Séries temporelles#
Une série temporelle est une donnée qui se souvient de son passé.
Introduction#
Une série temporelle est une suite d’observations ordonnées dans le temps : \(y_1, y_2, \ldots, y_T\). On la rencontre partout — ventes mensuelles, cours boursiers, température quotidienne, trafic web par heure. L’ordre temporel crée une dépendance entre observations qui invalide l’hypothèse d’indépendance classique et exige des méthodes spécifiques.
Les objectifs sont multiples : décrire la structure (tendance, saisonnalité), comprendre les mécanismes générateurs, et surtout prévoir les valeurs futures.
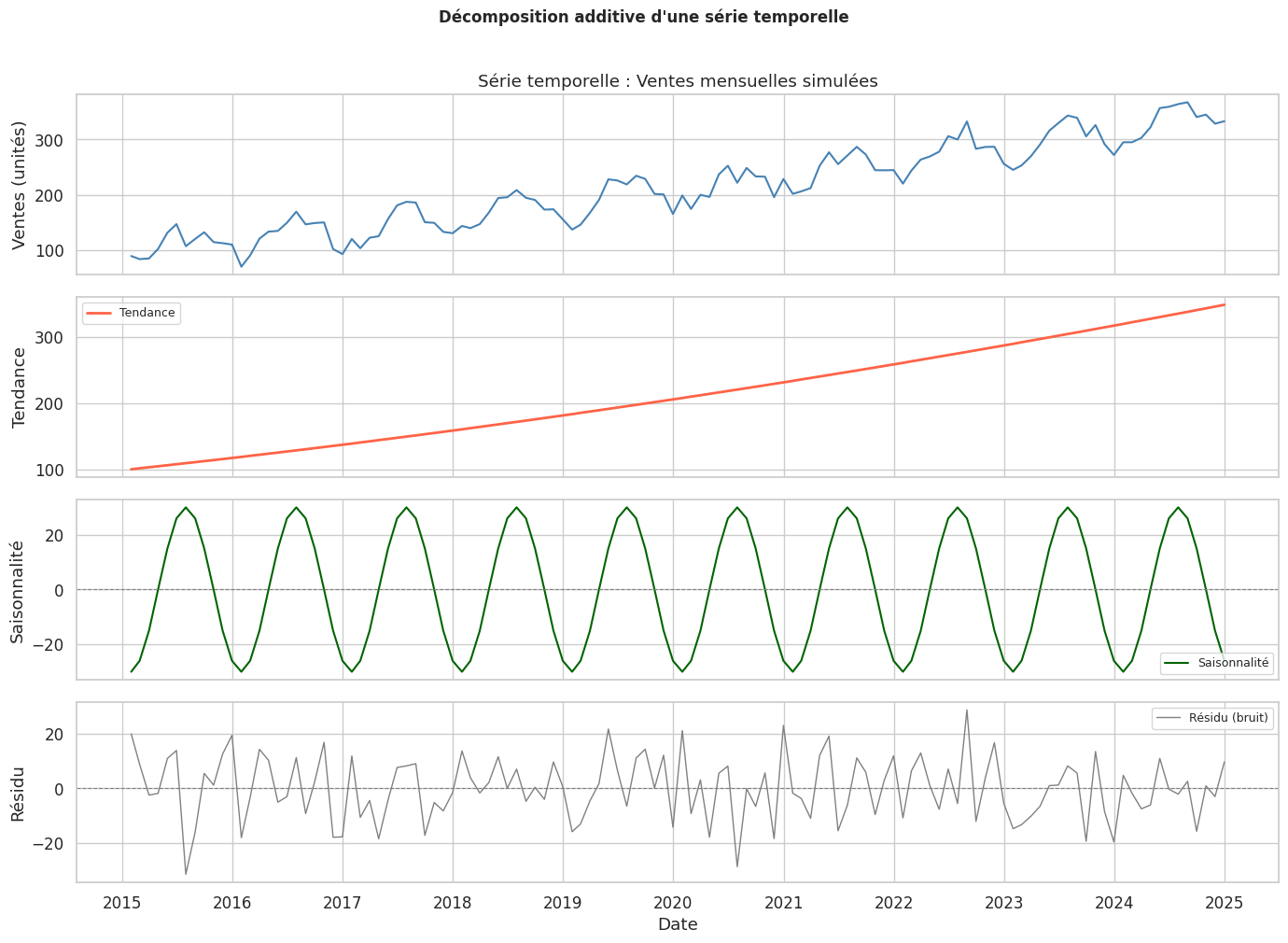
Décomposition d’une série temporelle#
Toute série peut être vue comme la superposition de composantes :
Modèle additif : \(y_t = T_t + S_t + R_t\)
Modèle multiplicatif : \(y_t = T_t \times S_t \times R_t\)
Le modèle multiplicatif est adapté quand l’amplitude de la saisonnalité croît avec le niveau (typique des séries financières ou de ventes en croissance forte).
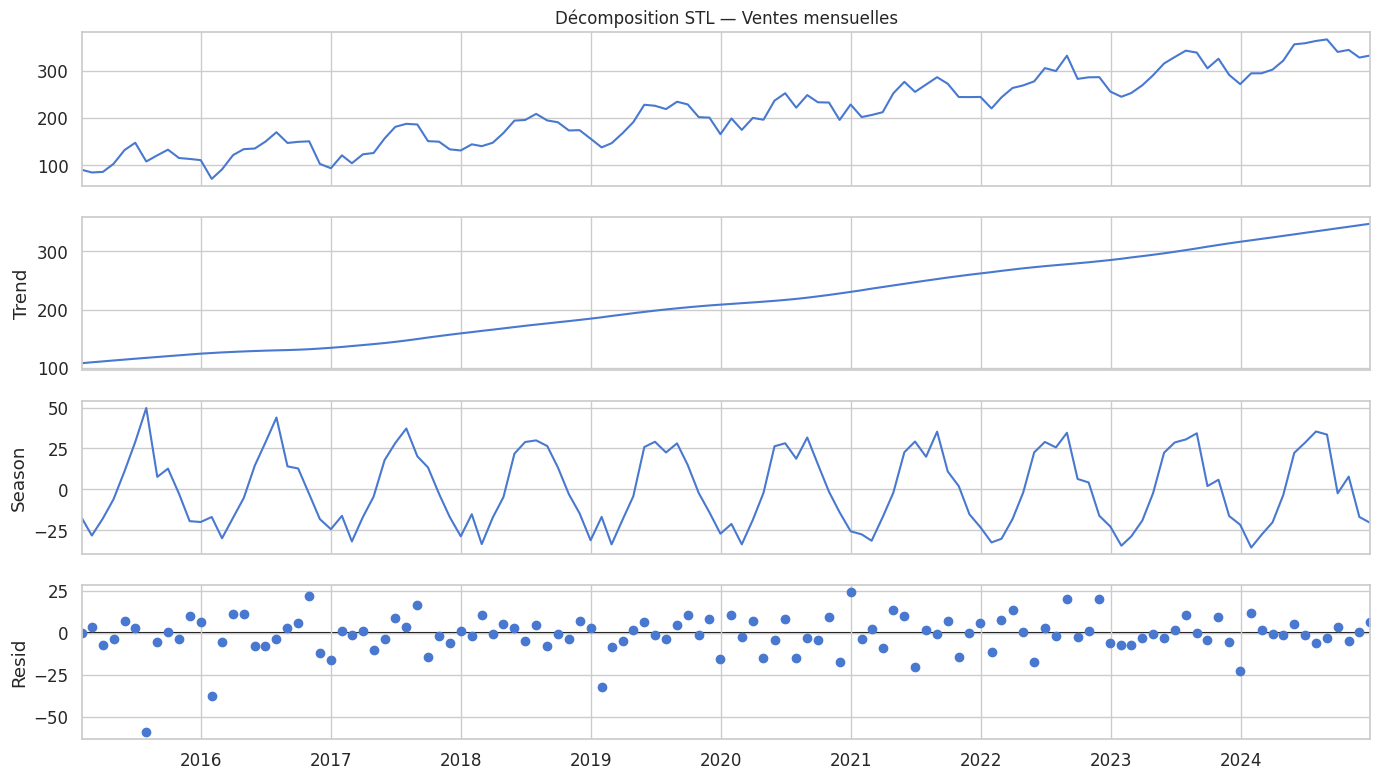
Statistiques de la décomposition STL :
Force de la tendance : 0.977
Force de la saisonnalité: 0.798
(0=absent, 1=composante dominante)
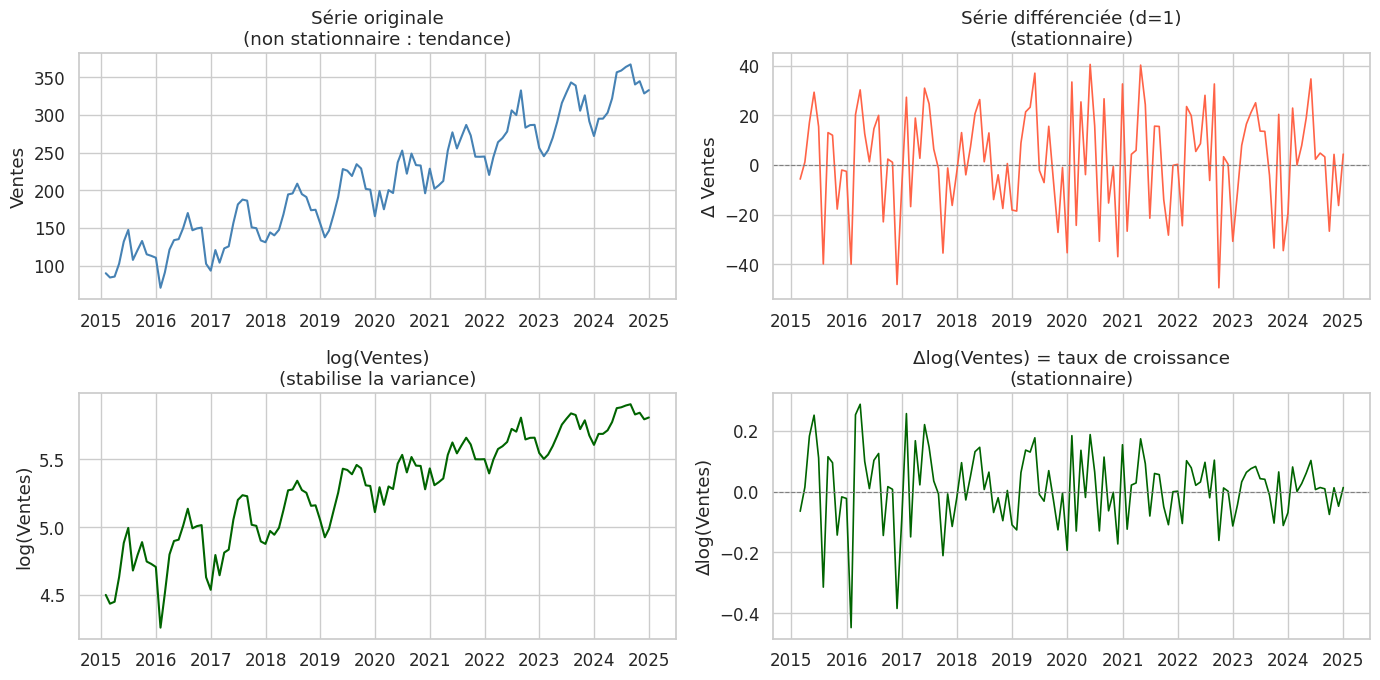
Stationnarité#
Une série est stationnaire au sens faible si :
\(E[y_t] = \mu\) (constante)
\(\text{Var}(y_t) = \sigma^2\) (constante)
\(\text{Cov}(y_t, y_{t+k}) = \gamma_k\) (dépend seulement du lag \(k\), pas de \(t\))
La stationnarité est une condition nécessaire pour la plupart des modèles ARIMA.
Tests de stationnarité#
def test_stationnarite(serie, nom='Série'):
"""Applique les tests ADF et KPSS."""
print(f"\n=== Tests de stationnarité : {nom} ===")
# Test ADF : H0 = racine unitaire (non stationnaire)
adf_result = adfuller(serie.dropna(), autolag='AIC')
print(f"\nTest ADF (Augmented Dickey-Fuller) :")
print(f" Statistique : {adf_result[0]:.4f}")
print(f" p-valeur : {adf_result[1]:.4f}")
print(f" Valeurs critiques : {adf_result[4]}")
if adf_result[1] < 0.05:
print(" → Rejet H0 : la série est STATIONNAIRE (ADF)")
else:
print(" → Non-rejet H0 : la série est probablement NON-STATIONNAIRE (ADF)")
# Test KPSS : H0 = stationnarité
kpss_result = kpss(serie.dropna(), regression='c', nlags='auto')
print(f"\nTest KPSS :")
print(f" Statistique : {kpss_result[0]:.4f}")
print(f" p-valeur : {kpss_result[1]:.4f}")
if kpss_result[1] > 0.05:
print(" → Non-rejet H0 : la série est STATIONNAIRE (KPSS)")
else:
print(" → Rejet H0 : la série est NON-STATIONNAIRE (KPSS)")
# Série originale (avec tendance)
test_stationnarite(serie, 'Ventes originales')
# Après différenciation d'ordre 1
serie_diff = serie.diff().dropna()
test_stationnarite(serie_diff, 'Ventes différenciées (d=1)')
=== Tests de stationnarité : Ventes originales ===
Test ADF (Augmented Dickey-Fuller) :
Statistique : 2.3637
p-valeur : 0.9990
Valeurs critiques : {'1%': np.float64(-3.4924012594942333), '5%': np.float64(-2.8886968193364835), '10%': np.float64(-2.5812552709190673)}
→ Non-rejet H0 : la série est probablement NON-STATIONNAIRE (ADF)
Test KPSS :
Statistique : 1.7617
p-valeur : 0.0100
→ Rejet H0 : la série est NON-STATIONNAIRE (KPSS)
=== Tests de stationnarité : Ventes différenciées (d=1) ===
Test ADF (Augmented Dickey-Fuller) :
Statistique : -8.4726
p-valeur : 0.0000
Valeurs critiques : {'1%': np.float64(-3.4924012594942333), '5%': np.float64(-2.8886968193364835), '10%': np.float64(-2.5812552709190673)}
→ Rejet H0 : la série est STATIONNAIRE (ADF)
Test KPSS :
Statistique : 0.0137
p-valeur : 0.1000
→ Non-rejet H0 : la série est STATIONNAIRE (KPSS)
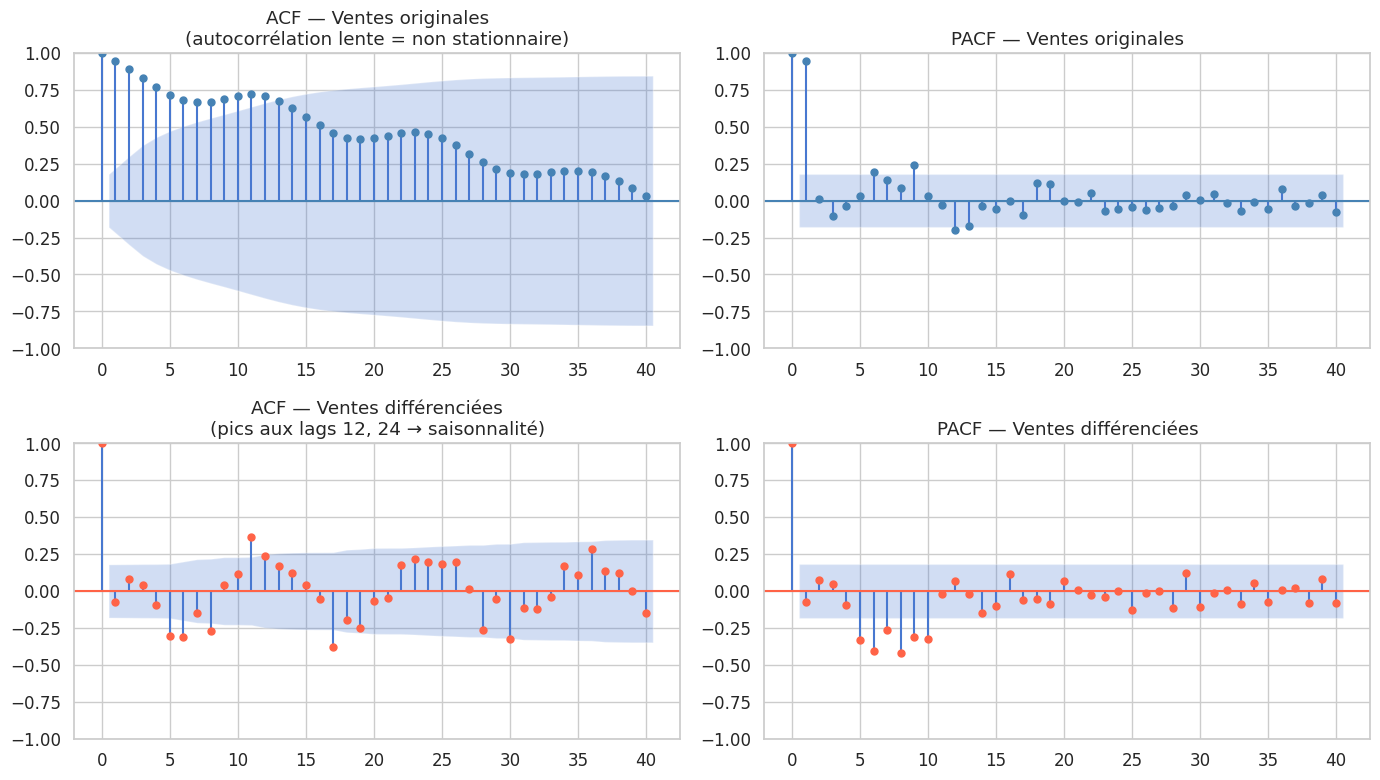
ACF et PACF : identifier l’ordre du modèle#
ACF (Autocorrelation Function) : corrélation entre \(y_t\) et \(y_{t-k}\).
PACF (Partial ACF) : corrélation entre \(y_t\) et \(y_{t-k}\) après avoir éliminé l’effet des lags intermédiaires.
Règles d’identification#
Modèle |
ACF |
PACF |
|---|---|---|
AR(p) |
Décroissance géométrique ou oscillante |
Coupure nette après le lag p |
MA(q) |
Coupure nette après le lag q |
Décroissance géométrique ou oscillante |
ARMA(p,q) |
Décroissance après lag q |
Décroissance après lag p |
Modèles AR, MA et ARMA#
Processus AR(p) — Autorégressif#
Processus MA(q) — Moyenne mobile#
Processus ARMA(p, q)#
Combinaison des deux.
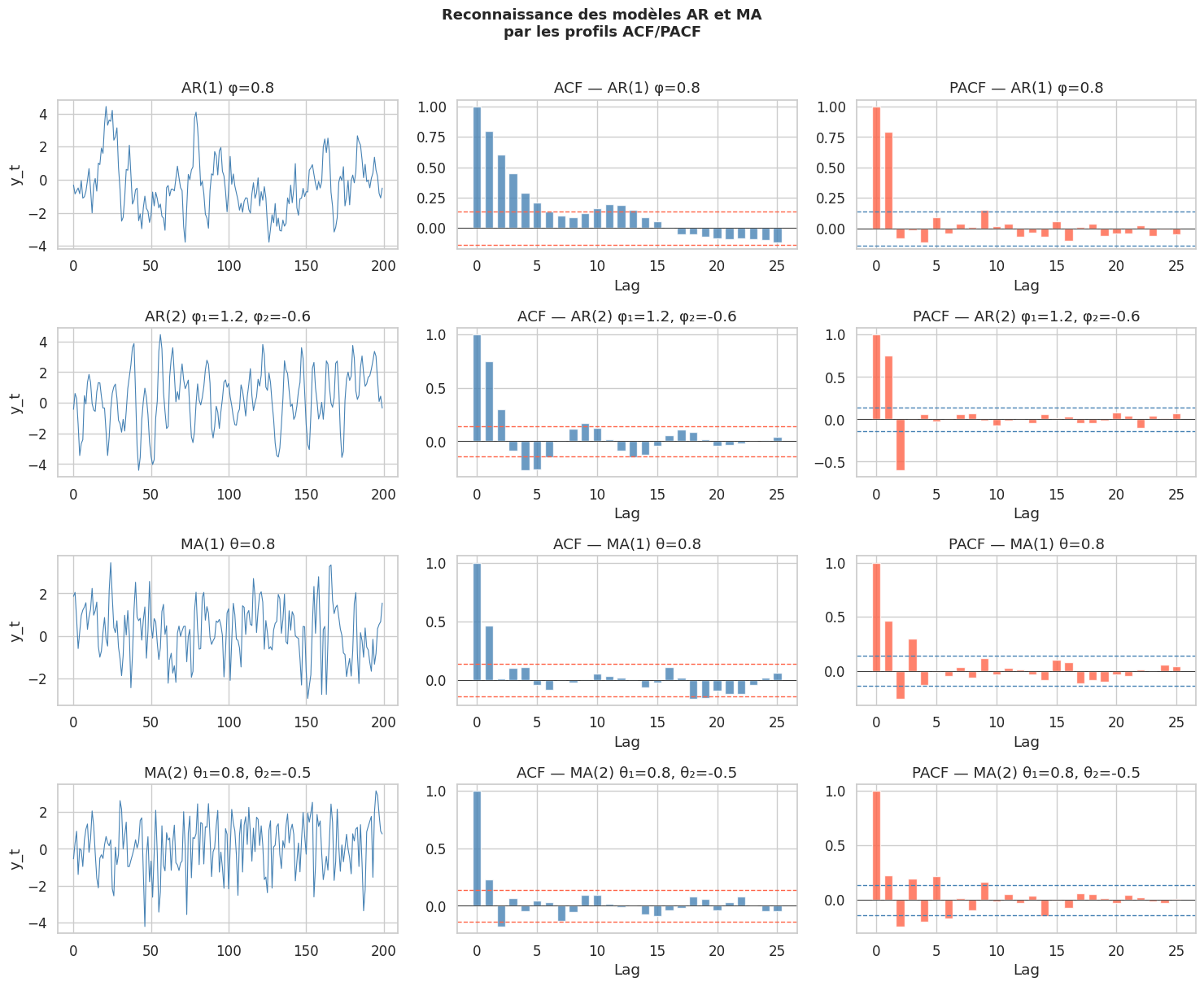
ARIMA : identification et estimation#
Le modèle ARIMA(p, d, q) (AutoRegressive Integrated Moving Average) généralise ARMA en permettant la différenciation d’ordre \(d\) pour rendre la série stationnaire.
# Sélection automatique d'ordre par AIC sur la série de ventes différenciée
# On teste quelques modèles ARIMA manuellement
print("Sélection du modèle ARIMA par AIC :")
print("="*50)
aic_results = []
for p in range(0, 4):
for q in range(0, 4):
try:
mod = ARIMA(serie, order=(p, 1, q)).fit()
aic_results.append({'p': p, 'd': 1, 'q': q, 'AIC': mod.aic, 'BIC': mod.bic})
except Exception:
pass
df_aic = pd.DataFrame(aic_results).sort_values('AIC').head(8)
print(df_aic.to_string(index=False))
Sélection du modèle ARIMA par AIC :
==================================================
p d q AIC BIC
2 1 3 995.483412 1012.158153
2 1 2 1035.355548 1049.251165
3 1 3 1049.481567 1068.935432
3 1 2 1060.427522 1077.102263
0 1 0 1060.733293 1063.512417
1 1 3 1061.164003 1075.059620
0 1 3 1061.912076 1073.028570
2 1 1 1062.093608 1073.210102
# Ajustement du meilleur modèle ARIMA
best_order = tuple(df_aic.iloc[0][['p', 'd', 'q']].astype(int))
print(f"Meilleur modèle : ARIMA{best_order}")
model_arima = ARIMA(serie, order=best_order).fit()
print(model_arima.summary())
Meilleur modèle : ARIMA(2, 1, 3)
SARIMAX Results
==============================================================================
Dep. Variable: ventes No. Observations: 120
Model: ARIMA(2, 1, 3) Log Likelihood -491.742
Date: Wed, 01 Apr 2026 AIC 995.483
Time: 22:30:59 BIC 1012.158
Sample: 01-31-2015 HQIC 1002.254
- 12-31-2024
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 1.7314 0.004 424.047 0.000 1.723 1.739
ar.L2 -0.9999 0.002 -539.558 0.000 -1.004 -0.996
ma.L1 -2.3287 4.741 -0.491 0.623 -11.622 6.964
ma.L2 2.0450 8.387 0.244 0.807 -14.393 18.483
ma.L3 -0.6071 3.340 -0.182 0.856 -7.154 5.940
sigma2 209.4804 1155.390 0.181 0.856 -2055.043 2474.003
===================================================================================
Ljung-Box (L1) (Q): 5.71 Jarque-Bera (JB): 3.34
Prob(Q): 0.02 Prob(JB): 0.19
Heteroskedasticity (H): 0.82 Skew: -0.40
Prob(H) (two-sided): 0.54 Kurtosis: 3.16
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
SARIMA : modèle saisonnier#
Le modèle SARIMA(p,d,q)(P,D,Q)ₛ ajoute des composantes autorégressives et de moyennes mobiles saisonnières d’ordre \(s\) :
# Modèle SARIMA(1,1,1)(1,1,1)12 pour les ventes mensuelles
model_sarima = SARIMAX(serie,
order=(1, 1, 1),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False).fit(disp=False)
print(f"SARIMA(1,1,1)(1,1,1)12")
print(f" AIC : {model_sarima.aic:.1f}")
print(f" BIC : {model_sarima.bic:.1f}")
print(model_sarima.summary().tables[1])
SARIMA(1,1,1)(1,1,1)12
AIC : 747.6
BIC : 760.2
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 -0.1232 0.142 -0.870 0.384 -0.401 0.154
ma.L1 -0.8796 0.079 -11.083 0.000 -1.035 -0.724
ar.S.L12 0.0127 0.008 1.514 0.130 -0.004 0.029
ma.S.L12 -1.0000 0.170 -5.870 0.000 -1.334 -0.666
sigma2 129.0331 0.001 9.77e+04 0.000 129.031 129.036
==============================================================================
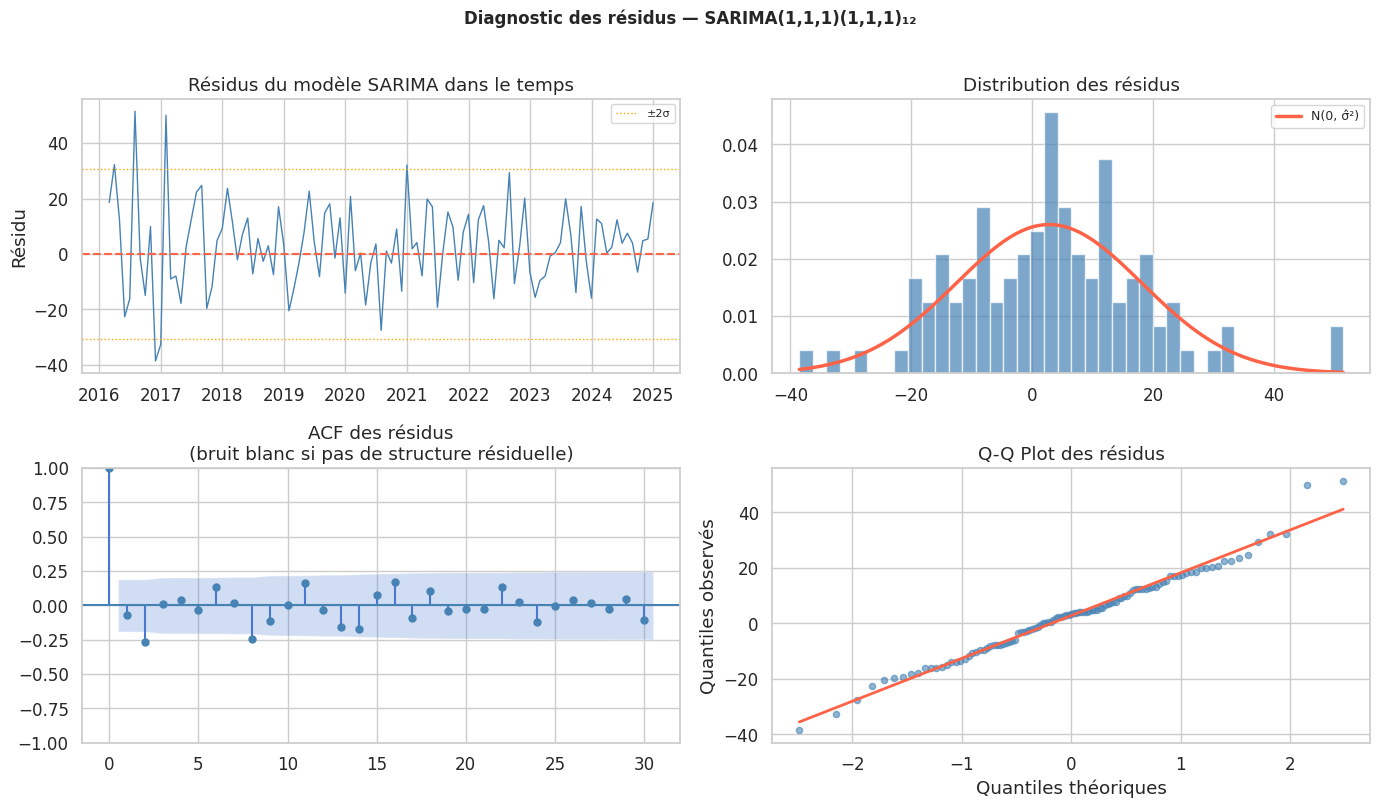
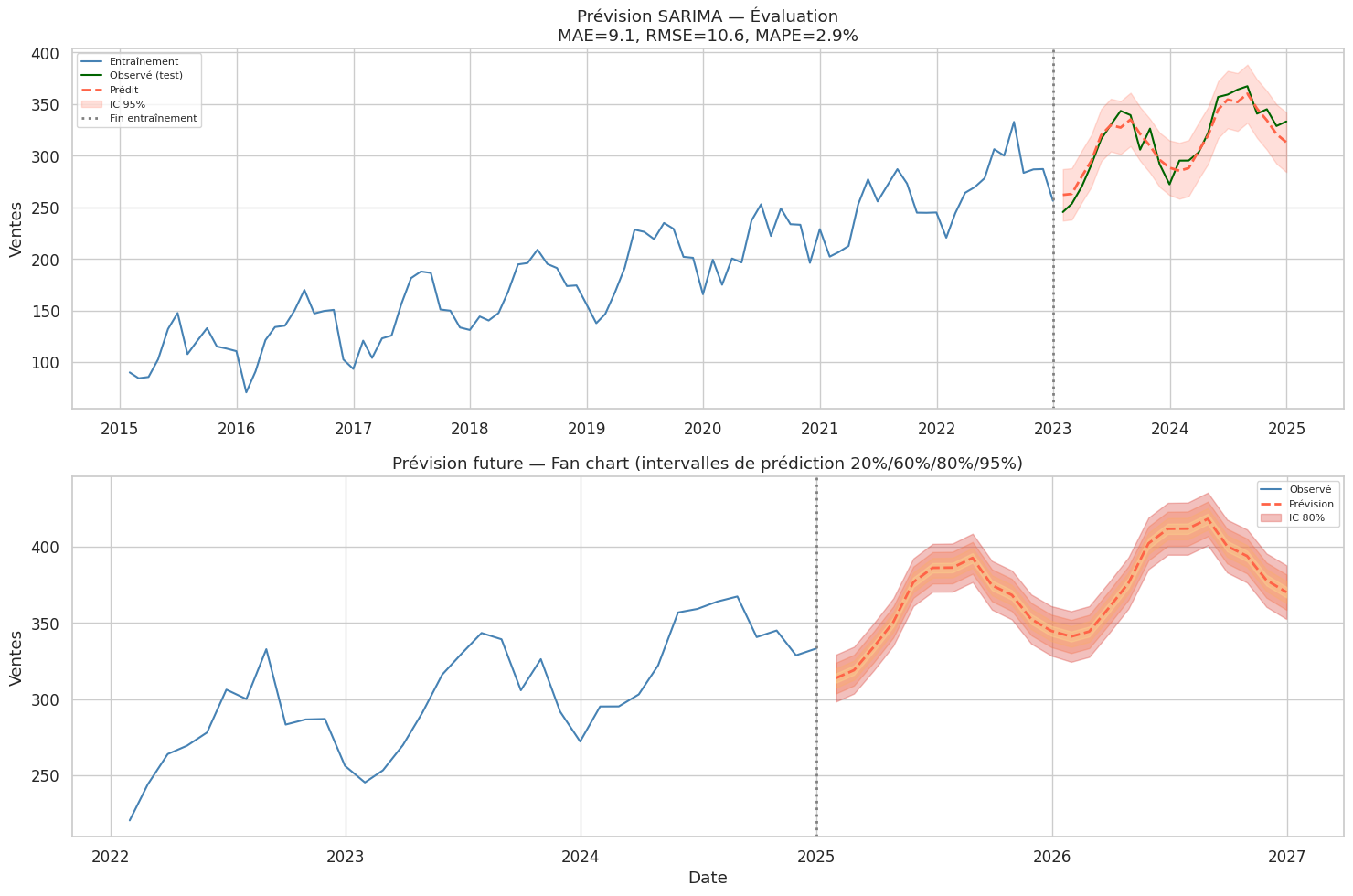
Prévision avec intervalles de prédiction#
# Prévision 24 mois en avant
horizon = 24
forecast = model_sarima.get_forecast(steps=horizon)
pred_mean = forecast.predicted_mean
pred_ci = forecast.conf_int(alpha=0.05)
# Dates de prévision
dates_forecast = pd.date_range(serie.index[-1] + pd.DateOffset(months=1),
periods=horizon, freq='ME')
# Évaluation sur la fin de la série (walk-forward)
# Utiliser les 96 premiers mois pour entraîner, tester sur les 24 derniers
n_train = 96
serie_train = serie.iloc[:n_train]
serie_test = serie.iloc[n_train:]
model_eval = SARIMAX(serie_train,
order=(1, 1, 1),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False).fit(disp=False)
forecast_eval = model_eval.get_forecast(steps=len(serie_test))
y_pred_eval = forecast_eval.predicted_mean
y_true_eval = serie_test.values
# Métriques
mae = np.mean(np.abs(y_true_eval - y_pred_eval))
rmse = np.sqrt(np.mean((y_true_eval - y_pred_eval)**2))
mape = np.mean(np.abs((y_true_eval - y_pred_eval) / y_true_eval)) * 100
print("Évaluation de la prévision (test : 24 derniers mois) :")
print(f" MAE : {mae:.1f}")
print(f" RMSE : {rmse:.1f}")
print(f" MAPE : {mape:.1f}%")
Évaluation de la prévision (test : 24 derniers mois) :
MAE : 9.1
RMSE : 10.6
MAPE : 2.9%
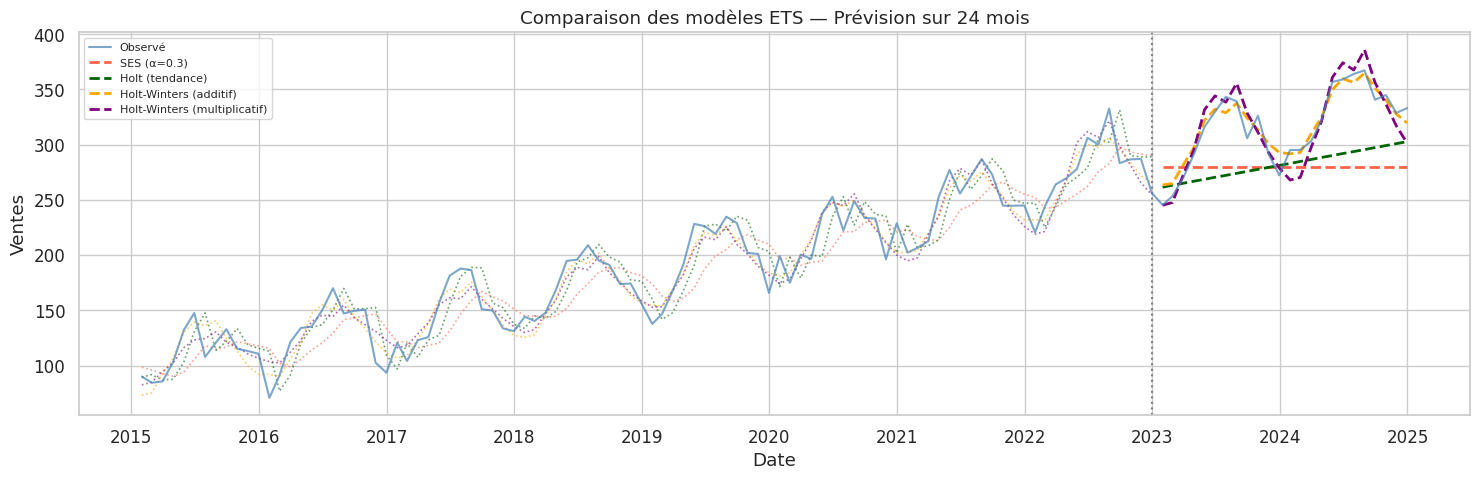
Lissage exponentiel (ETS)#
Les modèles ETS (Error, Trend, Seasonality) offrent une alternative aux modèles ARIMA via une pondération exponentielle décroissante des observations passées.
Lissage simple (SES)#
Méthode de Holt (double lissage)#
Prend en compte la tendance avec deux équations de mise à jour.
Holt-Winters (triple lissage)#
Prend en compte tendance et saisonnalité.
# Comparaison des méthodes de lissage exponentiel
models_ets = {
'SES (α=0.3)': ExponentialSmoothing(serie_train, trend=None, seasonal=None).fit(
smoothing_level=0.3),
'Holt (tendance)': ExponentialSmoothing(serie_train, trend='add', seasonal=None,
damped_trend=False).fit(optimized=True),
'Holt-Winters (additif)': ExponentialSmoothing(serie_train, trend='add',
seasonal='add', seasonal_periods=12,
damped_trend=True).fit(optimized=True),
'Holt-Winters (multiplicatif)': ExponentialSmoothing(serie_train, trend='add',
seasonal='mul', seasonal_periods=12,
damped_trend=True).fit(optimized=True),
}
print("Comparaison des modèles ETS :")
print(f"{'Modèle':<35} {'AIC':>10} {'RMSE test':>12}")
print('-' * 60)
for nom, mod in models_ets.items():
preds = mod.forecast(len(serie_test))
rmse_ets = np.sqrt(np.mean((serie_test.values - preds.values)**2))
try:
aic_ets = mod.aic
except Exception:
aic_ets = float('nan')
print(f"{nom:<35} {aic_ets:>10.1f} {rmse_ets:>12.1f}")
Comparaison des modèles ETS :
Modèle AIC RMSE test
------------------------------------------------------------
SES (α=0.3) 626.0 49.7
Holt (tendance) 591.6 43.7
Holt-Winters (additif) 515.9 10.0
Holt-Winters (multiplicatif) 532.5 14.5
Métriques d’évaluation#
from sklearn.metrics import mean_absolute_error, mean_squared_error
def metriques_prevision(y_true, y_pred, nom=''):
"""Calcule MAE, RMSE, MAPE et MASE."""
mae_val = mean_absolute_error(y_true, y_pred)
rmse_val = np.sqrt(mean_squared_error(y_true, y_pred))
mape_val = np.mean(np.abs((y_true - y_pred) / (y_true + 1e-9))) * 100
return {'Modèle': nom, 'MAE': mae_val, 'RMSE': rmse_val, 'MAPE (%)': mape_val}
resultats_eval = []
# SARIMA
resultats_eval.append(metriques_prevision(serie_test.values, y_pred_eval.values, 'SARIMA(1,1,1)(1,1,1)₁₂'))
# ETS
for nom, mod in models_ets.items():
preds = mod.forecast(len(serie_test))
resultats_eval.append(metriques_prevision(serie_test.values, preds.values, nom))
df_resultats = pd.DataFrame(resultats_eval).set_index('Modèle')
print("Comparaison finale des modèles :")
print(df_resultats.round(2).to_string())
print("\n→ MAPE < 5% : excellente prévision")
print("→ MAPE 5-10% : bonne prévision")
print("→ MAPE > 20% : prévision médiocre")
Comparaison finale des modèles :
MAE RMSE MAPE (%)
Modèle
SARIMA(1,1,1)(1,1,1)₁₂ 9.07 10.60 2.93
SES (α=0.3) 43.04 49.65 13.04
Holt (tendance) 37.25 43.73 11.21
Holt-Winters (additif) 8.12 9.98 2.70
Holt-Winters (multiplicatif) 11.53 14.49 3.60
→ MAPE < 5% : excellente prévision
→ MAPE 5-10% : bonne prévision
→ MAPE > 20% : prévision médiocre
Choix entre ARIMA et ETS
ARIMA/SARIMA : meilleur pour les séries avec des dépendances complexes, adapté quand ACF/PACF montrent une structure claire. Peut intégrer des variables exogènes (SARIMAX).
ETS/Holt-Winters : plus intuitif, robuste, souvent très compétitif en pratique. Plus rapide à estimer.
En production, tester les deux et sélectionner par validation croisée temporelle (time series cross-validation).
Validation croisée temporelle#
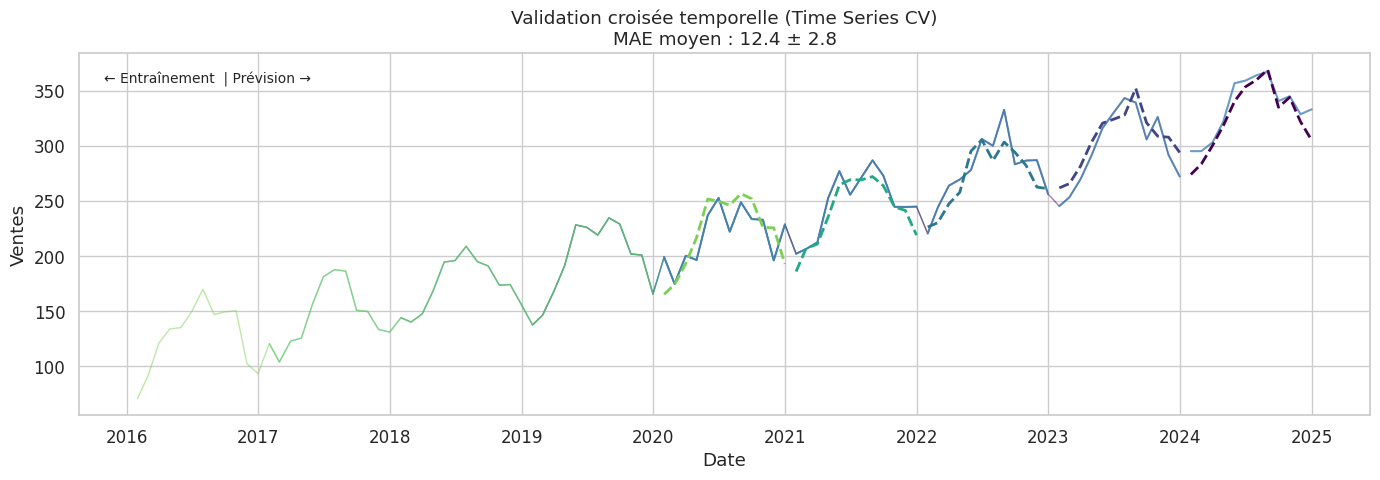
MAE par fold : ['9.1', '13.5', '12.7', '9.7', '16.8']
MAE moyen : 12.4
Résumé#
Points clés — Séries temporelles
Prétraitement :
Vérifier la stationnarité (tests ADF et KPSS) et différencier si nécessaire.
Visualiser ACF/PACF pour identifier l’ordre (p, q) du modèle.
Décomposer avec STL pour séparer tendance, saisonnalité et résidu.
Modèles :
ARIMA(p,d,q) : modèle général pour séries stationnaires après différenciation.
SARIMA(p,d,q)(P,D,Q)ₛ : extension saisonnière indispensable pour les données périodiques.
ETS/Holt-Winters : approche de lissage, souvent compétitive et plus interprétable.
Validation :
Toujours évaluer sur des données futures (jamais d’inversion temporelle !).
Métriques : MAE, RMSE, MAPE selon le contexte.
Valider les résidus : bruit blanc (ACF ≈ 0, gaussien).
Utiliser la validation croisée temporelle pour estimer la généralisation.