Statistiques computationnelles#
Avant l’ère des ordinateurs, les statisticiens devaient se contenter de résultats analytiques exacts — formules closes, tables de distributions, approximations asymptotiques. Aujourd’hui, la puissance de calcul disponible permet d”estimer par simulation ce qui ne peut pas être calculé analytiquement. Ce chapitre couvre les grandes familles de méthodes computationnelles : Monte Carlo, tests de permutation, bootstrap, jackknife, et validation croisée statistique.
Simulation Monte Carlo#
Principe général#
La méthode de Monte Carlo repose sur la loi des grands nombres : la moyenne empirique d’une grande quantité de réalisations indépendantes d’une variable aléatoire converge vers son espérance. Pour estimer \(\mu = \mathbb{E}[f(X)]\) :
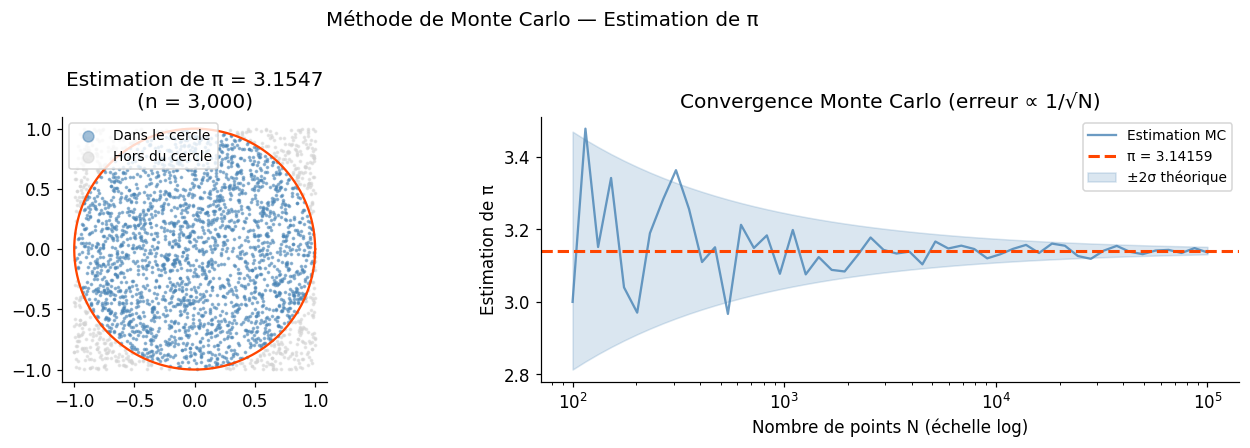
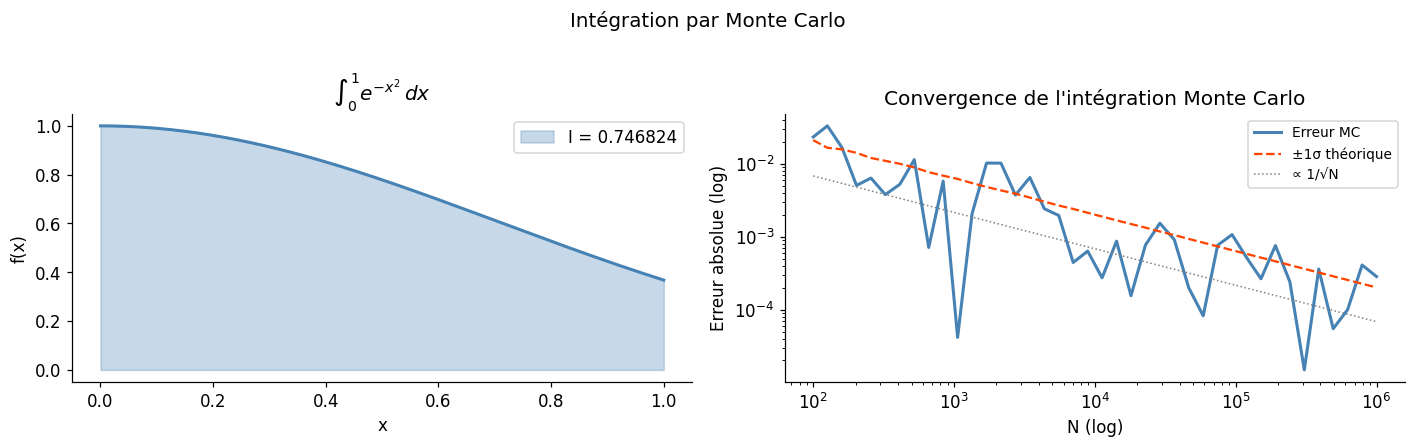
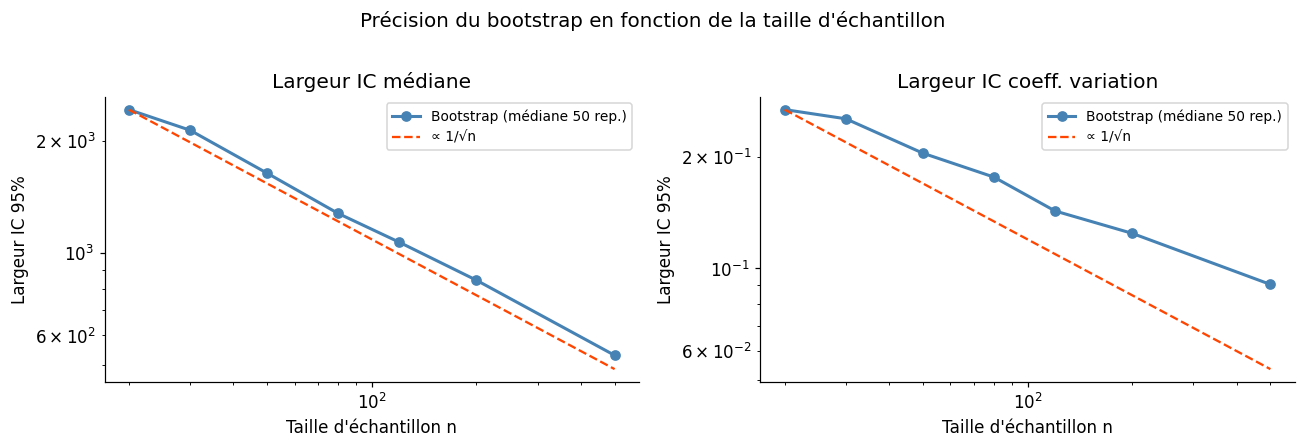
L’erreur d’estimation (écart-type de \(\hat{\mu}_N\)) décroît en \(1/\sqrt{N}\) — indépendamment de la dimension du problème.
Estimation de π#
L’exemple classique : on tire des points uniformément dans \([-1,1]^2\). La proportion de points dans le disque de rayon 1 converge vers \(\pi/4\).
Intégration par Monte Carlo#
Pour estimer \(I = \int_a^b f(x)\,dx\), on peut écrire \(I = (b-a)\,\mathbb{E}[f(U)]\) où \(U \sim \mathcal{U}(a,b)\) et estimer par la moyenne empirique.
Tests de permutation#
Principe#
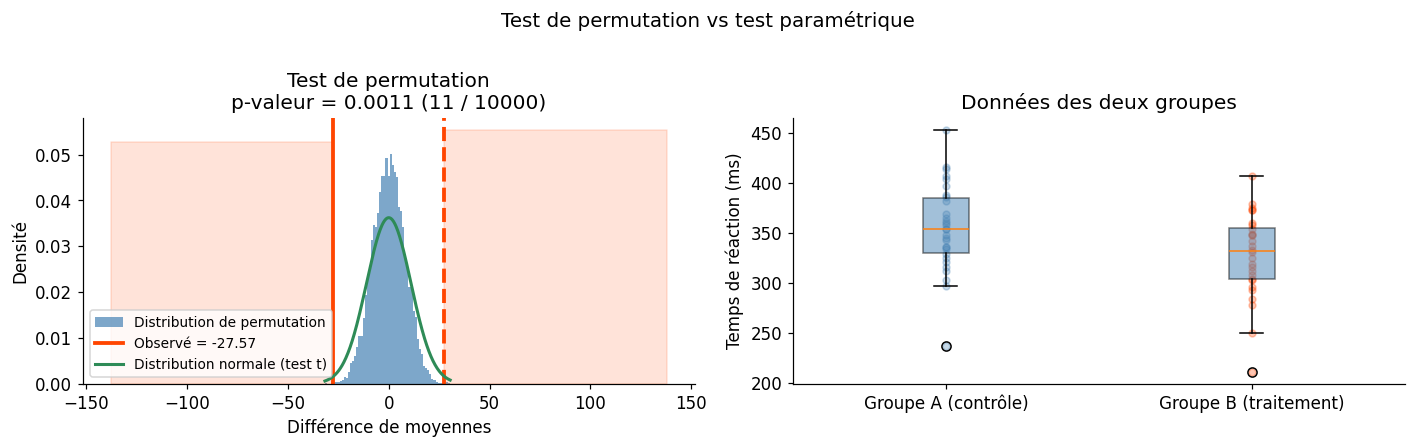
Un test de permutation est une alternative non paramétrique aux tests classiques. L’idée : sous H₀ (les deux groupes sont échangeables), toutes les permutations des labels sont également probables. La p-valeur est la proportion de permutations qui donnent une statistique aussi ou plus extrême que celle observée.
Avantages :
Ne suppose aucune distribution particulière
Valide à taille d’échantillon finie (exactitude)
Fonctionne pour n’importe quelle statistique (même sans distribution analytique connue)
Inconvénient : coûteux pour \(n\) grand (mais on peut approcher par un sous-ensemble aléatoire de permutations).
Comparaison des méthodes de test
Différence observée (B - A) : -27.57 ms
Méthode | Statistique | p-valeur
-------------------------------------------------------
Test de permutation | |Δ| observé | 0.0011
Test t de Student | 2.457 | 0.0171
Mann-Whitney | 567 | 0.0226
Bootstrap#
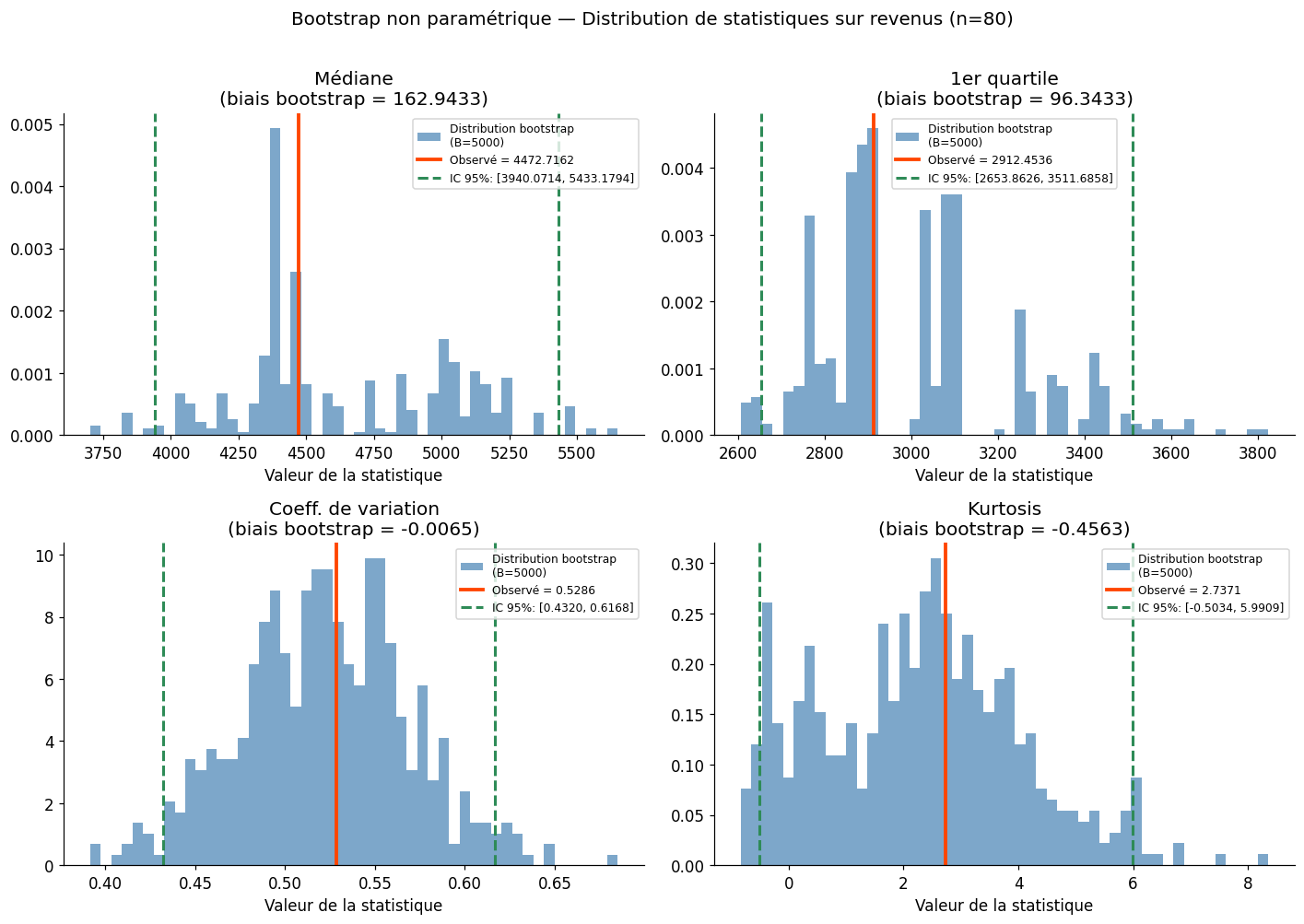
Bootstrap non paramétrique#
Le bootstrap de Efron (1979) est une méthode de rééchantillonnage pour estimer la distribution d’une statistique quelconque. L’idée : l’échantillon observé est la meilleure approximation de la population. On peut donc simuler ce qui se passerait si on rééchantillonnait la population en tirant des échantillons avec remise de l’échantillon observé.
Algorithme :
Calculer la statistique \(\hat{\theta}\) sur l’échantillon original
Pour \(b = 1, \ldots, B\) : tirer un échantillon bootstrap \(X^{*b}\) de taille \(n\) avec remise depuis \(X\)
Calculer \(\hat{\theta}^{*b}\) sur chaque échantillon bootstrap
Utiliser la distribution de \(\{\hat{\theta}^{*b}\}\) pour estimer biais, variance, et intervalles de confiance
Intervalle de confiance percentile : $\(\text{IC}_{1-\alpha} = \left[\hat{\theta}^{*(\alpha/2 \cdot B)}, \hat{\theta}^{*(1-\alpha/2 \cdot B)}\right]\)$
Intervalle BCa (Bias-Corrected and accelerated) : corrige le biais et l’accélération de la distribution bootstrap — méthode recommandée.
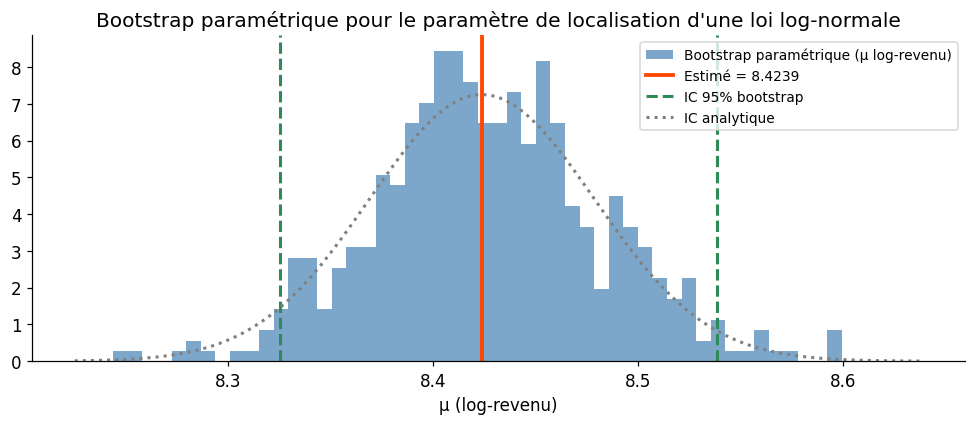
Bootstrap paramétrique#
Le bootstrap paramétrique suppose un modèle paramétrique ajusté aux données. Les échantillons bootstrap sont générés depuis ce modèle ajusté, et non par rééchantillonnage direct.
Bootstrap paramétrique vs IC analytique (loi log-normale)
μ_chapeau = 8.4239, σ_chapeau = 0.4922
IC 95% bootstrap paramétrique : [8.3252, 8.5389]
IC 95% analytique (normale) : [8.3161, 8.5318]
Erreur bootstrap vs taille d’échantillon#
Jackknife#
Le jackknife de Quenouille (1949) est une autre méthode de rééchantillonnage, plus ancienne que le bootstrap. Chaque échantillon jackknife omet un individu : \(X_{(-i)} = (X_1, \ldots, X_{i-1}, X_{i+1}, \ldots, X_n)\).
Estimation du biais : $\(\widehat{\text{biais}} = (n-1)(\bar{\theta}_{(-\cdot)} - \hat{\theta})\)$
Estimation de la variance : $\(\widehat{\text{Var}}(\hat{\theta}) = \frac{n-1}{n}\sum_{i=1}^n (\hat{\theta}_{(-i)} - \bar{\theta}_{(-\cdot)})^2\)$
Le jackknife est plus conservateur que le bootstrap (il tend à sous-estimer la variance pour des statistiques non lisses comme la médiane). Il reste utile pour l’estimation du biais.
def jackknife(data, statistic):
"""Estimation jackknife du biais et de la variance."""
n = len(data)
stat_obs = statistic(data)
jack_stats = np.array([
statistic(np.delete(data, i)) for i in range(n)
])
mean_jack = jack_stats.mean()
biais_jack = (n-1) * (mean_jack - stat_obs)
var_jack = (n-1)/n * np.sum((jack_stats - mean_jack)**2)
return stat_obs, jack_stats, biais_jack, np.sqrt(var_jack)
# Comparaison bootstrap vs jackknife pour plusieurs statistiques
n_data = 50
data_test = rng.exponential(scale=2.0, size=n_data)
print(f"Comparaison Bootstrap vs Jackknife (n={n_data}, loi exponentielle)\n")
print(f"{'Statistique':>20} | {'Observé':>10} | {'Biais Jack.':>12} | {'SE Jack.':>10} | {'SE Boot.':>10}")
print("-" * 72)
for nom, func in [('Moyenne', np.mean), ('Médiane', np.median),
('Écart-type', np.std), ('Skewness', stats.skew)]:
stat_obs, _, biais_j, se_j = jackknife(data_test, func)
_, boot_stats, _, _, _ = bootstrap(data_test, func, n_boot=500)
se_b = boot_stats.std()
print(f"{nom:>20} | {stat_obs:>10.4f} | {biais_j:>+12.5f} | {se_j:>10.5f} | {se_b:>10.5f}")
Comparaison Bootstrap vs Jackknife (n=50, loi exponentielle)
Statistique | Observé | Biais Jack. | SE Jack. | SE Boot.
------------------------------------------------------------------------
Moyenne | 2.3522 | +0.00000 | 0.28805 | 0.27426
Médiane | 1.9723 | -0.00000 | 0.74851 | 0.38221
Écart-type | 2.0163 | -0.03726 | 0.25936 | 0.23917
Skewness | 1.0850 | -0.11739 | 0.40985 | 0.32628
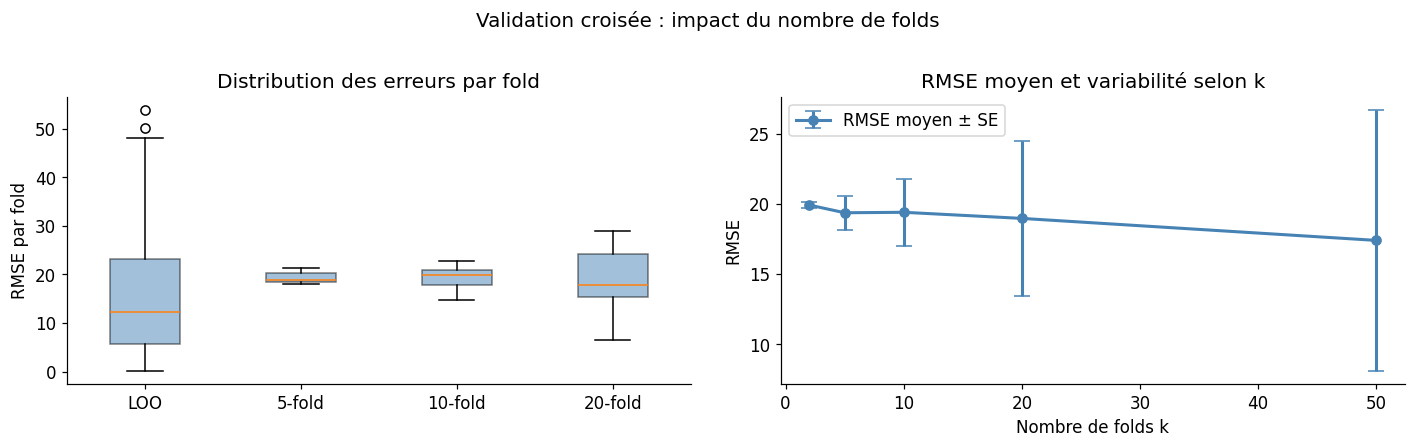
Validation croisée statistique#
La validation croisée évalue la capacité de généralisation d’un modèle statistique en estimant son erreur sur des données non utilisées pour l’ajustement.
Stratégies#
Leave-One-Out (LOO) : chaque observation est laissée de côté une fois. Peu biaisé mais très variable (et coûteux pour \(n\) grand).
k-fold : partition aléatoire en \(k\) groupes ; on entraîne sur \(k-1\) groupes et évalue sur le groupe restant. \(k = 5\) ou \(k = 10\) offrent le meilleur compromis biais-variance.
Stratifiée : la partition respecte la proportion des classes (recommandée pour la classification).
Validation croisée — Régression linéaire (n=100, p=5)
Stratégie | RMSE moyen | SE | N folds
--------------------------------------------------
LOO | 15.4868 | 12.3368 | 100
5-fold | 19.3773 | 1.2249 | 5
10-fold | 19.4105 | 2.3846 | 10
20-fold | 18.9748 | 5.5047 | 20
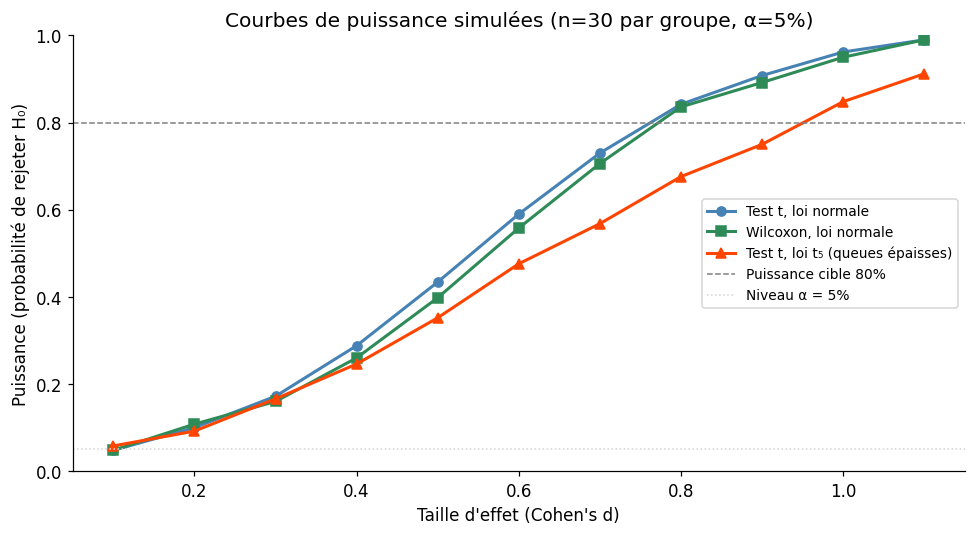
Simulation de puissance#
Calculer la puissance d’un test complexe par simulation est souvent plus simple et plus flexible que les formules analytiques.
Simulation de puissance (n=30 par groupe, α=5%, 2000 simulations)
Cohen's d | t (norm.) | Wilcoxon | t (t₅)
------------------------------------------------
0.1 | 0.048 | 0.048 | 0.058
0.2 | 0.100 | 0.108 | 0.092
0.3 | 0.172 | 0.160 | 0.166
0.4 | 0.288 | 0.260 | 0.246
0.5 | 0.434 | 0.398 | 0.352
0.6 | 0.590 | 0.558 | 0.476
0.7 | 0.730 | 0.706 | 0.568
0.8 | 0.842 | 0.836 | 0.676
0.9 | 0.908 | 0.892 | 0.750
1.0 | 0.962 | 0.950 | 0.848
1.1 | 0.990 | 0.990 | 0.912
Nombres pseudo-aléatoires et reproductibilité#
Générateurs modernes#
Python utilise par défaut le Mersenne Twister (MT19937) — une période de \(2^{19937}-1\), adapté à la plupart des simulations. NumPy recommande depuis la version 1.17 le PCG64 (Permuted Congruential Generator), plus rapide et avec de meilleures propriétés statistiques.
rng = np.random.default_rng(seed=42) # PCG64, recommandé
# Ne pas utiliser : np.random.seed(42) # MT19937, interface legacy
Reproductibilité#
Pour garantir la reproductibilité d’une simulation :
Fixer le seed au début de la simulation
Documenter le seed dans le rapport / notebook
Ne pas réutiliser le même générateur global dans des fonctions appelées en parallèle
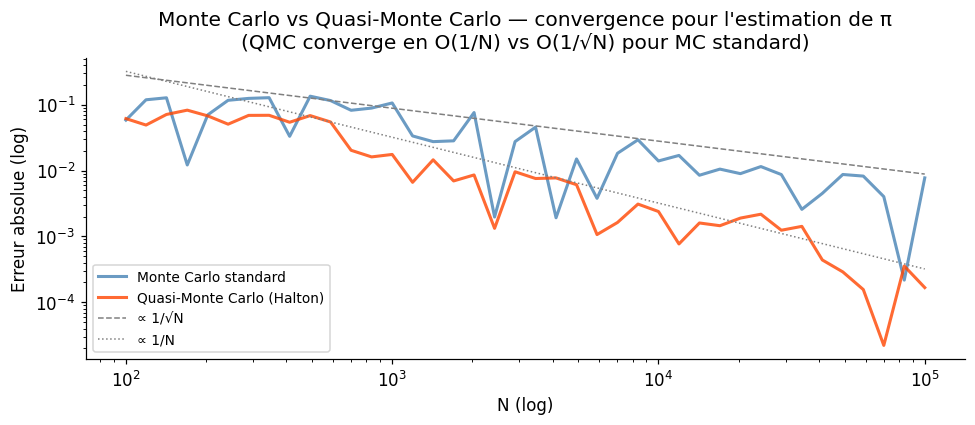
Note
Le Quasi-Monte Carlo utilise des séquences à faible discrépance (Halton, Sobol, Latin Hypercube) qui remplissent l’espace de façon plus uniforme que les nombres pseudo-aléatoires, d’où une convergence théorique en \(O((\log N)^d / N)\) au lieu de \(O(1/\sqrt{N})\). En pratique, le gain est substantiel en faible dimension (\(d \leq 10\)).
Résumé des méthodes computationnelles#
Méthode |
Objectif principal |
Hypothèses |
Complexité |
|---|---|---|---|
Monte Carlo |
Estimer E[f(X)], intégrer |
Aucune |
O(N) |
Test de permutation |
Tester H₀ : groupes échangeables |
Échangeabilité |
O(n × B) |
Bootstrap non-param. |
IC, biais, variance de tout estimateur |
n suffisant, i.i.d. |
O(n × B) |
Bootstrap paramétrique |
IC sous modèle paramétrique |
Modèle correctement spécifié |
O(n × B) |
Jackknife |
Biais, variance (lissé) |
Statistique lisse |
O(n²) |
Validation croisée |
Erreur de généralisation |
i.i.d. |
O(k × coût_modèle) |
Simulation de puissance |
Puissance de tests complexes |
Modèle de simulation valide |
O(nsim × n) |