Régression linéaire multiple#
La régression linéaire simple est un outil puissant, mais le monde réel est rarement aussi simple qu’une seule cause. Le prix d’un logement dépend non seulement de la surface, mais aussi du quartier, du nombre de pièces, de l’état du bien. La consommation énergétique d’un bâtiment dépend des températures, de l’isolation, du nombre d’occupants. La régression multiple permet de modéliser ces relations à plusieurs dimensions, d’estimer l’effet propre de chaque variable (toutes choses égales par ailleurs) et de construire des modèles prédictifs robustes.
Extension au cas multivarié#
Le modèle de régression linéaire multiple est : $\(Y_i = \beta_0 + \beta_1 X_{i1} + \beta_2 X_{i2} + \cdots + \beta_p X_{ip} + \varepsilon_i\)$
ou en notation matricielle : \(Y = X\beta + \varepsilon\) où \(X\) est la matrice de design \((n \times (p+1))\).
Les estimateurs MCO sont : \(\hat{\beta} = (X^TX)^{-1}X^TY\)
Interprétation des coefficients : \(\hat{\beta}_j\) est la variation moyenne de \(Y\) pour une augmentation d’une unité de \(X_j\), toutes les autres variables maintenues constantes — la notion de ceteris paribus.
# Données immobilières synthétiques avec plusieurs prédicteurs
n = 200
surface = rng.uniform(30, 200, n)
nb_pieces = np.round(surface / 30 + rng.normal(0, 0.8, n)).clip(1, 8)
distance_centre = rng.uniform(1, 25, n)
etage = rng.integers(0, 15, n)
# Quartier (variable catégorielle)
quartier = rng.choice(['Centre', 'Nord', 'Sud', 'Est'], n)
quartier_coef = {'Centre': 30, 'Nord': 0, 'Sud': 10, 'Est': -5}
prix = (80
+ 2.8 * surface
+ 5.0 * nb_pieces
- 1.5 * distance_centre
+ 0.5 * etage
+ np.array([quartier_coef[q] for q in quartier])
+ rng.normal(0, 20, n))
df_immo = pd.DataFrame({
'prix': prix,
'surface': surface,
'nb_pieces': nb_pieces,
'distance_centre': distance_centre,
'etage': etage,
'quartier': quartier
})
# Modèle avec toutes les variables
model_full = smf.ols(
'prix ~ surface + nb_pieces + distance_centre + etage + C(quartier)',
data=df_immo
).fit()
print(model_full.summary())
OLS Regression Results
==============================================================================
Dep. Variable: prix R-squared: 0.982
Model: OLS Adj. R-squared: 0.981
Method: Least Squares F-statistic: 1477.
Date: Wed, 01 Apr 2026 Prob (F-statistic): 2.99e-163
Time: 22:12:10 Log-Likelihood: -881.58
No. Observations: 200 AIC: 1779.
Df Residuals: 192 BIC: 1806.
Df Model: 7
Covariance Type: nonrobust
=======================================================================================
coef std err t P>|t| [0.025 0.975]
---------------------------------------------------------------------------------------
Intercept 102.8693 5.689 18.081 0.000 91.648 114.091
C(quartier)[T.Est] -27.4337 4.037 -6.795 0.000 -35.397 -19.471
C(quartier)[T.Nord] -28.7418 3.831 -7.503 0.000 -36.298 -21.186
C(quartier)[T.Sud] -18.5933 4.074 -4.564 0.000 -26.629 -10.557
surface 2.7457 0.068 40.509 0.000 2.612 2.879
nb_pieces 7.6170 1.745 4.365 0.000 4.175 11.059
distance_centre -1.6241 0.213 -7.611 0.000 -2.045 -1.203
etage 0.6940 0.341 2.035 0.043 0.021 1.367
==============================================================================
Omnibus: 4.767 Durbin-Watson: 1.803
Prob(Omnibus): 0.092 Jarque-Bera (JB): 6.065
Skew: -0.113 Prob(JB): 0.0482
Kurtosis: 3.823 Cond. No. 578.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Multicolinéarité#
Le problème#
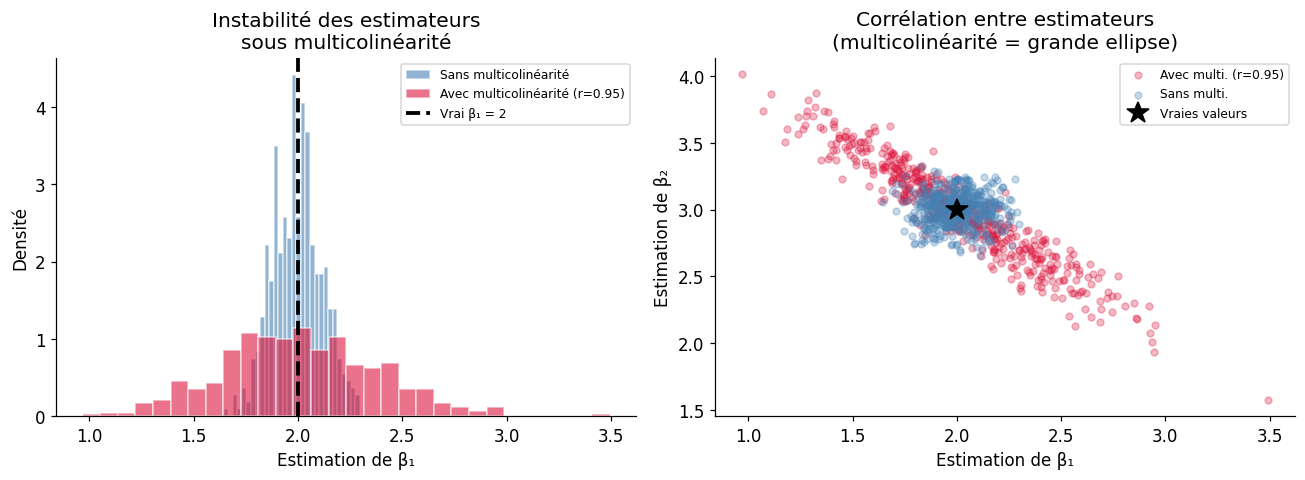
Lorsque deux prédicteurs sont fortement corrélés, leur effet propre devient difficile à estimer : les estimateurs sont instables (forte variance), les intervalles de confiance s’élargissent, et les signes des coefficients peuvent s’inverser.
VIF — Variance Inflation Factor#
Le VIF mesure le facteur par lequel la variance de \(\hat{\beta}_j\) est multipliée par rapport à un modèle sans corrélation entre prédicteurs :
où \(R^2_j\) est le \(R^2\) de la régression de \(X_j\) sur tous les autres prédicteurs.
VIF |
Interprétation |
|---|---|
1 |
Aucune multicolinéarité |
1–5 |
Modérée, généralement acceptable |
5–10 |
Forte, à surveiller |
> 10 |
Sévère, problématique |
# Calculer les VIF
X_vif = df_immo[['surface', 'nb_pieces', 'distance_centre', 'etage']].copy()
X_vif_const = sm.add_constant(X_vif)
vif_data = pd.DataFrame({
'Variable': X_vif.columns,
'VIF': [variance_inflation_factor(X_vif_const.values, i + 1)
for i in range(len(X_vif.columns))]
})
print("VIF des prédicteurs continus :")
print(vif_data.to_string(index=False))
print()
print("Note : surface et nb_pieces sont corrélés → VIF > 1")
print(f"Corrélation surface / nb_pieces : {np.corrcoef(surface, nb_pieces)[0,1]:.3f}")
VIF des prédicteurs continus :
Variable VIF
surface 5.059589
nb_pieces 5.037644
distance_centre 1.047847
etage 1.058014
Note : surface et nb_pieces sont corrélés → VIF > 1
Corrélation surface / nb_pieces : 0.895
# Simulation : effet de la multicolinéarité sur les coefficients
rng_mc = np.random.default_rng(55)
n_mc = 100
# Cas 1 : prédicteurs indépendants
x1_ind = rng_mc.normal(0, 1, n_mc)
x2_ind = rng_mc.normal(0, 1, n_mc)
y_mc = 2 * x1_ind + 3 * x2_ind + rng_mc.normal(0, 1, n_mc)
model_ind = smf.ols('y ~ x1 + x2',
data=pd.DataFrame({'y': y_mc, 'x1': x1_ind, 'x2': x2_ind})).fit()
# Cas 2 : prédicteurs fortement corrélés (r = 0.95)
x1_col = rng_mc.normal(0, 1, n_mc)
x2_col = 0.95 * x1_col + np.sqrt(1 - 0.95**2) * rng_mc.normal(0, 1, n_mc)
y_col = 2 * x1_col + 3 * x2_col + rng_mc.normal(0, 1, n_mc)
model_col = smf.ols('y ~ x1 + x2',
data=pd.DataFrame({'y': y_col, 'x1': x1_col, 'x2': x2_col})).fit()
print("Cas 1 — Prédicteurs indépendants (r = 0) :")
print(f" β₁ = {model_ind.params['x1']:.3f} ± {model_ind.bse['x1']:.3f} (vrai : 2)")
print(f" β₂ = {model_ind.params['x2']:.3f} ± {model_ind.bse['x2']:.3f} (vrai : 3)")
print()
print("Cas 2 — Prédicteurs corrélés (r = 0.95) :")
print(f" β₁ = {model_col.params['x1']:.3f} ± {model_col.bse['x1']:.3f} (vrai : 2)")
print(f" β₂ = {model_col.params['x2']:.3f} ± {model_col.bse['x2']:.3f} (vrai : 3)")
print()
print(f"L'erreur-type est {model_col.bse['x1']/model_ind.bse['x1']:.1f}× plus grande avec multicolinéarité")
Cas 1 — Prédicteurs indépendants (r = 0) :
β₁ = 1.886 ± 0.087 (vrai : 2)
β₂ = 2.946 ± 0.102 (vrai : 3)
Cas 2 — Prédicteurs corrélés (r = 0.95) :
β₁ = 2.410 ± 0.323 (vrai : 2)
β₂ = 2.629 ± 0.309 (vrai : 3)
L'erreur-type est 3.7× plus grande avec multicolinéarité
Variables catégorielles : encodage dummy#
Les variables catégorielles sont représentées par des variables indicatrices (dummy) : pour \(k\) catégories, on crée \(k-1\) variables binaires. La catégorie omise devient la variable de référence — tous les coefficients s’interprètent par rapport à elle.
# Modèle avec variable catégorielle quartier
# statsmodels / patsy gèrent automatiquement l'encodage avec C()
model_cat = smf.ols('prix ~ surface + C(quartier)', data=df_immo).fit()
print("Coefficients de la variable catégorielle 'quartier' :")
print("(référence automatique = première catégorie alphabétique : 'Centre')")
print()
for param, val, se, p in zip(model_cat.params.index,
model_cat.params.values,
model_cat.bse.values,
model_cat.pvalues.values):
if 'quartier' in param or 'Intercept' in param:
print(f" {param:<35} = {val:8.2f} ± {se:5.2f} (p={p:.4f})")
print()
print("Interprétation :")
print(" Quartier Nord est la référence (β = 0 par convention)")
print(" Quartier Centre : survaleur de ~30 k€ par rapport au Nord")
print(" Quartier Sud : survaleur de ~10 k€ par rapport au Nord")
# Encodage explicite pour illustration
dummies = pd.get_dummies(df_immo['quartier'], drop_first=True)
print(f"\nExemple d'encodage (drop_first=True, ref = {df_immo['quartier'].value_counts().index[-1]}) :")
print(dummies.head(5))
Coefficients de la variable catégorielle 'quartier' :
(référence automatique = première catégorie alphabétique : 'Centre')
Intercept = 87.65 ± 5.19 (p=0.0000)
C(quartier)[T.Est] = -30.69 ± 4.69 (p=0.0000)
C(quartier)[T.Nord] = -28.62 ± 4.51 (p=0.0000)
C(quartier)[T.Sud] = -18.20 ± 4.80 (p=0.0002)
Interprétation :
Quartier Nord est la référence (β = 0 par convention)
Quartier Centre : survaleur de ~30 k€ par rapport au Nord
Quartier Sud : survaleur de ~10 k€ par rapport au Nord
Exemple d'encodage (drop_first=True, ref = Sud) :
Est Nord Sud
0 False True False
1 True False False
2 False False True
3 True False False
4 False True False
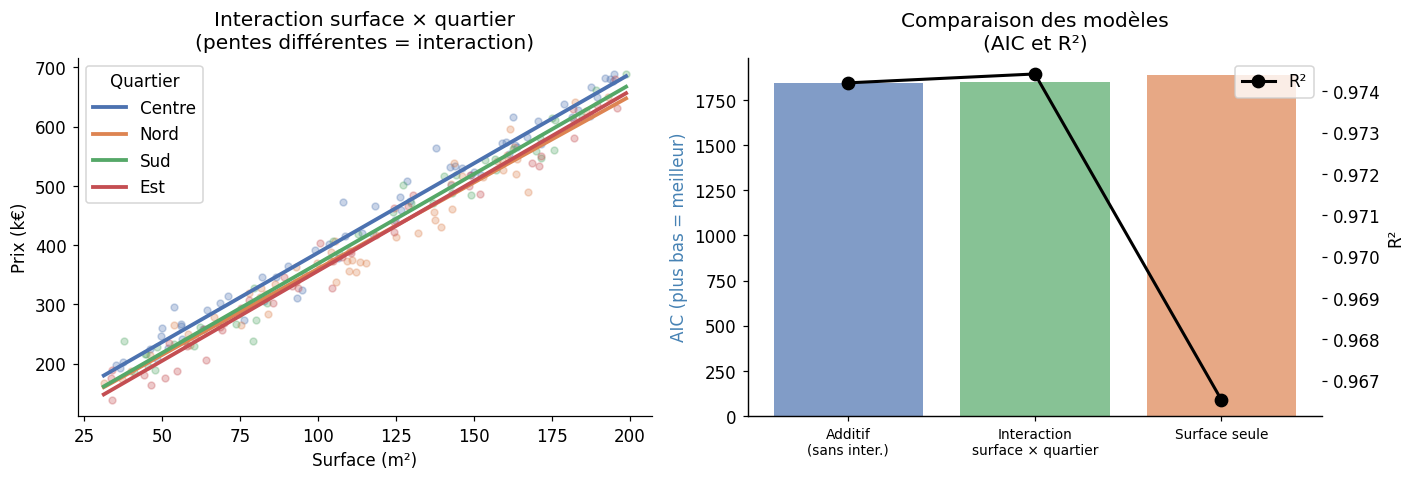
Interactions#
Un terme d’interaction \(X_1 \times X_2\) capture l’effet de \(X_1\) qui change en fonction du niveau de \(X_2\). Sans interaction, l’effet de \(X_1\) est le même quelle que soit la valeur de \(X_2\) (hypothèse souvent trop simpliste).
Modèle avec interaction surface × quartier :
R² = 0.9744
AIC = 1846.9
Sélection de variables et régularisation#
Le problème de la sélection#
Plus on ajoute de prédicteurs, plus le \(R^2\) augmente — mais le modèle peut sur-ajuster les données d’entraînement et mal se généraliser. L’objectif est de trouver le modèle le plus parcimonieux qui capture les vraies relations.
AIC et BIC#
Le BIC pénalise plus fortement les modèles complexes que l’AIC (facteur \(\ln(n)\) vs 2). On préfère le modèle avec l’AIC/BIC le plus bas.
# Créer quelques prédicteurs supplémentaires (dont certains sans effet réel)
rng_sel = np.random.default_rng(123)
df_immo['bruit1'] = rng_sel.normal(0, 1, n)
df_immo['bruit2'] = rng_sel.normal(0, 1, n)
df_immo['bruit3'] = rng_sel.normal(0, 1, n)
modeles_candidats = {
'M1: surface seulement': 'prix ~ surface',
'M2: + nb_pieces': 'prix ~ surface + nb_pieces',
'M3: + distance': 'prix ~ surface + nb_pieces + distance_centre',
'M4: + etage': 'prix ~ surface + nb_pieces + distance_centre + etage',
'M5: + quartier': 'prix ~ surface + nb_pieces + distance_centre + etage + C(quartier)',
'M6: + bruit1': 'prix ~ surface + nb_pieces + distance_centre + etage + C(quartier) + bruit1',
'M7: + bruit1,2,3': 'prix ~ surface + nb_pieces + distance_centre + etage + C(quartier) + bruit1 + bruit2 + bruit3',
}
comparaison = []
for nom, formule in modeles_candidats.items():
mod = smf.ols(formule, data=df_immo).fit()
comparaison.append({
'Modèle': nom,
'p': mod.df_model,
'R²': mod.rsquared,
'R² ajusté': mod.rsquared_adj,
'AIC': mod.aic,
'BIC': mod.bic,
})
df_comp = pd.DataFrame(comparaison)
print(df_comp.to_string(index=False))
print()
print(f"Meilleur AIC : {df_comp.loc[df_comp['AIC'].idxmin(), 'Modèle']}")
print(f"Meilleur BIC : {df_comp.loc[df_comp['BIC'].idxmin(), 'Modèle']}")
Modèle p R² R² ajusté AIC BIC
M1: surface seulement 1.0 0.966532 0.966363 1888.637239 1895.233874
M2: + nb_pieces 2.0 0.968781 0.968464 1876.730454 1886.625407
M3: + distance 3.0 0.974139 0.973743 1841.070400 1854.263670
M4: + etage 4.0 0.974875 0.974359 1837.297186 1853.788773
M5: + quartier 7.0 0.981767 0.981102 1779.167080 1805.553619
M6: + bruit1 8.0 0.981890 0.981131 1779.820001 1809.504857
M7: + bruit1,2,3 10.0 0.981928 0.980972 1783.389413 1819.670904
Meilleur AIC : M5: + quartier
Meilleur BIC : M5: + quartier
Régression Ridge (régularisation L2)#
La régression Ridge ajoute une pénalité proportionnelle au carré des coefficients :
La solution analytique est \(\hat{\beta}_{\text{Ridge}} = (X^TX + \lambda I)^{-1}X^Ty\). Ridge réduit les coefficients vers zéro mais ne les annule pas — utile pour la multicolinéarité.
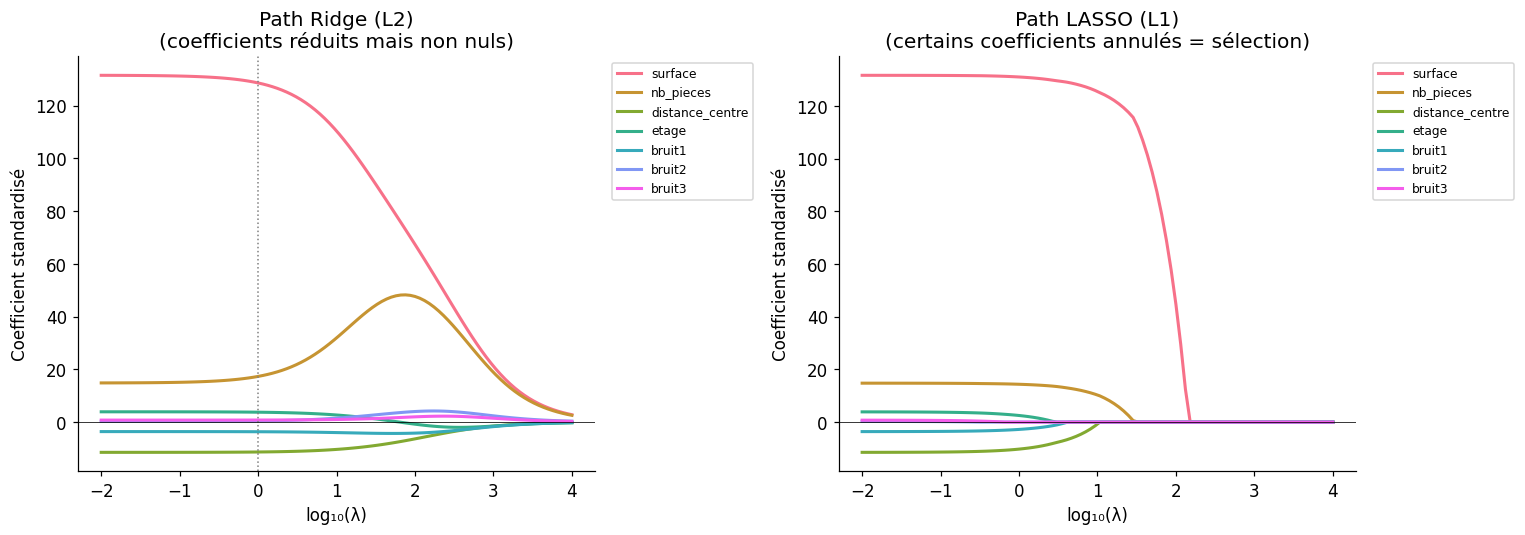
Régression LASSO : sélection automatique#
La régression LASSO (Least Absolute Shrinkage and Selection Operator) utilise une pénalité L1 :
La pénalité L1 produit des solutions sparse : certains coefficients sont exactement nuls. LASSO réalise simultanément la régularisation et la sélection de variables.
# Choix de lambda par validation croisée
from sklearn.linear_model import LassoCV, RidgeCV
lasso_cv = LassoCV(cv=5, max_iter=10000, random_state=42)
lasso_cv.fit(X_scaled, y_sk)
ridge_cv = RidgeCV(alphas=lambdas, cv=5)
ridge_cv.fit(X_scaled, y_sk)
print(f"LASSO — λ optimal (CV 5-fold) : {lasso_cv.alpha_:.4f}")
print(f"\nCoefficients LASSO optimaux :")
for feat, coef in zip(feature_cols, lasso_cv.coef_):
status = '← annulé' if abs(coef) < 1e-10 else ''
print(f" {feat:<20} = {coef:8.3f} {status}")
print(f"\nRidge — λ optimal (CV 5-fold) : {ridge_cv.alpha_:.4f}")
print(f"\nCoefficients Ridge optimaux :")
for feat, coef in zip(feature_cols, ridge_cv.coef_):
print(f" {feat:<20} = {coef:8.3f}")
LASSO — λ optimal (CV 5-fold) : 0.5078
Coefficients LASSO optimaux :
surface = 131.334
nb_pieces = 14.554
distance_centre = -10.874
etage = 3.178
bruit1 = -3.191
bruit2 = 0.000 ← annulé
bruit3 = 0.171
Ridge — λ optimal (CV 5-fold) : 0.0100
Coefficients Ridge optimaux :
surface = 131.541
nb_pieces = 14.845
distance_centre = -11.491
etage = 3.891
bruit1 = -3.619
bruit2 = 0.263
bruit3 = 0.743
Elastic Net : combiner Ridge et LASSO#
L’Elastic Net combine les pénalités L1 et L2 :
où \(\rho \in [0,1]\) contrôle le mélange : \(\rho = 1\) → LASSO, \(\rho = 0\) → Ridge.
from sklearn.linear_model import ElasticNetCV
enet_cv = ElasticNetCV(l1_ratio=[0.1, 0.5, 0.7, 0.9, 0.95, 1.0],
cv=5, max_iter=10000, random_state=42)
enet_cv.fit(X_scaled, y_sk)
print(f"Elastic Net — λ optimal : {enet_cv.alpha_:.4f}")
print(f"Elastic Net — ρ optimal (l1_ratio) : {enet_cv.l1_ratio_:.2f}")
print(f"\nCoefficients Elastic Net :")
for feat, coef in zip(feature_cols, enet_cv.coef_):
status = '← annulé' if abs(coef) < 1e-10 else ''
print(f" {feat:<20} = {coef:8.3f} {status}")
Elastic Net — λ optimal : 0.5078
Elastic Net — ρ optimal (l1_ratio) : 1.00
Coefficients Elastic Net :
surface = 131.334
nb_pieces = 14.554
distance_centre = -10.874
etage = 3.178
bruit1 = -3.191
bruit2 = 0.000 ← annulé
bruit3 = 0.171
Coefficient plot avec intervalles de confiance#
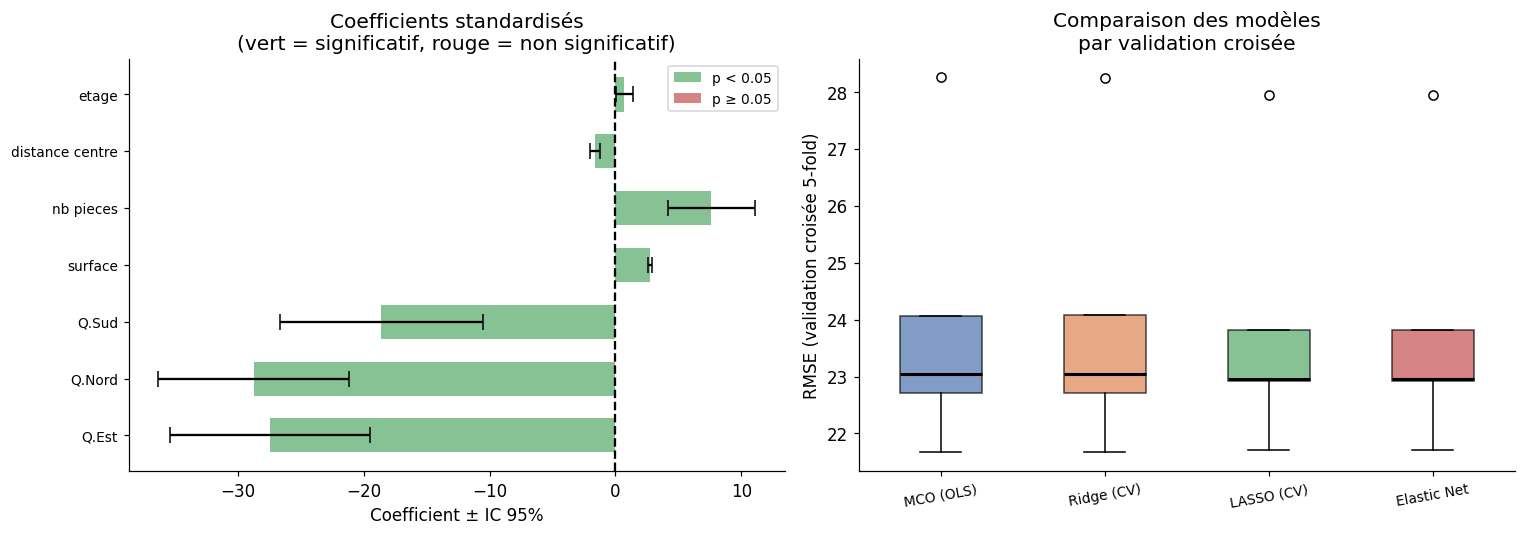
Validation croisée pour évaluer la régression#
La validation croisée donne une estimation honnête des performances hors-échantillon, sans nécessiter un jeu de test séparé.
# Validation croisée détaillée par fold
from sklearn.linear_model import LinearRegression
model_sk = LinearRegression()
X_mod = df_immo[['surface', 'nb_pieces', 'distance_centre', 'etage']].values
X_mod_s = StandardScaler().fit_transform(X_mod)
kf5 = KFold(n_splits=5, shuffle=True, random_state=42)
rmse_folds = []
r2_folds = []
mae_folds = []
fold_results = []
for fold, (train_idx, test_idx) in enumerate(kf5.split(X_mod_s)):
X_train, X_test = X_mod_s[train_idx], X_mod_s[test_idx]
y_train, y_test = y_sk[train_idx], y_sk[test_idx]
model_sk.fit(X_train, y_train)
y_pred = model_sk.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
r2 = r2_score(y_test, y_pred)
mae = np.mean(np.abs(y_test - y_pred))
fold_results.append({'Fold': fold+1, 'RMSE': rmse, 'MAE': mae, 'R²': r2,
'n_train': len(train_idx), 'n_test': len(test_idx)})
df_cv = pd.DataFrame(fold_results)
print("Résultats par fold (validation croisée 5-fold) :")
print(df_cv.to_string(index=False))
print()
print(f"RMSE moyen : {df_cv['RMSE'].mean():.2f} ± {df_cv['RMSE'].std():.2f} k€")
print(f"MAE moyen : {df_cv['MAE'].mean():.2f} ± {df_cv['MAE'].std():.2f} k€")
print(f"R² moyen : {df_cv['R²'].mean():.4f} ± {df_cv['R²'].std():.4f}")
Résultats par fold (validation croisée 5-fold) :
Fold RMSE MAE R² n_train n_test
1 23.025252 18.881093 0.972328 160 40
2 22.977301 19.566593 0.979299 160 40
3 24.455605 17.601153 0.974387 160 40
4 20.834665 15.668052 0.977454 160 40
5 27.708846 22.310198 0.963066 160 40
RMSE moyen : 23.80 ± 2.54 k€
MAE moyen : 18.81 ± 2.46 k€
R² moyen : 0.9733 ± 0.0063
Partial regression plots#
Les graphiques de régression partielle (added variable plots) montrent la relation nette entre un prédicteur et la réponse, après avoir retiré l’effet de tous les autres prédicteurs.
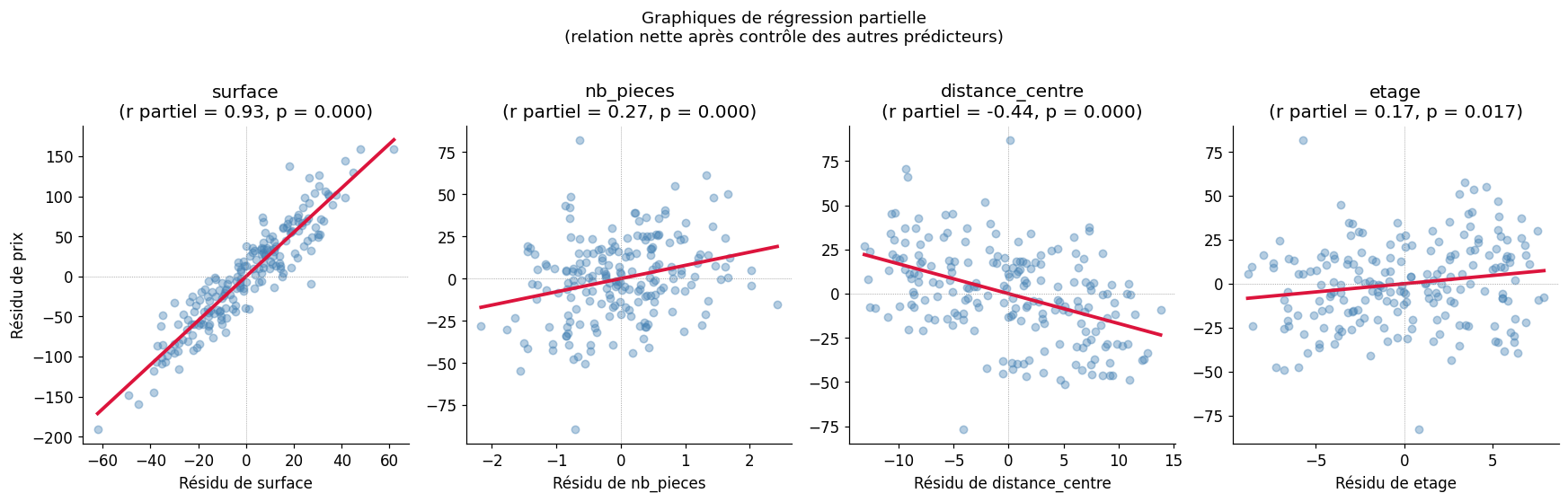
Résumé : choisir la méthode de régression#
Méthode Pénalité Sélection Multicolinéarité Hyperparamètre Quand l'utiliser
MCO (OLS) Aucune Non Sensible — Peu de variables, hypothèses vérifiées
Ridge L2 : λΣβ² Non Robuste λ (CV) Multicolinéarité, beaucoup de variables
LASSO L1 : λΣ|β| Oui (sparse) Sélectionne 1 var. λ (CV) Sélection automatique souhaitée
Elastic Net αρΣ|β| + α(1-ρ)Σβ²/2 Oui (sparse) Sélectionne groupe λ, ρ (CV) Corrélation ET sélection
Checklist régression multiple
Explorer les distributions et les corrélations entre prédicteurs (matrice de corrélation, pairplot)
Calculer les VIF pour détecter la multicolinéarité
Encoder correctement les variables catégorielles (dummy, variable de référence)
Sélectionner les variables (AIC/BIC, LASSO, théorie du domaine)
Examiner les diagnostics (résidus, QQ-plot, influence)
Valider hors-échantillon (validation croisée, R² out-of-sample)
Interpréter en termes de ceteris paribus et IC, pas seulement p-valeurs
Tester les interactions si des effets modificateurs sont attendus
Communiquer l’incertitude sur les prédictions (IC et IP)