Statistiques multivariées#
La plupart des jeux de données réels comportent des dizaines, voire des centaines de variables mesurées simultanément sur les mêmes individus. Analyser ces variables une par une revient à ignorer l’information contenue dans leurs relations. Les statistiques multivariées exploitent précisément ces relations : elles décrivent la structure d’un nuage de points en grande dimension, détectent des groupes naturels, réduisent la dimensionnalité tout en préservant l’information essentielle.
Ce chapitre couvre les outils fondamentaux : la distribution normale multivariée, l’analyse en composantes principales (ACP), l’analyse factorielle des correspondances (AFC), les méthodes de clustering (k-means, clustering hiérarchique, DBSCAN), et un aperçu des méthodes de réduction de dimension modernes.
Distribution normale multivariée#
Définition et paramètres#
Un vecteur aléatoire \(\mathbf{X} = (X_1, \ldots, X_p)^\top\) suit une loi normale multivariée \(\mathcal{N}(\boldsymbol{\mu}, \boldsymbol{\Sigma})\) si sa densité est :
Les paramètres sont :
\(\boldsymbol{\mu} \in \mathbb{R}^p\) : vecteur des moyennes marginales
\(\boldsymbol{\Sigma} \in \mathbb{R}^{p \times p}\) : matrice de covariance, symétrique définie positive
La matrice de covariance \(\boldsymbol{\Sigma}\) contient sur la diagonale les variances \(\text{Var}(X_i) = \sigma_i^2\), et hors-diagonale les covariances \(\text{Cov}(X_i, X_j) = \rho_{ij}\sigma_i\sigma_j\) où \(\rho_{ij}\) est la corrélation entre \(X_i\) et \(X_j\).
Ellipses de confiance#
En dimension 2, les courbes de niveau de la densité sont des ellipses. L’ellipse à \((1 - \alpha)\)% de confiance est l’ensemble des points \(\mathbf{x}\) vérifiant :
où \(\chi^2_{p, 1-\alpha}\) est le quantile \((1-\alpha)\) du chi-deux à \(p\) degrés de liberté. Cette distance au centre est la distance de Mahalanobis, qui généralise la distance euclidienne en tenant compte des corrélations.
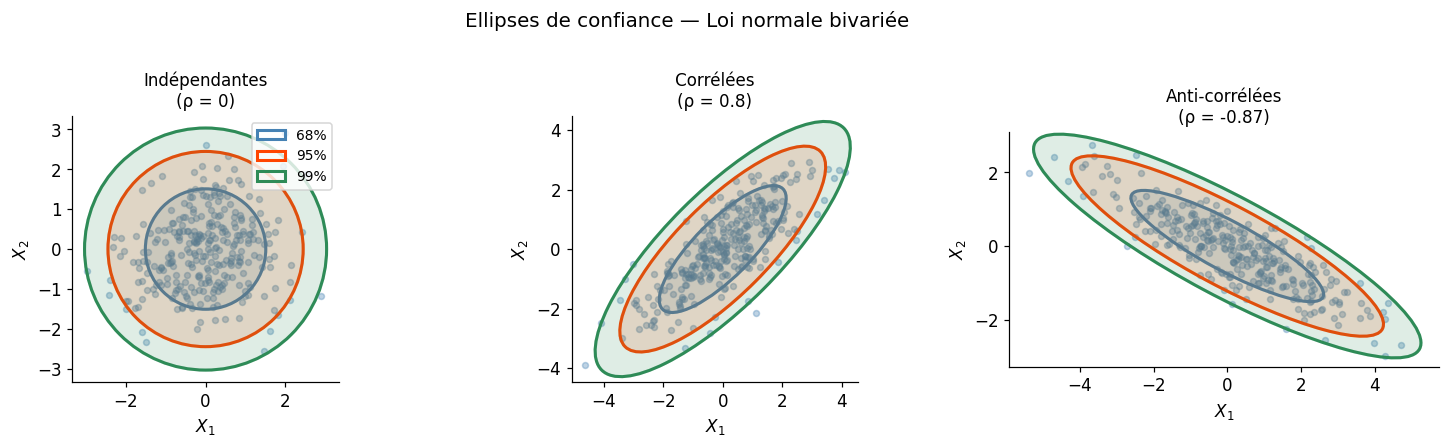
La forme des ellipses révèle immédiatement la structure de dépendance : des ellipses allongées selon une diagonale indiquent une corrélation forte entre les variables.
Analyse en Composantes Principales (ACP)#
Principe et objectif#
L’ACP est une transformation linéaire orthogonale qui réexprime les données dans un nouveau système d’axes — les composantes principales — ordonnés par variance décroissante. La première composante principale (CP1) est la direction qui maximise la variance des projections ; la deuxième (CP2) est orthogonale à CP1 et maximise la variance résiduelle, etc.
Quand l’utiliser ?
Visualiser des données en grande dimension (projection sur CP1, CP2)
Réduire la dimensionnalité avant un modèle (débruitage, décorrélation)
Détecter la structure latente dans les données
Diagnostiquer des problèmes (multicolinéarité)
Prétraitement indispensable#
Avant toute ACP, il faut centrer et réduire les variables (soustraction de la moyenne, division par l’écart-type). Sans réduction, les variables à grande variance domineront artificiellement les premières composantes. La réduction est impérative dès que les variables sont exprimées dans des unités différentes.
Algorithme (rappel)#
Centrer-réduire la matrice \(\mathbf{X}\) (\(n \times p\)) → \(\mathbf{Z}\)
Calculer la matrice de corrélation \(\mathbf{R} = \frac{1}{n-1}\mathbf{Z}^\top\mathbf{Z}\)
Décomposer en valeurs propres : \(\mathbf{R} = \mathbf{V}\boldsymbol{\Lambda}\mathbf{V}^\top\)
Les loadings sont les colonnes de \(\mathbf{V}\) (vecteurs propres)
Les scores sont \(\mathbf{F} = \mathbf{Z}\mathbf{V}\) (coordonnées dans le nouveau repère)
Choix du nombre de composantes#
Deux critères courants :
Scree plot : chercher le « coude » dans la courbe des valeurs propres
Règle de Kaiser : conserver les composantes dont la valeur propre \(> 1\) (c’est-à-dire celles qui expliquent plus de variance qu’une variable originale)
Variance cumulée : viser 70-80% de variance expliquée cumulée
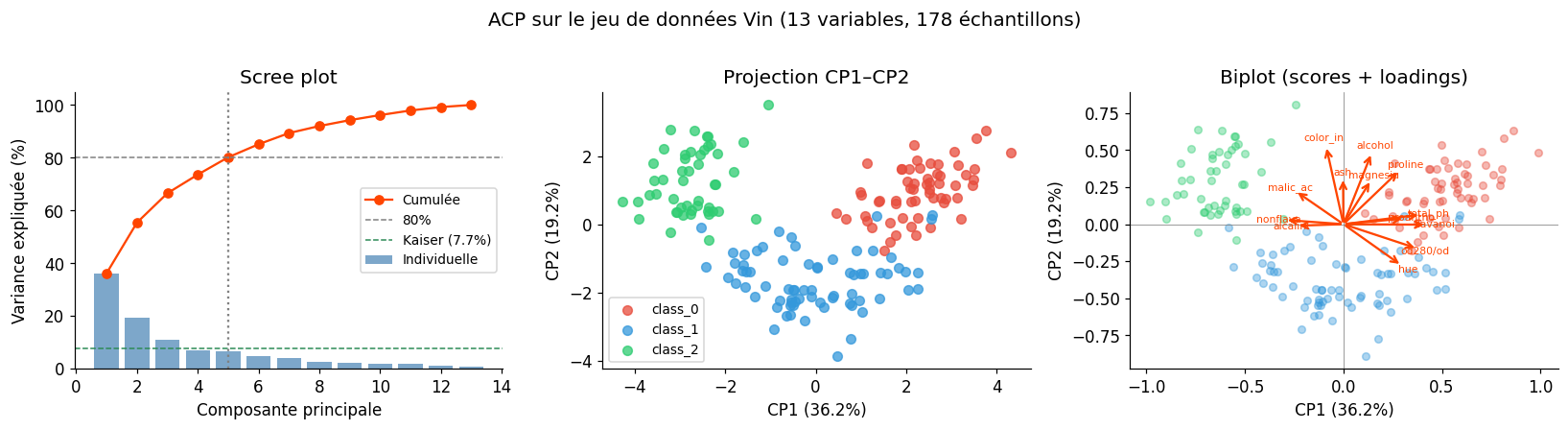
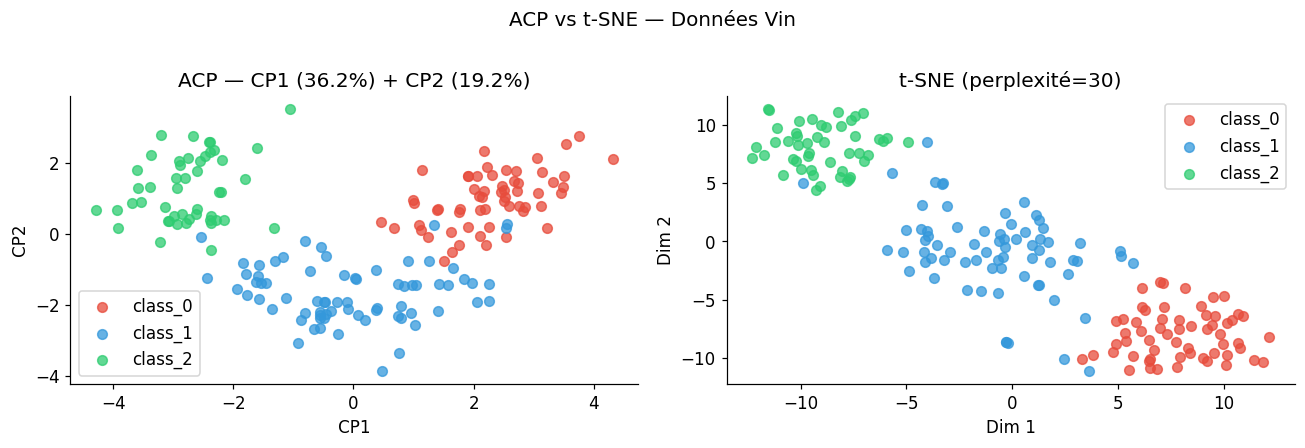
Variance expliquée par CP1 : 36.2%
Variance expliquée par CP1+CP2 : 55.4%
Nombre de composantes pour 80% de variance : 5
Interprétation du biplot#
Le biplot superpose deux informations :
Les scores (points) : position de chaque individu dans le nouveau repère
Les loadings (flèches) : contribution de chaque variable originale aux composantes
Des flèches longues indiquent des variables bien représentées sur le plan. Des flèches proches (angle faible) correspondent à des variables fortement corrélées entre elles. Des flèches opposées (angle ≈ 180°) correspondent à une anti-corrélation.
Analyse des loadings#
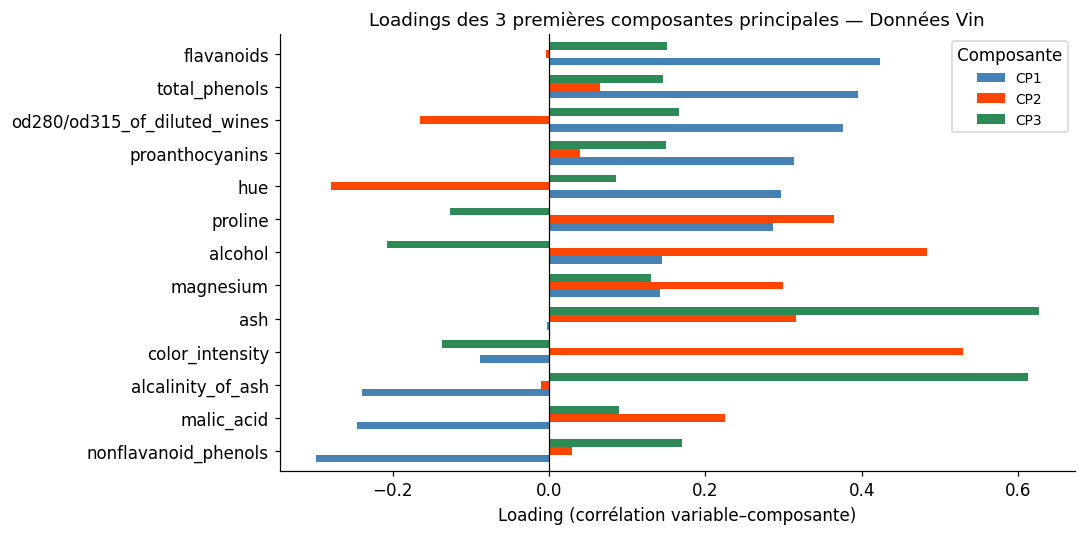
Interprétation des loadings
Les loadings peuvent être interprétés comme des corrélations entre les variables originales et les composantes. Un loading de 0.8 signifie que la variable est corrélée à 80% avec cette composante. En pratique, on nomme une composante d’après les variables qui ont les loadings les plus élevés (en valeur absolue).
Analyse Factorielle des Correspondances (AFC)#
L’AFC est l’analogue de l’ACP pour les tableaux de contingence (variables catégorielles). Elle décompose le \(\chi^2\) d’un tableau de contingence en dimensions successives et permet de visualiser les relations entre modalités de lignes et de colonnes.
Principe#
Pour un tableau de contingence \(\mathbf{N}\) (\(r \times c\)) :
Calculer le tableau des profils (fréquences relatives par ligne et colonne)
Calculer la statistique du \(\chi^2\) et l”inertie totale \(= \chi^2 / n\)
Décomposition en valeurs singulières du tableau des résidus standardisés
Les axes factoriels maximisent l’inertie expliquée
Inertie totale (= χ²/n) : 0.1243
χ² associé : 109.37
Inertie axe 1 : 96.8%
Inertie axes 1+2 : 100.0%
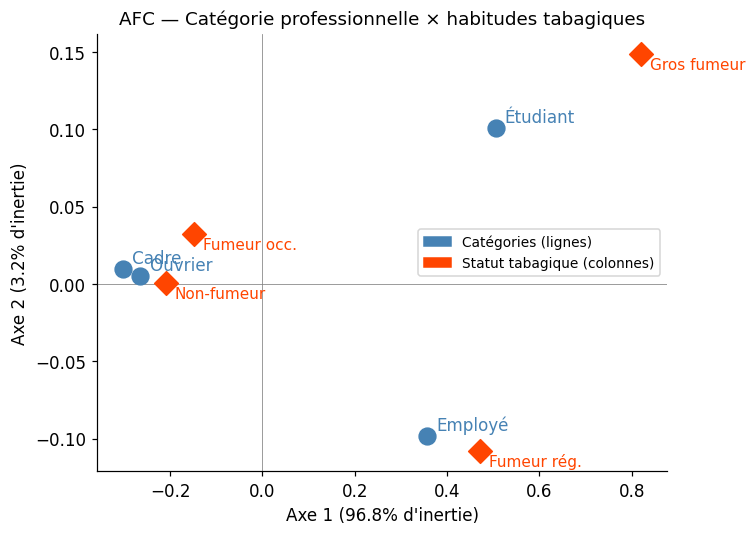
Note
En AFC, les modalités proches sur le graphique sont associées : les cadres se retrouvent du côté « non-fumeur » tandis que les employés se rapprochent des « gros fumeurs ». Les modalités proches de l’origine sont banales (elles ne dépassent pas la fréquence attendue sous indépendance).
Clustering non supervisé#
Le clustering consiste à regrouper des individus similaires sans connaissance préalable des groupes. Contrairement à la classification supervisée, il n’y a pas d’étiquettes d’entraînement.
K-means#
Algorithme#
L’algorithme de Lloyd (communément appelé k-means) procède par itérations :
Initialiser \(k\) centroïdes aléatoirement (ou par k-means++)
Affecter chaque point au centroïde le plus proche (distance euclidienne)
Mettre à jour chaque centroïde : nouvelle position = moyenne du cluster
Répéter jusqu’à convergence (les affectations ne changent plus)
L’algorithme minimise l”inertie intra-cluster (aussi appelée WCSS, Within-Cluster Sum of Squares) :
Méthode du coude et silhouette#
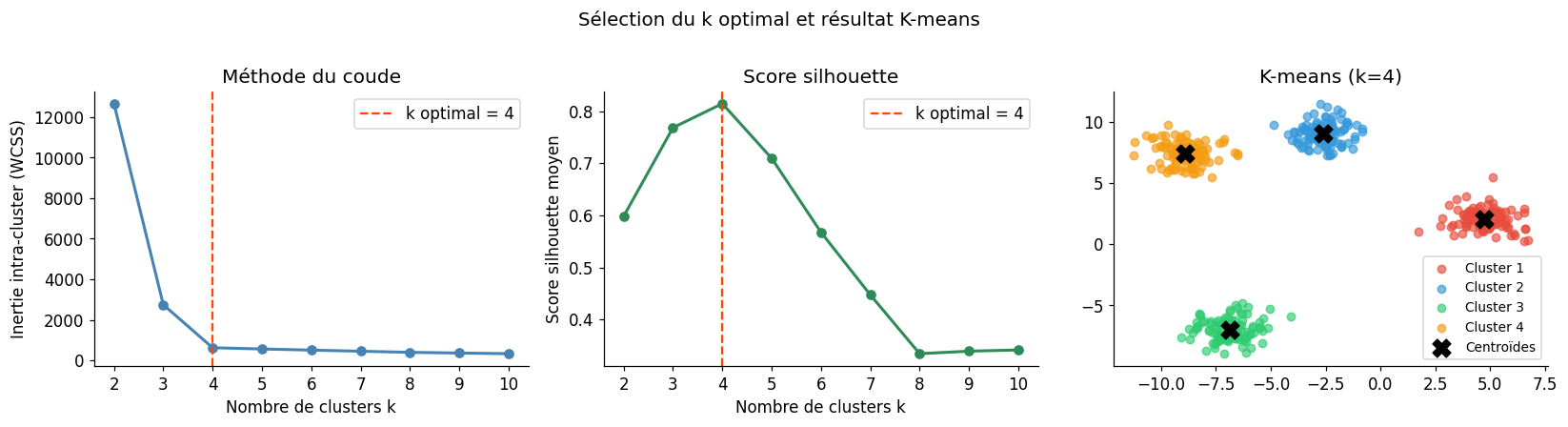
Score silhouette pour k=4 : 0.814
Silhouette plot détaillé#
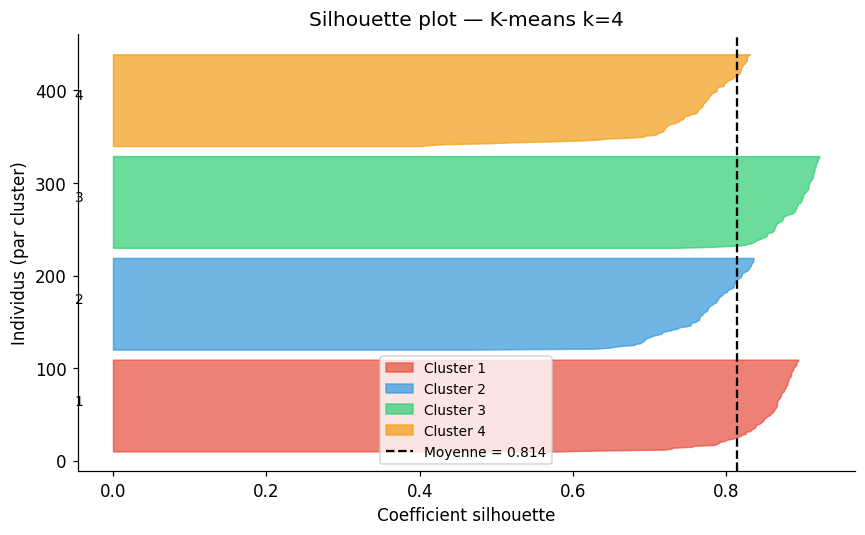
Interpréter le score silhouette
Le coefficient silhouette \(s_i\) d’un point \(i\) compare sa distance moyenne aux points de son cluster (\(a_i\)) à la distance moyenne au cluster le plus proche (\(b_i\)) :
\(s_i \approx 1\) : le point est bien placé dans son cluster
\(s_i \approx 0\) : le point est à la frontière entre deux clusters
\(s_i < 0\) : le point est probablement mal classé
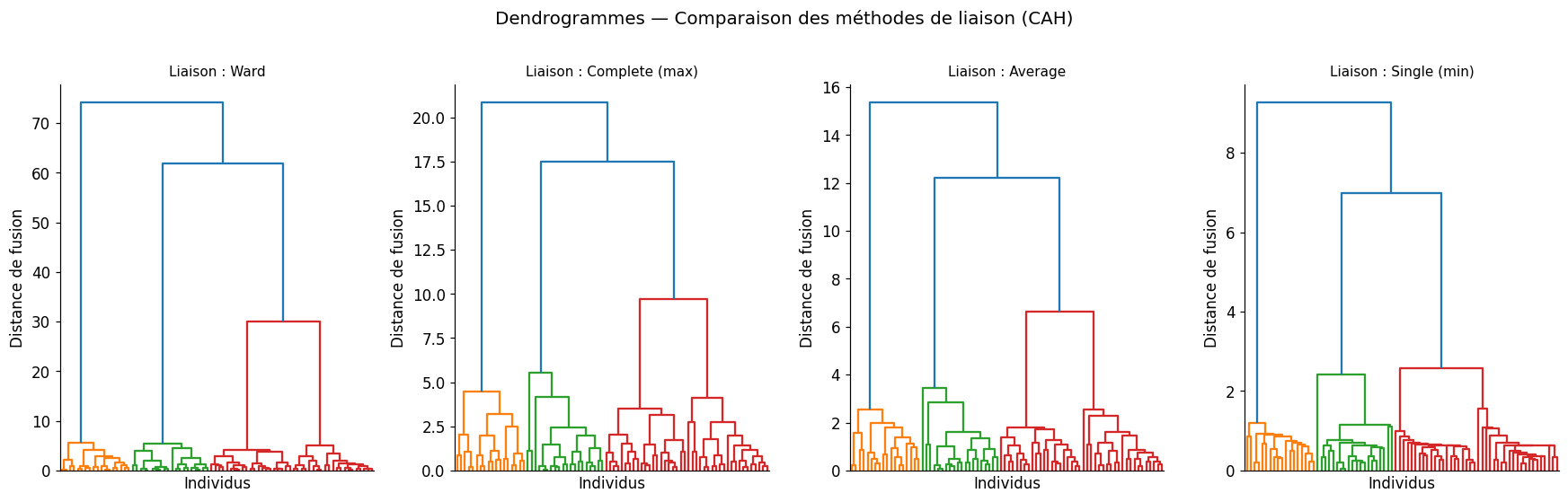
Clustering hiérarchique agglomératif (CAH)#
La CAH construit un dendrogramme en fusionnant itérativement les clusters les plus proches. Contrairement au k-means, elle n’impose pas de nombre de clusters a priori et produit une hiérarchie complète.
Méthodes de liaison#
La définition de la distance entre clusters varie selon la méthode :
Ward : minimise l’augmentation de l’inertie totale lors de la fusion (recommandée pour des clusters compacts et de taille similaire)
Complete (lien maximum) : distance entre les deux points les plus éloignés
Average (UPGMA) : distance moyenne entre tous les couples de points
Single (lien minimum) : distance entre les deux points les plus proches (sensible aux chaînes)
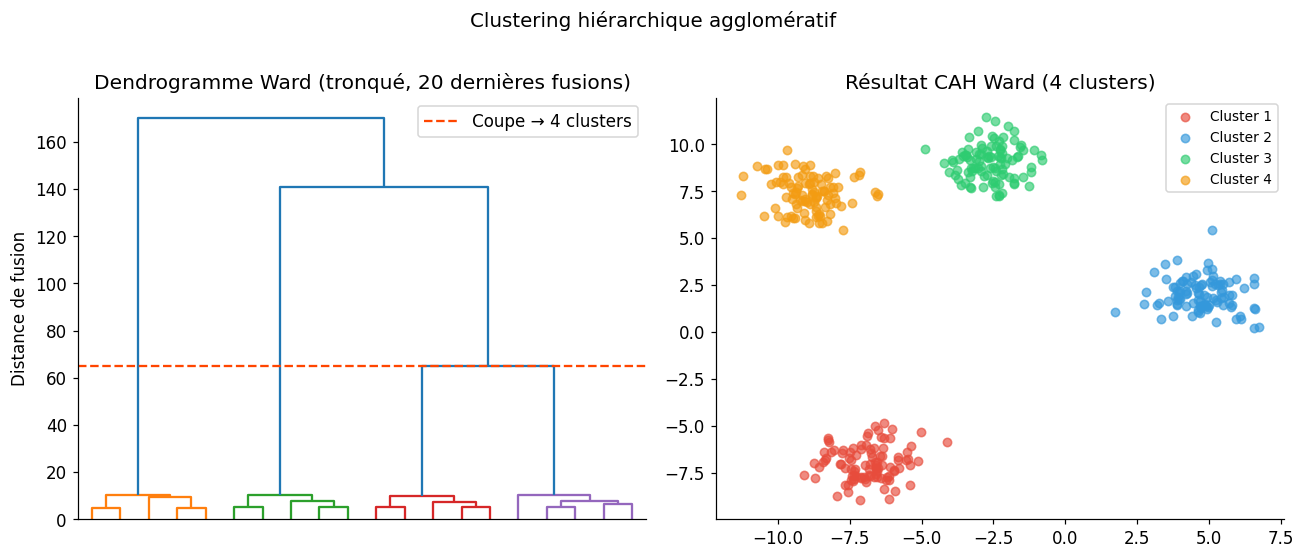
Score silhouette CAH Ward : 0.814
Score silhouette K-means : 0.814
DBSCAN#
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) est un algorithme basé sur la densité plutôt que sur la distance aux centroïdes. Il est particulièrement adapté aux clusters de forme arbitraire et identifie automatiquement les points de bruit.
Paramètres clés :
\(\epsilon\) (eps) : rayon de voisinage — distance maximale pour qu’un point soit considéré comme voisin
minPts (min_samples) : nombre minimal de voisins pour qu’un point soit un point cœur
Classification des points :
Point cœur : au moins
minPtsvoisins dans le rayon \(\epsilon\)Point frontière : dans le voisinage d’un point cœur, mais pas assez de voisins lui-même
Point de bruit : ni cœur ni frontière (label = −1 dans sklearn)
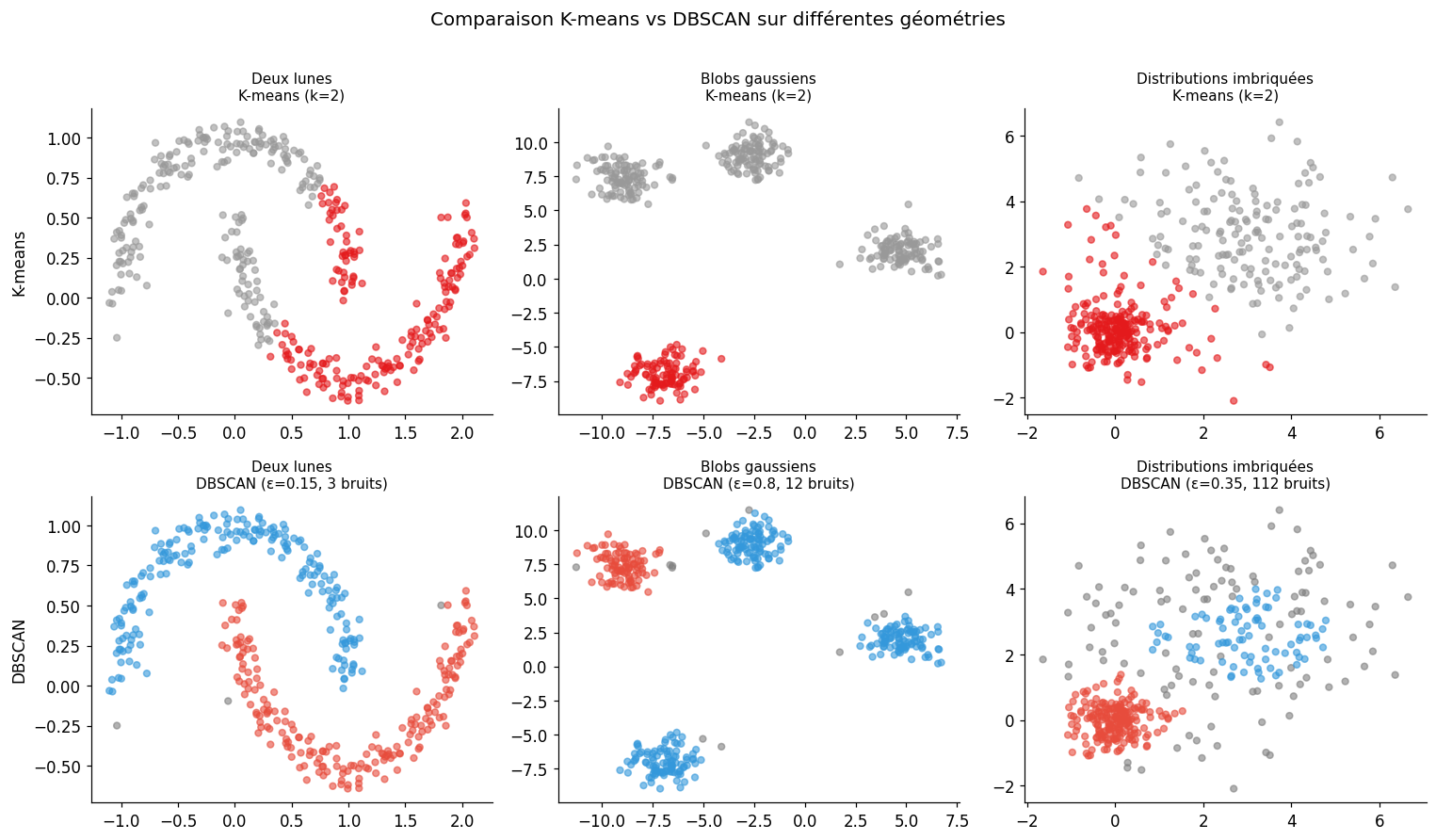
Limites du K-means
Le K-means suppose des clusters convexes et de variance homogène. Il est inadapté aux formes en lune, en anneau ou allongées. DBSCAN gère ces cas mais requiert un bon réglage de ε et minPts. Pour choisir ε, on trace la courbe des distances au k-ième plus proche voisin (k = minPts) et on cherche le « coude ».
Réduction de dimension : t-SNE et UMAP#
Comparaison avec l’ACP#
Méthode |
Type |
Global/Local |
Déterministe |
Utilisable pour modélisation |
|---|---|---|---|---|
ACP |
Linéaire |
Global |
Oui |
Oui |
t-SNE |
Non-linéaire |
Local |
Non (stochastique) |
Non (embedding seulement) |
UMAP |
Non-linéaire |
Global + Local |
Presque |
Avec précautions |
t-SNE (t-distributed Stochastic Neighbor Embedding) minimise la divergence KL entre distributions de similarités dans l’espace d’origine et dans l’espace 2D. Il préserve les structures locales mais distord les distances globales. Les distances entre clusters sur un t-SNE ne sont pas interprétables directement.
UMAP (Uniform Manifold Approximation and Projection) repose sur une théorie différentielle des variétés riemanniennes. Il est plus rapide que t-SNE, préserve mieux la structure globale, et peut être utilisé pour projeter de nouveaux points.
MANOVA#
La MANOVA (Multivariate Analysis of Variance) est l’extension multivariée de l’ANOVA. Là où l’ANOVA teste si la moyenne d”une variable dépend d’un facteur de groupe, la MANOVA teste si le vecteur de moyennes de plusieurs variables dépend simultanément d’un facteur.
Hypothèses :
\(H_0\) : \(\boldsymbol{\mu}_1 = \boldsymbol{\mu}_2 = \ldots = \boldsymbol{\mu}_k\) (tous les vecteurs moyens sont égaux)
\(H_1\) : au moins deux vecteurs moyens diffèrent
Statistiques de test (plusieurs variantes) : Lambda de Wilks \(\Lambda\), Trace de Pillai, Trace d’Hotelling, Valeur propre maximale de Roy.
from statsmodels.multivariate.manova import MANOVA
# MANOVA sur les données Iris (3 groupes, 4 variables)
iris = load_iris()
df_iris = pd.DataFrame(iris.data, columns=['sepal_length', 'sepal_width',
'petal_length', 'petal_width'])
df_iris['species'] = iris.target_names[iris.target]
manova = MANOVA.from_formula(
'sepal_length + sepal_width + petal_length + petal_width ~ species',
data=df_iris
)
result = manova.mv_test()
print(result)
Multivariate linear model
================================================================
----------------------------------------------------------------
Intercept Value Num DF Den DF F Value Pr > F
----------------------------------------------------------------
Wilks' lambda 0.0170 4.0000 144.0000 2086.7720 0.0000
Pillai's trace 0.9830 4.0000 144.0000 2086.7720 0.0000
Hotelling-Lawley trace 57.9659 4.0000 144.0000 2086.7720 0.0000
Roy's greatest root 57.9659 4.0000 144.0000 2086.7720 0.0000
----------------------------------------------------------------
----------------------------------------------------------------
species Value Num DF Den DF F Value Pr > F
----------------------------------------------------------------
Wilks' lambda 0.0234 8.0000 288.0000 199.1453 0.0000
Pillai's trace 1.1919 8.0000 290.0000 53.4665 0.0000
Hotelling-Lawley trace 32.4773 8.0000 203.4024 582.1970 0.0000
Roy's greatest root 32.1919 4.0000 145.0000 1166.9574 0.0000
================================================================
Note
Le Lambda de Wilks proche de 0 indique que les groupes sont bien séparés dans l’espace multivarié. Ici, \(p < 0.001\) confirme que les trois espèces d’iris diffèrent significativement sur l’ensemble des quatre mesures morphologiques.
Comparaison complète des méthodes de clustering#
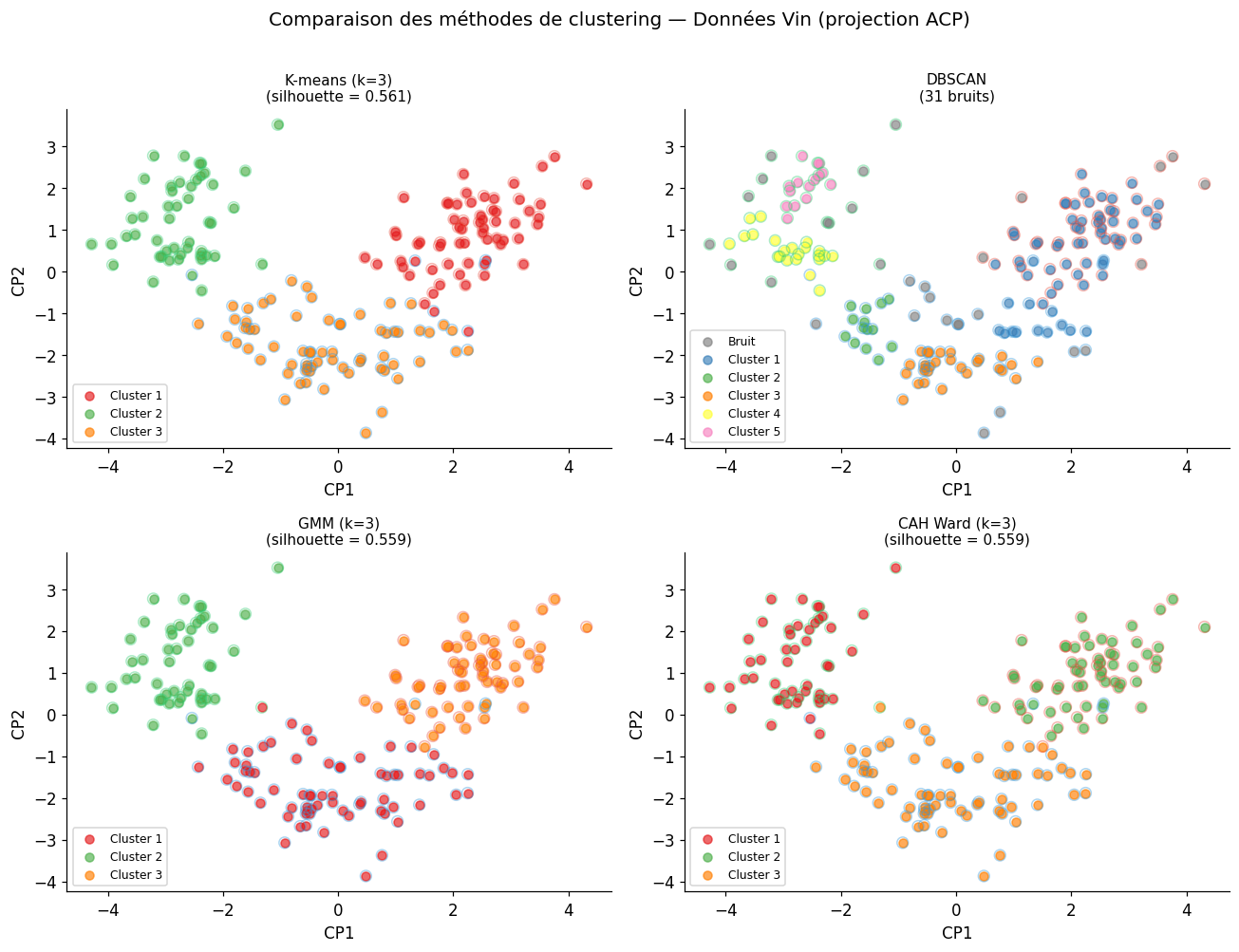
Résumé#
Méthode |
Type |
Hypothèses |
Points forts |
Limites |
|---|---|---|---|---|
ACP |
Réduction dim. |
Linéarité, variance maximale |
Interprétable, rapide |
Liaisons non-linéaires perdues |
AFC |
Réduction dim. |
Tableau de contingence |
Variables catégorielles |
Données quantitatives non adaptées |
K-means |
Clustering |
Clusters convexes, sphériques |
Rapide, scalable |
Sensible aux outliers, k fixé |
CAH |
Clustering |
Aucune sur la forme |
Dendrogramme, k libre |
Lent sur grands jeux, irréversible |
DBSCAN |
Clustering |
Densité uniforme |
Formes arbitraires, bruit |
Paramètres sensibles |
t-SNE |
Visualisation |
— |
Structures locales |
Non interprétable quantitativement |
Bonnes pratiques en analyse multivariée
Toujours centrer-réduire avant l’ACP si les variables ont des unités différentes.
Vérifier la stabilité du clustering : relancer k-means plusieurs fois, comparer avec CAH.
Ne pas sur-interpréter les distances sur un t-SNE : seuls les regroupements locaux sont fiables.
Valider les clusters sur des données externes quand c’est possible.
L’ACP est exploratoire : elle ne teste pas d’hypothèse. Pour des conclusions inférentielles, utiliser MANOVA ou des tests sur les scores.