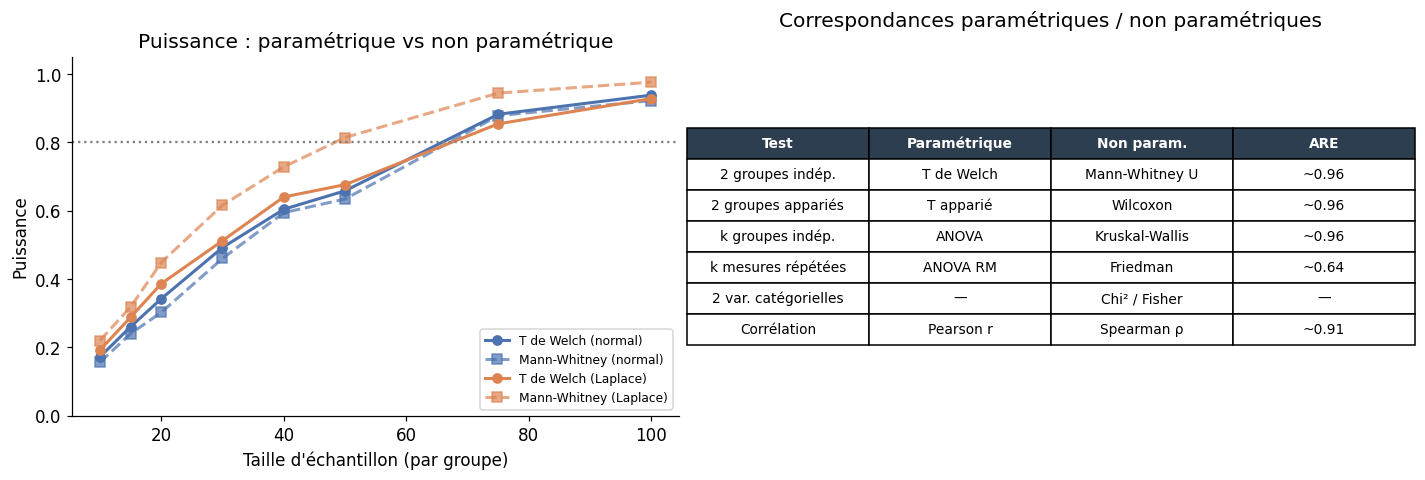
Tests non paramétriques#
Les tests paramétriques supposent une distribution sous-jacente connue (souvent normale) et des paramètres estimables (moyenne, variance). Mais que faire face à des données fortement asymétriques, des valeurs aberrantes, des mesures ordinales, ou des échantillons trop petits pour vérifier la normalité ? Les tests non paramétriques offrent une alternative robuste, fondée sur les rangs plutôt que sur les valeurs brutes.
Quand utiliser les tests non paramétriques ?#
Situation |
Test paramétrique |
Alternative non paramétrique |
|---|---|---|
Non-normalité avérée |
t de Welch |
Mann-Whitney U |
Données ordinales (échelles Likert) |
— |
Mann-Whitney U, Wilcoxon |
Petit échantillon (\(n < 20\)) |
t (fragile) |
Mann-Whitney, Wilcoxon |
Outliers influents |
t (biaisé) |
Tests sur rangs |
\(k\) groupes non normaux |
ANOVA |
Kruskal-Wallis |
Tableau de contingence |
— |
Chi² d’indépendance |
Efficacité relative asymptotique (ARE)
L’ARE (Asymptotic Relative Efficiency) compare la puissance de deux tests. Par exemple, le test de Mann-Whitney a une ARE de 0,955 par rapport au test t sous la normale — il n’est que 4,5% moins puissant. Mais sur une distribution de Laplace ou logistique, il surpasse le test t. Les tests non paramétriques ne sont pas forcément moins puissants : ils sont souvent plus efficaces dès que les données s’écartent de la normale.
Mann-Whitney U : alternative au test t de Welch#
Principe : logique des rangs#
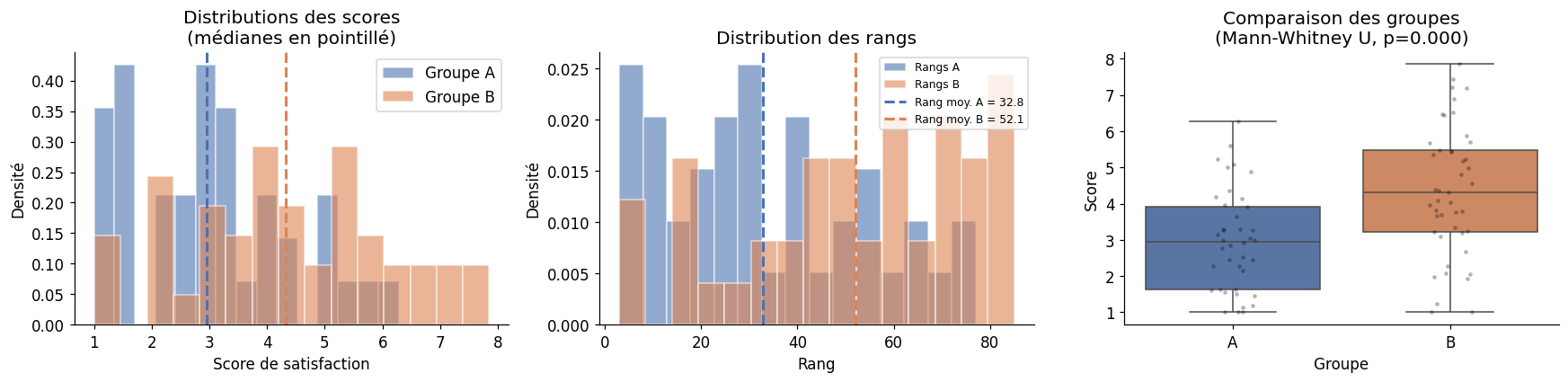
Au lieu de travailler sur les moyennes, le test de Mann-Whitney compare les distributions via leurs rangs. On range tous les \(n_1 + n_2\) observations ensemble, puis on somme les rangs du groupe 1.
La statistique \(U\) compte le nombre de fois où une observation du groupe 1 précède une observation du groupe 2 : $\(U_1 = n_1 n_2 + \frac{n_1(n_1+1)}{2} - R_1\)\( où \)R_1$ est la somme des rangs du groupe 1.
L’interprétation probabiliste est élégante : \(P(X > Y) = U_1 / (n_1 n_2)\).
# Exemple : satisfaction client (score de 1 à 10)
# Distribution asymétrique — les tests t seraient inappropriés
n1, n2 = 40, 45
# Groupe A : distribution légèrement à gauche
groupe_A = np.clip(rng.beta(2, 5, n1) * 10, 1, 10)
# Groupe B : distribution légèrement à droite
groupe_B = np.clip(rng.beta(3, 4, n2) * 10, 1, 10)
# Test de Mann-Whitney
stat_U, p_mw = stats.mannwhitneyu(groupe_A, groupe_B, alternative='two-sided')
# Taille d'effet r = Z / sqrt(N)
n_total = n1 + n2
z_score = stats.norm.ppf(p_mw / 2) # approximation normale
r_effect = abs(z_score) / np.sqrt(n_total)
print(f"Test de Mann-Whitney U")
print(f" U = {stat_U:.0f}")
print(f" p = {p_mw:.4f}")
print(f" Taille d'effet r = {r_effect:.3f} (0.1=petit, 0.3=modéré, 0.5=grand)")
print()
# Avec pingouin
res_mw = pg.mwu(groupe_A, groupe_B, alternative='two-sided')
print("Résultat pingouin :")
print(res_mw.to_string(index=False))
print()
# Interprétation probabiliste
p_A_sur_B = stat_U / (n1 * n2)
print(f"P(A > B) = {p_A_sur_B:.3f} (0.5 = pas de différence)")
Test de Mann-Whitney U
U = 490
p = 0.0003
Taille d'effet r = 0.391 (0.1=petit, 0.3=modéré, 0.5=grand)
Résultat pingouin :
U_val alternative p_val RBC CLES
490.0 two-sided 0.000311 -0.455556 0.272222
P(A > B) = 0.272 (0.5 = pas de différence)
Test de Wilcoxon signé des rangs#
Alternative au test t apparié#
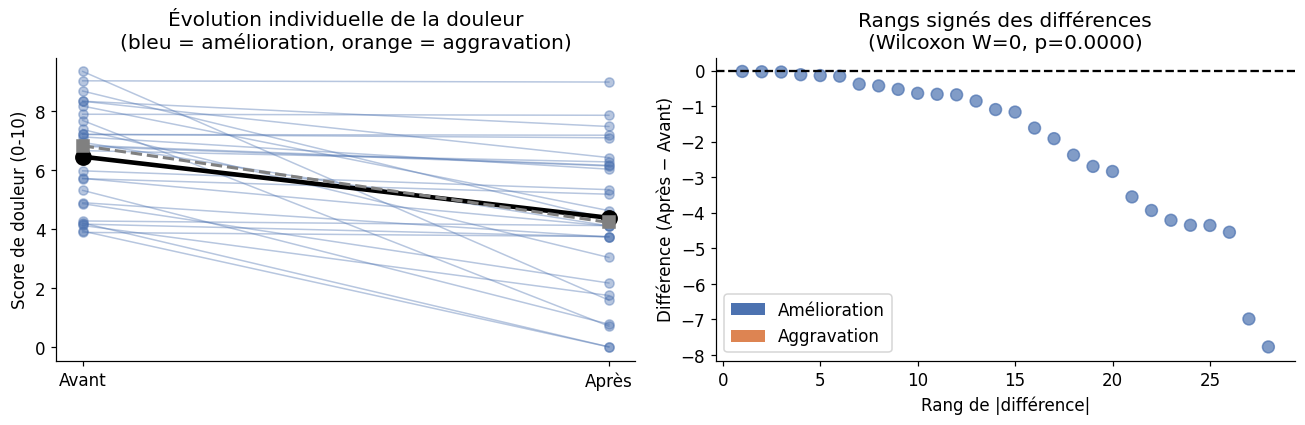
Le test de Wilcoxon signé des rangs s’applique aux données appariées non normales. Il range les différences \(|d_i|\) et tient compte des signes.
# Exemple : douleur avant/après acupuncture (échelle ordinale 0-10)
n_patients = 28
avant = rng.integers(4, 10, n_patients).astype(float) + rng.uniform(-0.4, 0.4, n_patients)
avant = np.clip(avant, 0, 10)
# Réduction de la douleur d'environ 2 points (distribution asymétrique)
reduction = np.clip(rng.exponential(2.0, n_patients), 0, avant)
apres = np.clip(avant - reduction, 0, 10)
differences = apres - avant
# Test de Wilcoxon
stat_wilc, p_wilc = stats.wilcoxon(avant, apres, alternative='two-sided')
print(f"Test de Wilcoxon signé des rangs")
print(f" W = {stat_wilc:.0f}")
print(f" p = {p_wilc:.4f}")
print()
# Comparaison avec t apparié
t_stat, p_t = stats.ttest_rel(avant, apres)
print(f"T apparié (pour comparaison) : t = {t_stat:.3f}, p = {p_t:.4f}")
print()
# Avec pingouin
res_wilc = pg.wilcoxon(avant, apres, alternative='two-sided')
print("Résultat pingouin :")
print(res_wilc.to_string(index=False))
Test de Wilcoxon signé des rangs
W = 0
p = 0.0000
T apparié (pour comparaison) : t = 5.096, p = 0.0000
Résultat pingouin :
W_val alternative p_val RBC CLES
0.0 two-sided 7.450581e-09 1.0 0.751276
Kruskal-Wallis : alternative à l’ANOVA#
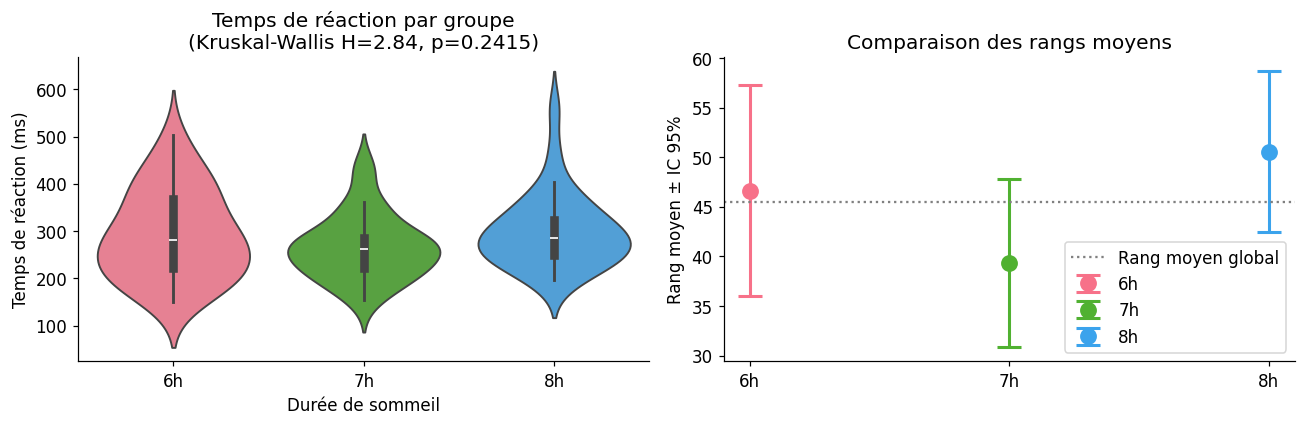
Le test de Kruskal-Wallis est l’extension de Mann-Whitney à \(k > 2\) groupes. Il range toutes les observations ensemble et compare les rangs moyens.
Sous \(H_0\), \(H \sim \chi^2(k-1)\).
# Exemple : temps de réaction selon trois régimes de sommeil (heures de sommeil)
# Distribution log-normale — asymétrique
n_gr = 30
sommeil_6h = rng.lognormal(np.log(300), 0.3, n_gr) # privation légère
sommeil_7h = rng.lognormal(np.log(260), 0.25, n_gr) # optimal
sommeil_8h = rng.lognormal(np.log(270), 0.28, n_gr) # surcharge légère
# Test de Kruskal-Wallis
stat_kw, p_kw = stats.kruskal(sommeil_6h, sommeil_7h, sommeil_8h)
print(f"Test de Kruskal-Wallis")
print(f" H = {stat_kw:.3f}")
print(f" p = {p_kw:.4f}")
print(f" ddl = 2")
print()
# Avec pingouin
df_sommeil = pd.DataFrame({
'reaction': np.concatenate([sommeil_6h, sommeil_7h, sommeil_8h]),
'groupe': ['6h'] * n_gr + ['7h'] * n_gr + ['8h'] * n_gr
})
res_kw = pg.kruskal(data=df_sommeil, dv='reaction', between='groupe')
print("Résultat pingouin :")
print(res_kw.to_string(index=False))
Test de Kruskal-Wallis
H = 2.842
p = 0.2415
ddl = 2
Résultat pingouin :
Source ddof1 H p_unc
groupe 2 2.841612 0.241519
Post-hoc : test de Dunn#
Test de Dunn (post-hoc Kruskal-Wallis, correction Bonferroni) :
6h 7h 8h
6h 1.0000 0.8375 1.0000
7h 0.8375 1.0000 0.2905
8h 1.0000 0.2905 1.0000
Test de Friedman : mesures répétées#
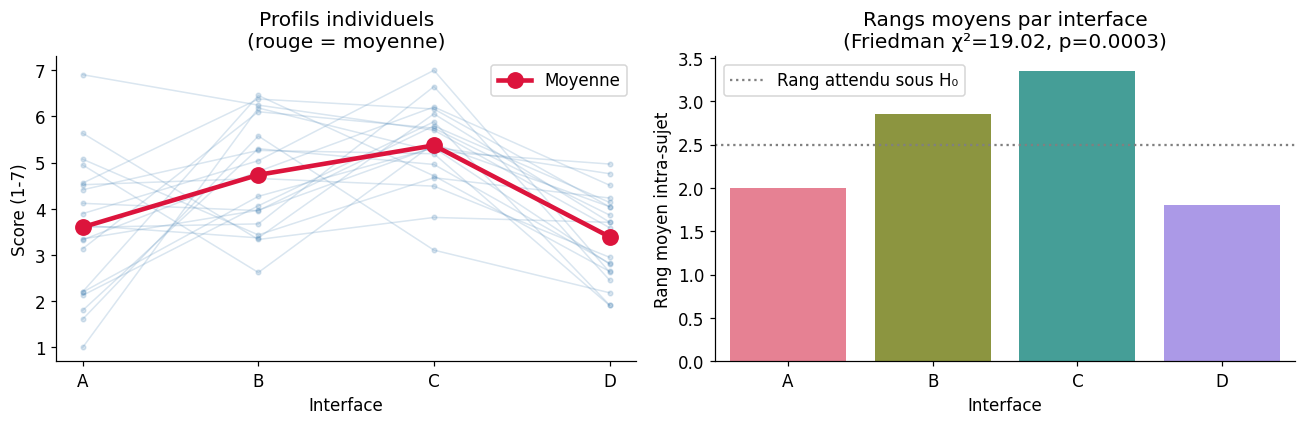
Le test de Friedman est l’analogue non paramétrique de l’ANOVA à mesures répétées. Il range les observations au sein de chaque bloc (individu) et compare les rangs entre conditions.
# Exemple : évaluation de 4 interfaces utilisateur par les mêmes sujets
n_sujets = 20
# Chaque sujet note les 4 interfaces (score 1-7)
# Interface C est objectivement meilleure
interfaces = {
'Interface A': np.clip(rng.normal(4.0, 1.2, n_sujets), 1, 7),
'Interface B': np.clip(rng.normal(4.5, 1.2, n_sujets), 1, 7),
'Interface C': np.clip(rng.normal(5.5, 1.0, n_sujets), 1, 7),
'Interface D': np.clip(rng.normal(3.8, 1.3, n_sujets), 1, 7),
}
df_ux = pd.DataFrame(interfaces)
df_ux['sujet'] = range(n_sujets)
# Test de Friedman
stat_fr, p_fr = stats.friedmanchisquare(*[interfaces[k] for k in interfaces])
print(f"Test de Friedman")
print(f" χ²r = {stat_fr:.3f}")
print(f" p = {p_fr:.4f}")
print(f" ddl = {len(interfaces) - 1}")
print()
# Avec pingouin (format long)
df_ux_long = df_ux.melt(id_vars='sujet', var_name='interface', value_name='score')
res_fr = pg.friedman(data=df_ux_long, dv='score', within='interface', subject='sujet')
print("Résultat pingouin :")
print(res_fr.to_string(index=False))
Test de Friedman
χ²r = 19.020
p = 0.0003
ddl = 3
Résultat pingouin :
Source W ddof1 Q p_unc
interface 0.317 3 19.02 0.000271
Test du Chi² d’indépendance#
Tableaux de contingence#
Le test du Chi² (\(\chi^2\)) d’indépendance s’applique à deux variables catégorielles. On teste si elles sont indépendantes, i.e., si la distribution d’une variable est la même quel que soit le niveau de l’autre.
où \(E_{ij} = \frac{n_{i\cdot} \cdot n_{\cdot j}}{N}\) sont les fréquences attendues sous indépendance.
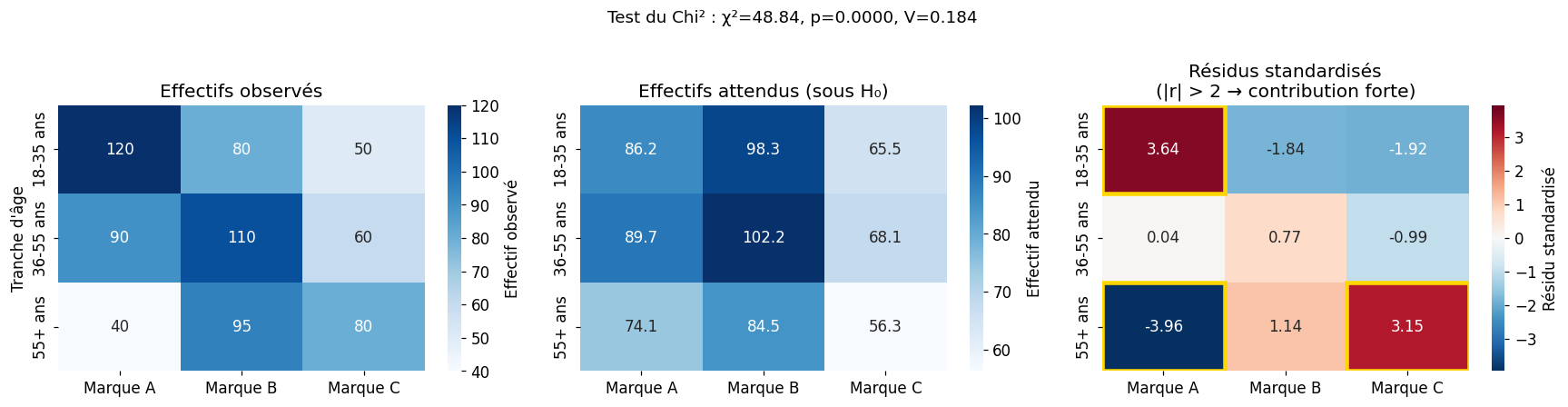
# Exemple : préférence de marque selon tranche d'âge
# Tableau de contingence observé
contingence = np.array([
[120, 80, 50], # 18-35 ans
[90, 110, 60], # 36-55 ans
[40, 95, 80], # 55+ ans
])
labels_age = ['18-35 ans', '36-55 ans', '55+ ans']
labels_marque = ['Marque A', 'Marque B', 'Marque C']
# Test du Chi²
chi2_stat, p_chi2, ddl, freq_attendues = stats.chi2_contingency(contingence)
print(f"Test du Chi² d'indépendance")
print(f" χ² = {chi2_stat:.3f}")
print(f" p = {p_chi2:.4f}")
print(f" ddl = {ddl}")
print()
# V de Cramér (taille d'effet)
n_total = contingence.sum()
r, c = contingence.shape
V_cramer = np.sqrt(chi2_stat / (n_total * (min(r, c) - 1)))
print(f"V de Cramér = {V_cramer:.3f} (0.1=petit, 0.3=modéré, 0.5=grand)")
print()
print("Fréquences attendues :")
df_attendu = pd.DataFrame(freq_attendues, index=labels_age, columns=labels_marque)
print(df_attendu.round(1))
Test du Chi² d'indépendance
χ² = 48.839
p = 0.0000
ddl = 4
V de Cramér = 0.184 (0.1=petit, 0.3=modéré, 0.5=grand)
Fréquences attendues :
Marque A Marque B Marque C
18-35 ans 86.2 98.3 65.5
36-55 ans 89.7 102.2 68.1
55+ ans 74.1 84.5 56.3
Test exact de Fisher#
Pour les petits effectifs ou les tableaux 2×2, le test du Chi² peut être inexact. Le test exact de Fisher calcule directement la probabilité d’observer une table aussi extrême ou plus sous \(H_0\) d’indépendance.
# Exemple : essai clinique avec petits effectifs
# Traitement vs Placebo, Guéri vs Non guéri
table_2x2 = np.array([
[12, 3], # Traitement : 12 guéris, 3 non guéris
[7, 8], # Placebo : 7 guéris, 8 non guéris
])
# Test exact de Fisher
odds_ratio, p_fisher = stats.fisher_exact(table_2x2, alternative='two-sided')
# Chi² pour comparaison (souvent invalide ici)
chi2_s, p_chi2_s, _, _ = stats.chi2_contingency(table_2x2)
print(f"Tableau 2×2 :")
print(pd.DataFrame(table_2x2, index=['Traitement', 'Placebo'],
columns=['Guéri', 'Non guéri']))
print()
print(f"Test exact de Fisher :")
print(f" Odds Ratio = {odds_ratio:.3f}")
print(f" p = {p_fisher:.4f}")
print()
print(f"Test du Chi² (comparaison) :")
print(f" χ² = {chi2_s:.3f}")
print(f" p = {p_chi2_s:.4f}")
print()
# Vérifier la règle des 5
freq_att = np.outer(table_2x2.sum(axis=1), table_2x2.sum(axis=0)) / table_2x2.sum()
print("Fréquences attendues (règle des 5) :")
print(freq_att.round(1))
print(f"→ {'Chi² valide' if (freq_att >= 5).all() else 'Fisher recommandé (freq. attendue < 5)'}")
Tableau 2×2 :
Guéri Non guéri
Traitement 12 3
Placebo 7 8
Test exact de Fisher :
Odds Ratio = 4.571
p = 0.1281
Test du Chi² (comparaison) :
χ² = 2.297
p = 0.1297
Fréquences attendues (règle des 5) :
[[9.5 5.5]
[9.5 5.5]]
→ Chi² valide
Règle des 5 pour le Chi²
Le test du Chi² est approximatif et peut être inexact lorsque les fréquences attendues sont faibles. La règle classique : toutes les fréquences attendues doivent être ≥ 5. Sinon, utilisez le test exact de Fisher (pour les tableaux 2×2) ou le test exact de Fisher-Freeman-Halton (tableaux plus grands).
Corrélation de Spearman : test de significativité#
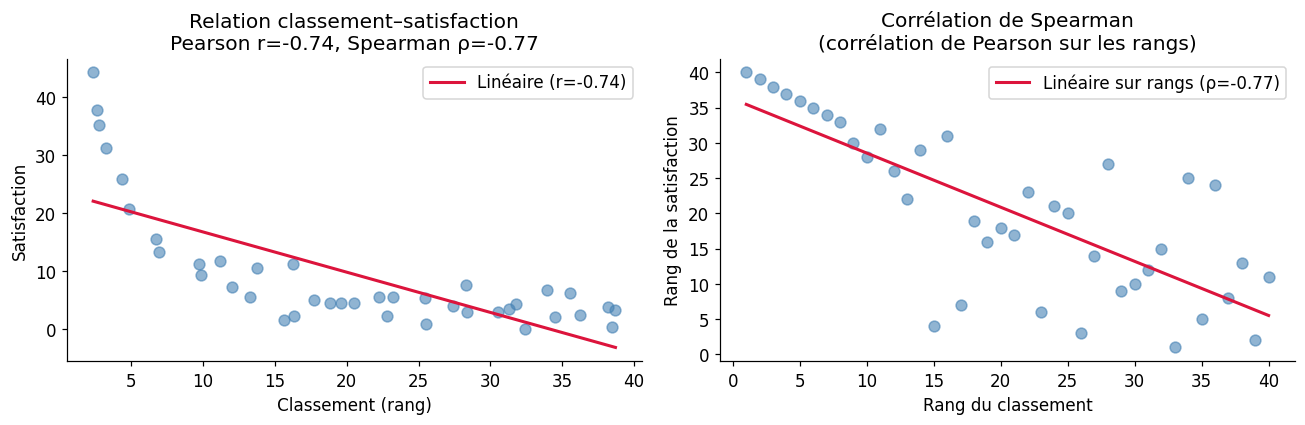
La corrélation de Spearman \(\rho_s\) est la corrélation de Pearson calculée sur les rangs. Elle est robuste aux outliers et adaptée aux relations monotones non linéaires.
# Exemple : relation entre rang de classement et satisfaction (non linéaire)
n_prod = 40
classement = np.arange(1, n_prod + 1, dtype=float) + rng.normal(0, 1, n_prod)
# Relation monotone décroissante mais non linéaire
satisfaction = 100 / classement + rng.normal(0, 2, n_prod)
satisfaction = np.clip(satisfaction, 0, 100)
# Corrélation de Pearson
r_pearson, p_pearson = stats.pearsonr(classement, satisfaction)
# Corrélation de Spearman
r_spearman, p_spearman = stats.spearmanr(classement, satisfaction)
# Corrélation de Kendall
tau_kendall, p_kendall = stats.kendalltau(classement, satisfaction)
print(f"Corrélation de Pearson r = {r_pearson:.3f}, p = {p_pearson:.4f}")
print(f"Corrélation de Spearman ρ = {r_spearman:.3f}, p = {p_spearman:.4f}")
print(f"Corrélation de Kendall τ = {tau_kendall:.3f}, p = {p_kendall:.4f}")
print()
# Cas avec outlier
classement_out = classement.copy()
satisfaction_out = satisfaction.copy()
classement_out[-1] = 100 # outlier
satisfaction_out[-1] = 95 # outlier extrême
r_pearson_out, _ = stats.pearsonr(classement_out, satisfaction_out)
r_spearman_out, _ = stats.spearmanr(classement_out, satisfaction_out)
print("Avec un outlier extrême :")
print(f" Pearson : r = {r_pearson_out:.3f} (fortement affecté)")
print(f" Spearman : ρ = {r_spearman_out:.3f} (robuste)")
Corrélation de Pearson r = -0.744, p = 0.0000
Corrélation de Spearman ρ = -0.768, p = 0.0000
Corrélation de Kendall τ = -0.610, p = 0.0000
Avec un outlier extrême :
Pearson : r = 0.277 (fortement affecté)
Spearman : ρ = -0.643 (robuste)
Comparaison paramétrique vs non paramétrique#
Efficacité relative asymptotique (ARE)#
L’ARE quantifie la puissance relative : un ARE de 0,955 signifie que le test non paramétrique nécessite ~4,5% d’observations supplémentaires pour atteindre la même puissance que le test paramétrique sous la normale.
# Simulation : comparaison puissance t de Welch vs Mann-Whitney
# selon la distribution sous-jacente
from scipy.stats import ttest_ind, mannwhitneyu
def simulate_power(dist_func, n, n_sim=2000, alpha=0.05):
"""Estime la puissance de t-test et Mann-Whitney pour un effet donné."""
reject_t, reject_mw = 0, 0
for _ in range(n_sim):
# Groupe A (distribution de base)
g1 = dist_func(0, n)
# Groupe B (décalé de 0.5 unités)
g2 = dist_func(0.5, n)
_, p_t = ttest_ind(g1, g2, equal_var=False)
_, p_mw = mannwhitneyu(g1, g2, alternative='two-sided')
if p_t < alpha:
reject_t += 1
if p_mw < alpha:
reject_mw += 1
return reject_t / n_sim, reject_mw / n_sim
rng_sim = np.random.default_rng(99)
def norm_dist(shift, n):
return rng_sim.normal(shift, 1, n)
def laplace_dist(shift, n):
return rng_sim.laplace(shift, 1/np.sqrt(2), n)
def uniform_dist(shift, n):
return rng_sim.uniform(shift - np.sqrt(3), shift + np.sqrt(3), n)
n_test = 30
distributions = {
'Normale': norm_dist,
'Laplace': laplace_dist,
'Uniforme': uniform_dist,
}
print("Puissance simulée (n=30 par groupe, effet=0.5, α=0.05) :")
print(f"{'Distribution':<15} {'Test t':>10} {'Mann-Whitney':>15} {'ARE (MWU/t)':>12}")
print("-" * 55)
for name, dist_f in distributions.items():
pow_t, pow_mw = simulate_power(dist_f, n_test, n_sim=1000)
are = pow_mw / pow_t if pow_t > 0 else float('nan')
print(f"{name:<15} {pow_t:>10.3f} {pow_mw:>15.3f} {are:>12.3f}")
Puissance simulée (n=30 par groupe, effet=0.5, α=0.05) :
Distribution Test t Mann-Whitney ARE (MWU/t)
-------------------------------------------------------
Normale 0.509 0.470 0.923
Laplace 0.514 0.634 1.233
Uniforme 0.440 0.406 0.923
Résumé : quand choisir ?
Utilisez les tests non paramétriques quand :
Les données sont fortement asymétriques ou ont des queues lourdes
Les observations sont sur une échelle ordinale (Likert, rangs)
Les effectifs sont petits (< 15-20 par groupe) et la normalité non vérifiable
Des outliers résistants à la suppression sont présents
Continuez avec les tests paramétriques quand :
Les données sont approximativement normales et les échantillons raisonnables
Vous avez besoin d’intervalles de confiance sur des moyennes
Le modèle paramétrique est justifié par la connaissance du domaine
Les tests non paramétriques ne sont pas une solution de facilité — ils testent une hypothèse différente (distribution / médianes) et ont des tailles d’effet distinctes à rapporter.