Déploiement de modèles#
De l’expérimentation à la production#
Un modèle qui reste enfermé dans un notebook n’a aucune valeur opérationnelle. Le déploiement est la discipline qui consiste à rendre un modèle entraîné accessible et utilisable par d’autres systèmes, d’autres utilisateurs ou d’autres services. C’est une étape souvent sous-estimée lors de la formation des data scientists : elle demande des compétences qui débordent du périmètre habituel du machine learning — architecture logicielle, gestion des dépendances, sécurité, performances, surveillance en production.
Le chemin entre un modèle modele.pkl et un service en production fiable passe par plusieurs décisions : quel format d’export garantit la portabilité ? Quelle interface — API REST, interface graphique, batch — correspond au cas d’usage ? Comment gérer la performance en inférence lorsque le trafic augmente ? Comment conteneuriser l’application pour que son déploiement soit reproductible ? Ce chapitre répond à chacune de ces questions.
Inférence et latence
L”inférence (inference) désigne l’application d’un modèle entraîné à de nouvelles données pour produire des prédictions. Contrairement à l’entraînement, l’inférence ne calcule pas de gradients. La latence est le temps écoulé entre la réception d’une requête et l’envoi de la réponse ; le débit (throughput) est le nombre de requêtes traitées par unité de temps. Ces deux métriques sont souvent en tension : augmenter la taille des batches améliore le débit mais dégrade la latence pour chaque requête individuelle.
FastAPI : servir un modèle comme API REST#
FastAPI est le framework Python le plus populaire pour la création d’APIs REST performantes. Il est basé sur Starlette (serveur ASGI asynchrone) et Pydantic (validation de données), et génère automatiquement une documentation interactive (Swagger UI / ReDoc). Sa syntaxe déclarative et son typage fort s’accordent naturellement avec les pipelines ML où les entrées et sorties ont des schémas bien définis.
API REST et endpoint
Une API REST (Representational State Transfer) expose des ressources via des URLs et des verbes HTTP (GET, POST, PUT, DELETE). En inférence ML, l’endpoint de prédiction est presque toujours un POST : le client envoie les données d’entrée dans le corps de la requête (JSON), le serveur retourne la prédiction. Un endpoint est une URL associée à une fonction de traitement — dans FastAPI, un décorateur sur une fonction Python suffit à définir un endpoint.
# api.py
import torch
import torch.nn as nn
import numpy as np
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
from typing import List
import time
# ── Définition de l'architecture (doit correspondre au modèle sauvegardé) ──
class ClassifieurMLP(nn.Module):
def __init__(self, n_entrées: int, n_classes: int):
super().__init__()
self.réseau = nn.Sequential(
nn.Linear(n_entrées, 256), nn.ReLU(), nn.Dropout(0.2),
nn.Linear(256, 64), nn.ReLU(),
nn.Linear(64, n_classes),
)
def forward(self, x):
return self.réseau(x)
# ── Chargement du modèle au démarrage (une seule fois) ────────────────────
app = FastAPI(title="Inférence ML", version="1.0.0",
description="API de prédiction basée sur un MLP PyTorch")
modèle: ClassifieurMLP = None
classes = ["Classe A", "Classe B", "Classe C"]
@app.on_event("startup")
def charger_modèle():
global modèle
modèle = ClassifieurMLP(n_entrées=20, n_classes=3)
modèle.load_state_dict(torch.load("modèle.pt", map_location="cpu"))
modèle.eval()
print("Modèle chargé en mémoire.")
# ── Schémas de données Pydantic ────────────────────────────────────────────
class RequêtePrédiction(BaseModel):
features: List[float] = Field(..., min_items=20, max_items=20,
description="Vecteur de 20 caractéristiques")
class RéponsePrédiction(BaseModel):
classe_prédite: str
probabilités: dict
latence_ms: float
class RequêteBatch(BaseModel):
items: List[RequêtePrédiction] = Field(..., max_items=512)
# ── Endpoints ──────────────────────────────────────────────────────────────
@app.get("/santé")
def santé():
"""Endpoint de vérification de l'état du service."""
return {"statut": "ok", "modèle_chargé": modèle is not None}
@app.post("/prédire", response_model=RéponsePrédiction)
def prédire(requête: RequêtePrédiction):
"""Prédit la classe d'un seul exemple."""
if modèle is None:
raise HTTPException(status_code=503, detail="Modèle non disponible")
t0 = time.perf_counter()
x = torch.tensor([requête.features], dtype=torch.float32)
with torch.no_grad():
logits = modèle(x)
probas = torch.softmax(logits, dim=1).squeeze().tolist()
latence = (time.perf_counter() - t0) * 1000
return RéponsePrédiction(
classe_prédite=classes[int(np.argmax(probas))],
probabilités=dict(zip(classes, [round(p, 4) for p in probas])),
latence_ms=round(latence, 2),
)
@app.post("/prédire/batch")
def prédire_batch(requête: RequêteBatch):
"""Prédit la classe de plusieurs exemples en une seule requête."""
if modèle is None:
raise HTTPException(status_code=503, detail="Modèle non disponible")
t0 = time.perf_counter()
x = torch.tensor([item.features for item in requête.items], dtype=torch.float32)
with torch.no_grad():
logits = modèle(x)
probas = torch.softmax(logits, dim=1).numpy()
latence = (time.perf_counter() - t0) * 1000
résultats = [
{"classe_prédite": classes[int(np.argmax(p))],
"probabilités": dict(zip(classes, [round(float(v), 4) for v in p]))}
for p in probas
]
return {"prédictions": résultats, "latence_ms": round(latence, 2),
"n_exemples": len(requête.items)}
# Lancement de l'API avec uvicorn (serveur ASGI)
uvicorn api:app --host 0.0.0.0 --port 8000 --workers 4
# Test rapide avec curl
curl -X POST http://localhost:8000/prédire \
-H "Content-Type: application/json" \
-d '{"features": [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0,
1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0]}'
Note
Dans FastAPI, le modèle est chargé une seule fois au démarrage (@app.on_event("startup")) et conservé en mémoire globale. C’est crucial pour la performance : charger un modèle PyTorch à chaque requête introduirait une latence de plusieurs secondes. Le contexte torch.no_grad() est indispensable en inférence : il désactive le graphe de calcul automatique, réduit la mémoire consommée d’environ 30 % et accélère légèrement le calcul.
ONNX : export pour la portabilité#
ONNX (Open Neural Network Exchange) est un format ouvert de représentation de modèles de deep learning. Il permet d’exporter un modèle entraîné avec PyTorch et de l’exécuter avec ONNX Runtime — un moteur d’inférence hautement optimisé — sans dépendance à PyTorch. C’est particulièrement utile pour déployer des modèles sur des environnements contraints (mobile, embarqué, navigateur web) ou pour réduire la taille de l’environnement de production.
ONNX et ONNX Runtime
ONNX définit un format de graphe de calcul interopérable : les opérations (convolution, matmul, activations…) sont représentées comme des nœuds dans un graphe orienté acyclique avec des types et des formes de tenseurs. ONNX Runtime est la bibliothèque d’inférence qui exécute ce graphe de façon optimisée sur CPU (avec AVX/AVX-512), GPU (via CUDA ou TensorRT) ou accélérateurs spécialisés. La conversion PyTorch → ONNX se fait via la trace (tracing) d’une passe avant sur un exemple fictif.
import torch
import torch.nn as nn
# ── Modèle de démonstration (MLP 20 → 64 → 3) ────────────────────────────
class ClassifieurMLP(nn.Module):
def __init__(self):
super().__init__()
self.réseau = nn.Sequential(
nn.Linear(20, 64), nn.ReLU(),
nn.Linear(64, 3),
)
def forward(self, x):
return self.réseau(x)
modèle = ClassifieurMLP()
import warnings
import torch
import torch.onnx
import onnxruntime as ort
import numpy as np
# ── Export PyTorch → ONNX ─────────────────────────────────────────────────
modèle.eval()
exemple_entrée = torch.randn(1, 20) # batch de taille 1, 20 features
with warnings.catch_warnings():
warnings.simplefilter("ignore")
torch.onnx.export(
modèle,
exemple_entrée,
"modèle.onnx",
export_params=True, # inclure les poids dans le fichier
opset_version=17, # version des opérations ONNX
dynamo=False, # utiliser l'exporteur TorchScript (legacy)
input_names=["features"],
output_names=["logits"],
dynamic_axes={ # autoriser des tailles de batch variables
"features": {0: "batch_size"},
"logits": {0: "batch_size"},
},
)
print("Export ONNX terminé.")
# ── Inférence avec ONNX Runtime ────────────────────────────────────────────
# Utiliser uniquement les fournisseurs disponibles (CPU en environnement sans GPU)
fournisseurs_disponibles = ort.get_available_providers()
session = ort.InferenceSession("modèle.onnx", providers=fournisseurs_disponibles)
# Requête d'inférence : NumPy, pas PyTorch
x_np = np.random.randn(8, 20).astype(np.float32) # batch de 8 exemples
sorties = session.run(["logits"], {"features": x_np})
logits_onnx = sorties[0] # array NumPy (8, 3)
print(f"Sortie ONNX Runtime : {logits_onnx.shape}")
print(f"Fournisseurs actifs : {session.get_providers()}")
# ── Vérification de la cohérence PyTorch ↔ ONNX ───────────────────────────
with torch.no_grad():
logits_torch = modèle(torch.from_numpy(x_np)).numpy()
erreur_max = np.abs(logits_torch - logits_onnx).max()
print(f"Erreur maximale PyTorch ↔ ONNX : {erreur_max:.2e}")
Export ONNX terminé.
Sortie ONNX Runtime : (8, 3)
Fournisseurs actifs : ['AzureExecutionProvider', 'CPUExecutionProvider']
Erreur maximale PyTorch ↔ ONNX : 5.96e-08
Gradio : interfaces de démonstration#
Gradio permet de construire en quelques lignes une interface web interactive pour n’importe quelle fonction Python. C’est l’outil idéal pour créer des démonstrations (demos) partageables — notamment avec la plateforme Hugging Face Spaces — permettant à des non-techniciens d’interagir avec un modèle sans installer quoi que ce soit.
import gradio as gr
import torch
import numpy as np
def prédire_gradio(texte_features: str) -> str:
"""Fonction Python ordinaire que Gradio va envelopper dans une interface."""
try:
valeurs = [float(v.strip()) for v in texte_features.split(",")]
if len(valeurs) != 20:
return "Erreur : fournir exactement 20 valeurs séparées par des virgules."
x = torch.tensor([valeurs], dtype=torch.float32)
with torch.no_grad():
logits = modèle(x)
probas = torch.softmax(logits, dim=1).squeeze().tolist()
classe = classes[int(np.argmax(probas))]
résultat = f"Classe prédite : **{classe}**\n\n"
résultat += "\n".join([f"- {c} : {p:.1%}" for c, p in zip(classes, probas)])
return résultat
except ValueError:
return "Erreur : les valeurs doivent être des nombres séparés par des virgules."
# Interface Gradio
interface = gr.Interface(
fn=prédire_gradio,
inputs=gr.Textbox(
label="Caractéristiques (20 valeurs séparées par des virgules)",
placeholder="0.1, 0.2, 0.3, ...",
lines=2,
),
outputs=gr.Markdown(label="Prédiction"),
title="Démonstration du classifieur MLP",
description="Saisissez 20 valeurs numériques pour obtenir une prédiction.",
examples=[["0.1, " * 19 + "0.1"]],
)
# interface.launch(share=True) # share=True génère un lien public temporaire
Conteneurisation avec Docker#
Docker empaquette une application et toutes ses dépendances dans une image portable et reproductible. Déployer un modèle dans un conteneur Docker garantit que l’environnement d’exécution est identique en développement, en staging et en production, quelle que soit la machine hôte.
Image et conteneur Docker
Une image Docker est un instantané immuable d’un système de fichiers, contenant le système d’exploitation de base, les bibliothèques système, l’interpréteur Python, les dépendances et le code applicatif. Un conteneur est une instance en cours d’exécution d’une image : il est isolé du système hôte, dispose de ses propres ressources réseau et système de fichiers, et peut être démarré, arrêté et supprimé en quelques secondes.
# Dockerfile
# ── Image de base officielle Python slim ─────────────────────────────────
FROM python:3.11-slim
# Répertoire de travail dans le conteneur
WORKDIR /app
# ── Installation des dépendances système ─────────────────────────────────
RUN apt-get update && apt-get install -y --no-install-recommends \
libgomp1 \
&& rm -rf /var/lib/apt/lists/*
# ── Installation des dépendances Python ──────────────────────────────────
# Copier d'abord les fichiers de dépendances (optimise le cache Docker)
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# ── Copie du code applicatif et du modèle ────────────────────────────────
COPY api.py .
COPY modèle.onnx .
# ── Exposition du port et commande de démarrage ───────────────────────────
EXPOSE 8000
CMD ["uvicorn", "api:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "2"]
# Construction de l'image
docker build -t classifieur-api:1.0.0 .
# Lancement d'un conteneur (port 8000 exposé sur le port 8080 de l'hôte)
docker run -d --name classifieur \
-p 8080:8000 \
--memory="512m" \
classifieur-api:1.0.0
# Vérification
curl http://localhost:8080/santé
docker logs classifieur
docker stop classifieur
Pour des déploiements plus complexes nécessitant plusieurs services (API + base de données + cache Redis), Docker Compose orchestre plusieurs conteneurs :
# docker-compose.yml
version: "3.9"
services:
api:
build: .
ports:
- "8080:8000"
environment:
- MODEL_PATH=/app/modèle.onnx
deploy:
resources:
limits:
memory: 1G
restart: unless-stopped
redis:
image: redis:7-alpine
volumes:
- redis_data:/data
volumes:
redis_data:
Considérations de performance en inférence#
La performance en inférence englobe plusieurs dimensions qui doivent être abordées selon le contexte de déploiement.
Quantification. Réduire la précision des poids de float32 (32 bits) à int8 (8 bits) réduit la taille du modèle d’un facteur 4 et accélère l’inférence CPU d’un facteur 2 à 4, avec une dégradation de la précision généralement inférieure à 1 point de pourcentage.
import torch.quantization
# Quantification dynamique (la plus simple) : s'applique aux couches Linear et LSTM
modèle_quantifié = torch.quantization.quantize_dynamic(
modèle,
qconfig_spec={nn.Linear},
dtype=torch.qint8,
)
print(f"Taille originale : {sum(p.numel() * 4 for p in modèle.parameters()) / 1e6:.1f} MB")
print(f"Taille quantifiée : approximativement 1/4 de la taille originale")
Compilation TorchScript. Compiler le modèle avec torch.jit.script ou torch.jit.trace produit un graphe statique exécutable sans l’interpréteur Python, réduisant la latence et permettant le déploiement dans des environnements C++.
# Trace (pour les architectures sans branchements conditionnels)
exemple = torch.randn(1, 20)
modèle_trace = torch.jit.trace(modèle, exemple)
modèle_trace.save("modèle_compilé.pt")
# Script (pour les architectures avec boucles ou conditions)
modèle_script = torch.jit.script(modèle)
# Inférence identique mais sans l'overhead Python
sortie = modèle_script(exemple)
Comparaison des formats d’export selon le cas d’usage
Format |
Cas d’usage |
Avantages |
Inconvénients |
|---|---|---|---|
|
Reprise d’entraînement |
Flexible, natif PyTorch |
Nécessite PyTorch à l’inférence |
TorchScript |
API Python haute perf |
Pas d’overhead Python |
Pas tous les modèles scriptables |
ONNX |
Interopérabilité |
Multi-framework, multi-hardware |
Pas tous les opérateurs supportés |
ONNX + TensorRT |
GPU NVIDIA production |
Performance maximale |
Dépendant du matériel NVIDIA |
CoreML / TFLite |
Mobile / embarqué |
Optimisé pour l’appareil |
Conversion parfois complexe |
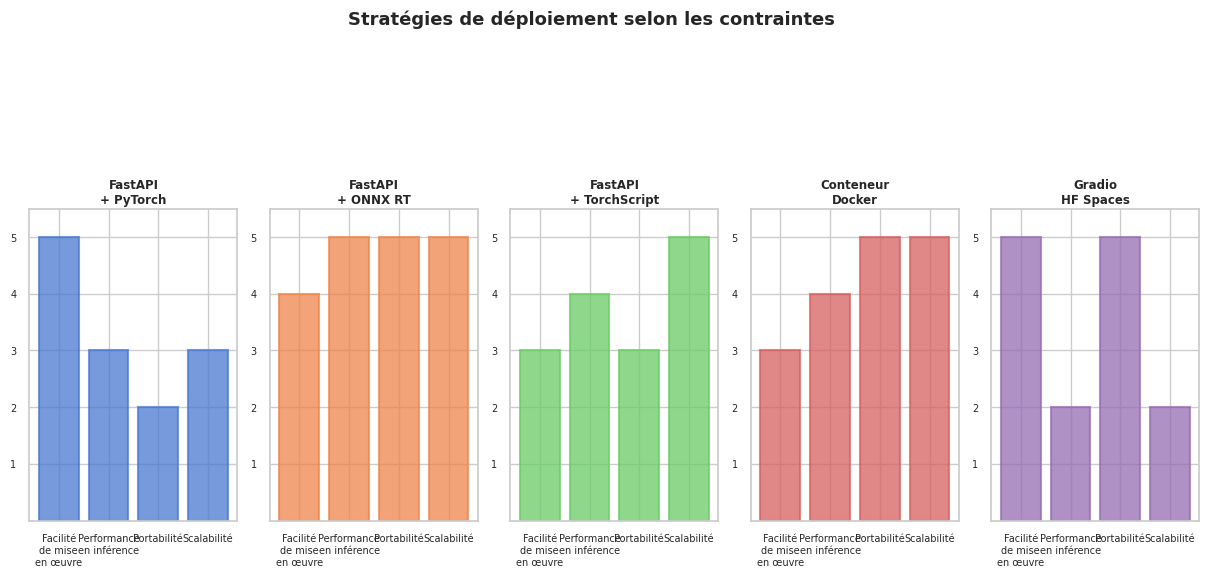
Résumé#
Ce chapitre a couvert les principales techniques et outils pour déployer des modèles ML en production :
FastAPI est le framework de référence pour exposer un modèle comme service REST. Le modèle est chargé une seule fois au démarrage, les schémas Pydantic valident automatiquement les entrées, et
torch.no_grad()optimise l’inférence. La séparation entre endpoint unitaire et endpoint batch permet de s’adapter à différents cas d’usage.ONNX est le format d’interopérabilité universel : il découple le modèle de PyTorch et permet son exécution avec ONNX Runtime, un moteur d’inférence optimisé pour CPU, GPU et accélérateurs spécialisés. La vérification de cohérence entre les sorties PyTorch et ONNX est une étape indispensable après l’export.
Gradio réduit à quelques lignes la création d’une interface web interactive. C’est l’outil idéal pour les démonstrations, la validation par les utilisateurs finaux et le partage via Hugging Face Spaces.
La conteneurisation Docker garantit la reproductibilité du déploiement en empaquetant application, modèle et dépendances dans une image portable. Un Dockerfile bien structuré exploite le cache des couches pour des reconstructions rapides.
Les techniques d’optimisation — quantification int8, TorchScript, ONNX Runtime — réduisent la latence et la consommation mémoire en inférence. Le bon choix dépend du matériel cible (CPU vs GPU NVIDIA), des contraintes de latence et des opérations utilisées par le modèle.
Ce chapitre conclut la partie déploiement du livre. Les thèmes abordés dans les chapitres précédents — entraînement, architectures CNN et RNN, pipelines et orchestration — forment un cycle complet : de la donnée brute au modèle en production, en passant par l’expérimentation reproductible et la mise en service fiable.