Pipelines de données et orchestration#
Du prototype au système reproductible#
Un projet de data science commence presque toujours dans un notebook Jupyter : l’exploration est rapide, les résultats sont visibles immédiatement, et le cycle d’itération est très court. Mais ce mode de travail montre ses limites dès que le projet prend de l’ampleur. Plusieurs semaines après avoir produit un modèle performant, il devient difficile de répondre à des questions pourtant simples : avec quelles données exactement ce modèle a-t-il été entraîné ? Quel prétraitement a été appliqué ? Quels hyperparamètres ont conduit à ce résultat ? Comment relancer l’entraînement si de nouvelles données arrivent ?
Ces questions de reproductibilité et de traçabilité sont au cœur de la discipline émergente du MLOps (Machine Learning Operations). L’orchestration de pipelines, le versioning des données et le suivi des expériences sont les trois piliers qui permettent de passer d’un prototype fragile à un système fiable, auditable et maintenable.
Pipeline ML
Un pipeline ML est une séquence ordonnée d’étapes de traitement automatisées, allant de l’ingestion des données brutes jusqu’à la production d’un modèle évalué. Chaque étape est une unité de calcul avec des entrées et des sorties bien définies, que l’on peut relancer, remplacer ou paralléliser indépendamment. Un pipeline bien conçu est idempotent : le relancer sur les mêmes données produit toujours le même résultat.
Prefect : orchestration de workflows Python#
Prefect est un framework d’orchestration de workflows Python qui permet de transformer des scripts Python ordinaires en pipelines robustes, surveillés et ré-exécutables. Il est particulièrement bien adapté aux workflows ML car il ne nécessite pas de changer radicalement la façon d’écrire le code : les décorateurs @flow et @task annotent les fonctions existantes.
Flow et Task dans Prefect
Dans Prefect, un task (@task) est l’unité atomique de travail : une fonction Python dont l’exécution est surveillée, dont les résultats peuvent être mis en cache, et qui peut être ré-exécutée en cas d’échec. Un flow (@flow) est un graphe de tasks : il orchestre leur exécution, gère les dépendances entre elles, et constitue l’unité de déploiement et de surveillance. Les flows peuvent appeler d’autres flows (subflows), permettant une organisation hiérarchique.
from prefect import flow, task
from prefect.tasks import task_input_hash
from datetime import timedelta
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=24))
def charger_données(chemin: str) -> pd.DataFrame:
"""Charge les données brutes depuis un fichier CSV."""
df = pd.read_csv(chemin)
print(f"Données chargées : {len(df):,} lignes, {df.shape[1]} colonnes")
return df
@task
def nettoyer_données(df: pd.DataFrame) -> pd.DataFrame:
"""Supprime les doublons et impute les valeurs manquantes."""
df = df.drop_duplicates()
df = df.dropna(subset=["cible"]) # cible obligatoire
# Imputation numérique par médiane
colonnes_num = df.select_dtypes("number").columns
df[colonnes_num] = df[colonnes_num].fillna(df[colonnes_num].median())
print(f"Après nettoyage : {len(df):,} lignes")
return df
@task
def préparer_features(df: pd.DataFrame):
"""Sépare features/cible, normalise, et découpe train/val/test."""
X = df.drop(columns=["cible"]).values
y = df["cible"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train,
test_size=0.1, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
X_test = scaler.transform(X_test)
return X_train, X_val, X_test, y_train, y_val, y_test, scaler
@task(retries=2, retry_delay_seconds=10)
def entraîner_modèle(X_train, y_train, X_val, y_val, params: dict):
"""Entraîne le modèle avec les paramètres donnés."""
from sklearn.ensemble import GradientBoostingClassifier
modèle = GradientBoostingClassifier(**params, random_state=42)
modèle.fit(X_train, y_train)
score_val = modèle.score(X_val, y_val)
print(f"Accuracy validation : {score_val:.4f}")
return modèle, score_val
@flow(name="Pipeline ML complet", log_prints=True)
def pipeline_ml(chemin_données: str, params_modèle: dict = None):
"""Flow principal orchestrant toutes les étapes du pipeline."""
if params_modèle is None:
params_modèle = {"n_estimators": 200, "max_depth": 4, "learning_rate": 0.05}
# Les tasks sont exécutées dans l'ordre défini par leurs dépendances de données
df_brut = charger_données(chemin_données)
df_propre = nettoyer_données(df_brut)
données_prep = préparer_features(df_propre)
X_train, X_val, X_test, y_train, y_val, y_test, scaler = données_prep
modèle, score = entraîner_modèle(X_train, y_train, X_val, y_val, params_modèle)
return modèle, score
# Lancement du flow
# if __name__ == "__main__":
# modèle, score = pipeline_ml("données/features.csv")
L’un des avantages majeurs de Prefect est la mise en cache des résultats (cache_key_fn=task_input_hash) : si les données d’entrée d’une task n’ont pas changé depuis la dernière exécution, la task n’est pas relancée et son résultat est récupéré directement depuis le cache. Cela réduit considérablement le temps de développement en évitant de recalculer des étapes coûteuses (téléchargement, transformation) à chaque expérience.
DVC : versioning des données#
Le versioning des données est le problème dual du versioning du code. Git gère parfaitement les fichiers texte et le code source, mais il n’est pas conçu pour stocker des fichiers binaires de grande taille (images, modèles, jeux de données). DVC (Data Version Control) étend Git pour versionner les données : il stocke les gros fichiers dans un dépôt distant (S3, Google Cloud Storage, Azure Blob, un simple serveur SSH) et ne conserve dans Git que de petits fichiers .dvc qui pointent vers le contenu par son hash SHA-256.
DVC
DVC (Data Version Control) est un outil open-source qui étend Git pour le versioning des données, des modèles et des pipelines ML. Il fonctionne en deux couches : les fichiers .dvc (versionnés dans Git) contiennent le hash et la taille des artefacts ; le cache DVC et les remotes (dépôts distants) stockent le contenu réel des artefacts. La commande dvc repro relance uniquement les étapes du pipeline dont les dépendances ont changé, grâce au graphe de dépendances défini dans dvc.yaml.
# Installation et initialisation dans un dépôt Git existant
pip install dvc dvc-s3 # ou dvc-gdrive, dvc-azure, etc.
dvc init
# Configurer le dépôt distant pour le stockage des artefacts
dvc remote add -d stockage s3://mon-bucket/dvc-store
dvc remote modify stockage region eu-west-3
# Ajouter des données au versioning DVC (retirer du .gitignore automatiquement)
dvc add données/raw/features.csv
git add données/raw/features.csv.dvc données/raw/.gitignore
git commit -m "feat: ajout des données brutes v1.0"
dvc push # envoie les données vers S3
# Sur une autre machine ou après un git pull :
dvc pull # télécharge les données correspondant au commit courant
Le fichier dvc.yaml définit un pipeline reproductible dont DVC gère les dépendances :
# dvc.yaml
stages:
préparer:
cmd: python src/préparer.py --entrée données/raw/features.csv
--sortie données/processed/features.parquet
deps:
- src/préparer.py
- données/raw/features.csv
outs:
- données/processed/features.parquet
entraîner:
cmd: python src/entraîner.py
deps:
- src/entraîner.py
- données/processed/features.parquet
- params.yaml
params:
- params.yaml:
- learning_rate
- n_estimators
outs:
- modèles/modele.pkl
metrics:
- métriques/scores.json:
cache: false
évaluer:
cmd: python src/évaluer.py
deps:
- src/évaluer.py
- modèles/modele.pkl
- données/processed/features.parquet
metrics:
- métriques/rapport_final.json:
cache: false
dvc repro # relance uniquement les étapes dont les dépendances ont changé
dvc dag # affiche le graphe de dépendances du pipeline
MLflow : suivi des expériences#
Lorsqu’on entraîne un modèle, on ajuste continuellement les hyperparamètres, les architectures, les prétraitements — et il devient rapidement impossible de se souvenir quelle combinaison a donné quel résultat. MLflow est une plateforme open-source de suivi des expériences ML qui enregistre automatiquement les paramètres, les métriques et les artefacts de chaque run, et offre une interface web pour les comparer.
Run MLflow
Un run MLflow est une instance d’exécution d’un code d’entraînement. Il encapsule : les paramètres (hyperparamètres, chemins de données), les métriques (accuracy, loss, F1 — éventuellement enregistrées au fil des époques), les artefacts (modèle serialisé, graphiques, fichiers de données) et les métadonnées (heure de début, durée, utilisateur, version Git). Les runs sont regroupés en expériences (experiments) qui correspondent à un objectif de modélisation.
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score
# Configuration du serveur de tracking (local ou distant)
mlflow.set_tracking_uri("http://localhost:5000") # ou "mlruns/" pour stockage local
mlflow.set_experiment("Classification_Clients")
def entraîner_avec_tracking(X_train, y_train, X_val, y_val, params: dict):
with mlflow.start_run(run_name=f"RF_n{params['n_estimators']}"):
# Enregistrer les paramètres
mlflow.log_params(params)
mlflow.log_param("taille_train", len(X_train))
mlflow.log_param("taille_val", len(X_val))
# Entraînement
modèle = RandomForestClassifier(**params, random_state=42, n_jobs=-1)
modèle.fit(X_train, y_train)
# Enregistrer les métriques de validation
y_pred = modèle.predict(X_val)
acc = accuracy_score(y_val, y_pred)
f1 = f1_score(y_val, y_pred, average="weighted")
mlflow.log_metric("val_accuracy", acc)
mlflow.log_metric("val_f1", f1)
# Enregistrer le modèle
mlflow.sklearn.log_model(modèle, artifact_path="modèle",
registered_model_name="ClassifieurClients")
print(f"Run terminé — acc={acc:.4f}, f1={f1:.4f}")
return modèle
# Exploration d'hyperparamètres : chaque combinaison crée un run distinct
grille_params = [
{"n_estimators": 100, "max_depth": 5},
{"n_estimators": 200, "max_depth": 5},
{"n_estimators": 200, "max_depth": 10},
{"n_estimators": 300, "max_depth": None},
]
for params in grille_params:
entraîner_avec_tracking(X_train, y_train, X_val, y_val, params)
MLflow propose également MLflow Projects (exécution reproductible de code) et MLflow Models (format d’empaquetage de modèles indépendant du framework). La commande mlflow ui lance l’interface web qui permet de filtrer, trier et comparer graphiquement tous les runs d’une expérience.
Note
Pour les projets PyTorch, mlflow.pytorch.autolog() enregistre automatiquement les hyperparamètres du modèle et les métriques à chaque époque sans aucune instrumentation manuelle. De même, mlflow.sklearn.autolog() est disponible pour les modèles Scikit-learn. Ces fonctions d’auto-logging sont pratiques pour les démarrages rapides, mais l’instrumentation manuelle avec mlflow.log_param() et mlflow.log_metric() offre un contrôle plus fin sur ce qui est enregistré.
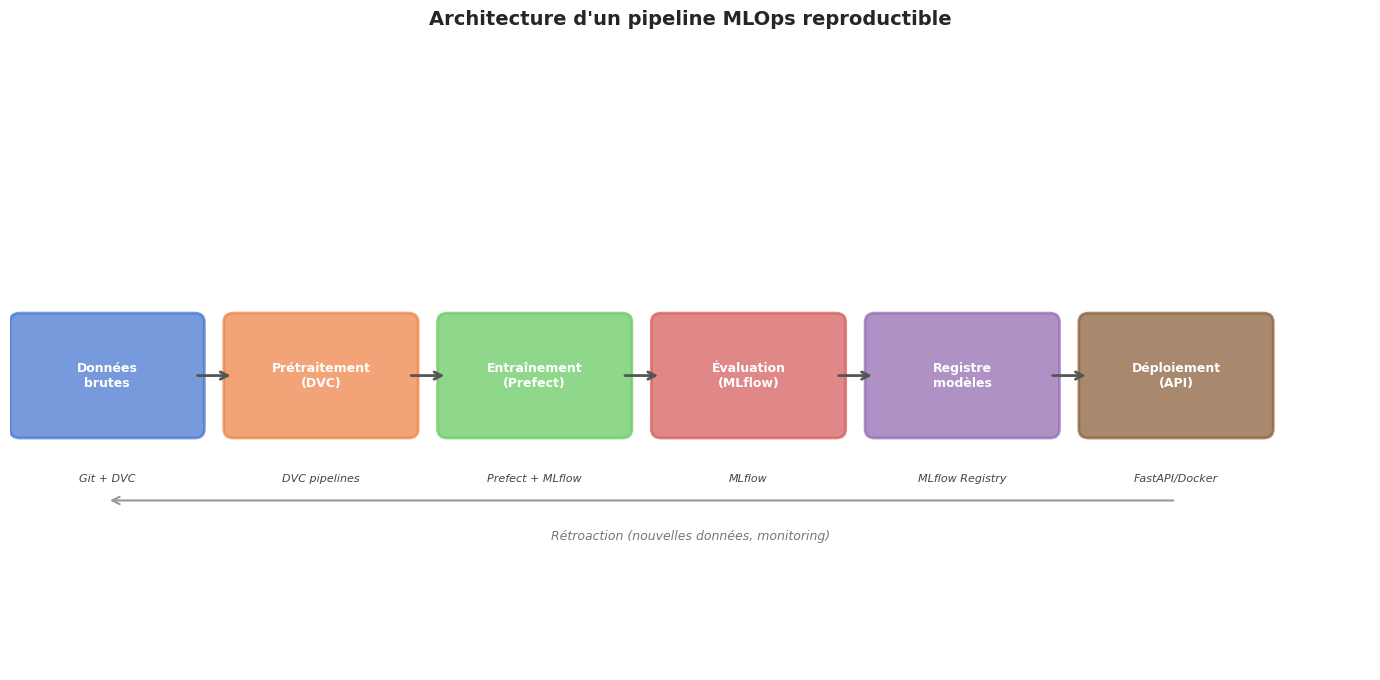
Reproductibilité : bonnes pratiques#
La reproductibilité en ML est un objectif multidimensionnel. Il ne suffit pas de fixer la graine aléatoire — encore faut-il que l’environnement logiciel, les données et le code soient exactement identiques.
Fixer les graines aléatoires. En PyTorch, la reproductibilité complète requiert de fixer plusieurs graines indépendantes :
import random
import os
def fixer_graines(graine: int = 42):
"""Fixe toutes les sources d'aléatoire pour la reproductibilité."""
random.seed(graine)
np.random.seed(graine)
torch.manual_seed(graine)
torch.cuda.manual_seed_all(graine)
# Activer le mode déterministe (peut ralentir l'entraînement)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ["PYTHONHASHSEED"] = str(graine)
Versionner les dépendances. Un fichier requirements.txt avec des versions épinglées (numpy==2.0.1) garantit que l’environnement peut être recréé à l’identique. Avec uv, le fichier uv.lock joue ce rôle. Avec conda, environment.yml avec --export capture toutes les dépendances.
Versionner le code et les données ensemble. Une bonne pratique consiste à enregistrer dans chaque run MLflow le hash Git du commit courant et le hash DVC des données utilisées, créant ainsi un lien traçable entre un modèle, son code source et ses données d’entraînement.
import subprocess
import mlflow
def obtenir_hash_git():
résultat = subprocess.run(["git", "rev-parse", "HEAD"],
capture_output=True, text=True)
return résultat.stdout.strip()
with mlflow.start_run():
mlflow.set_tag("git_commit", obtenir_hash_git())
mlflow.set_tag("dvc_version", "v1.2.0") # tag de version DVC
# ... reste de l'entraînement ...
Résumé#
Ce chapitre a présenté les outils fondamentaux pour construire des pipelines ML reproductibles et maintenables :
Un pipeline ML décompose le processus d’apprentissage en étapes atomiques aux interfaces bien définies, permettant la réexécution partielle, le débogage ciblé et la parallélisation.
Prefect orchestre des workflows Python avec les décorateurs
@flowet@task. La mise en cache des résultats, la gestion des échecs avec retries et la surveillance via l’interface web en font un outil de productivité puissant pour les projets ML.DVC étend Git pour versionner les données et les modèles de grande taille. Le fichier
dvc.yamldéfinit un pipeline reproductible dontdvc reprone relance que les étapes invalidées par des changements de dépendances.MLflow enregistre automatiquement les paramètres, métriques et artefacts de chaque run d’entraînement. Le registre de modèles permet de versionner les modèles en production et de gérer leur cycle de vie (staging, production, archivage).
La reproductibilité requiert de fixer les graines aléatoires, d’épingler les versions des dépendances, et de lier chaque modèle à son code source (hash Git) et à ses données (version DVC).
Le chapitre suivant couvrira le déploiement de modèles : comment exposer un modèle entraîné sous forme d’API, l’exporter vers des formats portables, et le conteneuriser pour la production.