Plans d’expérience et A/B testing#
Le A/B testing est devenu la méthode de référence pour prendre des décisions basées sur les données dans le monde du produit numérique : quelle version d’une page d’accueil génère plus d’inscriptions ? Quelle formulation d’un bouton augmente le taux de clic ? Derrière ces questions pratiques se cachent des fondements statistiques rigoureux — ceux des plans d’expérience — dont la maîtrise est indispensable pour éviter de fausses conclusions coûteuses.
Principes des plans d’expérience#
Un plan d’expérience est un protocole rigoureux pour comparer des conditions expérimentales tout en contrôlant les sources de variabilité. Quatre principes fondamentaux, formalisés par R.A. Fisher dans les années 1920, restent au cœur de tout design expérimental :
Les quatre principes de Fisher#
1. Randomisation L’affectation des sujets aux conditions (traitement A ou B) doit être aléatoire. La randomisation équilibre en moyenne toutes les variables confondantes — connues et inconnues — entre les groupes. Sans elle, tout effet observé peut être dû à un biais de sélection.
2. Contrôle Un groupe contrôle (ou placebo) permet d’isoler l’effet du traitement de l’effet temporel, du régression vers la moyenne, de l’effet Hawthorne, etc.
3. Réplication Répéter les mesures augmente la puissance statistique (capacité à détecter un effet réel) et permet d’estimer la variabilité naturelle du phénomène.
4. Blocage Regrouper des sujets similaires dans des blocs avant de randomiser réduit la variabilité résiduelle. Exemple : bloquer par plateforme (mobile/desktop) avant d’assigner les utilisateurs à A ou B.
A/B testing : définition opérationnelle#
Les étapes d’un A/B test#
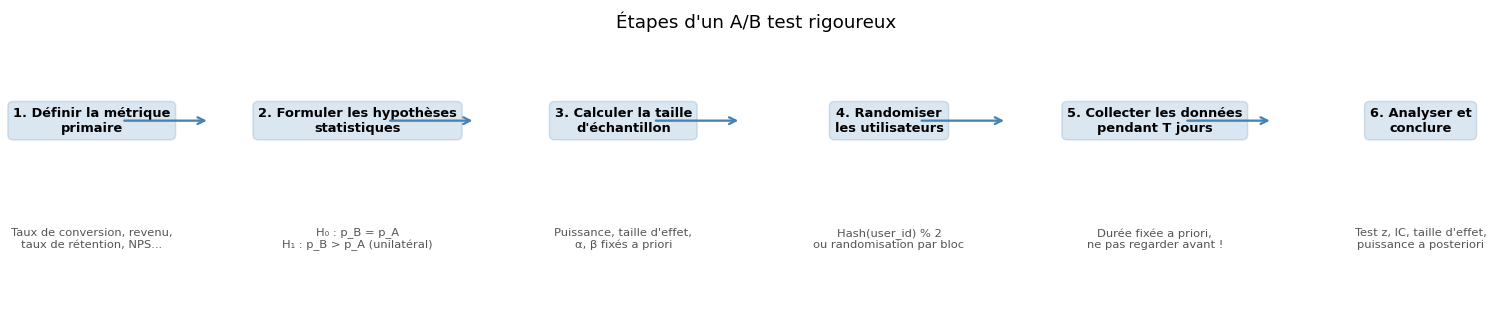
Métrique primaire vs métriques secondaires#
Choisir une seule métrique primaire avant de lancer le test est crucial. Analyser simultanément de nombreuses métriques après le test revient à faire des comparaisons multiples — le taux de faux positifs explose (voir chapitre 8). Les métriques secondaires servent à comprendre le mécanisme, pas à décider.
Calcul de la taille d’échantillon#
Formule pour deux proportions#
Pour un test bilatéral comparant deux taux de conversion \(p_A\) et \(p_B\) :
où :
\(z_{\alpha/2}\) : quantile normal pour le niveau de risque α (typiquement 1.96 pour α = 5%)
\(z_\beta\) : quantile normal pour la puissance souhaitée (0.84 pour 80%, 1.28 pour 90%)
\(p_A\) : taux de conversion du groupe contrôle (baseline)
\(p_B\) : taux de conversion attendu sous H₁ (= \(p_A\) + effet minimal détectable)
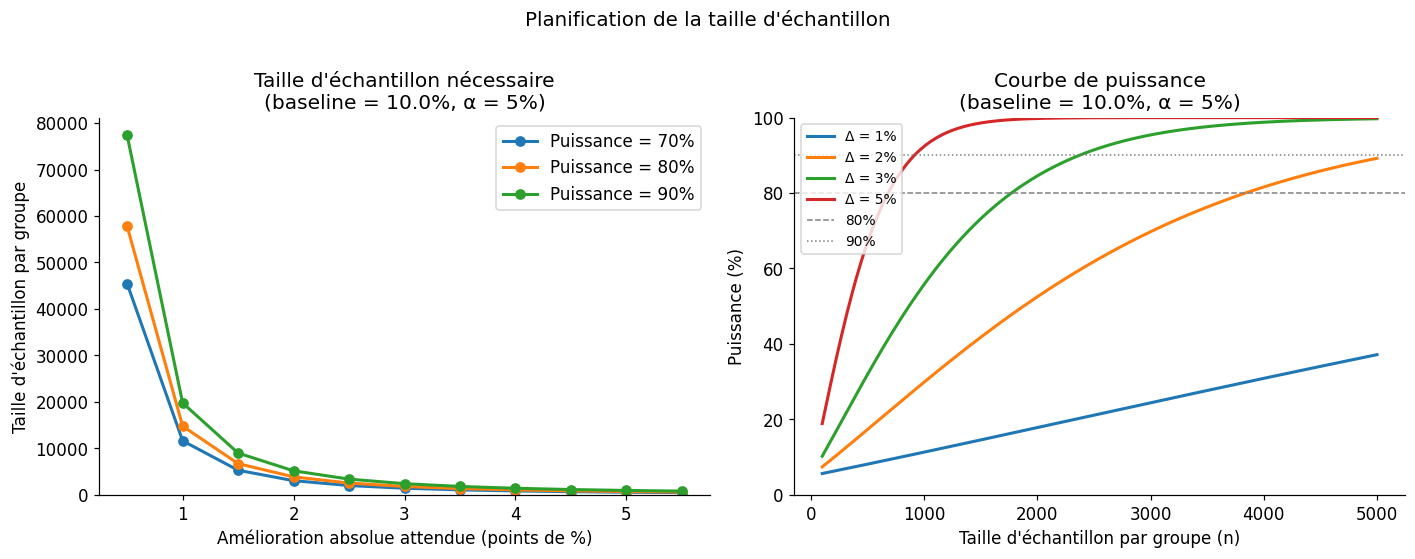
Table : taille par groupe (α=5%, puissance=80%, baseline=10%)
Δ absolu | n/groupe | n total
------------------------------------
+1% | 14,749 | 29,498
+2% | 3,839 | 7,678
+3% | 1,772 | 3,544
+5% | 683 | 1,366
+10% | 197 | 394
Règle pratique
Pour un A/B test sur un taux de conversion de 10%, détecter une amélioration de 2 points (20% d’amélioration relative) à puissance 80% requiert environ 3 800 utilisateurs par groupe, soit 7 600 au total. Si votre trafic est de 500 visiteurs/jour, il faudra au moins 15 jours — et c’est sans regarder les résultats avant la fin !
Le problème du « peeking » (regarder en cours de route)#
Pourquoi c’est un problème#
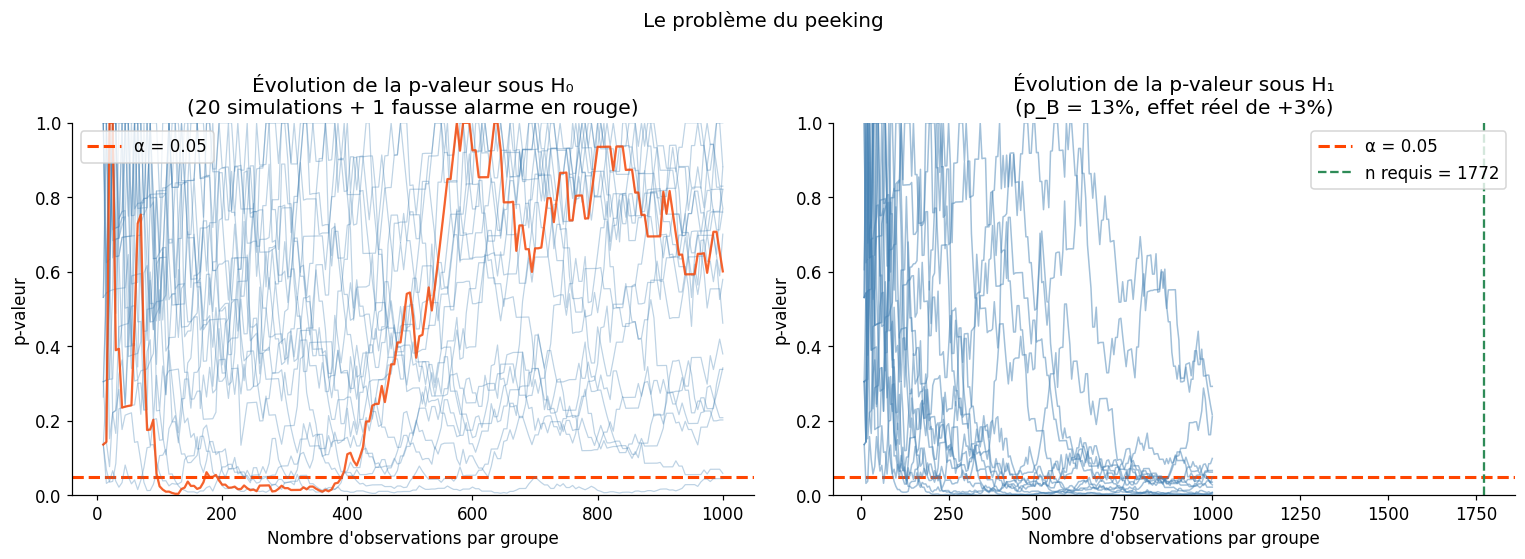
L’intuition dit qu’il serait utile d’arrêter le test dès que \(p < 0.05\). C’est l’une des erreurs les plus répandues en A/B testing. En regardant les résultats à plusieurs reprises et en s’autorisant à arrêter si \(p < \alpha\), le taux de faux positifs réel explose bien au-delà de α.
Taux de faux positifs — test standard (n fixé) : 4.4%
Taux de faux positifs — peeking (arrêt si p<5%) : 40.8%
Alpha spending et tests séquentiels#
Pour les situations où il est opérationnellement nécessaire de regarder les résultats en cours de route (tests longs, décisions urgentes), des méthodes d”alpha spending permettent de distribuer le budget d’erreur de type I entre les analyses intermédiaires.
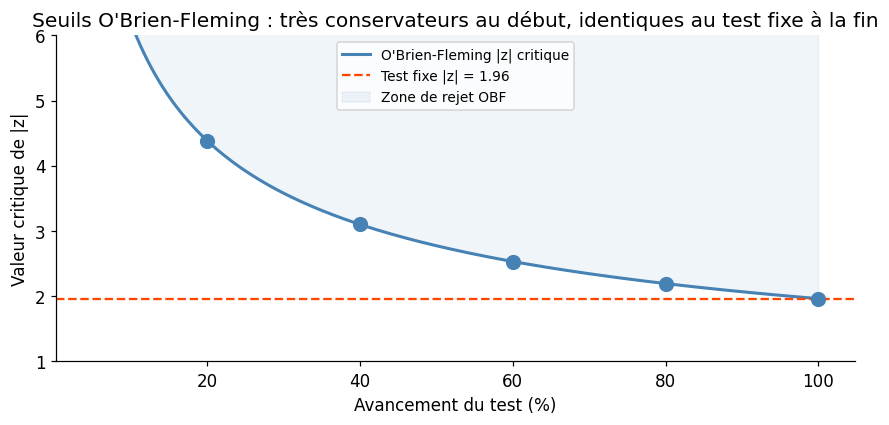
Procédure de O’Brien-Fleming : les seuils critiques sont très conservateurs au début (ex : \(\alpha_1 = 0.001\), \(\alpha_2 = 0.005\)) et s’assouplissent à mesure que l’on approche du terme prévu, de sorte que le budget α total reste 5%.
SPRT (Sequential Probability Ratio Test, Wald 1945) : à chaque observation, on calcule le rapport de vraisemblance \(\Lambda_n\) et on arrête si \(\Lambda_n \geq B\) (rejeter H₀) ou \(\Lambda_n \leq A\) (accepter H₀). Les bornes \(A = \beta/(1-\alpha)\) et \(B = (1-\beta)/\alpha\) garantissent les erreurs α et β désirées.
Always-valid p-values (méthode d’anytime-valid inference) : des variantes récentes utilisent des e-valeurs (e-values) pour produire des p-valeurs valides à tout moment de l’observation.
Seuils O'Brien-Fleming (α=5%, 5 analyses)
Temps relatif | |z| critique | p équivalent
------------------------------------------------
0.2 | 4.383 | 0.0000
0.4 | 3.099 | 0.0019
0.6 | 2.530 | 0.0114
0.8 | 2.191 | 0.0284
1.0 | 1.960 | 0.0500
Biais courants en A/B testing#
Effet de nouveauté (novelty effect)#
Les utilisateurs réagissent à la nouveauté d’une interface, indépendamment de sa qualité réelle. Un bouton de couleur différente peut générer plus de clics simplement parce qu’il attire l’œil, mais l’effet disparaît après quelques jours d’exposition. Solution : s’assurer que le test dure suffisamment longtemps (au moins 2 semaines) et vérifier la cohérence de l’effet entre utilisateurs nouveaux et habitués.
Paradoxe de Simpson#
# Illustration du paradoxe de Simpson en A/B testing
data = {
'Segment' : ['Mobile', 'Mobile', 'Desktop', 'Desktop', 'Total', 'Total'],
'Variante' : ['A', 'B'] * 3,
'Visiteurs' : [8000, 2000, 2000, 8000, 10000, 10000],
'Conversions': [400, 80, 200, 640, 600, 720],
}
df_simpson = pd.DataFrame(data)
df_simpson['Taux'] = df_simpson['Conversions'] / df_simpson['Visiteurs']
print("Paradoxe de Simpson — A/B test segmenté par appareil\n")
print(f"{'Segment':>10} | {'Variante':>10} | {'Visiteurs':>10} | {'Conversions':>12} | {'Taux':>8}")
print("-" * 58)
for _, row in df_simpson.iterrows():
print(f"{row['Segment']:>10} | {row['Variante']:>10} | {row['Visiteurs']:>10,} | "
f"{row['Conversions']:>12,} | {row['Taux']:>8.1%}")
print("\n→ Sur mobile : A=5.0% > B=4.0% (A gagne)")
print("→ Sur desktop : A=10.0% < B=8.0% (A gagne... non, B=8% < A=10%)")
print("→ En agrégé : A=6.0% < B=7.2% (B semble gagner)")
print("\nCause : la variante B reçoit plus de visiteurs desktop (taux naturellement plus élevé).")
Paradoxe de Simpson — A/B test segmenté par appareil
Segment | Variante | Visiteurs | Conversions | Taux
----------------------------------------------------------
Mobile | A | 8,000 | 400 | 5.0%
Mobile | B | 2,000 | 80 | 4.0%
Desktop | A | 2,000 | 200 | 10.0%
Desktop | B | 8,000 | 640 | 8.0%
Total | A | 10,000 | 600 | 6.0%
Total | B | 10,000 | 720 | 7.2%
→ Sur mobile : A=5.0% > B=4.0% (A gagne)
→ Sur desktop : A=10.0% < B=8.0% (A gagne... non, B=8% < A=10%)
→ En agrégé : A=6.0% < B=7.2% (B semble gagner)
Cause : la variante B reçoit plus de visiteurs desktop (taux naturellement plus élevé).
Contamination entre groupes#
Lorsque les utilisateurs peuvent se parler (réseau social) ou partager un compte, l”effet de contamination (spillover) invalide la comparaison. Solution : randomiser par unité d’expérimentation adaptée (cluster randomization : par ménage, par ville, par entreprise).
Biais de survie#
Si certains utilisateurs abandonnent le test avant la fin (notamment dans le groupe contrôle ou parce qu’ils sont frustrés), l’échantillon final n’est plus représentatif. Les statistiques d’attrition doivent être analysées avant les statistiques de performance.
Plans factoriels et tests multivariés (MVT)#
Plans factoriels#
Un plan factoriel teste plusieurs facteurs simultanément. Un design \(2^k\) teste \(k\) facteurs binaires en combinant toutes les combinaisons possibles, permettant d’estimer :
Les effets principaux de chaque facteur
Les effets d’interaction entre facteurs
Exemple : tester simultanément la couleur du bouton (rouge/bleu) et le texte (« Acheter maintenant » / « Découvrir ») génère 4 conditions au lieu de lancer 2 tests séquentiels, avec la possibilité de détecter une interaction (ex : le texte court fonctionne mieux avec le rouge).
Tests multivariés (MVT)#
Le MVT (Multivariate Testing) permet de tester plusieurs éléments d’une page simultanément. La différence avec le plan factoriel est surtout terminologique dans le monde du produit :
A/B test : 1 facteur, 2 niveaux
A/B/n test : 1 facteur, n niveaux
MVT : plusieurs facteurs, tous les niveaux combinés
L’attribution des effets requiert une analyse de la variance multifactorielle (ANOVA à plusieurs facteurs ou régression avec interactions).
Analyse des résultats#
Simulation complète d’un A/B test#
=======================================================
RAPPORT D'A/B TEST
=======================================================
Groupe A (contrôle) : n=1,772, conv=0.108 (10.78%)
Groupe B (variante) : n=1,772, conv=0.130 (12.98%)
Δ absolu : +0.0220 (+2.20%)
Δ relatif : +20.4%
IC 95% : [0.07%, 4.33%]
z-stat : 2.025
p-valeur : 0.0429
Décision (α=5%) : Rejeter H₀ ✓
=======================================================
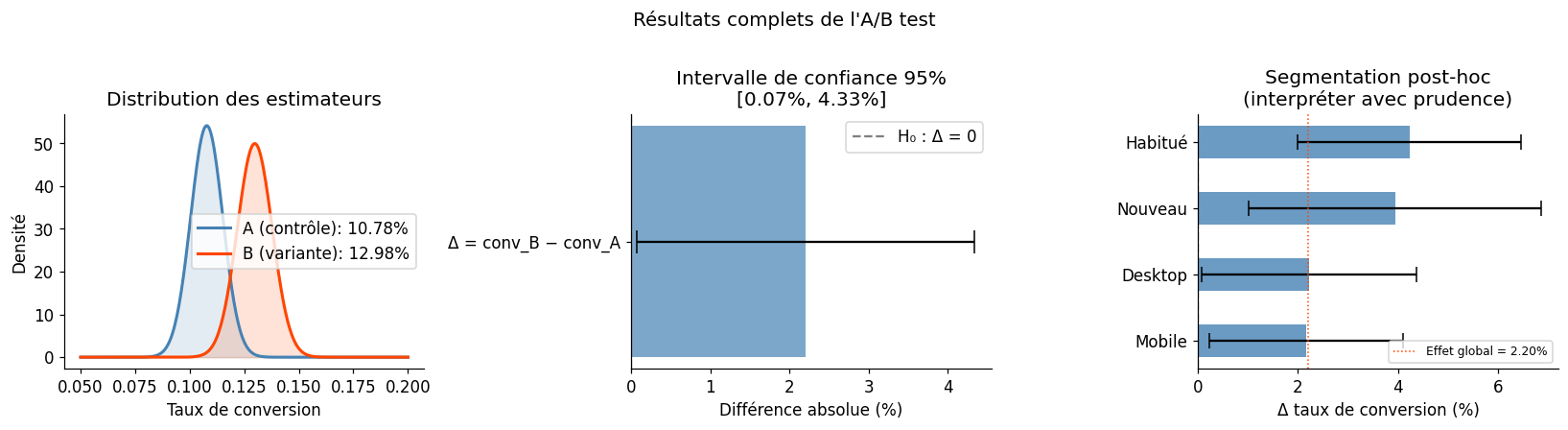
Segmentation post-hoc : prudence !
L’analyse par segment après le test constitue des comparaisons multiples non planifiées. Si vous analysez 10 segments, vous attendez statistiquement 0.5 faux positif sous H₀. Les résultats de segmentation post-hoc doivent être considérés comme exploratoires et validés par un test préenregistré.
Récapitulatif et checklist#
