaires élevés rares mais présents)")
print(f" → Kurtosis {kurt:.2f} > 0 : queues plus lourdes qu'une gaussienne")
Skewness : 2.895
Kurtosis (excès) : 10.444
Interprétation :
→ Skewness 2.89 > 0 : queue droite étalée (salaires élevés rares mais présents)
→ Kurtosis 10.44 > 0 : queues plus lourdes qu'une gaussienne
Quantiles, percentiles et boxplot#
Les quantiles découpent la distribution en tranches d’égale probabilité. Le quantile d’ordre \(p\) est la valeur \(Q_p\) telle que \(P(X \leq Q_p) = p\). Les quartiles (\(Q_{0.25}\), \(Q_{0.5}\), \(Q_{0.75}\)) sont les plus utilisés.
Le boxplot (boîte à moustaches) résume une distribution en cinq chiffres : minimum, Q1, médiane, Q3, maximum — avec un traitement visuel des outliers. La moustache s’étend jusqu’à \(\text{Q1} - 1{,}5 \times \text{IQR}\) (en bas) et \(\text{Q3} + 1{,}5 \times \text{IQR}\) (en haut). Les points au-delà sont tracés individuellement.
quantiles = df["salaire"].quantile([0.1, 0.25, 0.5, 0.75, 0.9, 0.95, 0.99])
print("Quantiles des salaires :")
for q, v in quantiles.items():
print(f" P{int(q*100):2d} : {v:.1f} k€")
Quantiles des salaires :
P10 : 29.1 k€
P25 : 34.4 k€
P50 : 40.2 k€
P75 : 48.7 k€
P90 : 68.8 k€
P95 : 80.9 k€
P99 : 143.7 k€
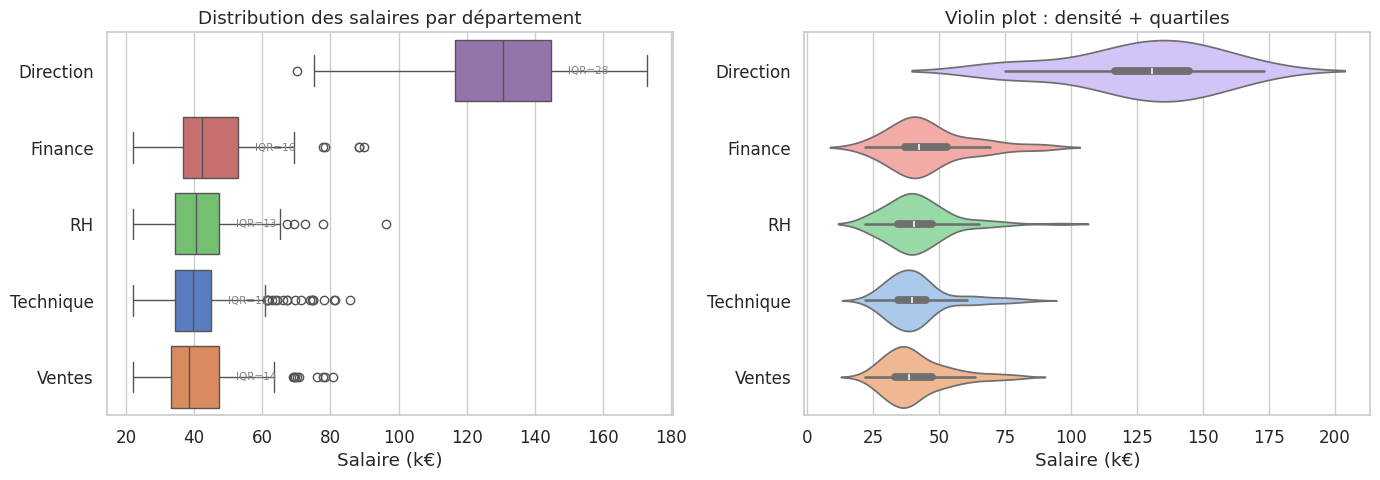
Boxplot vs violin plot
Le boxplot est lisible et compact : il fonctionne bien pour comparer beaucoup de groupes. Le violin plot montre la forme de la distribution (multimodalité, asymétrie) mais est plus difficile à lire avec de nombreux groupes. Pour une distribution bimodale, le boxplot n’en révèle rien là où le violin plot la révèle immédiatement.
Détection d’outliers#
Un outlier n’est pas forcément une erreur de mesure — c’est une valeur qui se distingue du comportement typique. Sa détection dépend du contexte et de la méthode choisie.
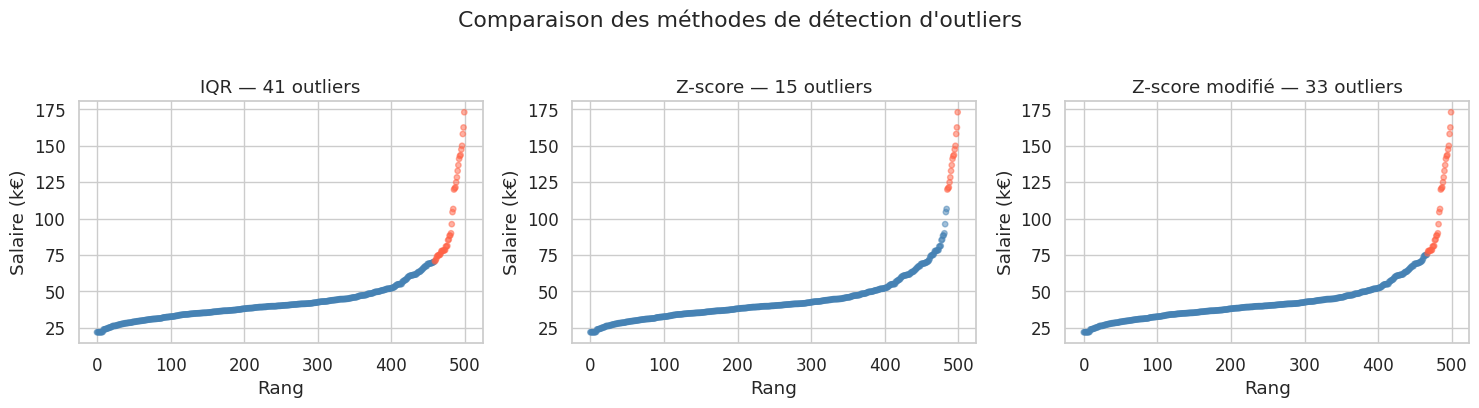
Règle de l’IQR (Tukey)#
Un point \(x\) est déclaré outlier si \(x < Q_1 - 1{,}5 \times \text{IQR}\) ou \(x > Q_3 + 1{,}5 \times \text{IQR}\). Simple et non paramétrique, cette règle est celle utilisée par défaut dans les boxplots.
Z-score classique#
\(z = \frac{x - \bar{x}}{s}\). Convention : \(|z| > 3\) signale un outlier. Cette méthode suppose une distribution approximativement gaussienne et est sensible aux outliers eux-mêmes (le masquage).
Z-score modifié (Iglewicz & Hoaglin)#
\(z_{\text{mod}} = \frac{0{,}6745 \times (x - \text{médiane})}{\text{MAD}}\). Le seuil habituel est \(|z_{\text{mod}}| > 3{,}5\). Beaucoup plus robuste : ni la médiane ni la MAD ne sont affectées par les outliers.
def detecter_outliers(x):
"""Trois méthodes de détection d'outliers."""
x = np.asarray(x)
# IQR
q1, q3 = np.percentile(x, 25), np.percentile(x, 75)
iqr_val = q3 - q1
outliers_iqr = (x < q1 - 1.5 * iqr_val) | (x > q3 + 1.5 * iqr_val)
# Z-score classique
z = np.abs(stats.zscore(x))
outliers_z = z > 3
# Z-score modifié
med = np.median(x)
mad_val = stats.median_abs_deviation(x)
z_mod = np.abs(0.6745 * (x - med) / mad_val) if mad_val > 0 else np.zeros_like(x)
outliers_zmod = z_mod > 3.5
return outliers_iqr, outliers_z, outliers_zmod
oi, oz, ozm = detecter_outliers(df["salaire"])
print(f"Méthode IQR : {oi.sum()} outliers ({oi.mean()*100:.1f}%)")
print(f"Z-score classique : {oz.sum()} outliers ({oz.mean()*100:.1f}%)")
print(f"Z-score modifié (MAD): {ozm.sum()} outliers ({ozm.mean()*100:.1f}%)")
print()
print("Outliers IQR (salaires en k€) :")
print(np.sort(df["salaire"][oi].values)[:10], "...")
Méthode IQR : 41 outliers (8.2%)
Z-score classique : 15 outliers (3.0%)
Z-score modifié (MAD): 33 outliers (6.6%)
Outliers IQR (salaires en k€) :
[70.69636506 71.25400707 72.4300534 73.9932068 74.64302023 74.84634171
74.9542285 75.05781747 76.1395639 77.76621839] ...
Isolation Forest et méthodes non paramétriques
Pour des données multivariées, les méthodes univariées sont insuffisantes : un point peut être normal sur chaque dimension séparément mais aberrant par leur combinaison. Isolation Forest (sklearn.ensemble.IsolationForest) isole les outliers en les coupant aléatoirement dans l’espace des features ; ils nécessitent moins de coupes que les points normaux. Local Outlier Factor (LOF) compare la densité locale d’un point à celle de ses voisins. Ces méthodes seront couvertes dans le livre Data Science.
Résumé complet avec describe() enrichi#
La méthode describe() de pandas donne un résumé rapide, mais elle peut être enrichie pour inclure skewness, kurtosis et MAD.
def describe_enrichi(series, nom="variable"):
"""Résumé statistique enrichi."""
s = series.dropna()
q = s.quantile
mad_v = stats.median_abs_deviation(s)
resume = {
"n": len(s),
"n_manquants": series.isna().sum(),
"min": s.min(),
"P5": q(0.05),
"Q1 (P25)": q(0.25),
"médiane": q(0.50),
"Q3 (P75)": q(0.75),
"P95": q(0.95),
"max": s.max(),
"moyenne": s.mean(),
"écart-type": s.std(),
"IQR": q(0.75) - q(0.25),
"MAD": mad_v,
"skewness": stats.skew(s),
"kurtosis (excès)": stats.kurtosis(s),
}
return pd.Series(resume, name=nom)
desc = describe_enrichi(df["salaire"], "salaire (k€)")
print(desc.to_string())
n 500.000000
n_manquants 0.000000
min 22.000000
P5 26.419083
Q1 (P25) 34.354700
médiane 40.186470
Q3 (P75) 48.742764
P95 80.852155
max 172.996435
moyenne 45.817865
écart-type 21.683401
IQR 14.388064
MAD 6.913711
skewness 2.894855
kurtosis (excès) 10.444140
Statistiques groupées#
L’analyse par groupe est une des opérations les plus fréquentes en data analyse. groupby de pandas permet de calculer n’importe quelle statistique par sous-groupe.
# Statistiques par département
stats_groupe = df.groupby("departement")["salaire"].agg([
("n", "count"),
("médiane", "median"),
("moyenne", "mean"),
("écart-type", "std"),
("IQR", lambda x: x.quantile(0.75) - x.quantile(0.25)),
("skewness", stats.skew),
("P90", lambda x: x.quantile(0.90)),
]).round(1)
print(stats_groupe.sort_values("médiane", ascending=False).to_string())
n médiane moyenne écart-type IQR skewness P90
departement
Direction 20 130.5 127.2 28.0 28.0 -0.5 158.5
Finance 70 42.2 46.3 15.6 16.1 1.0 68.8
RH 90 40.5 41.9 12.7 13.0 1.3 55.3
Technique 180 39.8 41.9 12.4 10.6 1.4 61.3
Ventes 140 38.6 41.5 12.4 14.2 1.1 58.8
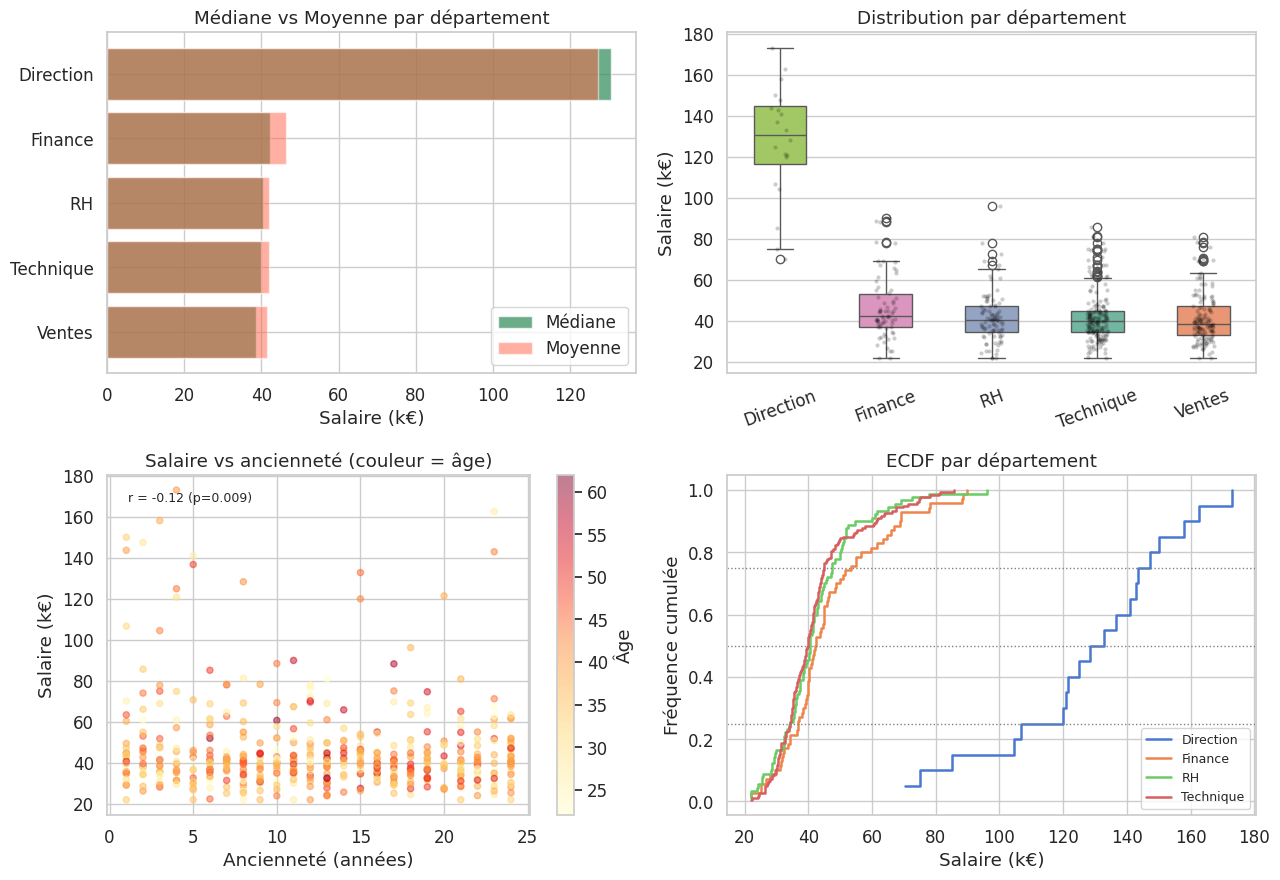
Tableau récapitulatif des mesures#
Catégorie Robustesse Quand l'utiliser
Mesure
Moyenne Tendance centrale Faible Distribution symétrique, sans outliers extrêmes
Médiane Tendance centrale Forte Distribution asymétrique, revenus, prix
Mode Tendance centrale Forte Variables discrètes, catégorielles
Variance Dispersion Faible Calculs théoriques, ANOVA
Écart-type Dispersion Faible Distribution ≈ normale
IQR Dispersion Forte Boxplots, détection d'outliers Tukey
MAD Dispersion Très forte Données contaminées, outliers probables
Skewness Forme Faible Diagnostic d'asymétrie
Kurtosis (excès) Forme Faible Diagnostic de queues lourdes
Le choix de la bonne mesure statistique n’est pas anodin. Rapporter la moyenne des salaires d’une entreprise peut être politiquement trompeur si quelques dirigeants très bien payés la tirent vers le haut — la médiane révèle alors une réalité plus fidèle. Comprendre ces nuances, c’est déjà une grande partie du travail de statisticien.