Régression logistique#
Quand la réponse est oui ou non, le modèle doit l’être aussi.
Introduction#
La régression linéaire suppose une variable réponse continue et non bornée. Mais de nombreux problèmes pratiques impliquent des résultats binaires : un patient est malade ou sain, un crédit est remboursé ou en défaut, un email est spam ou légitime. Appliquer une régression linéaire à une variable indicatrice \(Y \in \{0, 1\}\) produit des prédictions en dehors de \([0, 1]\), viole l’hypothèse de normalité des résidus, et n’est pas interprétable comme une probabilité.
La régression logistique résout ce problème en modélisant directement \(P(Y = 1 \mid X)\) via une transformation qui confine les prédictions dans \((0, 1)\).
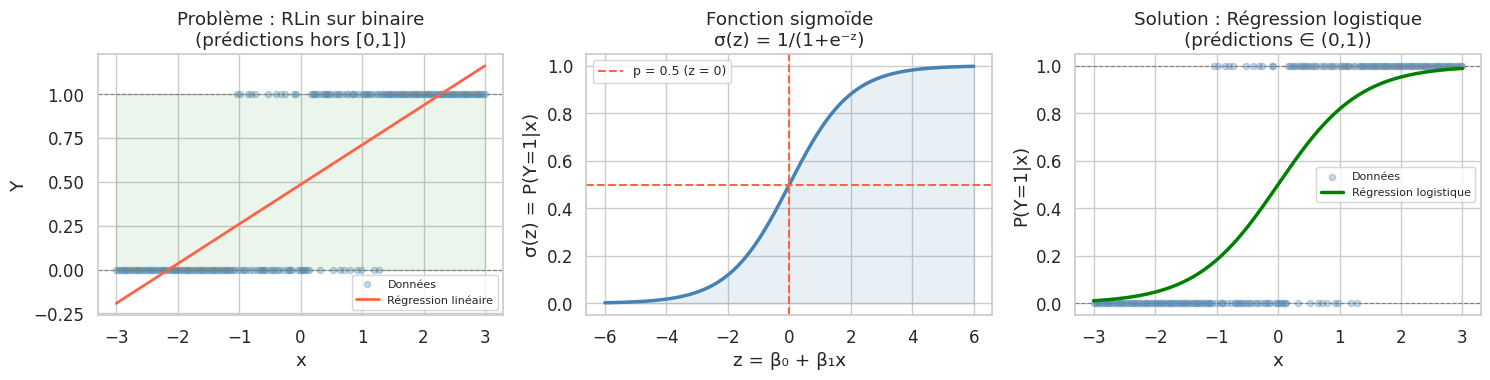
La fonction logistique et le modèle#
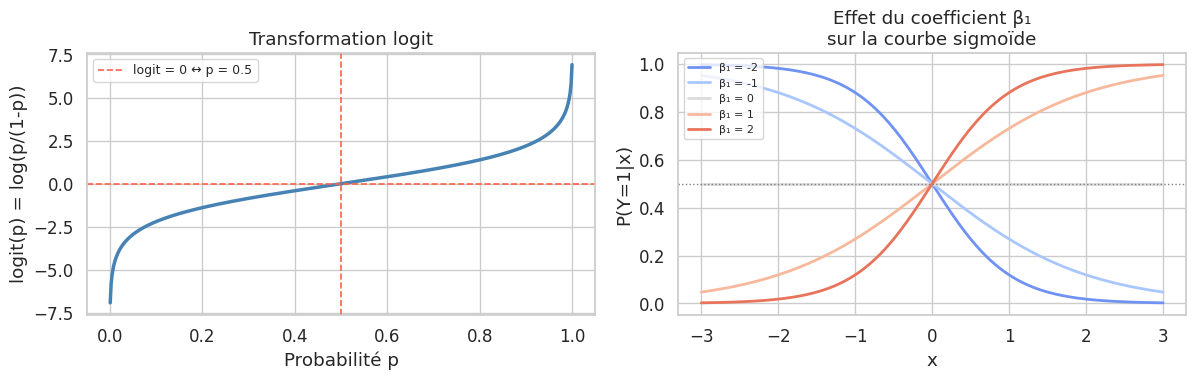
Du linéaire aux probabilités : le logit#
Le modèle de régression logistique postule :
La transformation inverse s’appelle le logit (ou log-odds) :
Le ratio \(p/(1-p)\) est la cote (odds) : si \(p = 0{,}75\), la cote est \(3\) (trois chances pour une). Le logit est la transformation qui rend ce rapport linéaire en \(\mathbf{x}\).
Estimation par maximum de vraisemblance#
Contrairement à la régression linéaire (qui minimise les moindres carrés), la régression logistique est estimée par maximum de vraisemblance (MLE). La log-vraisemblance est :
où \(\hat{p}_i = \sigma(\mathbf{x}_i^T\boldsymbol{\beta})\). Il n’existe pas de solution analytique fermée ; on utilise des méthodes itératives (Newton-Raphson, IRLS).
Pourquoi pas les MCO ?
Les moindres carrés ordinaires supposent des résidus gaussiens homoscédastiques. Pour une variable binaire, la variance est \(p(1-p)\), qui dépend de \(p\) lui-même (hétéroscédasticité structurelle), et les résidus ne sont pas gaussiens. Le MLE est l’approche naturelle et efficiente.
Exemple fil rouge : risque de défaut de crédit#
import statsmodels.api as sm
import statsmodels.formula.api as smf
from sklearn.metrics import (confusion_matrix, classification_report,
roc_curve, auc, precision_recall_curve)
from sklearn.model_selection import train_test_split
# Simulation d'un jeu de données de crédit
np.random.seed(2024)
n = 800
age = np.random.normal(40, 10, n).clip(20, 70)
revenu = np.random.lognormal(10.5, 0.5, n) # revenus annuels
dette_revenu = np.random.beta(2, 5, n) * 0.8 # ratio dette/revenu
historique = np.random.choice([0, 1], n, p=[0.3, 0.7]) # bon historique
# Log-odds vrai
log_odds = (-1.5
+ 0.03 * (age - 40)
- 0.4 * np.log(revenu / 50000)
+ 3.0 * dette_revenu
- 1.2 * historique)
p_defaut = expit(log_odds)
defaut = np.random.binomial(1, p_defaut)
df = pd.DataFrame({
'defaut': defaut,
'age': age.round(1),
'revenu_k': (revenu / 1000).round(1),
'dette_revenu': dette_revenu.round(3),
'bon_historique': historique
})
print(f"Taux de défaut : {defaut.mean():.1%}")
print(f"\nAperçu du jeu de données :")
df.head()
Taux de défaut : 20.1%
Aperçu du jeu de données :
| defaut | age | revenu_k | dette_revenu | bon_historique | |
|---|---|---|---|---|---|
| 0 | 1 | 56.7 | 33.2 | 0.470 | 0 |
| 1 | 0 | 47.4 | 26.3 | 0.327 | 1 |
| 2 | 0 | 38.0 | 29.9 | 0.364 | 0 |
| 3 | 0 | 38.5 | 45.5 | 0.181 | 0 |
| 4 | 0 | 49.2 | 18.0 | 0.289 | 0 |
# Ajustement du modèle avec statsmodels
model = smf.logit(
'defaut ~ age + np.log(revenu_k) + dette_revenu + bon_historique',
data=df
).fit(disp=False)
print(model.summary())
Logit Regression Results
==============================================================================
Dep. Variable: defaut No. Observations: 800
Model: Logit Df Residuals: 795
Method: MLE Df Model: 4
Date: Wed, 01 Apr 2026 Pseudo R-squ.: 0.1013
Time: 20:38:49 Log-Likelihood: -361.02
converged: True LL-Null: -401.70
Covariance Type: nonrobust LLR p-value: 8.945e-17
====================================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------------
Intercept -0.5671 0.808 -0.702 0.483 -2.151 1.017
age 0.0255 0.009 2.727 0.006 0.007 0.044
np.log(revenu_k) -0.4657 0.190 -2.447 0.014 -0.839 -0.093
dette_revenu 2.8798 0.703 4.095 0.000 1.501 4.258
bon_historique -1.3884 0.191 -7.258 0.000 -1.763 -1.013
====================================================================================
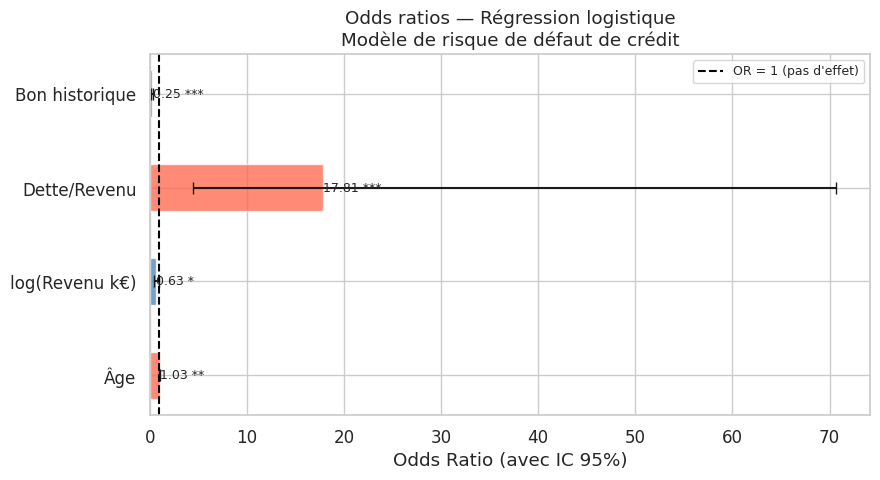
Interprétation des coefficients : odds ratios#
Le coefficient \(\beta_j\) représente la variation du log-odds associée à une augmentation unitaire de \(x_j\). L”odds ratio (OR) est \(e^{\beta_j}\) :
OR > 1 : le facteur augmente la cote de défaut
OR < 1 : le facteur diminue la cote de défaut
OR = 1 : pas d’effet
# Odds ratios avec intervalles de confiance à 95%
conf = model.conf_int()
conf.columns = ['IC_inf', 'IC_sup']
resultats = pd.DataFrame({
'Coefficient': model.params,
'OR': np.exp(model.params),
'OR_IC_inf': np.exp(conf['IC_inf']),
'OR_IC_sup': np.exp(conf['IC_sup']),
'p_valeur': model.pvalues
})
print(resultats.round(4))
Coefficient OR OR_IC_inf OR_IC_sup p_valeur
Intercept -0.5671 0.5672 0.1164 2.7647 0.4829
age 0.0255 1.0259 1.0072 1.0449 0.0064
np.log(revenu_k) -0.4657 0.6277 0.4323 0.9115 0.0144
dette_revenu 2.8798 17.8103 4.4883 70.6739 0.0000
bon_historique -1.3884 0.2495 0.1715 0.3630 0.0000
Évaluation du modèle#
Matrice de confusion et métriques#
# Prédictions (seuil = 0.5 par défaut)
df_train, df_test = train_test_split(df, test_size=0.3, random_state=42, stratify=df['defaut'])
model_train = smf.logit(
'defaut ~ age + np.log(revenu_k) + dette_revenu + bon_historique',
data=df_train
).fit(disp=False)
p_pred = model_train.predict(df_test)
y_pred = (p_pred >= 0.5).astype(int)
y_true = df_test['defaut'].values
cm = confusion_matrix(y_true, y_pred)
print("Matrice de confusion :")
print(pd.DataFrame(cm,
index=['Réel : Non-défaut', 'Réel : Défaut'],
columns=['Prédit : Non-défaut', 'Prédit : Défaut']))
print()
print(classification_report(y_true, y_pred,
target_names=['Non-défaut', 'Défaut']))
Matrice de confusion :
Prédit : Non-défaut Prédit : Défaut
Réel : Non-défaut 184 8
Réel : Défaut 41 7
precision recall f1-score support
Non-défaut 0.82 0.96 0.88 192
Défaut 0.47 0.15 0.22 48
accuracy 0.80 240
macro avg 0.64 0.55 0.55 240
weighted avg 0.75 0.80 0.75 240
Courbe ROC et AUC#
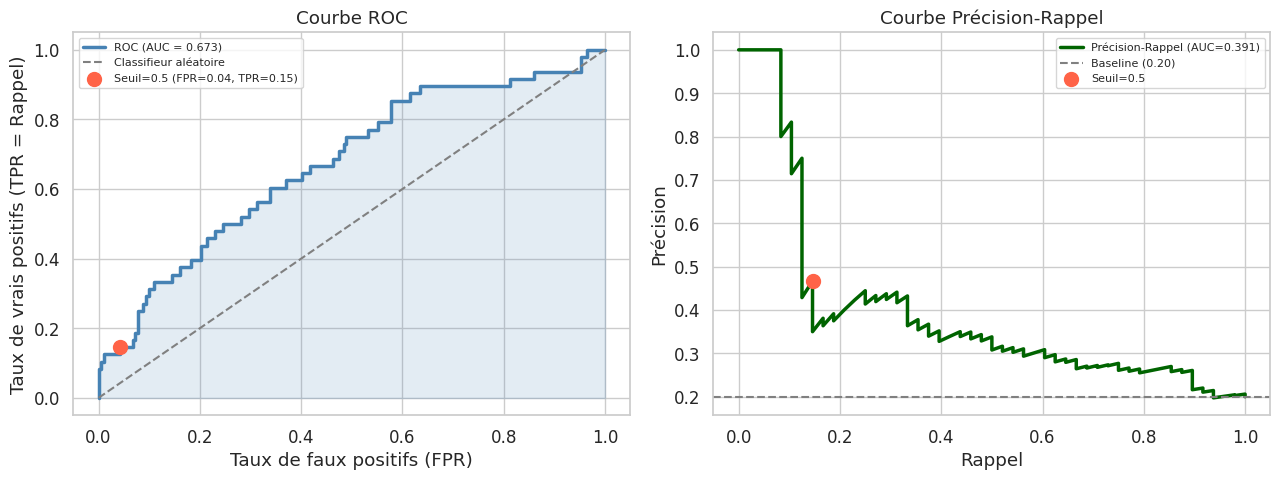
Impact du seuil de classification#
Choix du seuil
Le seuil à 0,5 n’est pas toujours optimal. Dans un contexte de détection de fraude ou de maladie grave, on préfère un seuil plus bas (augmenter le rappel quitte à baisser la précision). Le seuil optimal dépend des coûts relatifs des erreurs de type I et type II.
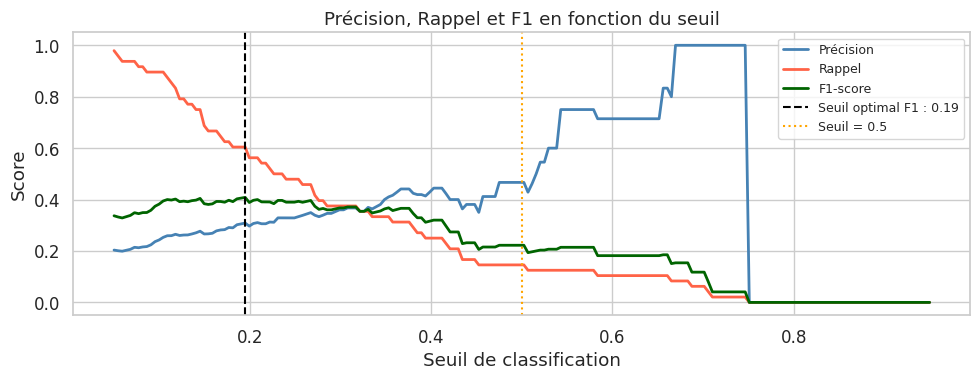
Seuil optimal (F1) : 0.19
Régression logistique multinomiale#
Quand la variable réponse est multi-classes (plus de 2 catégories non ordonnées), on étend la régression logistique au modèle softmax :
On fixe une classe de référence (par exemple \(k = K\)) et on estime \(K-1\) jeux de coefficients.
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_classification
# Exemple : classification 3 classes
np.random.seed(42)
X_multi, y_multi = make_classification(
n_samples=600, n_features=2, n_redundant=0, n_informative=2,
n_clusters_per_class=1, n_classes=3, random_state=42
)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_multi)
clf_multi = LogisticRegression(solver='lbfgs', max_iter=500)
clf_multi.fit(X_scaled, y_multi)
print(f"Précision multinomiale : {clf_multi.score(X_scaled, y_multi):.3f}")
print(f"Coefficients (forme) : {clf_multi.coef_.shape} (K classes × p features)")
Précision multinomiale : 0.925
Coefficients (forme) : (3, 2) (K classes × p features)
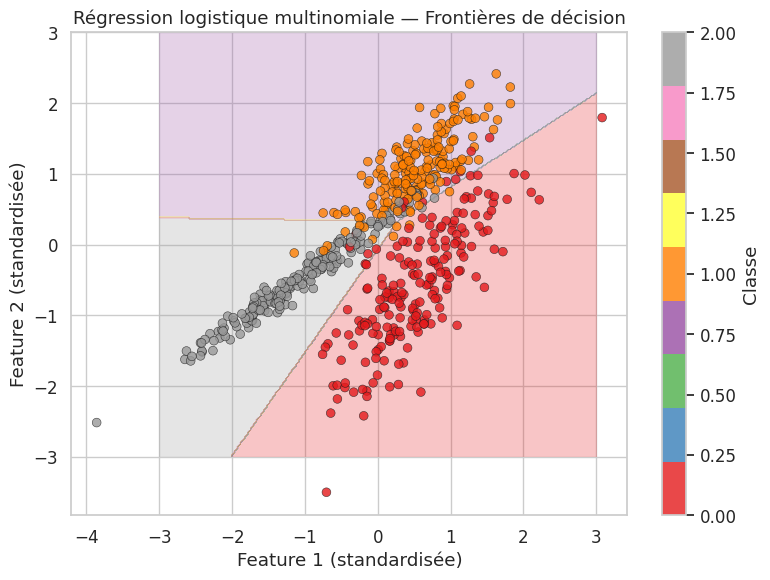
Régression logistique ordinale#
Quand les catégories sont ordonnées (par exemple notes A/B/C/D, niveaux de satisfaction 1-5), le modèle proportional odds (logit cumulatif) est adapté :
# Simulation d'une variable ordinale (note de crédit : 1=mauvais, 5=excellent)
from statsmodels.miscmodels.ordinal_model import OrderedModel
np.random.seed(42)
n_ord = 500
x1 = np.random.normal(0, 1, n_ord)
x2 = np.random.normal(0, 1, n_ord)
latent = 0.8 * x1 - 0.5 * x2 + np.random.normal(0, 1, n_ord)
cuts = [-1.5, -0.5, 0.5, 1.5]
y_ord = np.digitize(latent, cuts) # 0, 1, 2, 3, 4
df_ord = pd.DataFrame({'y': y_ord, 'x1': x1, 'x2': x2})
print("Distribution de la variable ordinale :")
print(df_ord['y'].value_counts().sort_index())
model_ord = OrderedModel(df_ord['y'], df_ord[['x1', 'x2']], distr='logit')
result_ord = model_ord.fit(method='bfgs', disp=False)
print(result_ord.summary())
Distribution de la variable ordinale :
y
0 56
1 100
2 164
3 112
4 68
Name: count, dtype: int64
OrderedModel Results
==============================================================================
Dep. Variable: y Log-Likelihood: -654.04
Model: OrderedModel AIC: 1320.
Method: Maximum Likelihood BIC: 1345.
Date: Wed, 01 Apr 2026
Time: 20:38:52
No. Observations: 500
Df Residuals: 494
Df Model: 2
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
x1 1.2165 0.100 12.201 0.000 1.021 1.412
x2 -0.7212 0.092 -7.853 0.000 -0.901 -0.541
0/1 -2.7240 0.168 -16.188 0.000 -3.054 -2.394
1/2 0.5087 0.092 5.508 0.000 0.328 0.690
2/3 0.6088 0.071 8.614 0.000 0.470 0.747
3/4 0.5022 0.087 5.765 0.000 0.331 0.673
==============================================================================
Hypothèses et diagnostics#
Hypothèses du modèle logistique
Indépendance des observations : pas de structure de dépendance (groupes, séries temporelles).
Pas de séparation parfaite : si un prédicteur sépare parfaitement les classes, les coefficients divergent vers ±∞.
Pas de multicolinéarité sévère : vérifier avec le VIF (comme en régression linéaire).
Taille d’échantillon : règle empirique — au moins 10 événements par variable (EPV ≥ 10).
Linéarité du logit : la relation entre les variables continues et le logit doit être linéaire.
# VIF pour diagnostiquer la multicolinéarité
from statsmodels.stats.outliers_influence import variance_inflation_factor
X_vif = df[['age', 'revenu_k', 'dette_revenu', 'bon_historique']].copy()
X_vif_const = sm.add_constant(X_vif)
vif_data = pd.DataFrame({
'Variable': X_vif.columns,
'VIF': [variance_inflation_factor(X_vif_const.values, i+1)
for i in range(X_vif.shape[1])]
})
print("Facteur d'inflation de variance (VIF) :")
print(vif_data.to_string(index=False))
print("\nVIF < 5 : acceptable | VIF > 10 : problématique")
Facteur d'inflation de variance (VIF) :
Variable VIF
age 1.001490
revenu_k 1.003259
dette_revenu 1.001789
bon_historique 1.003505
VIF < 5 : acceptable | VIF > 10 : problématique
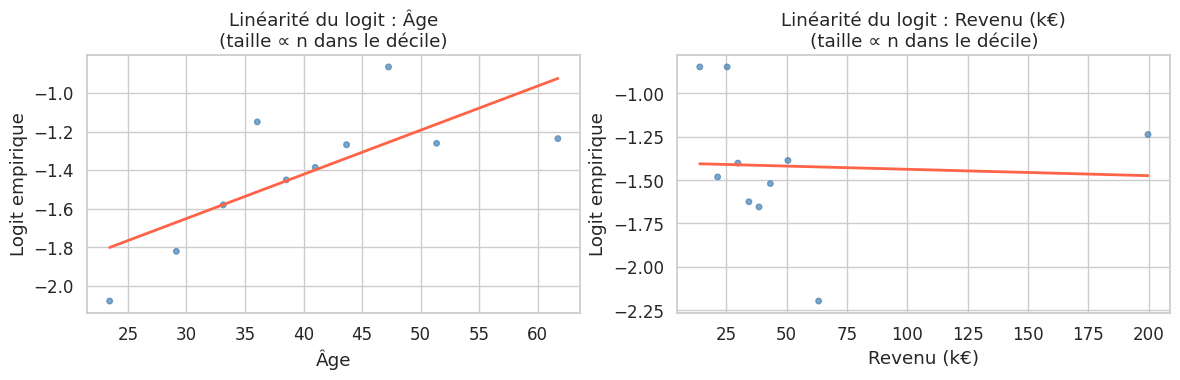
Résumé#
Points clés — Régression logistique
La régression logistique modélise \(P(Y=1|\mathbf{x})\) via la fonction sigmoïde, garantissant des prédictions dans \((0,1)\).
Le modèle est estimé par maximum de vraisemblance, pas par MCO.
Les odds ratios (\(e^\beta\)) quantifient l’effet multiplicatif sur la cote.
L’évaluation passe par la matrice de confusion, la courbe ROC/AUC et la courbe précision-rappel.
Le seuil de classification doit être choisi selon le coût des erreurs, pas automatiquement à 0,5.
L’extension multinomiale (softmax) gère les multi-classes ; le modèle ordinal préserve l’ordre des catégories.
Diagnostics indispensables : VIF, EPV, linéarité du logit, absence de séparation parfaite.