Données manquantes et valeurs aberrantes#
Dans un monde idéal, toutes les mesures seraient complètes et exemptes d’erreurs. En pratique, les données réelles sont presque toujours trouées et bruyantes. La façon dont on gère ces imperfections peut transformer une analyse correcte en une conclusion complètement fausse — ou vice-versa. Ce chapitre couvre les mécanismes de manquance, les méthodes d’imputation (de la plus naïve à la plus sophistiquée), et la détection des valeurs aberrantes.
Mécanismes de manquance#
La taxonomie de Rubin (1976) distingue trois mécanismes fondamentalement différents, avec des implications très différentes pour l’analyse.
MCAR — Missing Completely At Random#
Les données manquent de façon entièrement aléatoire, sans lien avec les valeurs observées ou manquantes. La probabilité qu’une valeur soit manquante ne dépend ni de la variable elle-même ni d’aucune autre variable.
Exemple : un capteur défaillant de façon aléatoire, des questionnaires perdus au hasard.
Impact : l’analyse sur les données complètes reste non biaisée (mais perd en puissance).
Test (Little, 1988) : on peut tester MCAR via la statistique de Little (disponible dans pyampute ou rpy2).
MAR — Missing At Random#
Les données manquent de façon aléatoire conditionnellement aux données observées. La probabilité de manquance peut dépendre d’autres variables, mais pas de la valeur manquante elle-même.
Exemple : les femmes répondent moins souvent à la question « salaire » (probabilité de manquance liée au sexe, observé), mais pas liée au salaire lui-même.
Impact : les méthodes d’imputation qui tiennent compte des autres variables produisent des estimations non biaisées.
MNAR — Missing Not At Random#
La probabilité de manquance dépend de la valeur manquante elle-même. C’est le mécanisme le plus problématique.
Exemple : les personnes avec un salaire très élevé refusent de divulguer leur salaire. Les patients qui guérissent vite ne reviennent pas pour les visites de suivi.
Impact : toute méthode d’imputation basée uniquement sur les données observées introduira un biais. Des modèles de sélection spécifiques sont nécessaires.
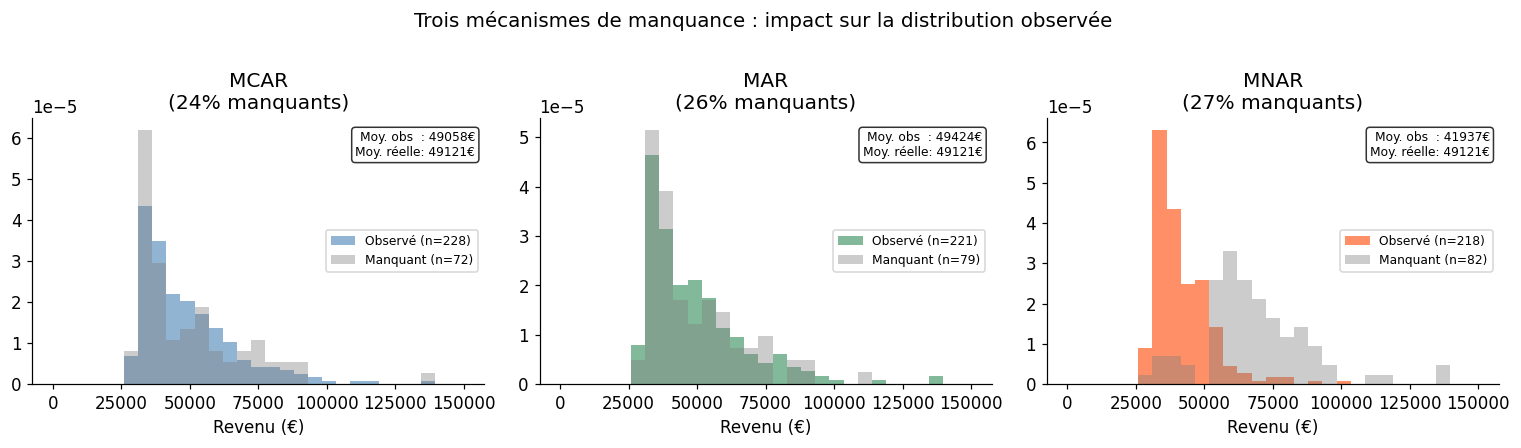
Note
La différence fondamentale : sous MCAR et MAR, la distribution observée est représentative (éventuellement après conditionnement). Sous MNAR, les données observées sont systématiquement biaisées — les hauts revenus sont sous-représentés, et aucune méthode d’imputation purement mécanique ne peut corriger ce biais.
Détection et visualisation des données manquantes#
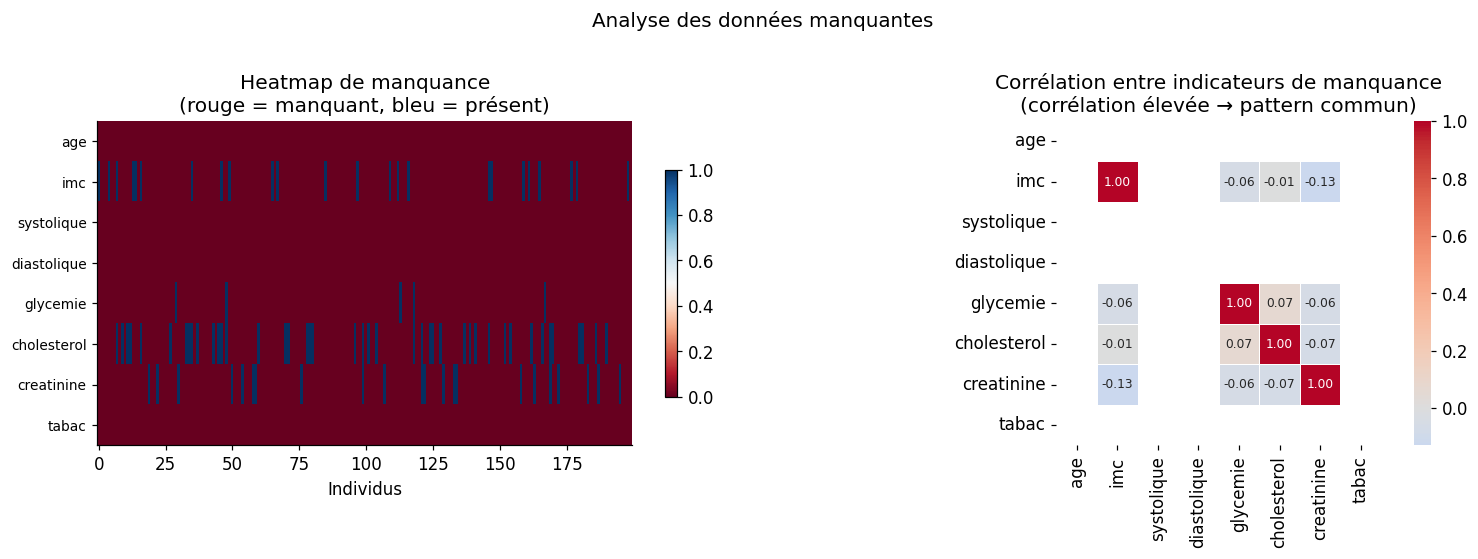
Heatmap et patterns de manquance#
Taux de données manquantes par variable :
age : 0.0%
imc : 12.0% ██████
systolique : 0.0%
diastolique : 0.0%
glycemie : 2.5% █
cholesterol : 21.5% ██████████
creatinine : 11.0% █████
tabac : 0.0%
Méthodes d’imputation#
Imputation simple#
Les méthodes simples remplacent chaque valeur manquante par une statistique de la distribution observée.
Méthode |
Formule |
Problèmes |
|---|---|---|
Moyenne |
\(\hat{x}_{ij} = \bar{x}_j\) |
Sous-estime la variance, détruit les corrélations |
Médiane |
\(\hat{x}_{ij} = \text{med}(x_j)\) |
Robuste aux outliers, mêmes problèmes |
Mode |
\(\hat{x}_{ij} = \text{mode}(x_j)\) |
Pour variables catégorielles |
Constante |
\(\hat{x}_{ij} = c\) |
Parfois utile (0 pour les comptages) |
Pour les séries temporelles, le forward fill (reporter la dernière valeur connue) et le backward fill sont naturels mais supposent une continuité temporelle.
Imputation par modèle#
# Comparaison des méthodes d'imputation sur la variable 'glycemie'
var_cible = 'glycemie'
vraies_valeurs = df_base[var_cible].values
masque = df_manquant[var_cible].isnull()
# Variables prédictives pour l'imputation
vars_pred = [c for c in df_manquant.columns if c != var_cible]
methodes = {}
# 1. Imputation par la moyenne
imp_mean = SimpleImputer(strategy='mean')
df_mean = df_manquant.copy()
df_mean[var_cible] = imp_mean.fit_transform(df_manquant[[var_cible]]).ravel()
methodes['Moyenne'] = df_mean[var_cible][masque].values
# 2. Imputation par la médiane
imp_med = SimpleImputer(strategy='median')
df_med = df_manquant.copy()
df_med[var_cible] = imp_med.fit_transform(df_manquant[[var_cible]]).ravel()
methodes['Médiane'] = df_med[var_cible][masque].values
# 3. KNN imputer
imp_knn = KNNImputer(n_neighbors=10)
df_knn_imputed = imp_knn.fit_transform(df_manquant)
methodes['KNN (k=10)'] = df_knn_imputed[masque, list(df_manquant.columns).index(var_cible)]
# 4. MICE (Multiple Imputation by Chained Equations) — une imputation simple pour l'évaluation
imp_iter = IterativeImputer(max_iter=10, random_state=42)
df_mice_imputed = imp_iter.fit_transform(df_manquant)
methodes['MICE (itératif)'] = df_mice_imputed[masque, list(df_manquant.columns).index(var_cible)]
# Évaluation
print("Évaluation des méthodes d'imputation (sur valeurs manquantes de glycémie)\n")
print(f" Vraie moyenne (données manquantes) : {vraies_valeurs[masque].mean():.3f}")
print(f" Vraie valeur observée (moyenne) : {vraies_valeurs[~masque].mean():.3f}")
print()
print(f"{'Méthode':>15} | {'RMSE':>8} | {'Biais':>10} | {'Corrélation':>12}")
print("-" * 52)
for nom, imputed in methodes.items():
vraies = vraies_valeurs[masque]
rmse = np.sqrt(np.mean((imputed - vraies)**2))
biais = np.mean(imputed - vraies)
corr = np.corrcoef(imputed, vraies)[0, 1]
print(f"{nom:>15} | {rmse:>8.3f} | {biais:>+10.3f} | {corr:>12.3f}")
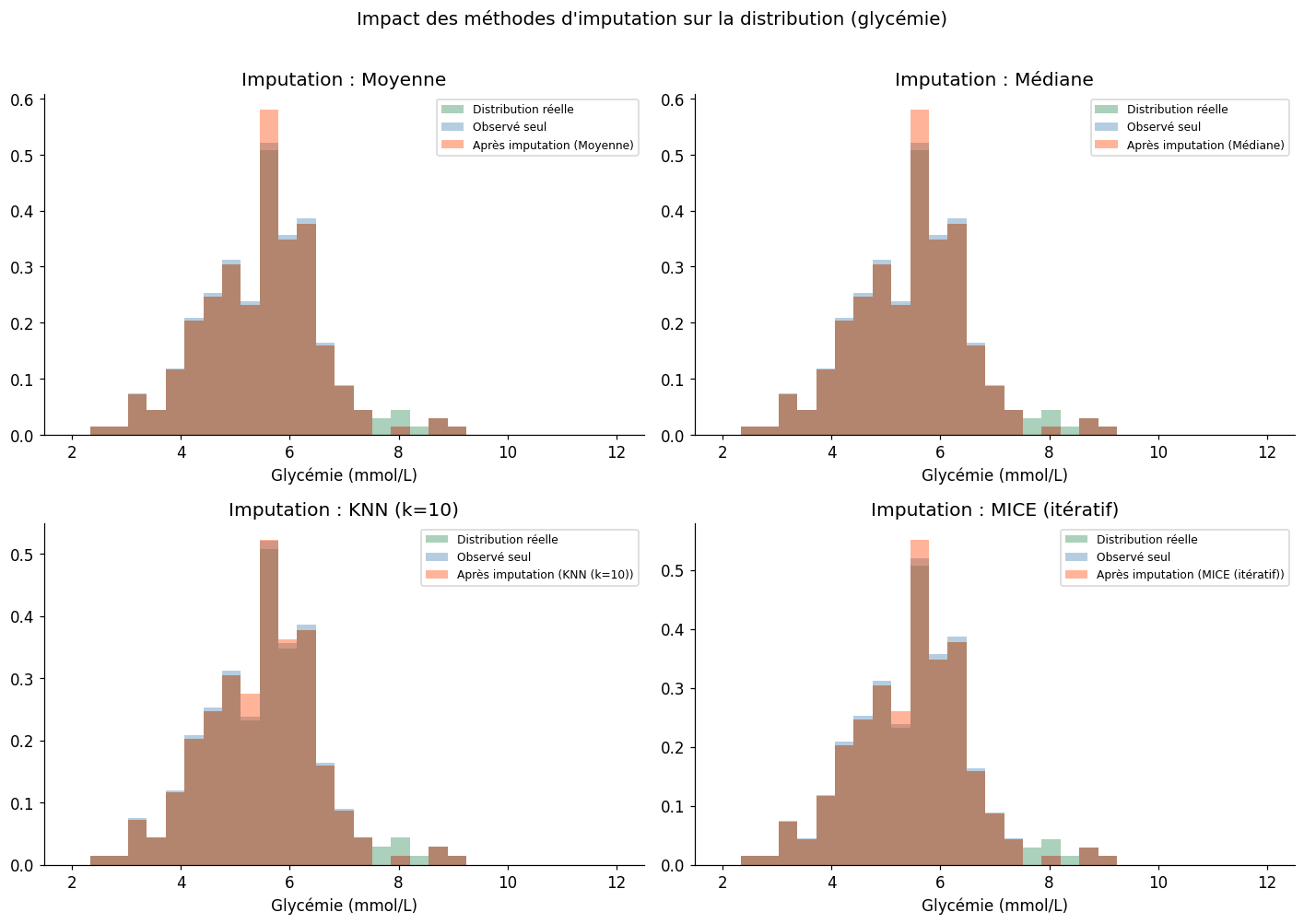
Évaluation des méthodes d'imputation (sur valeurs manquantes de glycémie)
Vraie moyenne (données manquantes) : 7.973
Vraie valeur observée (moyenne) : 5.460
Méthode | RMSE | Biais | Corrélation
----------------------------------------------------
Moyenne | 2.526 | -2.513 | nan
Médiane | 2.423 | -2.409 | nan
KNN (k=10) | 2.543 | -2.540 | 0.871
MICE (itératif) | 2.521 | -2.506 | -0.584
Imputation multiple (MICE)#
La MICE (Multiple Imputation by Chained Equations) est la méthode de référence pour les données MAR. Le principe :
Remplissage initial : imputation par la moyenne pour initialiser
Itérations cycliques : pour chaque variable avec des manquantes, entraîner un modèle (régression, forêt aléatoire…) sur les autres variables et imputer les valeurs manquantes par une valeur tirée de la distribution prédictive
M imputations : répéter le processus M fois (typiquement M = 5 à 20) pour obtenir M jeux de données complets
Analyse de chaque jeu : appliquer le modèle d’analyse à chacun des M jeux
Combinaison des résultats (règles de Rubin) :
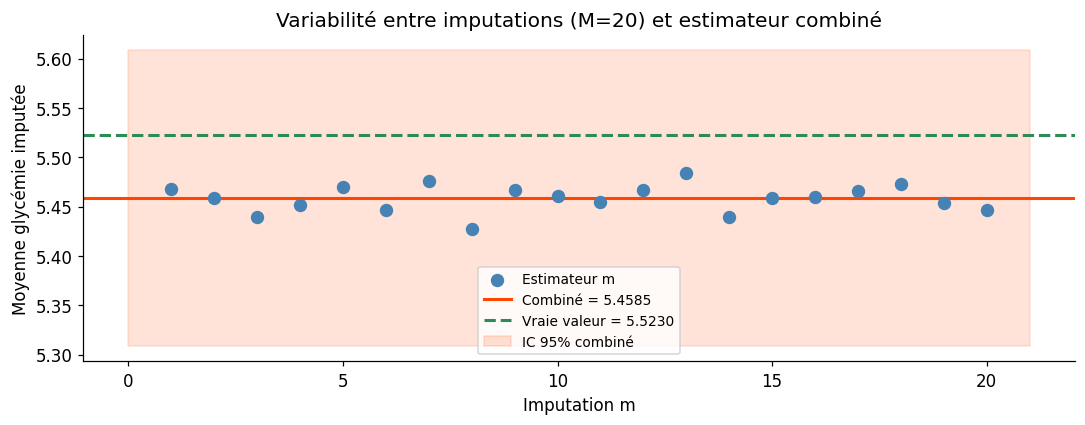
Imputation multiple (MICE) — Règles de Rubin
M = 20 imputations
Moyenne glycémie (vraie) : 5.5230
Moyenne glycémie (complète) : 5.4585
IC 95% combiné : [5.3085, 5.6084]
Variance intra (Ū) : 0.005655
Variance inter (B) : 0.000189
Fraction d'information manq. : 3.39%
Valeurs aberrantes#
Détection univariée#
Z-score : \(z_i = (x_i - \bar{x}) / s\). On considère comme aberrante toute valeur avec \(|z_i| > 3\). Problème : la moyenne et l’écart-type sont eux-mêmes sensibles aux outliers.
IQR (méthode de Tukey) : les valeurs situées au-delà de \(Q_1 - 1.5 \cdot \text{IQR}\) ou \(Q_3 + 1.5 \cdot \text{IQR}\) sont signalées (boîtes à moustaches). Le facteur 1.5 capture environ 0.7% des observations d’une normale.
Test de Grubbs : test de la valeur la plus extrême, sous hypothèse de normalité.
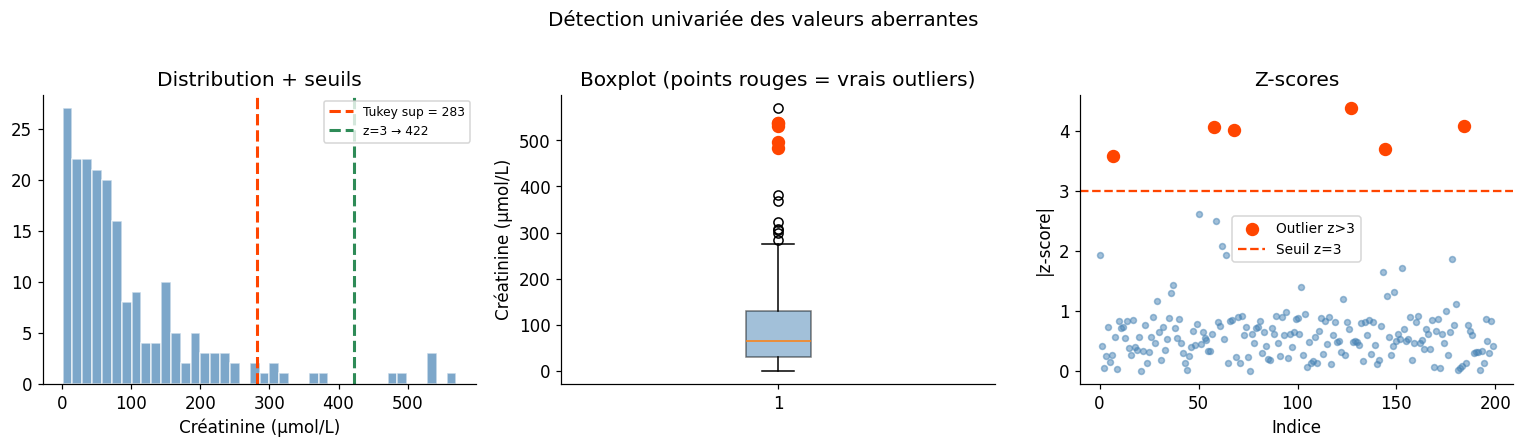
Détection d'outliers univariés — Créatinine
Z-score > 3 : 6 outliers
IQR (Tukey) : 13 outliers
Test de Grubbs : G = 4.377, G_crit = 3.606, outlier = True
Détection multivariée#
La détection univariée peut manquer des outliers qui ne sont aberrants qu’en combinaison de plusieurs variables (masqués), ou signaler des points normaux qui ont des valeurs extrêmes sur une seule variable.
Distance de Mahalanobis : généralise le z-score en tenant compte des corrélations.
Sous normalité multivariée, \(D_M^2 \sim \chi^2_p\), ce qui fournit un seuil de détection.
Isolation Forest : algorithme basé sur des arbres de décision aléatoires. L’idée : les outliers sont plus faciles à isoler (moins de coupures nécessaires pour les isoler). Le score d’anomalie est la profondeur moyenne d’isolation.
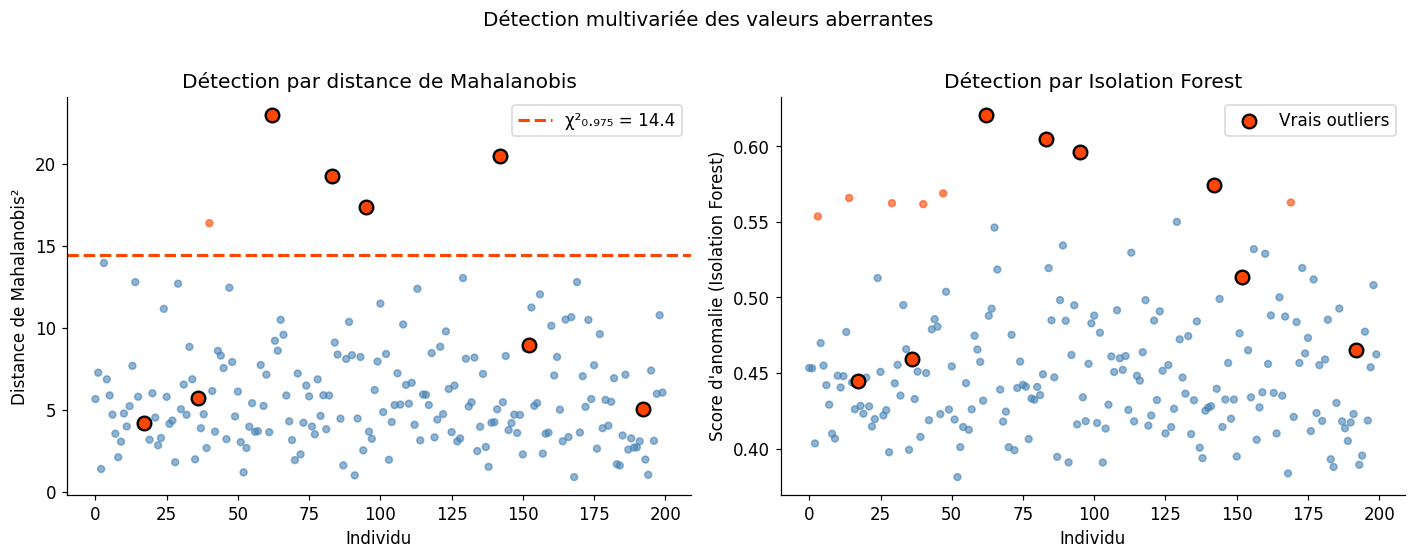
Comparaison des méthodes de détection multivariée
Distance de Mahalanobis (χ²₀.₉₇₅) : 5 outliers détectés
Isolation Forest (5%) : 10 outliers détectés
Vrais outliers : 8
Vrais positifs Mahalanobis : 4/8
Vrais positifs Iso Forest : 4/8
Traitement des valeurs aberrantes#
Une fois les outliers identifiés, quatre options principales s’offrent :
1. Supprimer#
Approprié si l’outlier est dû à une erreur de saisie ou de mesure clairement identifiée. Risqué : peut introduire un biais si les valeurs extrêmes sont réelles.
2. Winsoriser#
La winsorisation remplace les valeurs extrêmes par les percentiles correspondants (ex : tout ce qui dépasse le 99e percentile est remplacé par la valeur du 99e percentile).
from scipy.stats.mstats import winsorize
# Winsorisation
creat_winsoriee = winsorize(creatinine, limits=[0.01, 0.01])
print(f"Avant winsorisation : max = {creatinine.max():.1f}, std = {creatinine.std():.1f}")
print(f"Après winsorisation : max = {np.max(creat_winsoriee):.1f}, std = {np.std(creat_winsoriee):.1f}")
Avant winsorisation : max = 570.5, std = 107.7
Après winsorisation : max = 536.5, std = 106.7
3. Transformer#
Une transformation logarithmique réduit l’influence des valeurs extrêmes dans les distributions asymétriques positives (revenus, créatinine, durées…).
4. Modèles robustes#
Utiliser des estimateurs robustes (médiane à la place de la moyenne, régression de Huber, régression quantile) qui pèsent moins les valeurs extrêmes.
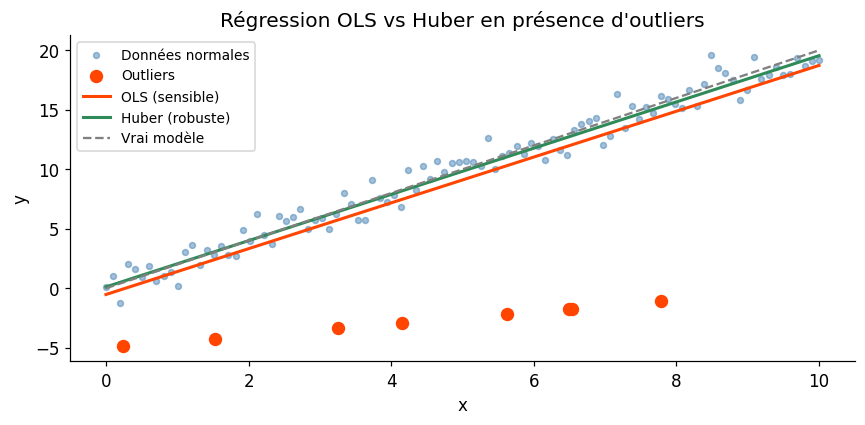
OLS : a = 1.925, b = -0.523
Huber : a = 1.943, b = 0.116
Vrai : a = 2.000, b = 0.000
Résumé et recommandations#
Protocole recommandé face aux données manquantes
Diagnostiquer le mécanisme : analyser si la manquance est liée à d’autres variables (MAR) ou à la variable elle-même (MNAR).
Quantifier : calculer le taux de manquance par variable. Au-delà de 40-50%, l’imputation devient très incertaine.
Choisir la méthode selon le mécanisme :
MCAR : n’importe quelle méthode raisonnable (KNN, médiane)
MAR : MICE ou KNN imputer
MNAR : modèles de sélection spécifiques ou analyse de sensibilité
Utiliser l’imputation multiple (MICE) pour les analyses inférentielles importantes — l’imputation simple sous-estime l’incertitude.
Toujours comparer les distributions avant/après imputation.
Protocole pour les valeurs aberrantes
Distinguer erreur de mesure (corriger ou supprimer) et valeur extrême réelle (conserver ou robustifier).
Ne jamais supprimer un outlier uniquement parce qu’il gêne le résultat.
Analyser avec et sans les outliers et rapporter les deux résultats.
Préférer les méthodes robustes (régression de Huber, médiane, quantiles) si les outliers sont courants dans le domaine.
Pour la détection multivariée : utiliser la distance de Mahalanobis (sous normalité) ou l’Isolation Forest (général).