Corrélation et dépendance#
La corrélation est l’une des notions les plus utilisées — et les plus mal comprises — de la statistique appliquée. Ce chapitre couvre les trois grandes mesures de corrélation, leurs hypothèses, leurs limites, et surtout les pièges dans lesquels tombent même les analystes expérimentés.
Corrélation de Pearson#
Le coefficient de corrélation de Pearson \(r\) mesure la force et la direction d’une relation linéaire entre deux variables :
\(r = 1\) : relation linéaire positive parfaite. \(r = -1\) : relation linéaire négative parfaite. \(r = 0\) : pas de relation linéaire (mais peut exister une relation non linéaire).
Hypothèses pour l’inférence : pour que le test de significativité (\(H_0 : \rho = 0\)) soit valide, les deux variables doivent être environ normalement distribuées (ou \(n\) doit être suffisamment grand par le TCL). La corrélation elle-même peut être calculée sans hypothèse de normalité.
# Jeu de données réaliste : caractéristiques de logements
n = 300
surface = rng.uniform(20, 150, n)
prix_base = 1500 * surface + rng.normal(0, 15000, n) # prix lié à la surface
nb_pieces = np.round(surface / 25 + rng.normal(0, 0.5, n)).clip(1, 8).astype(int)
etage = rng.integers(0, 15, n)
annee = rng.integers(1950, 2020, n)
df = pd.DataFrame({
"prix": prix_base + 500 * etage + rng.normal(0, 10000, n),
"surface": surface,
"nb_pieces": nb_pieces,
"etage": etage,
"annee_construction": annee,
"distance_centre": rng.exponential(5, n),
})
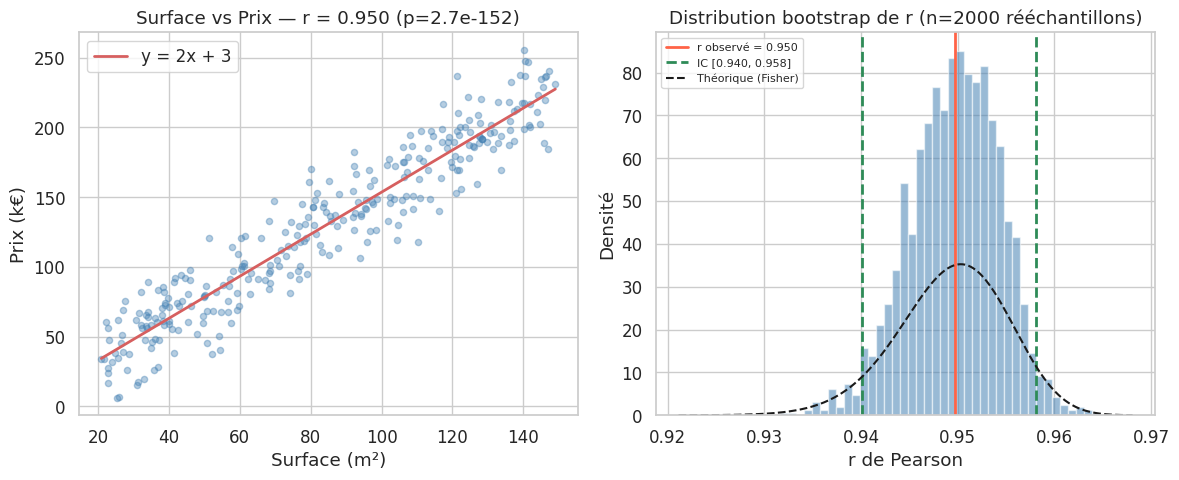
r_pearson, p_pearson = stats.pearsonr(df["surface"], df["prix"])
print(f"Corrélation de Pearson (surface, prix) : r = {r_pearson:.4f}, p = {p_pearson:.2e}")
Corrélation de Pearson (surface, prix) : r = 0.9497, p = 2.75e-152
Intervalle de confiance par bootstrap#
La distribution asymptotique de \(r\) est délicate (la transformation de Fisher \(z = \text{arctanh}(r)\) la normalise). Le bootstrap offre une alternative non paramétrique robuste.
def ic_bootstrap_pearson(x, y, n_boot=2000, alpha=0.05):
"""IC bootstrap percentile pour le coefficient de Pearson."""
n = len(x)
boots = []
for _ in range(n_boot):
idx = rng.integers(0, n, size=n)
r_b, _ = stats.pearsonr(x[idx], y[idx])
boots.append(r_b)
boots = np.array(boots)
ic_low = np.percentile(boots, 100 * alpha / 2)
ic_high = np.percentile(boots, 100 * (1 - alpha / 2))
return ic_low, ic_high, boots
# IC analytique via transformation de Fisher
def ic_fisher_pearson(r, n, alpha=0.05):
"""IC à 95% via transformation de Fisher."""
z = np.arctanh(r)
se = 1 / np.sqrt(n - 3)
z_crit = stats.norm.ppf(1 - alpha / 2)
z_low = z - z_crit * se
z_high = z + z_crit * se
return np.tanh(z_low), np.tanh(z_high)
r = r_pearson
n_obs = len(df)
ic_fish_low, ic_fish_high = ic_fisher_pearson(r, n_obs)
ic_boot_low, ic_boot_high, boots = ic_bootstrap_pearson(
df["surface"].values, df["prix"].values
)
print(f"r de Pearson : {r:.4f}")
print(f"IC Fisher (95%) : [{ic_fish_low:.4f}, {ic_fish_high:.4f}]")
print(f"IC Bootstrap (95%) : [{ic_boot_low:.4f}, {ic_boot_high:.4f}]")
r de Pearson : 0.9497
IC Fisher (95%) : [0.9372, 0.9597]
IC Bootstrap (95%) : [0.9401, 0.9580]
Corrélation de Spearman#
Le coefficient de Spearman \(\rho\) est la corrélation de Pearson appliquée aux rangs des observations. Il mesure une relation monotone (croissante ou décroissante) sans supposer la linéarité.
où \(d_i\) est la différence des rangs de \(x_i\) et \(y_i\).
Avantages : insensible aux transformations monotones (\(\log\), racine carrée…), robuste aux outliers, adapté aux données ordinales.
# Illustration : Spearman robuste aux outliers, Pearson non
x_base = rng.uniform(1, 10, 50)
y_base = 2 * x_base + rng.normal(0, 1, 50)
# Ajout d'un outlier extrême
x_avec = np.append(x_base, 50)
y_avec = np.append(y_base, 5) # outlier incohérent
r_p_sans, _ = stats.pearsonr(x_base, y_base)
r_s_sans, _ = stats.spearmanr(x_base, y_base)
r_p_avec, _ = stats.pearsonr(x_avec, y_avec)
r_s_avec, _ = stats.spearmanr(x_avec, y_avec)
print(" Pearson Spearman")
print(f"Sans outlier : {r_p_sans:.3f} {r_s_sans:.3f}")
print(f"Avec outlier : {r_p_avec:.3f} {r_s_avec:.3f}")
print(f"Variation : {abs(r_p_avec-r_p_sans):.3f} {abs(r_s_avec-r_s_sans):.3f}")
Pearson Spearman
Sans outlier : 0.978 0.977
Avec outlier : 0.198 0.896
Variation : 0.779 0.081
Corrélation de Kendall#
Le tau de Kendall \(\tau\) mesure la concordance entre les paires d’observations. Une paire \((x_i, x_j)\) est concordante si \(x_i < x_j\) et \(y_i < y_j\) (ou les deux plus grands), discordante sinon.
Avantages : plus robuste que Spearman pour les petits échantillons, interprétable directement comme différence de probabilités (\(P(\text{concordante}) - P(\text{discordante})\)), s’étend naturellement aux données avec ex-aequo.
# Comparaison des trois corrélations sur notre jeu de données logements
print("=== Corrélations paires (logements) ===\n")
variables = ["prix", "surface", "nb_pieces", "etage", "annee_construction"]
for v1, v2 in [("surface", "prix"), ("nb_pieces", "prix"), ("etage", "prix"),
("annee_construction", "prix"), ("surface", "nb_pieces")]:
r_p, p_p = stats.pearsonr(df[v1], df[v2])
r_s, p_s = stats.spearmanr(df[v1], df[v2])
r_k, p_k = stats.kendalltau(df[v1], df[v2])
print(f"{v1:25s} × {v2:20s}")
print(f" Pearson : r={r_p:.3f} (p={p_p:.3f})")
print(f" Spearman: ρ={r_s:.3f} (p={p_s:.3f})")
print(f" Kendall : τ={r_k:.3f} (p={p_k:.3f})")
print()
=== Corrélations paires (logements) ===
surface × prix
Pearson : r=0.950 (p=0.000)
Spearman: ρ=0.952 (p=0.000)
Kendall : τ=0.801 (p=0.000)
nb_pieces × prix
Pearson : r=0.867 (p=0.000)
Spearman: ρ=0.875 (p=0.000)
Kendall : τ=0.725 (p=0.000)
etage × prix
Pearson : r=-0.021 (p=0.715)
Spearman: ρ=-0.022 (p=0.701)
Kendall : τ=-0.014 (p=0.722)
annee_construction × prix
Pearson : r=0.090 (p=0.122)
Spearman: ρ=0.083 (p=0.151)
Kendall : τ=0.058 (p=0.140)
surface × nb_pieces
Pearson : r=0.930 (p=0.000)
Spearman: ρ=0.932 (p=0.000)
Kendall : τ=0.813 (p=0.000)
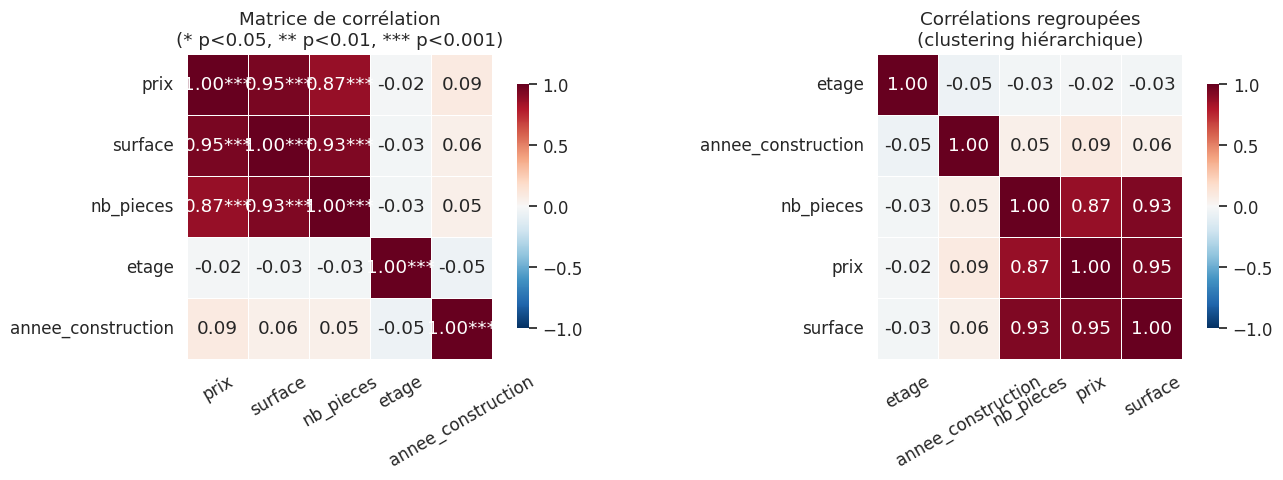
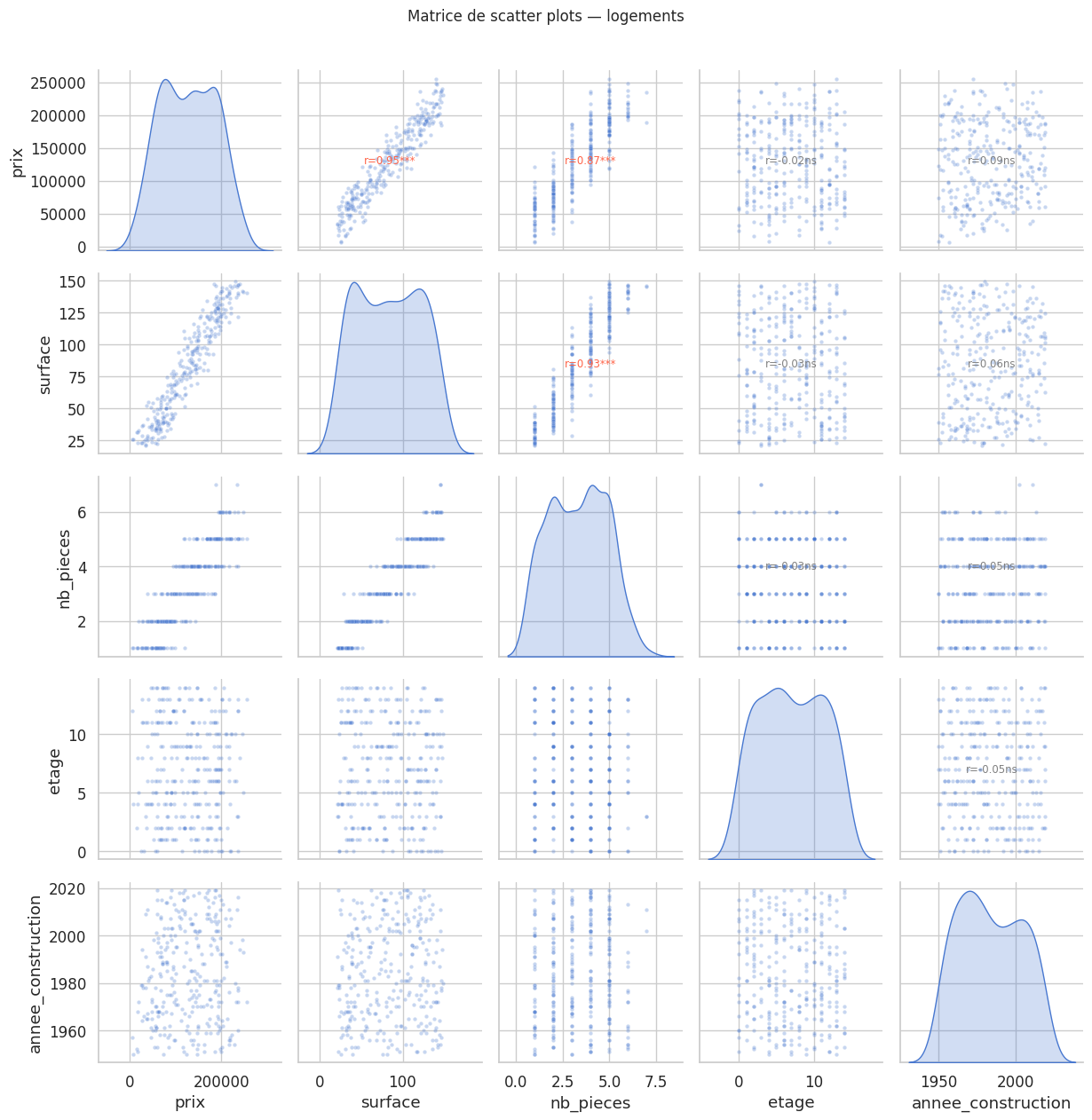
Matrice de corrélation et visualisation#
# Corrélations complètes avec significativité
def matrice_corr_avec_pvaleurs(df_vars, methode="pearson"):
"""Retourne la matrice de corrélation et les p-valeurs."""
cols = df_vars.columns
n = len(cols)
corr = pd.DataFrame(index=cols, columns=cols, dtype=float)
pvals = pd.DataFrame(index=cols, columns=cols, dtype=float)
for i, c1 in enumerate(cols):
for j, c2 in enumerate(cols):
if i == j:
corr.loc[c1, c2] = 1.0
pvals.loc[c1, c2] = 0.0
else:
if methode == "pearson":
r, p = stats.pearsonr(df_vars[c1], df_vars[c2])
elif methode == "spearman":
r, p = stats.spearmanr(df_vars[c1], df_vars[c2])
corr.loc[c1, c2] = r
pvals.loc[c1, c2] = p
return corr.astype(float), pvals.astype(float)
df_vars = df[variables]
corr_mat, pval_mat = matrice_corr_avec_pvaleurs(df_vars)
print("Matrice de corrélation de Pearson :")
print(corr_mat.round(3).to_string())
Matrice de corrélation de Pearson :
prix surface nb_pieces etage annee_construction
prix 1.000 0.950 0.867 -0.021 0.090
surface 0.950 1.000 0.930 -0.026 0.061
nb_pieces 0.867 0.930 1.000 -0.026 0.055
etage -0.021 -0.026 -0.026 1.000 -0.048
annee_construction 0.090 0.061 0.055 -0.048 1.000
Pièges classiques#
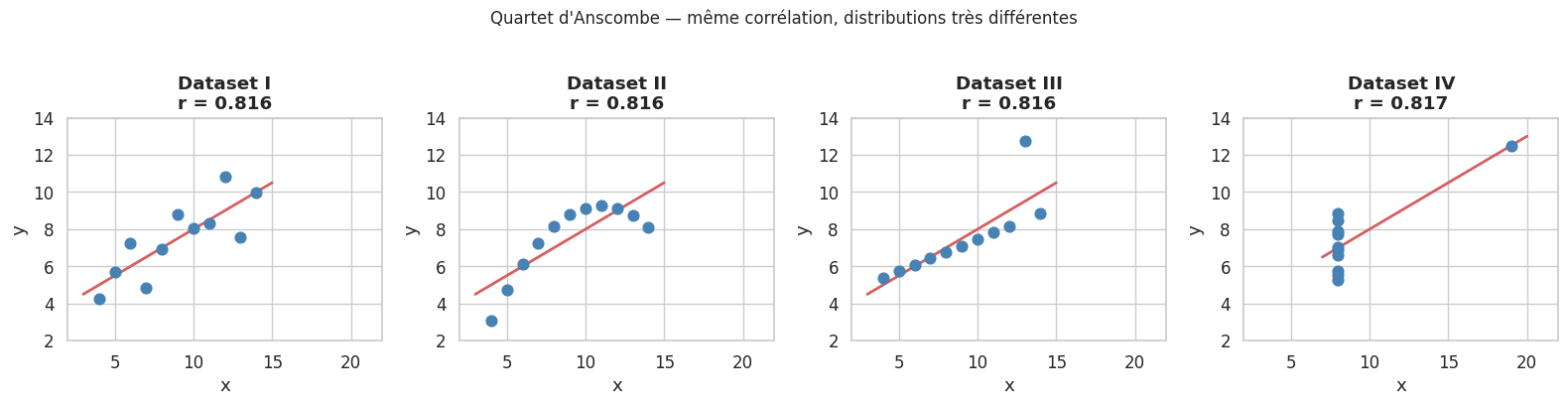
Le quartet d’Anscombe#
En 1973, Francis Anscombe construisit quatre jeux de données ayant exactement les mêmes statistiques descriptives (moyenne, variance, corrélation) mais des formes radicalement différentes. La leçon : toujours tracer les données.
# Quartet d'Anscombe (données exactes de l'article original)
anscombe = {
"I": {"x": [10,8,13,9,11,14,6,4,12,7,5],
"y": [8.04,6.95,7.58,8.81,8.33,9.96,7.24,4.26,10.84,4.82,5.68]},
"II": {"x": [10,8,13,9,11,14,6,4,12,7,5],
"y": [9.14,8.14,8.74,8.77,9.26,8.10,6.13,3.10,9.13,7.26,4.74]},
"III": {"x": [10,8,13,9,11,14,6,4,12,7,5],
"y": [7.46,6.77,12.74,7.11,7.81,8.84,6.08,5.39,8.15,6.42,5.73]},
"IV": {"x": [8,8,8,8,8,8,8,19,8,8,8],
"y": [6.58,5.76,7.71,8.84,8.47,7.04,5.25,12.50,5.56,7.91,6.89]},
}
print(f"{'':8s} {'Moyenne x':>10} {'Variance x':>10} {'Moyenne y':>10} {'Variance y':>10} {'Corrélation':>12}")
for nom, d in anscombe.items():
x, y = np.array(d["x"]), np.array(d["y"])
r, _ = stats.pearsonr(x, y)
print(f"Dataset {nom} {x.mean():>10.2f} {x.var():>10.2f} {y.mean():>10.2f} {y.var():>10.2f} {r:>12.4f}")
Moyenne x Variance x Moyenne y Variance y Corrélation
Dataset I 9.00 10.00 7.50 3.75 0.8164
Dataset II 9.00 10.00 7.50 3.75 0.8162
Dataset III 9.00 10.00 7.50 3.75 0.8163
Dataset IV 9.00 10.00 7.50 3.75 0.8165
Le Datasaurus#
Le Datasaurus Dozen (Matejka & Fitzmaurice, 2017) étend l’idée d’Anscombe à l’extrême : des jeux de données qui dessinent des formes reconnaissables tout en ayant des statistiques identiques.
Corrélation nulle ≠ indépendance#
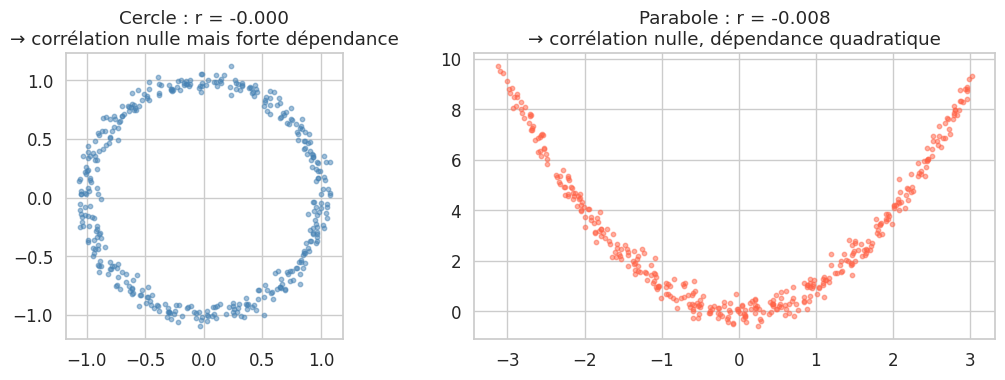
Corrélations fallacieuses (spurious correlations)#
La corrélation entre deux variables peut être entièrement due à une variable confondante — une troisième variable qui cause les deux.
# Exemple classique : taille de la ville → nombre de pompiers ET nombre d'incendies
# (les deux sont corrélés mais se causent-ils ?)
n_villes = 80
population = rng.exponential(scale=100_000, size=n_villes)
pompiers = 0.008 * population + rng.normal(0, 500, n_villes)
incendies = 0.002 * population + rng.normal(0, 100, n_villes)
# corrélation entre pompiers et incendies ?
r_pi, p_pi = stats.pearsonr(pompiers, incendies)
print(f"Corrélation pompiers / incendies : r = {r_pi:.3f} (p = {p_pi:.4f})")
print("→ Conclusion naive : les pompiers causent les incendies !")
print("→ Réalité : tous deux dépendent de la taille de la ville (confondante)")
# Après contrôle de la population (corrélation partielle) :
# r(pompiers, incendies | population) devrait être proche de 0
Corrélation pompiers / incendies : r = 0.832 (p = 0.0000)
→ Conclusion naive : les pompiers causent les incendies !
→ Réalité : tous deux dépendent de la taille de la ville (confondante)
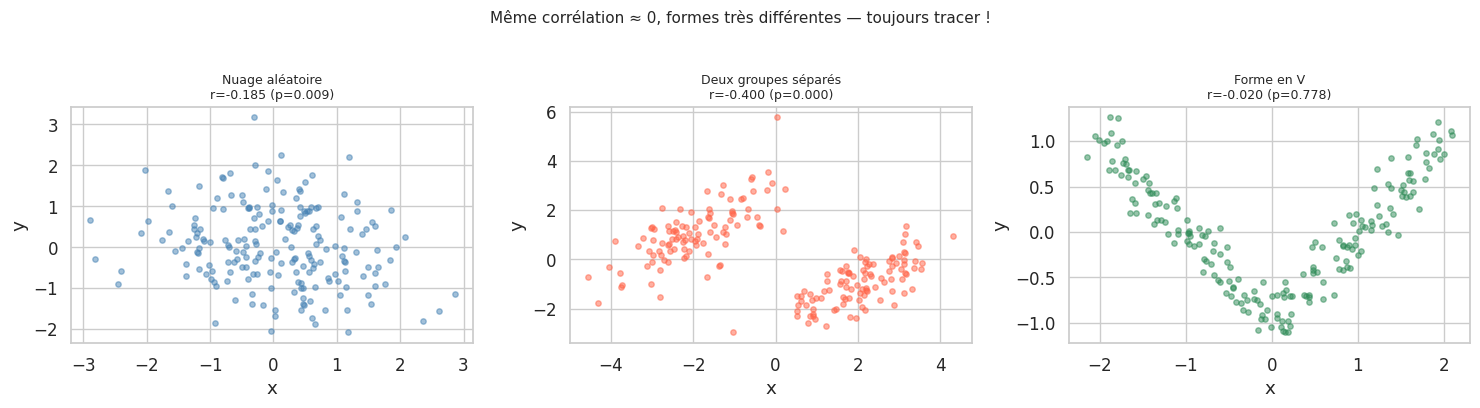
Dépendance non linéaire#
Pour détecter des relations non linéaires, deux mesures s’imposent.
Information mutuelle#
L”information mutuelle \(I(X; Y)\) mesure la réduction d’incertitude sur \(Y\) apportée par la connaissance de \(X\) :
Elle est nulle si et seulement si \(X\) et \(Y\) sont indépendants, quel que soit le type de relation. sklearn.feature_selection.mutual_info_regression en donne une estimation.
Distance correlation#
La distance correlation (Székely, 2007) vaut 0 si et seulement si les variables sont indépendantes (sous hypothèse de distribution à variance finie). Elle détecte des dépendances linéaires et non linéaires.
from sklearn.feature_selection import mutual_info_regression
# Comparaison sur plusieurs types de relations
n = 300
x_lin = rng.uniform(-3, 3, n)
relations = {
"Linéaire (y=x)": x_lin + rng.normal(0, 0.5, n),
"Quadratique (y=x²)": x_lin**2 + rng.normal(0, 0.5, n),
"Sinusoïdale": np.sin(x_lin * 2) + rng.normal(0, 0.2, n),
"Indépendante": rng.normal(0, 1, n),
}
print(f"{'Relation':30s} {'Pearson':>10} {'Spearman':>10} {'MI (est.)':>12}")
print("-" * 65)
for nom, y in relations.items():
r_p, _ = stats.pearsonr(x_lin, y)
r_s, _ = stats.spearmanr(x_lin, y)
mi = mutual_info_regression(x_lin.reshape(-1, 1), y, random_state=0)[0]
print(f"{nom:30s} {r_p:>10.3f} {r_s:>10.3f} {mi:>12.4f}")
Relation Pearson Spearman MI (est.)
-----------------------------------------------------------------
Linéaire (y=x) 0.955 0.958 1.1830
Quadratique (y=x²) -0.119 -0.090 1.4419
Sinusoïdale -0.371 -0.367 1.1241
Indépendante 0.042 0.046 0.0097
Corrélation partielle#
La corrélation partielle entre \(X\) et \(Y\) contrôlant \(Z\) mesure la relation entre \(X\) et \(Y\) une fois supprimée l’influence linéaire de \(Z\) sur les deux.
if HAS_PINGOUIN:
# Corrélation partielle logements : surface et prix en contrôlant nb_pieces
result = pg.partial_corr(data=df, x="surface", y="prix", covar="nb_pieces")
print("Corrélation partielle (surface, prix | nb_pieces) avec pingouin :")
print(result.to_string())
print()
# Version manuelle
r_sp, _ = stats.pearsonr(df["surface"], df["prix"])
r_sn, _ = stats.pearsonr(df["surface"], df["nb_pieces"])
r_pn, _ = stats.pearsonr(df["prix"], df["nb_pieces"])
r_partielle = (r_sp - r_sn * r_pn) / np.sqrt((1 - r_sn**2) * (1 - r_pn**2))
print(f"Corrélation brute (surface, prix) : {r_sp:.4f}")
print(f"Corrélation partielle (surface, prix | nb_pièces) : {r_partielle:.4f}")
print()
print("Après contrôle du nombre de pièces, la corrélation surface-prix diminue,")
print("car une partie de la relation passait par l'intermédiaire des pièces.")
Corrélation partielle (surface, prix | nb_pieces) avec pingouin :
n r CI95 p_val
pearson 300 0.782173 [0.73, 0.82] 5.580129e-63
Corrélation brute (surface, prix) : 0.9497
Corrélation partielle (surface, prix | nb_pièces) : 0.7822
Après contrôle du nombre de pièces, la corrélation surface-prix diminue,
car une partie de la relation passait par l'intermédiaire des pièces.
Matrice de corrélation complète avec tests (pingouin)#
if HAS_PINGOUIN:
# Matrice de corrélation avec p-valeurs via pingouin
corr_pg = pg.pairwise_corr(df[variables], method="pearson")
print("Corrélations paires avec pingouin (extrait) :")
print(corr_pg[["X", "Y", "r", "CI95", "p_unc", "BF10"]].head(10).to_string())
Corrélations paires avec pingouin (extrait) :
X Y r CI95 p_unc BF10
0 prix surface 0.949689 [0.94, 0.96] 2.747474e-152 nan
1 prix nb_pieces 0.867218 [0.84, 0.89] 3.031094e-92 3.182e+88
2 prix etage -0.021193 [-0.13, 0.09] 7.146808e-01 0.077
3 prix annee_construction 0.089553 [-0.02, 0.2] 1.216849e-01 0.238
4 surface nb_pieces 0.929791 [0.91, 0.94] 2.233573e-131 2.206e+127
5 surface etage -0.026364 [-0.14, 0.09] 6.492426e-01 0.08
6 surface annee_construction 0.060889 [-0.05, 0.17] 2.931643e-01 0.125
7 nb_pieces etage -0.025774 [-0.14, 0.09] 6.565823e-01 0.08
8 nb_pieces annee_construction 0.054899 [-0.06, 0.17] 3.433207e-01 0.113
9 etage annee_construction -0.048451 [-0.16, 0.07] 4.030520e-01 0.102
Récapitulatif : quelle corrélation choisir ?
Situation |
Recommandation |
|---|---|
Relation linéaire, données normales, pas d’outliers |
Pearson |
Relation monotone, données ordinales, outliers présents |
Spearman |
Petit échantillon, données ordinales |
Kendall |
Relation non linéaire quelconque |
Information mutuelle, distance correlation |
Contrôler une variable confondante |
Corrélation partielle (Pearson ou Spearman) |
Règle d’or : calculer la corrélation est facile ; l’interpréter est difficile. Tracez toujours le scatter plot. Corrélation forte ≠ causalité. Corrélation nulle ≠ indépendance.
La corrélation est un outil de description d’une relation, pas d’une explication. Comprendre la causalité nécessite un cadre différent — expériences randomisées, études causales (graphes de causalité, potentiel d’outcome) — qui dépasse le cadre de ce chapitre mais dont les principes fondamentaux seront abordés dans le chapitre sur l’A/B testing.