Distributions en pratique#
La théorie des probabilités décrit des distributions idéales. Les données réelles n’obéissent jamais exactement à ces distributions — mais elles s’en approchent souvent suffisamment pour que les outils associés soient valides. Ce chapitre enseigne à naviguer entre ces deux mondes : reconnaître la forme d’une distribution réelle, la tester, l’ajuster, et transformer les données quand nécessaire.
Reconnaître une distribution sur données réelles#
La première étape est toujours visuelle. L’histogramme, la densité estimée par noyau (KDE) et le QQ-plot donnent des informations complémentaires sur la forme d’une distribution.
# Génération de jeux de données avec différentes distributions
n = 500
# Revenus : log-normale (la loi des revenus par excellence)
revenus = rng.lognormal(mean=3.6, sigma=0.5, size=n) # en dizaines de milliers €
# Temps d'attente : exponentielle (files d'attente, temps entre événements)
temps_attente = rng.exponential(scale=5, size=n) # minutes
# Notes d'examen : bêta (bornée entre 0 et 20)
notes = 20 * rng.beta(a=5, b=2, size=n)
# Températures : normale (phénomène symétrique)
temperatures = rng.normal(loc=15, scale=5, size=n)
datasets = {
"Revenus (log-normale)": revenus,
"Temps d'attente (exponentielle)": temps_attente,
"Notes d'examen (bêta)": notes,
"Températures (normale)": temperatures,
}
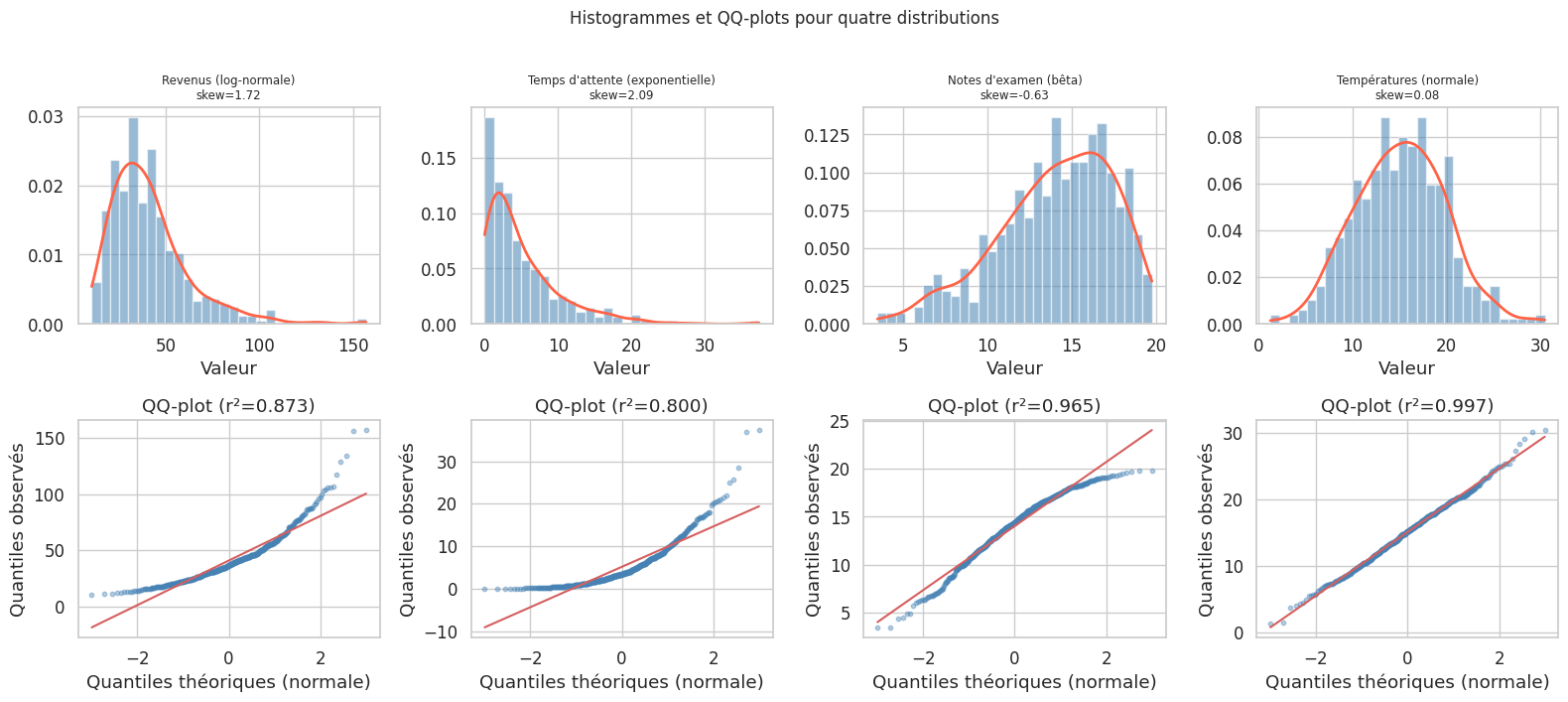
Le QQ-plot : lecture et interprétation#
Le QQ-plot (quantile-quantile plot) compare les quantiles empiriques d’un échantillon aux quantiles théoriques d’une loi de référence. Si l’échantillon suit cette loi, les points s’alignent sur la droite \(y = x\) (ou sur la droite de régression ajustée).
Les déviations caractéristiques ont chacune une signature visuelle reconnaissable.
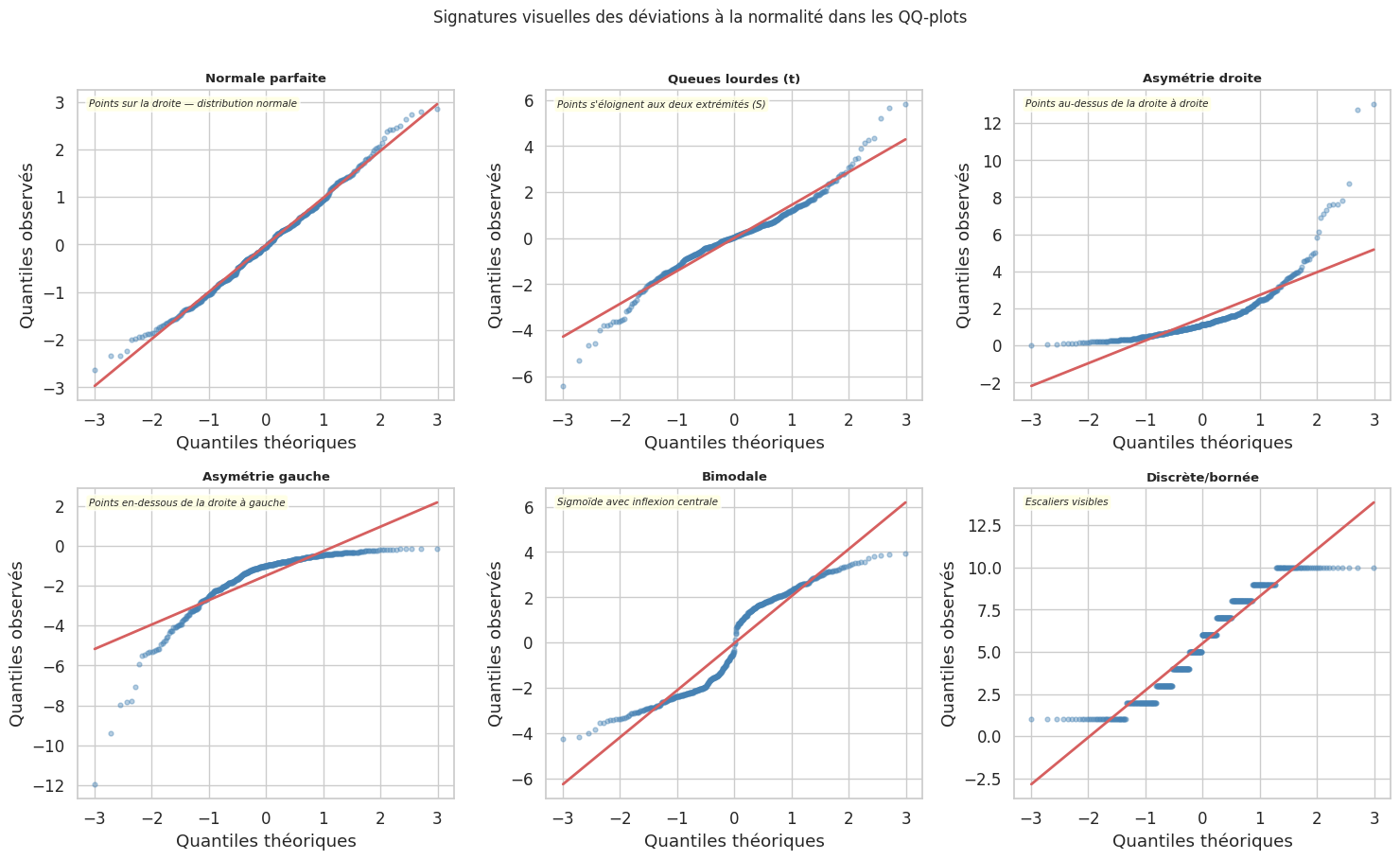
Lecture pratique du QQ-plot
Points sur la droite : la distribution correspond bien à la loi de référence.
Courbe en S : queues plus lourdes que la référence (leptokurtique).
Courbe en S inversé : queues plus légères (platykurtique).
Inflexion vers le haut à droite : asymétrie positive (queue droite étalée).
Inflexion vers le bas à gauche : asymétrie négative.
Marches d’escalier : données discrètes ou nombreuses ex-aequo.
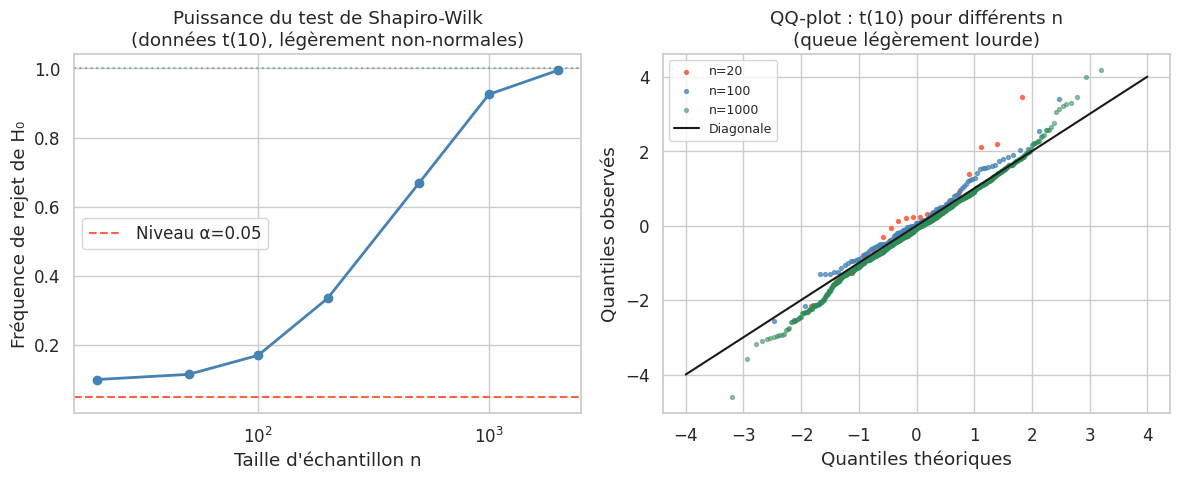
Tests de normalité#
Les tests de normalité répondent formellement à la question : « peut-on rejeter l’hypothèse que ces données suivent une loi normale ? »
Attention à l’usage des tests de normalité
Ces tests détectent la non-normalité, pas la normalité. Ne pas rejeter H₀ ne prouve pas que les données sont normales — cela signifie seulement que l’échantillon est trop petit pour détecter la déviation. Avec un grand n, le test rejette H₀ pour des déviations pratiquement insignifiantes.
Shapiro-Wilk#
Optimal pour les petits échantillons (\(n < 50\)). Il compare les statistiques d’ordre à leurs espérances sous la normale. Il est le plus puissant des tests courants pour détecter des déviations à la normalité.
Kolmogorov-Smirnov (avec correction Lilliefors)#
Basé sur la distance maximale entre la ECDF et la CDF théorique. Dans scipy, stats.kstest suppose les paramètres connus ; utiliser stats.kstest avec les paramètres estimés à partir des données invalide le test (biais conservateur). La correction de Lilliefors (statsmodels.stats.diagnostic.lilliefors) est préférable.
D’Agostino-Pearson#
Combine le skewness et le kurtosis en une statistique de test. Robuste, applicable pour \(n > 20\), disponible via scipy.stats.normaltest.
def tests_normalite(data, nom="données"):
"""Applique trois tests de normalité et retourne les résultats."""
resultats = {}
# Shapiro-Wilk (recommandé pour n < 5000)
if len(data) <= 5000:
stat_sw, p_sw = stats.shapiro(data)
resultats["Shapiro-Wilk"] = {"statistique": stat_sw, "p-valeur": p_sw}
# D'Agostino-Pearson
stat_dp, p_dp = stats.normaltest(data)
resultats["D'Agostino-Pearson"] = {"statistique": stat_dp, "p-valeur": p_dp}
# Jarque-Bera
stat_jb, p_jb = stats.jarque_bera(data)
resultats["Jarque-Bera"] = {"statistique": stat_jb, "p-valeur": p_jb}
df_res = pd.DataFrame(resultats).T
df_res["rejet H0 (α=0.05)"] = df_res["p-valeur"] < 0.05
print(f"\n=== Tests de normalité : {nom} ===")
print(df_res.round(4).to_string())
return df_res
_ = tests_normalite(temperatures, "Températures (normale)")
_ = tests_normalite(revenus[:500], "Revenus (log-normale)")
_ = tests_normalite(temps_attente[:500], "Temps d'attente (exponentielle)")
=== Tests de normalité : Températures (normale) ===
statistique p-valeur rejet H0 (α=0.05)
Shapiro-Wilk 0.9973 0.5917 False
D'Agostino-Pearson 0.5649 0.7539 False
Jarque-Bera 0.5131 0.7737 False
=== Tests de normalité : Revenus (log-normale) ===
statistique p-valeur rejet H0 (α=0.05)
Shapiro-Wilk 0.8742 0.0 True
D'Agostino-Pearson 189.4560 0.0 True
Jarque-Bera 711.3370 0.0 True
=== Tests de normalité : Temps d'attente (exponentielle) ===
statistique p-valeur rejet H0 (α=0.05)
Shapiro-Wilk 0.8013 0.0 True
D'Agostino-Pearson 237.9953 0.0 True
Jarque-Bera 1220.2718 0.0 True
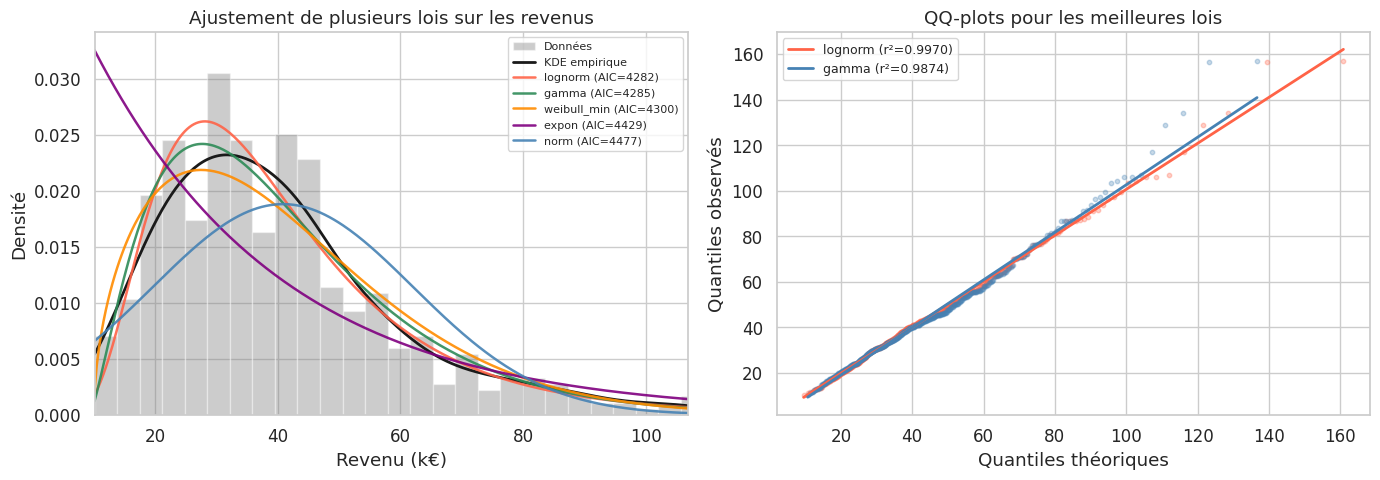
Ajustement d’une loi : scipy.stats.fit()#
Lorsqu’on souspecte une distribution particulière, on peut ajuster ses paramètres sur les données observées par maximum de vraisemblance (MLE).
# Ajustement de plusieurs lois sur les revenus (log-normaux)
lois_candidates = ["lognorm", "gamma", "expon", "norm", "weibull_min"]
data_revenus = revenus.copy()
resultats_fit = []
for nom_loi in lois_candidates:
loi = getattr(stats, nom_loi)
try:
params = loi.fit(data_revenus)
# Log-vraisemblance
loglik = loi.logpdf(data_revenus, *params).sum()
k = len(params)
n = len(data_revenus)
aic = 2 * k - 2 * loglik
bic = k * np.log(n) - 2 * loglik
# Test KS
stat_ks, p_ks = stats.kstest(data_revenus, nom_loi, args=params)
resultats_fit.append({
"Loi": nom_loi,
"Paramètres": str([round(p, 3) for p in params]),
"Log-vraisemblance": round(loglik, 1),
"AIC": round(aic, 1),
"BIC": round(bic, 1),
"KS p-valeur": round(p_ks, 4),
})
except Exception as e:
pass
df_fit = pd.DataFrame(resultats_fit).set_index("Loi").sort_values("AIC")
print("Ajustement de lois sur les revenus — comparaison par AIC/BIC :")
print(df_fit.to_string())
Ajustement de lois sur les revenus — comparaison par AIC/BIC :
Paramètres Log-vraisemblance AIC BIC KS p-valeur
Loi
lognorm [np.float64(0.518), 2.432, np.float64(33.608)] -2138.1 4282.3 4294.9 0.8426
gamma [np.float64(2.398), np.float64(9.31), np.float64(13.156)] -2139.5 4285.0 4297.7 0.3237
weibull_min [np.float64(1.544), np.float64(10.024), np.float64(34.38)] -2147.1 4300.2 4312.8 0.0548
expon [10.142, 30.713] -2212.3 4428.7 4437.1 0.0000
norm [np.float64(40.854), np.float64(21.208)] -2236.7 4477.3 4485.7 0.0000
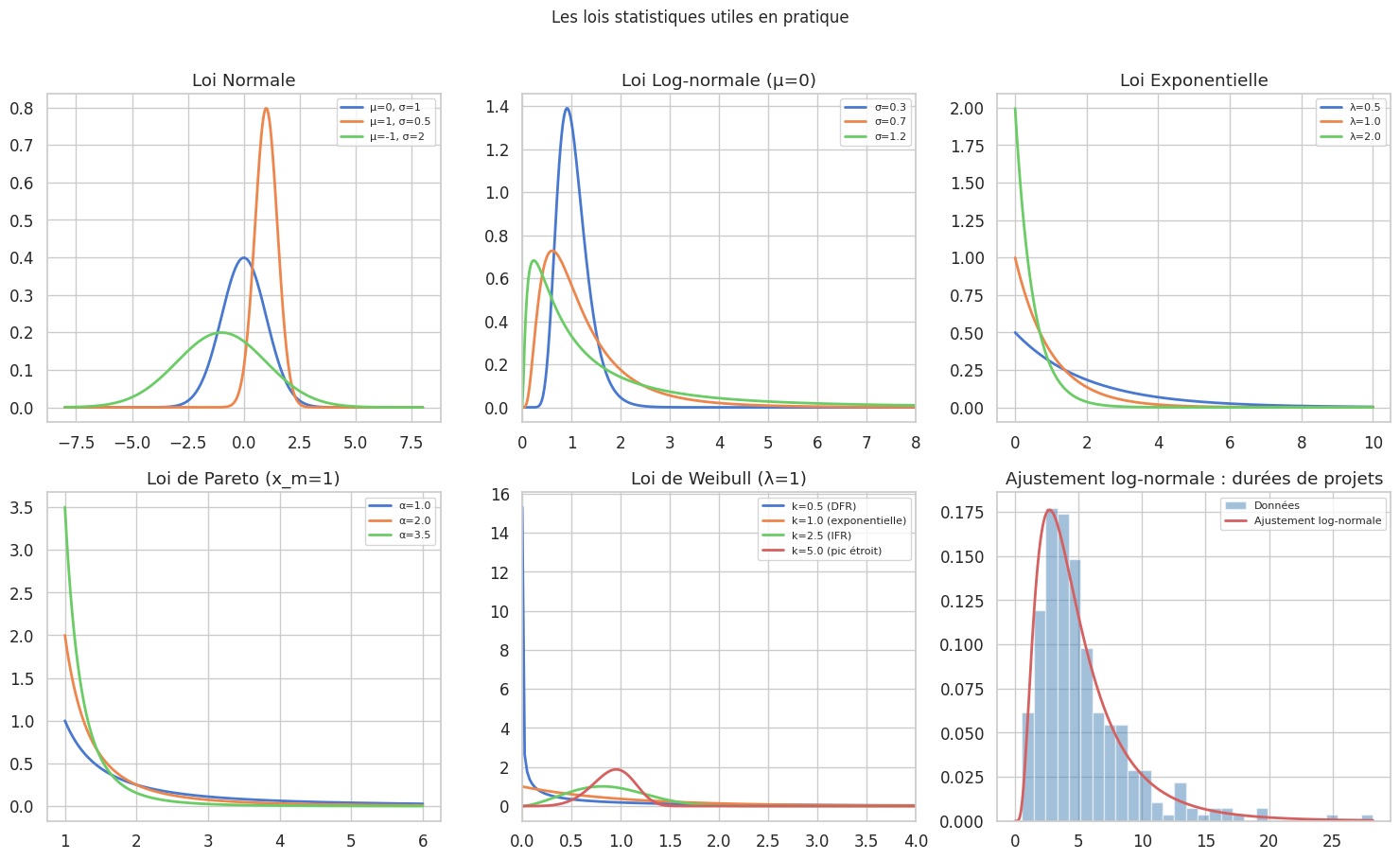
Lois utiles en pratique#
Normale \(\mathcal{N}(\mu, \sigma^2)\)#
Omniprésente par le théorème central limite. Convient aux mesures physiques, tailles humaines, erreurs de mesure. À utiliser par défaut quand rien n’indique le contraire.
Log-normale \(\text{LogNorm}(\mu, \sigma)\)#
Si \(\log X \sim \mathcal{N}(\mu, \sigma^2)\), alors \(X\) est log-normale. Modèle naturel des revenus, prix immobiliers, durées de vie de composants, tailles de fichiers. La queue droite est étalée, la distribution est toujours positive.
Exponentielle \(\text{Exp}(\lambda)\)#
Modèle des temps entre événements dans un processus de Poisson : temps entre arrivées dans une file d’attente, durée entre appels téléphoniques. Sa propriété remarquable est l’absence de mémoire : \(P(X > s+t \mid X > s) = P(X > t)\).
Pareto \(\text{Pareto}(\alpha, x_m)\)#
Formalise la « loi de puissance » : 20 % des fichiers représentent 80 % de l’espace. Convient aux revenus très élevés, tailles de fichiers, fréquence des mots (loi de Zipf).
Weibull \(\text{Weibull}(k, \lambda)\)#
Généralisation de l’exponentielle pour la fiabilité et l”analyse de survie. Le paramètre de forme \(k\) contrôle si le taux de défaillance est croissant (\(k>1\)), constant (\(k=1\), exponentielle) ou décroissant (\(k<1\)).
Transformations de données#
Quand les données ne sont pas normales alors qu’une méthode le requiert, on peut les transformer pour les rapprocher d’une gaussienne.
Transformation logarithmique#
\(y = \log(x + c)\) (souvent \(c=0\) si \(x > 0\)). Comprime les grandes valeurs, étire les petites. Idéale pour les distributions log-normales et les données à une ordre de grandeur de variation.
Transformation de Box-Cox#
\(y = \frac{x^\lambda - 1}{\lambda}\) pour \(\lambda \neq 0\), \(y = \log(x)\) pour \(\lambda = 0\). Le paramètre \(\lambda\) est estimé par MLE. Requiert \(x > 0\).
Transformation de Yeo-Johnson#
Extension de Box-Cox qui accepte les valeurs négatives : \(y = \begin{cases} \frac{(x+1)^\lambda - 1}{\lambda} & \text{si } x \geq 0, \lambda \neq 0 \\ \log(x+1) & \text{si } x \geq 0, \lambda = 0 \\ \frac{-((-x+1)^{2-\lambda} - 1)}{2-\lambda} & \text{si } x < 0, \lambda \neq 2 \end{cases}\)
# Données log-normales : revenu brut
data_brut = rng.lognormal(mean=3.5, sigma=0.8, size=500)
# Log
data_log = np.log(data_brut)
# Box-Cox
data_bc, lambda_bc = stats.boxcox(data_brut)
# Yeo-Johnson
data_yj, lambda_yj = stats.yeojohnson(data_brut)
print(f"Lambda Box-Cox : {lambda_bc:.3f} (proche de 0 → log convient)")
print(f"Lambda Yeo-Johnson : {lambda_yj:.3f}")
print()
for nom, d in [("Brut", data_brut), ("Log", data_log), ("Box-Cox", data_bc), ("Yeo-Johnson", data_yj)]:
sw_stat, sw_p = stats.shapiro(d[:500])
sk = stats.skew(d)
print(f"{nom:12s} : skewness={sk:.3f}, Shapiro p={sw_p:.4f}")
Lambda Box-Cox : -0.098 (proche de 0 → log convient)
Lambda Yeo-Johnson : -0.136
Brut : skewness=3.792, Shapiro p=0.0000
Log : skewness=0.226, Shapiro p=0.1325
Box-Cox : skewness=0.004, Shapiro p=0.8416
Yeo-Johnson : skewness=0.008, Shapiro p=0.7388
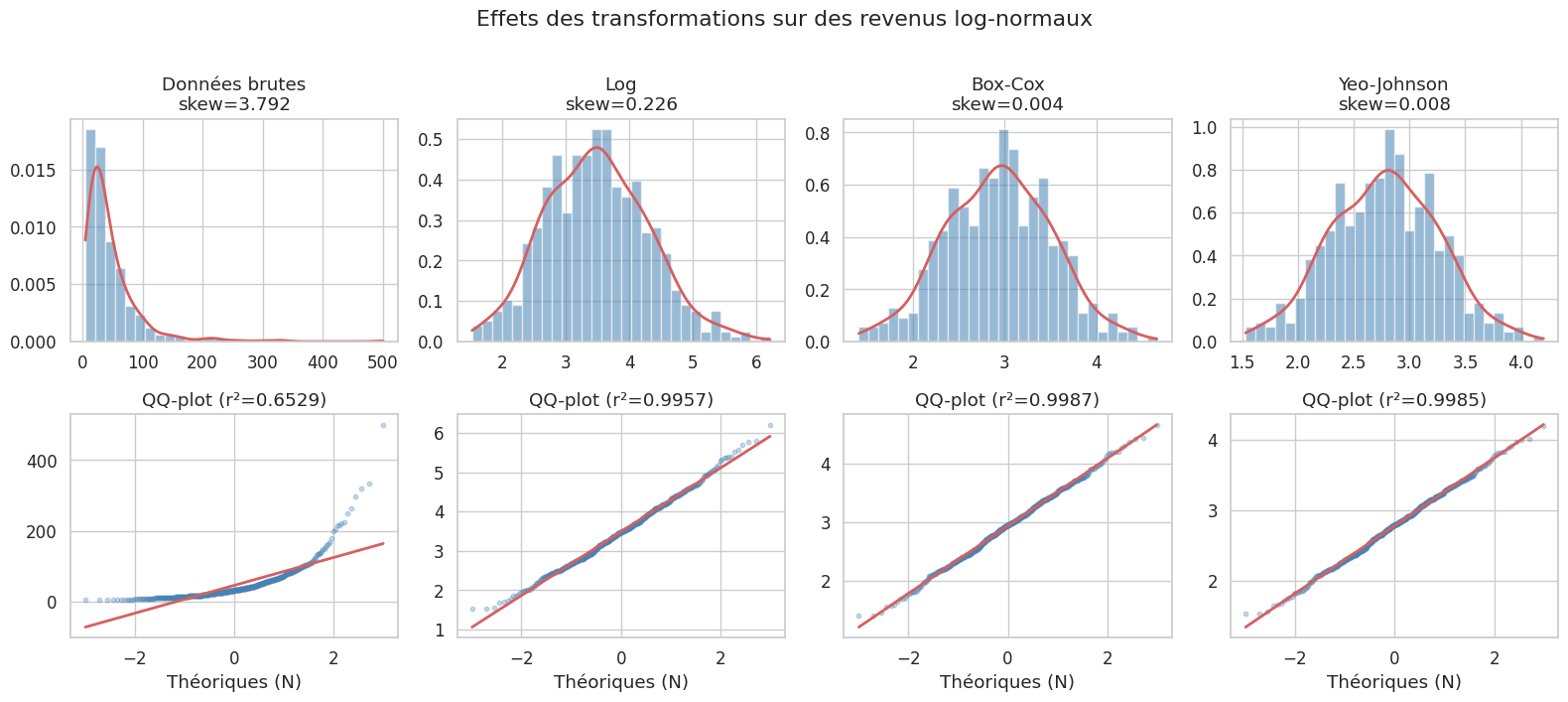
Quand transformer ?
Log : données strictement positives avec queue droite lourde (revenus, prix, concentrations chimiques).
Box-Cox : données strictement positives, λ estimé par MLE — optimal pour normaliser.
Yeo-Johnson : idem mais accepte les valeurs nulles ou négatives.
Racine carrée : données de comptage (Poisson) — variance proportionnelle à la moyenne.
Arcsine : proportions entre 0 et 1.
Interprétez toujours les résultats dans l’espace original (dé-transformer). Les coefficients d’une régression log-linéaire s’interprètent comme des effets multiplicatifs.
Mélange de gaussiennes (GMM)#
Certaines distributions semblent bimodales parce qu’elles sont un mélange de deux (ou plus) populations gaussiennes. Le Gaussian Mixture Model (GMM) décompose cette distribution mixte.
# Exemple : temps de réponse d'un serveur web (bimodal)
# Requêtes normales + requêtes lentes (cache miss)
t_normales = rng.normal(loc=50, scale=10, size=350) # ms
t_lentes = rng.normal(loc=200, scale=40, size=150) # ms
temps_reponse = np.concatenate([t_normales, t_lentes])
# Ajustement GMM "à la main" via scipy
from scipy.stats import norm
def gmm_pdf(x, pi1, mu1, sigma1, mu2, sigma2):
return pi1 * norm.pdf(x, mu1, sigma1) + (1 - pi1) * norm.pdf(x, mu2, sigma2)
# Estimation simple par inspection visuelle / EM simplifié
# (sklearn.mixture.GaussianMixture fait ça proprement en multidimensionnel)
from scipy.optimize import minimize
def neg_log_vraisemblance(params):
pi1, mu1, log_s1, mu2, log_s2 = params
if not (0.01 < pi1 < 0.99):
return 1e10
s1, s2 = np.exp(log_s1), np.exp(log_s2)
pdf = gmm_pdf(temps_reponse, pi1, mu1, s1, mu2, s2)
pdf = np.clip(pdf, 1e-300, None)
return -np.sum(np.log(pdf))
x0 = [0.7, 50, np.log(10), 200, np.log(40)]
res = minimize(neg_log_vraisemblance, x0, method="Nelder-Mead",
options={"maxiter": 10000, "xatol": 1e-6})
pi1, mu1, log_s1, mu2, log_s2 = res.x
s1, s2 = np.exp(log_s1), np.exp(log_s2)
print(f"Composante 1 : π={pi1:.2f}, μ={mu1:.1f} ms, σ={s1:.1f} ms")
print(f"Composante 2 : π={1-pi1:.2f}, μ={mu2:.1f} ms, σ={s2:.1f} ms")
Composante 1 : π=0.70, μ=49.5 ms, σ=10.0 ms
Composante 2 : π=0.30, μ=194.2 ms, σ=40.7 ms
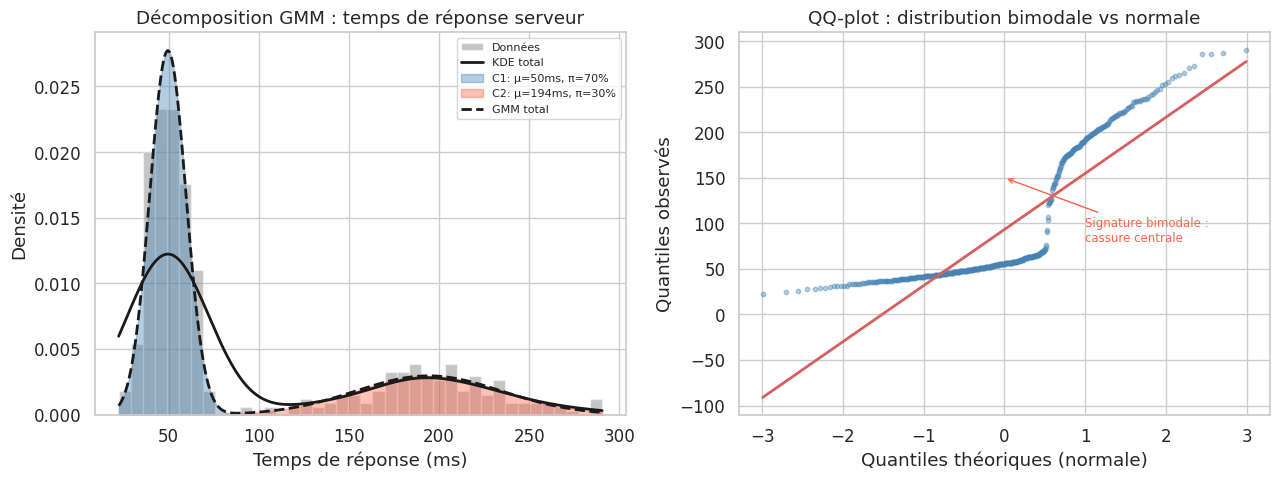
GMM en pratique
sklearn.mixture.GaussianMixture offre une implémentation robuste du GMM par algorithme EM (Expectation-Maximisation) pour des données multivariées. On choisit le nombre de composantes \(K\) par critère BIC. Le GMM est aussi utilisé comme méthode de clustering doux : chaque point appartient à chaque composante avec une probabilité. Il sera étudié en détail dans le livre Data Science.
Les outils de ce chapitre — QQ-plots, tests de normalité, ajustements de lois, transformations — constituent la boîte à outils de diagnostic indispensable avant toute modélisation. Connaître la loi (ou l’approximation raisonnable) d’une variable permet de choisir les bons tests, d’interpréter correctement les résultats, et d’éviter les erreurs classiques de l’analyse de données.