Tests paramétriques#
Les tests paramétriques constituent l’arsenal classique de l’inférence statistique : ils permettent de répondre à des questions concrètes — « ce traitement est-il efficace ? », « ces deux machines produisent-elles des pièces de même calibre ? », « les trois méthodes d’enseignement donnent-elles des résultats équivalents ? » — avec une rigueur formelle. Ce chapitre présente les tests les plus utilisés, leurs hypothèses, leur implémentation en Python et leur interprétation correcte.
Rappels : cadre des tests d’hypothèses#
Un test statistique repose sur une logique de réfutation : on formule une hypothèse nulle \(H_0\) (statu quo, absence d’effet), on calcule la probabilité d’observer des données au moins aussi extrêmes si \(H_0\) était vraie, et on décide de rejeter ou non \(H_0\).
Éléments fondamentaux :
\(H_0\) (hypothèse nulle) : hypothèse par défaut, que l’on cherche à réfuter. Exemple : \(\mu = \mu_0\), ou \(\mu_1 = \mu_2\).
\(H_1\) (hypothèse alternative) : ce que l’on cherche à établir. Peut être bilatérale (\(\mu \neq \mu_0\)) ou unilatérale (\(\mu > \mu_0\)).
p-valeur : \(P(\text{statistique} \geq t_{\text{obs}} \mid H_0)\). Ce n’est pas la probabilité que \(H_0\) soit vraie — c’est la probabilité d’obtenir ce résultat ou plus extrême si \(H_0\) était vraie.
Niveau \(\alpha\) : seuil de rejet fixé avant le test (souvent 0,05). Si \(p < \alpha\), on rejette \(H_0\).
Les deux types d’erreurs :
Décision \ Réalité |
\(H_0\) vraie |
\(H_0\) fausse |
|---|---|---|
Ne pas rejeter \(H_0\) |
Décision correcte |
Erreur de type II (\(\beta\)) |
Rejeter \(H_0\) |
Erreur de type I (\(\alpha\)) |
Décision correcte |
La puissance du test est \(1 - \beta\) : la probabilité de détecter un effet réel.
p-valeur : ce qu’elle n’est pas
La p-valeur n’est pas :
La probabilité que \(H_0\) soit vraie
La probabilité que les résultats soient dus au hasard
Une mesure de l’importance pratique de l’effet
Une p-valeur < 0,05 signifie seulement que les données sont incompatibles avec \(H_0\) au seuil \(\alpha = 5\%\). La taille d’effet mesure l’importance pratique.
Test t à un échantillon#
Contexte et hypothèses#
On dispose d’un échantillon \(x_1, \ldots, x_n\) et on veut tester si la moyenne de la population dont il est issu est égale à une valeur de référence \(\mu_0\).
La statistique de test est : $\(t = \frac{\bar{x} - \mu_0}{s / \sqrt{n}}\)$
Sous \(H_0\), \(t \sim \mathcal{T}(n-1)\) (loi de Student à \(n-1\) degrés de liberté), à condition que les observations soient indépendantes et que la population soit normale (ou \(n\) suffisamment grand pour le TCL).
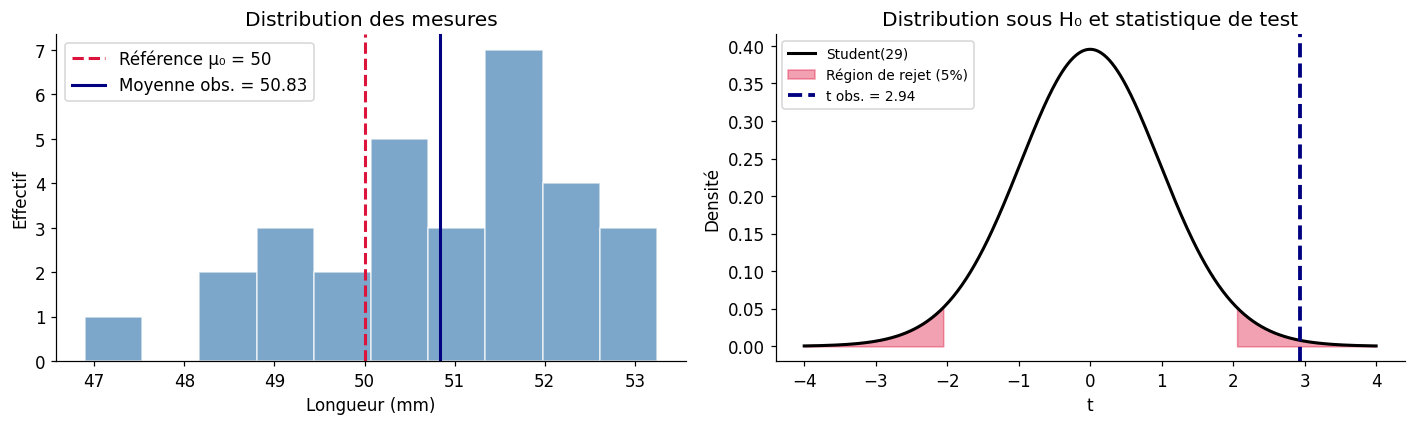
Exemple : calibrage d’une machine#
Une machine est censée produire des pièces de 50 mm. On mesure 30 pièces. La machine est-elle bien calibrée ?
# Simulation : machine légèrement déréglée
mu_reel = 50.8 # vrai écart
sigma = 2.0
n = 30
mesures = rng.normal(mu_reel, sigma, n)
# Test t à un échantillon
t_stat, p_val = stats.ttest_1samp(mesures, popmean=50.0)
print(f"Moyenne observée : {mesures.mean():.3f} mm")
print(f"Statistique t : {t_stat:.3f}")
print(f"p-valeur : {p_val:.4f}")
print(f"Degrés de liberté: {n - 1}")
print()
if p_val < 0.05:
print("→ Rejet de H0 : la machine est probablement déréglée.")
else:
print("→ Non-rejet de H0 : pas de preuve de dérèglage.")
Moyenne observée : 50.834 mm
Statistique t : 2.939
p-valeur : 0.0064
Degrés de liberté: 29
→ Rejet de H0 : la machine est probablement déréglée.
Taille d’effet : d de Cohen#
La p-valeur seule est insuffisante. Le d de Cohen mesure l’ampleur de l’écart en unités d’écarts-types :
Valeur absolue de \(d\) |
Interprétation |
|---|---|
0,2 |
Petit effet |
0,5 |
Effet modéré |
0,8 |
Grand effet |
# Taille d'effet
cohens_d = (mesures.mean() - 50.0) / mesures.std(ddof=1)
print(f"d de Cohen : {cohens_d:.3f}")
# Avec pingouin (résultat complet)
result = pg.ttest(mesures, 50.0)
print("\nRésultat complet avec pingouin :")
print(result[['T', 'dof', 'alternative', 'p_val', 'CI95', 'cohen_d', 'power']].to_string())
d de Cohen : 0.537
Résultat complet avec pingouin :
T dof alternative p_val CI95 cohen_d power
T_test 2.939154 29 two-sided 0.006397 [50.25, 51.41] 0.536614 0.810742
Visualisation : distribution sous H₀ et statistique observée#
Test t à deux échantillons indépendants#
Student vs Welch#
Deux groupes indépendants \(x_1, \ldots, x_{n_1}\) et \(y_1, \ldots, y_{n_2}\). On teste \(H_0 : \mu_X = \mu_Y\).
Test de Student (variantes égales) : \(t = \frac{\bar{x} - \bar{y}}{s_p \sqrt{1/n_1 + 1/n_2}}\) avec \(s_p^2\) variance poolée.
Test de Welch (variances inégales, recommandé par défaut) : ajuste les degrés de liberté selon l’approximation de Welch-Satterthwaite.
Quelle variante utiliser ?
En pratique, utilisez toujours le test de Welch (equal_var=False dans scipy). Il est robuste même lorsque les variances sont égales, alors que le test de Student peut être anti-conservateur lorsque les variances diffèrent. Vérifier l’égalité des variances avec un test de Levene et adapter en conséquence est une bonne pratique.
Exemple : deux méthodes pédagogiques#
# Deux groupes d'élèves (scores sur 100)
n_A, n_B = 35, 40
groupe_A = rng.normal(68, 12, n_A) # méthode traditionnelle
groupe_B = rng.normal(74, 15, n_B) # méthode active
# Test de Levene (égalité des variances)
lev_stat, lev_p = stats.levene(groupe_A, groupe_B)
print(f"Test de Levene : F = {lev_stat:.3f}, p = {lev_p:.4f}")
print(f"→ Variances {'probablement égales' if lev_p > 0.05 else 'probablement inégales'}")
print()
# Test de Welch (recommandé)
t_welch, p_welch = stats.ttest_ind(groupe_A, groupe_B, equal_var=False)
# Test de Student (pour comparaison)
t_student, p_student = stats.ttest_ind(groupe_A, groupe_B, equal_var=True)
print(f"Test de Welch : t = {t_welch:.3f}, p = {p_welch:.4f}")
print(f"Test de Student : t = {t_student:.3f}, p = {p_student:.4f}")
print()
# Avec pingouin
res = pg.ttest(groupe_A, groupe_B, correction=True)
print("Résultat pingouin (Welch) :")
print(res[['T', 'dof', 'p_val', 'CI95', 'cohen_d', 'power']].to_string())
Test de Levene : F = 0.760, p = 0.3860
→ Variances probablement égales
Test de Welch : t = -0.835, p = 0.4064
Test de Student : t = -0.828, p = 0.4101
Résultat pingouin (Welch) :
T dof p_val CI95 cohen_d power
T_test -0.835156 72.983305 0.406356 [-6.82, 2.79] 0.191745 0.129384
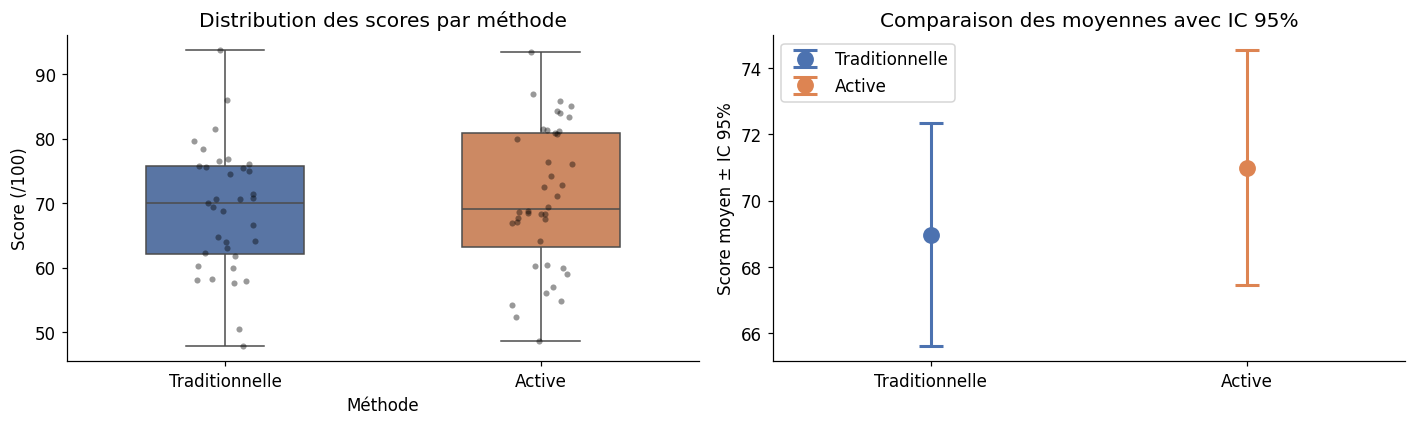
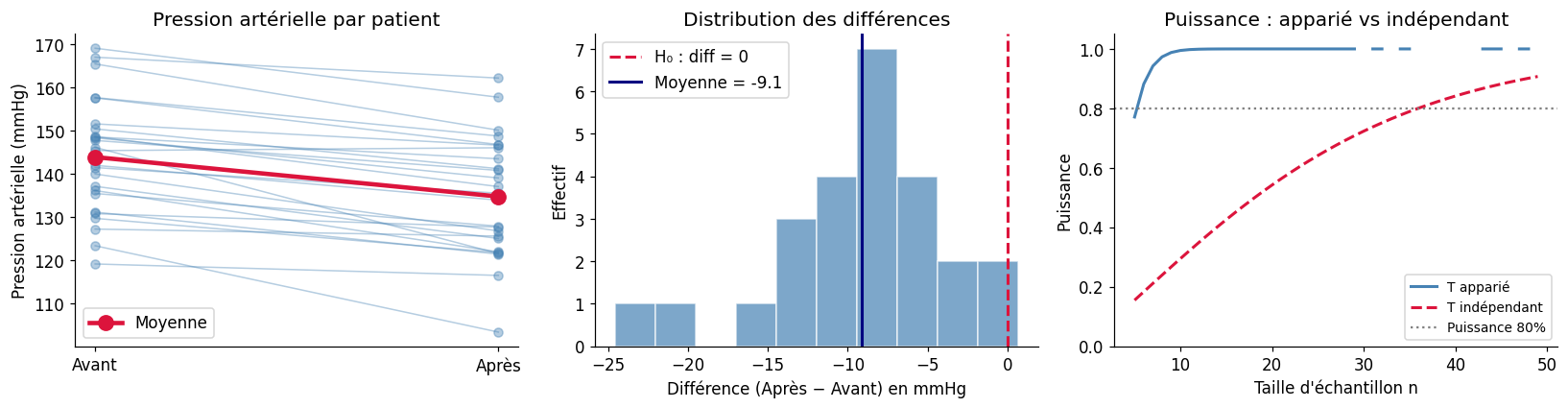
Test t apparié#
Données appariées : avant/après#
Lorsque les deux mesures sont liées (même individu mesuré deux fois, jumeaux, paires matchées), les observations ne sont pas indépendantes. Le test t apparié exploite cette structure en travaillant sur les différences \(d_i = x_{i,\text{après}} - x_{i,\text{avant}}\).
Le test t apparié est beaucoup plus puissant que le test à deux échantillons indépendants quand la corrélation intra-paire est élevée, car il élimine la variabilité inter-individus.
# Exemple médical : pression artérielle avant/après traitement
n_patients = 25
avant = rng.normal(145, 15, n_patients) # mmHg, avant traitement
# Effet du traitement : réduction de ~10 mmHg + variabilité individuelle
effet_traitement = rng.normal(10, 5, n_patients)
apres = avant - effet_traitement
differences = apres - avant
# Test t apparié
t_app, p_app = stats.ttest_rel(avant, apres)
# Test t indépendant (incorrect ici, pour illustration)
t_ind, p_ind = stats.ttest_ind(avant, apres)
print("Test t apparié (correct) :")
print(f" t = {t_app:.3f}, p = {p_app:.6f}")
print()
print("Test t indépendant (incorrect pour ces données) :")
print(f" t = {t_ind:.3f}, p = {p_ind:.4f}")
print()
print(f"Différence moyenne : {differences.mean():.2f} mmHg")
print(f"IC 95% sur la différence : {np.percentile(differences, [2.5, 97.5])}")
print()
res_app = pg.ttest(avant, apres, paired=True)
print("Résultat pingouin (apparié) :")
print(res_app[['T', 'dof', 'p_val', 'CI95', 'cohen_d', 'power']].to_string())
Test t apparié (correct) :
t = 8.092, p = 0.000000
Test t indépendant (incorrect pour ces données) :
t = 2.370, p = 0.0219
Différence moyenne : -9.12 mmHg
IC 95% sur la différence : [-21.81791761 -0.7118586 ]
Résultat pingouin (apparié) :
T dof p_val CI95 cohen_d power
T_test 8.092432 24 2.573756e-08 [6.8, 11.45] 0.670261 0.895176
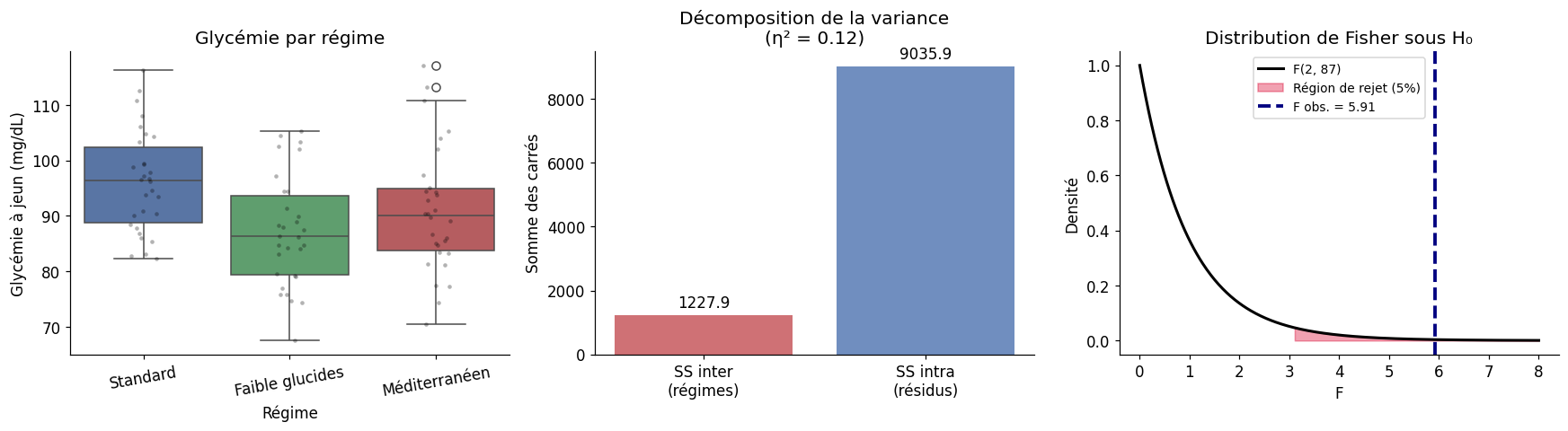
ANOVA à un facteur#
Principe#
L’ANOVA (ANalysis Of VAriance) étend le test t à plus de deux groupes. On décompose la variance totale en variance inter-groupes (due aux traitements) et variance intra-groupes (résiduelle).
où \(k\) est le nombre de groupes et \(N\) le nombre total d’observations.
Hypothèses de l’ANOVA :
Les observations sont indépendantes
Les résidus sont normalement distribués
Les variances sont homogènes (homoscédasticité) — vérifiée par Levene ou Bartlett
Pourquoi ne pas faire plusieurs tests t ?
Avec \(k\) groupes, faire tous les tests t par paires donne \(\binom{k}{2}\) tests. Au seuil \(\alpha = 0,05\), la probabilité d’au moins une fausse alarme est \(1 - (1-\alpha)^m\) où \(m\) est le nombre de tests. Pour \(k = 5\) groupes (10 tests), ce taux atteint ~40%. L’ANOVA contrôle globalement \(\alpha\).
Exemple : trois régimes alimentaires#
# Trois régimes, effet sur la glycémie à jeun (mg/dL)
regime_A = rng.normal(95, 10, 30) # régime standard
regime_B = rng.normal(88, 10, 30) # régime faible glucides
regime_C = rng.normal(92, 10, 30) # régime méditerranéen
# ANOVA avec scipy
f_stat, p_anova = stats.f_oneway(regime_A, regime_B, regime_C)
print(f"ANOVA à un facteur :")
print(f" F = {f_stat:.3f}")
print(f" p = {p_anova:.4f}")
print()
# Table ANOVA complète avec pingouin
df_glyc = pd.DataFrame({
'glycemie': np.concatenate([regime_A, regime_B, regime_C]),
'regime': ['Standard'] * 30 + ['Faible glucides'] * 30 + ['Méditerranéen'] * 30
})
aov = pg.anova(data=df_glyc, dv='glycemie', between='regime', detailed=True)
print("Table ANOVA (pingouin) :")
print(aov.to_string(index=False))
print()
print(f"η² (eta-carré, taille d'effet) : {aov.loc[0, 'np2']:.3f}")
ANOVA à un facteur :
F = 5.911
p = 0.0039
Table ANOVA (pingouin) :
Source SS DF MS F p_unc np2
regime 1227.941587 2 613.970794 5.911488 0.003915 0.119638
Within 9035.874239 87 103.860623 NaN NaN NaN
η² (eta-carré, taille d'effet) : 0.120
Tests post-hoc : Tukey HSD et Bonferroni#
L’ANOVA indique si au moins une paire de moyennes diffère — les tests post-hoc précisent lesquelles.
# Tests post-hoc avec pingouin
print("Post-hoc Tukey HSD :")
tukey = pg.pairwise_tukey(data=df_glyc, dv='glycemie', between='regime')
print(tukey[['A', 'B', 'mean_A', 'mean_B', 'diff', 'se', 'T', 'p_tukey']].to_string(index=False))
print()
print("Post-hoc Bonferroni :")
bonf = pg.pairwise_tests(data=df_glyc, dv='glycemie', between='regime', padjust='bonf')
print(bonf[['A', 'B', 'T', 'dof', 'p_unc', 'p_corr']].to_string(index=False))
Post-hoc Tukey HSD :
A B mean_A mean_B diff se T p_tukey
Faible glucides Méditerranéen 87.130916 90.942226 -3.811310 2.631357 -1.448420 0.320880
Faible glucides Standard 87.130916 96.143083 -9.012167 2.631357 -3.424912 0.002681
Méditerranéen Standard 90.942226 96.143083 -5.200857 2.631357 -1.976492 0.124127
Post-hoc Bonferroni :
A B T dof p_unc p_corr
Faible glucides Méditerranéen -1.385644 58.0 0.171161 0.513483
Faible glucides Standard -3.635859 58.0 0.000590 0.001769
Méditerranéen Standard -1.957010 58.0 0.055165 0.165496
ANOVA à deux facteurs#
L’ANOVA à deux facteurs analyse simultanément deux variables catégorielles et leur éventuelle interaction.
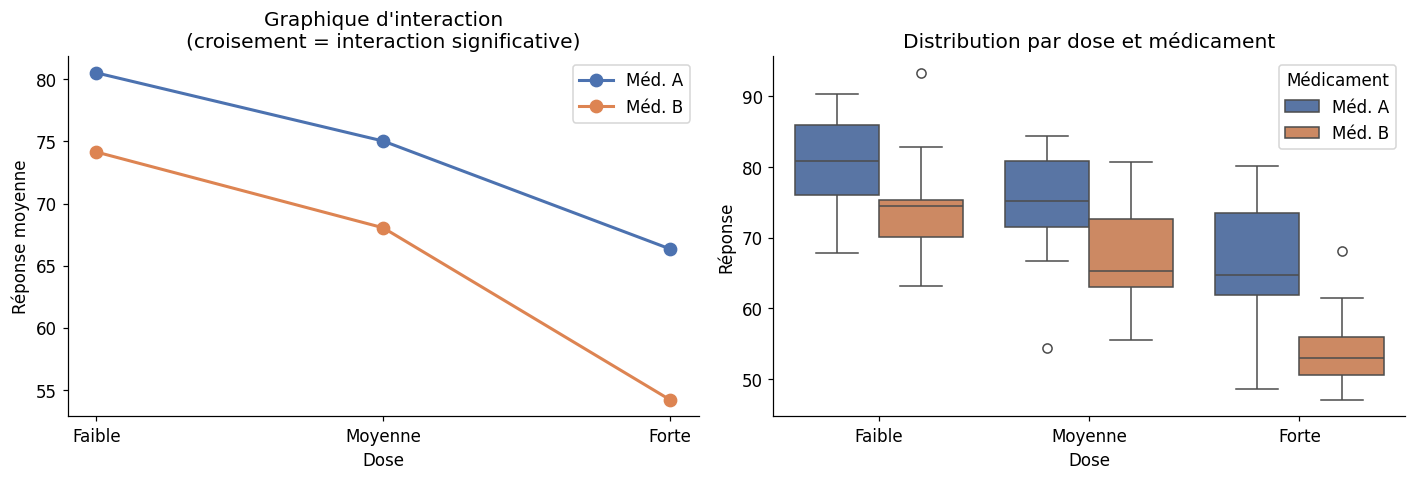
Exemple : médicament × dose#
# Plan factoriel 2×3 : 2 médicaments × 3 doses
rng2 = np.random.default_rng(123)
n_par_cellule = 15
medicaments = ['Méd. A', 'Méd. B']
doses = ['Faible', 'Moyenne', 'Forte']
data_rows = []
for med in medicaments:
for dose in doses:
# Effets principaux + interaction
base = 80
effet_med = 5 if med == 'Méd. B' else 0
effet_dose = {'Faible': 0, 'Moyenne': 8, 'Forte': 14}[dose]
# Interaction : Méd B est plus efficace à forte dose
interaction = 6 if (med == 'Méd. B' and dose == 'Forte') else 0
mu = base - effet_med - effet_dose - interaction
vals = rng2.normal(mu, 8, n_par_cellule)
for v in vals:
data_rows.append({'medicament': med, 'dose': dose, 'reponse': v})
df_fact = pd.DataFrame(data_rows)
# ANOVA à deux facteurs avec pingouin
aov2 = pg.anova(data=df_fact, dv='reponse', between=['medicament', 'dose'], detailed=True)
print("ANOVA à deux facteurs :")
print(aov2[['Source', 'SS', 'DF', 'MS', 'F', 'p_unc', 'np2']].to_string(index=False))
ANOVA à deux facteurs :
Source SS DF MS F p_unc np2
medicament 1626.149100 1 1626.149100 30.469331 3.696024e-07 0.266179
dose 4518.597961 2 2259.298981 42.332728 1.925892e-13 0.501973
medicament * dose 150.941926 2 75.470963 1.414108 2.488704e-01 0.032573
Residual 4483.082558 84 53.370030 NaN NaN NaN
Test de Fisher : comparer deux variances#
Le test F de Fisher teste \(H_0 : \sigma_1^2 = \sigma_2^2\) via la statistique \(F = s_1^2 / s_2^2\).
# Exemple : variabilité de deux procédés industriels
proc_A = rng.normal(100, 5, 30)
proc_B = rng.normal(100, 8, 30)
var_A = proc_A.var(ddof=1)
var_B = proc_B.var(ddof=1)
F_obs = var_A / var_B
# p-valeur bilatérale
df1, df2 = len(proc_A) - 1, len(proc_B) - 1
p_droite = stats.f.sf(F_obs, df1, df2)
p_gauche = stats.f.cdf(F_obs, df1, df2)
p_fisher = 2 * min(p_droite, p_gauche)
print(f"Variance procédé A : {var_A:.2f}")
print(f"Variance procédé B : {var_B:.2f}")
print(f"F = s²A / s²B = {F_obs:.3f}")
print(f"p-valeur (bilatéral) = {p_fisher:.4f}")
print()
print("Note : Levene est plus robuste que Fisher pour tester l'égalité des variances.")
lev_stat, lev_p = stats.levene(proc_A, proc_B)
print(f"Test de Levene : F = {lev_stat:.3f}, p = {lev_p:.4f}")
Variance procédé A : 27.22
Variance procédé B : 60.72
F = s²A / s²B = 0.448
p-valeur (bilatéral) = 0.0345
Note : Levene est plus robuste que Fisher pour tester l'égalité des variances.
Test de Levene : F = 2.848, p = 0.0968
Vérification des hypothèses#
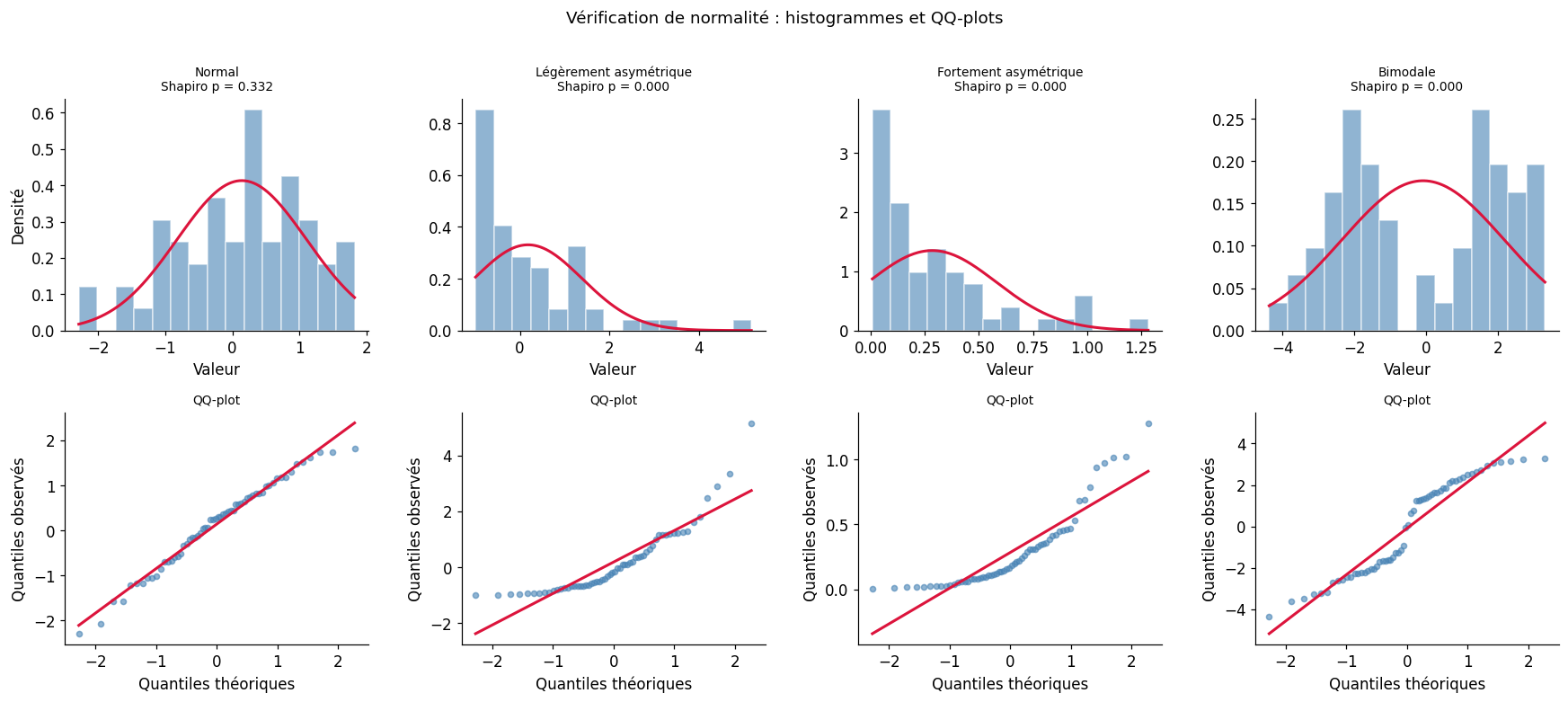
Normalité : test de Shapiro-Wilk#
Homoscédasticité : Levene et Bartlett#
# Trois groupes, dont un avec variance différente
g1 = rng.normal(50, 5, 30)
g2 = rng.normal(52, 5, 30)
g3 = rng.normal(54, 15, 30) # variance beaucoup plus grande
lev_stat, lev_p = stats.levene(g1, g2, g3)
bart_stat, bart_p = stats.bartlett(g1, g2, g3)
print("Test de Levene (robuste aux non-normalités) :")
print(f" F = {lev_stat:.3f}, p = {lev_p:.4f}")
print()
print("Test de Bartlett (sensible aux non-normalités) :")
print(f" χ² = {bart_stat:.3f}, p = {bart_p:.4f}")
print()
print(f"Variance G1: {g1.var(ddof=1):.1f}")
print(f"Variance G2: {g2.var(ddof=1):.1f}")
print(f"Variance G3: {g3.var(ddof=1):.1f}")
Test de Levene (robuste aux non-normalités) :
F = 26.480, p = 0.0000
Test de Bartlett (sensible aux non-normalités) :
χ² = 64.849, p = 0.0000
Variance G1: 14.3
Variance G2: 33.6
Variance G3: 279.1
Levene vs Bartlett
Le test de Levene est préféré en pratique : il est robuste aux écarts à la normalité, contrairement au test de Bartlett qui suppose que les groupes sont normalement distribués. Si Levene est significatif, envisagez le test de Welch (deux groupes) ou le test de Brown-Forsythe (plusieurs groupes).
Puissance statistique#
La puissance \(1 - \beta\) est la probabilité de détecter un effet réel. Elle dépend de :
La taille de l’effet (\(d\) de Cohen, \(f\) de Cohen, \(\eta^2\)…)
La taille de l’échantillon \(n\)
Le seuil \(\alpha\)
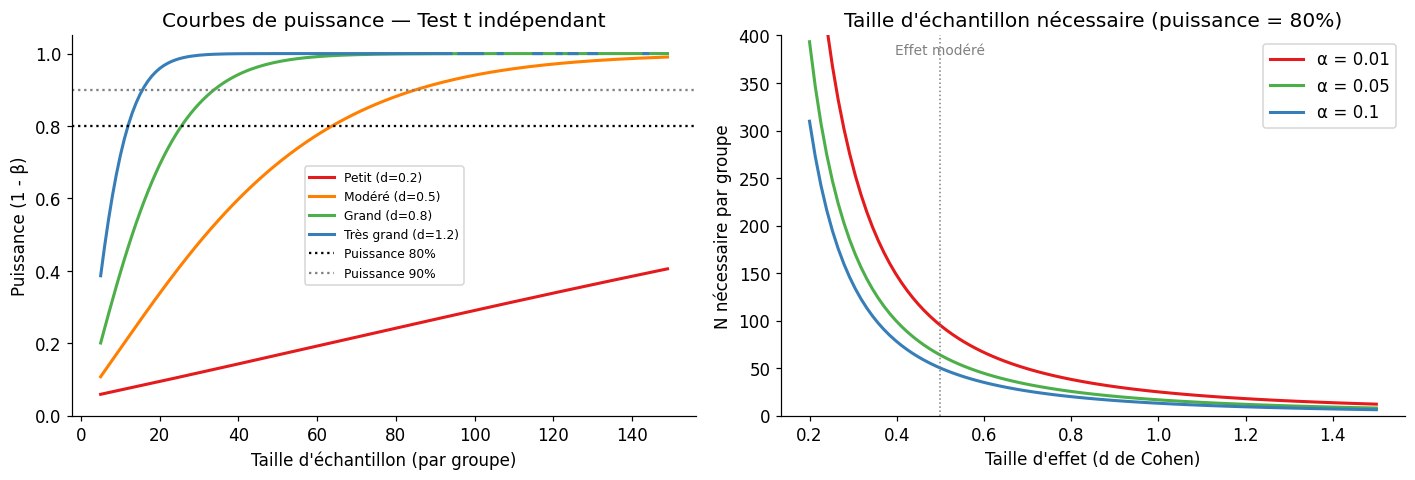
# Calcul de puissance et de n nécessaire
print("=== Calcul de puissance ===")
analysis = smp.TTestIndPower()
# Puissance pour n donné
n_obs = 30
d_cible = 0.5
pow_calc = analysis.power(effect_size=d_cible, nobs1=n_obs, alpha=0.05, ratio=1)
print(f"Puissance avec n={n_obs} par groupe, d={d_cible} : {pow_calc:.1%}")
# N nécessaire pour puissance cible
pow_cible = 0.80
n_nec = analysis.solve_power(effect_size=d_cible, alpha=0.05, power=pow_cible, ratio=1)
print(f"\nN nécessaire pour 80% de puissance, d={d_cible} : {n_nec:.0f} par groupe")
# ANOVA : puissance
print("\n=== ANOVA — puissance ===")
# f de Cohen pour ANOVA (f = 0.10 petit, 0.25 modéré, 0.40 grand)
f_cohen = 0.25
k_groupes = 3
anova_power = smp.FTestAnovaPower()
n_anova = anova_power.solve_power(effect_size=f_cohen, alpha=0.05, power=0.80, k_groups=k_groupes)
print(f"N par groupe pour ANOVA ({k_groupes} groupes), f={f_cohen}, puissance=80% : {n_anova:.0f}")
=== Calcul de puissance ===
Puissance avec n=30 par groupe, d=0.5 : 47.8%
N nécessaire pour 80% de puissance, d=0.5 : 64 par groupe
=== ANOVA — puissance ===
N par groupe pour ANOVA (3 groupes), f=0.25, puissance=80% : 157
Résumé : choisir le bon test#
Situation Test Fonction scipy Taille d'effet
1 groupe, μ connu t à 1 échantillon ttest_1samp() d de Cohen
2 groupes indépendants t de Student ttest_ind(equal_var=True) d de Cohen
2 groupes indépendants (var ≠) t de Welch (recommandé) ttest_ind(equal_var=False) d de Cohen
2 groupes appariés t apparié ttest_rel() d de Cohen
k groupes indépendants ANOVA à 1 facteur f_oneway() η² (eta-carré)
k groupes, 2 facteurs ANOVA à 2 facteurs smf.ols() + anova_lm() η² partiel
2 variances Test F de Fisher f.ppf() / levene() R² de variance
Bonnes pratiques des tests paramétriques
Vérifier les hypothèses avant le test : normalité (Shapiro-Wilk, QQ-plot), homoscédasticité (Levene).
Rapporter la taille d’effet (d de Cohen, η²) en plus de la p-valeur.
Calculer la puissance a priori pour déterminer la taille d’échantillon, et a posteriori pour interpréter les résultats non significatifs.
Utiliser Welch par défaut pour les comparaisons à deux groupes — il est robuste.
Ne pas confondre significativité statistique et importance pratique : un effet très faible peut être significatif avec un grand \(n\).
Fixer \(\alpha\) avant de voir les données.