NumPy — tableaux et vectorisation#
Pourquoi NumPy ?#
Avant de comprendre ce que NumPy apporte, il faut comprendre pourquoi les listes Python sont insuffisantes pour le calcul scientifique. Une liste Python est une structure de données extrêmement flexible : elle peut contenir des éléments de types hétérogènes, des objets Python arbitrairement complexes, même d’autres listes. Cette flexibilité a un coût : chaque élément d’une liste est un objet Python avec son propre en-tête en mémoire (type, compteur de références, valeur), et les éléments ne sont pas nécessairement contigus en mémoire. Pour accéder au n-ième élément, Python doit suivre un pointeur — une indirection qui ralentit le calcul et inhibe les optimisations du processeur.
Considérons le calcul de la somme de deux vecteurs de taille 10 millions. Avec des listes Python, il faut une boucle explicite :
# Approche naïve avec des listes Python — très lente
a = list(range(10_000_000))
b = list(range(10_000_000))
c = [a[i] + b[i] for i in range(len(a))]
Chaque itération de cette boucle est interprétée par le runtime Python, avec toutes les vérifications de types et la résolution des méthodes que cela implique. Sur un processeur moderne, cette boucle prend plusieurs secondes.
NumPy résout ce problème avec le tableau homogène (ndarray). Tous les éléments d’un ndarray partagent le même type (entier 32 bits, flottant 64 bits, etc.) et sont stockés de façon contiguë en mémoire, comme un tableau C. Cette organisation permet au processeur de charger efficacement les données dans ses caches et d’exploiter les instructions SIMD (Single Instruction, Multiple Data) qui appliquent une même opération à plusieurs éléments simultanément. Le résultat est un gain de vitesse de 10 à 100 fois par rapport à l’équivalent en listes Python, selon l’opération.
ndarray
Un ndarray (n-dimensional array) est la structure de données fondamentale de NumPy. C’est un tableau multidimensionnel de taille fixe dont tous les éléments partagent le même type numérique. Sa représentation en mémoire est un bloc contigu d’octets, décrit par ses attributs : shape (dimensions), dtype (type des éléments), strides (pas en octets entre deux éléments successifs dans chaque dimension). Cette organisation permet d’effectuer des opérations mathématiques sur des millions d’éléments en appelant du code compilé (C ou Fortran) sans passer par l’interpréteur Python.
import numpy as np
# Comparaison de performance : liste vs ndarray
import time
n = 5_000_000
a_list = list(range(n))
b_list = list(range(n))
a_arr = np.arange(n, dtype=np.float64)
b_arr = np.arange(n, dtype=np.float64)
# Avec des listes Python
t0 = time.perf_counter()
c_list = [a_list[i] + b_list[i] for i in range(n)]
t1 = time.perf_counter()
temps_liste = t1 - t0
# Avec NumPy
t0 = time.perf_counter()
c_arr = a_arr + b_arr
t1 = time.perf_counter()
temps_numpy = t1 - t0
print(f"Liste Python : {temps_liste:.3f} s")
print(f"NumPy : {temps_numpy:.4f} s")
print(f"Accélération : ×{temps_liste / temps_numpy:.0f}")
Liste Python : 0.539 s
NumPy : 0.0492 s
Accélération : ×11
Créer des tableaux#
NumPy offre de nombreuses fonctions pour créer des tableaux. La connaissance de ces constructeurs est la première étape vers une utilisation fluide de la bibliothèque.
# Depuis une liste ou une liste de listes
vecteur = np.array([1, 2, 3, 4, 5])
matrice = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("Vecteur :", vecteur)
print("Matrice :\n", matrice)
print()
# Tableaux initialisés
zeros = np.zeros((3, 4)) # matrice 3×4 de zéros
uns = np.ones((2, 3), dtype=int) # matrice 2×3 de uns entiers
iden = np.eye(4) # matrice identité 4×4
diag = np.diag([1, 2, 3, 4]) # matrice diagonale
print("Zeros :\n", zeros)
print("Identité :\n", iden)
Vecteur : [1 2 3 4 5]
Matrice :
[[1 2 3]
[4 5 6]
[7 8 9]]
Zeros :
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
Identité :
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
# Séquences numériques
arange_int = np.arange(0, 10, 2) # 0, 2, 4, 6, 8
arange_float = np.arange(0.0, 1.0, 0.25) # 0.0, 0.25, 0.5, 0.75
linspace_ex = np.linspace(0, 1, 5) # 5 points équidistants entre 0 et 1
logspace_ex = np.logspace(0, 3, 4) # 1, 10, 100, 1000
print("arange(0, 10, 2) :", arange_int)
print("arange(0.0, 1.0, 0.25) :", arange_float)
print("linspace(0, 1, 5) :", linspace_ex)
print("logspace(0, 3, 4) :", logspace_ex)
arange(0, 10, 2) : [0 2 4 6 8]
arange(0.0, 1.0, 0.25) : [0. 0.25 0.5 0.75]
linspace(0, 1, 5) : [0. 0.25 0.5 0.75 1. ]
logspace(0, 3, 4) : [ 1. 10. 100. 1000.]
# Tableaux aléatoires
rng = np.random.default_rng(seed=42) # générateur reproductible
uniforme = rng.random((3, 3)) # U[0, 1)
normale = rng.standard_normal((3, 3)) # N(0, 1)
entiers = rng.integers(0, 10, size=(2, 5)) # entiers entre 0 et 9
choix = rng.choice([10, 20, 30, 40], size=6) # tirage avec remise
print("Normale :\n", np.round(normale, 3))
print("Entiers aléatoires :\n", entiers)
Normale :
[[-0.853 0.879 0.778]
[ 0.066 1.127 0.468]
[-0.859 0.369 -0.959]]
Entiers aléatoires :
[[8 8 2 6 1]
[7 7 3 0 9]]
Note
Depuis NumPy 1.17, la bonne pratique est d’utiliser np.random.default_rng(seed) plutôt que np.random.seed(). Le nouvel objet Generator offre de meilleures propriétés statistiques et est thread-safe. Il expose les mêmes distributions (random, standard_normal, integers, choice, etc.) mais comme méthodes d’instance plutôt que fonctions globales.
Attributs fondamentaux#
Tout ndarray expose un ensemble d’attributs qui décrivent sa structure. Les connaître permet de diagnostiquer rapidement un problème de forme ou de type.
a = np.random.default_rng(0).standard_normal((4, 3, 2))
print(f"shape : {a.shape}") # (4, 3, 2) — dimensions
print(f"dtype : {a.dtype}") # float64 — type des éléments
print(f"ndim : {a.ndim}") # 3 — nombre de dimensions
print(f"size : {a.size}") # 24 — nombre total d'éléments
print(f"itemsize : {a.itemsize}") # 8 — octets par élément
print(f"nbytes : {a.nbytes}") # 192 — octets au total
print(f"strides : {a.strides}") # (48, 16, 8) — pas en octets
shape : (4, 3, 2)
dtype : float64
ndim : 3
size : 24
itemsize : 8
nbytes : 192
strides : (48, 16, 8)
L’attribut strides mérite une attention particulière : il indique le nombre d’octets à « enjamber » en mémoire pour passer d’un élément au suivant dans chaque dimension. Pour un tableau (4, 3, 2) de float64 (8 octets), se déplacer d’un indice dans la dernière dimension coûte 8 octets, dans la dimension du milieu 16 octets (= 2 × 8), dans la première dimension 48 octets (= 3 × 2 × 8). Cette mécanique est la base du mécanisme de vues que nous reverrons dans le chapitre suivant.
dtype
Le dtype (data type) décrit le type et la taille en octets de chaque élément d’un ndarray. Les types les plus courants sont float64 (flottant 64 bits, défaut pour les flottants), float32 (32 bits, utilisé en deep learning pour économiser la mémoire GPU), int64 (entier signé 64 bits), int32, bool et complex128. Le choix du dtype influe sur la précision des calculs, l’occupation mémoire et la compatibilité avec les bibliothèques GPU.
Indexation et slicing#
L’accès aux éléments d’un ndarray reprend la syntaxe des listes Python, généralisée à plusieurs dimensions, et s’enrichit de deux mécanismes propres à NumPy : l”indexation booléenne et le fancy indexing.
a = np.arange(12).reshape(3, 4)
print("Tableau a :\n", a)
print()
# Indexation simple
print("a[1, 2] =", a[1, 2]) # scalaire
print("a[0] =", a[0]) # première ligne (vecteur)
print("a[:, 1] =", a[:, 1]) # deuxième colonne
print()
# Slicing
print("a[0:2, 1:3] =\n", a[0:2, 1:3]) # sous-matrice 2×2
print("a[::2, ::2] =\n", a[::2, ::2]) # une ligne sur deux, une colonne sur deux
Tableau a :
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
a[1, 2] = 6
a[0] = [0 1 2 3]
a[:, 1] = [1 5 9]
a[0:2, 1:3] =
[[1 2]
[5 6]]
a[::2, ::2] =
[[ 0 2]
[ 8 10]]
# Indexation booléenne — sélectionner des éléments selon une condition
a = np.array([3, -1, 7, -4, 2, -9, 5])
masque = a > 0
print("Masque booléen :", masque)
print("Éléments positifs :", a[masque])
print()
# On peut aussi écrire directement :
print("a[a > 3] :", a[a > 3])
# Modifier des éléments selon une condition
b = a.copy()
b[b < 0] = 0 # remplacer les valeurs négatives par 0
print("Après rectification :", b)
Masque booléen : [ True False True False True False True]
Éléments positifs : [3 7 2 5]
a[a > 3] : [7 5]
Après rectification : [3 0 7 0 2 0 5]
# Fancy indexing — indexation par tableau d'indices
a = np.array([10, 20, 30, 40, 50, 60])
indices = np.array([0, 2, 4])
print("Fancy indexing :", a[indices]) # [10, 30, 50]
# Sur une matrice : sélectionner des lignes spécifiques
M = np.arange(20).reshape(4, 5)
print("M :\n", M)
print("Lignes 0 et 3 :\n", M[[0, 3]])
print("Élément (0,1) et (2,4) :", M[[0, 2], [1, 4]])
Fancy indexing : [10 30 50]
M :
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
Lignes 0 et 3 :
[[ 0 1 2 3 4]
[15 16 17 18 19]]
Élément (0,1) et (2,4) : [ 1 14]
Note
Contrairement au slicing (qui retourne une vue du tableau original, partageant la même mémoire), le fancy indexing et l’indexation booléenne retournent toujours une copie. Modifier le résultat d’un fancy indexing ne modifie donc pas le tableau source. Cette distinction est cruciale pour éviter des bugs silencieux et pour comprendre l’impact mémoire des opérations.
Opérations vectorisées#
La vectorisation est le principe central de NumPy : plutôt qu’écrire une boucle Python pour appliquer une opération élément par élément, on exprime l’opération directement sur le tableau entier. NumPy délègue alors l’exécution à du code compilé, rapide et optimisé.
a = np.array([1.0, 2.0, 3.0, 4.0])
b = np.array([10.0, 20.0, 30.0, 40.0])
# Arithmétique élément par élément
print("a + b :", a + b)
print("a * b :", a * b)
print("a ** 2 :", a ** 2)
print("b / a :", b / a)
a + b : [11. 22. 33. 44.]
a * b : [ 10. 40. 90. 160.]
a ** 2 : [ 1. 4. 9. 16.]
b / a : [10. 10. 10. 10.]
# Fonctions universelles (ufunc)
x = np.linspace(0, np.pi, 5)
print("sin(x) :", np.round(np.sin(x), 4))
print("cos(x) :", np.round(np.cos(x), 4))
print("exp(x) :", np.round(np.exp(x), 4))
print("log(x + 1) :", np.round(np.log(x + 1), 4))
print("sqrt(x) :", np.round(np.sqrt(x), 4))
sin(x) : [0. 0.7071 1. 0.7071 0. ]
cos(x) : [ 1. 0.7071 0. -0.7071 -1. ]
exp(x) : [ 1. 2.1933 4.8105 10.5507 23.1407]
log(x + 1) : [0. 0.5796 0.9442 1.2108 1.4211]
sqrt(x) : [0. 0.8862 1.2533 1.535 1.7725]
Fonction universelle (ufunc)
Une fonction universelle (universal function, ou ufunc) est une fonction NumPy qui opère élément par élément sur des ndarray, avec prise en charge automatique du broadcasting et des différents dtype. NumPy fournit plus de soixante ufuncs mathématiques (np.sin, np.cos, np.exp, np.log, np.sqrt, np.abs, etc.) ainsi que des ufuncs logiques et de comparaison. Il est également possible de créer des ufuncs personnalisées avec np.frompyfunc ou Numba.
L’avantage de la vectorisation dépasse la simple performance : le code devient plus lisible et plus proche de la notation mathématique. Écrire y = np.sin(x) + 0.5 * np.cos(2 * x) est bien plus clair qu’une boucle équivalente, et le lecteur comprend immédiatement qu’il s’agit d’une opération appliquée à un vecteur entier.
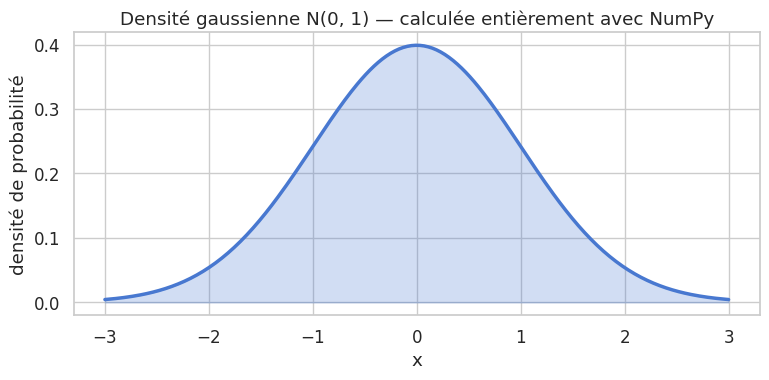
# Exemple : calcul d'une gaussienne sans boucle
x = np.linspace(-3, 3, 300)
mu, sigma = 0.0, 1.0
gaussienne = (1 / (sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)
fig, ax = plt.subplots(figsize=(8, 4))
ax.plot(x, gaussienne, lw=2.5, color=sns.color_palette("muted")[0])
ax.fill_between(x, gaussienne, alpha=0.25, color=sns.color_palette("muted")[0])
ax.set_xlabel("x")
ax.set_ylabel("densité de probabilité")
ax.set_title("Densité gaussienne N(0, 1) — calculée entièrement avec NumPy")
plt.tight_layout()
plt.show()
Broadcasting#
Le broadcasting est le mécanisme par lequel NumPy effectue des opérations arithmétiques entre tableaux de formes différentes. Plutôt que d’exiger que les deux opérandes aient exactement la même forme, NumPy étend conceptuellement les tableaux de dimension inférieure selon des règles précises.
Règles de broadcasting
Deux tableaux sont compatibles pour le broadcasting si, pour chaque dimension (en alignant les formes à droite), soit les tailles sont égales, soit l’une d’elles vaut 1. La dimension de taille 1 est alors « étirée » pour correspondre à l’autre. Si un tableau a moins de dimensions, sa forme est complétée à gauche par des 1 autant que nécessaire. Aucune copie des données n’est effectuée : l’extension est virtuelle.
# Broadcasting simple : scalaire + tableau
a = np.array([1, 2, 3, 4])
print("a + 10 :", a + 10) # 10 est étendu à [10, 10, 10, 10]
print()
# Broadcasting 2D : soustraire la moyenne de chaque colonne
M = np.array([[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0]])
means = M.mean(axis=0) # forme (3,) — moyenne de chaque colonne
print("Moyennes des colonnes :", means)
print("M - means :\n", M - means) # (3,3) - (3,) → broadcasting sur les lignes
a + 10 : [11 12 13 14]
Moyennes des colonnes : [4. 5. 6.]
M - means :
[[-3. -3. -3.]
[ 0. 0. 0.]
[ 3. 3. 3.]]
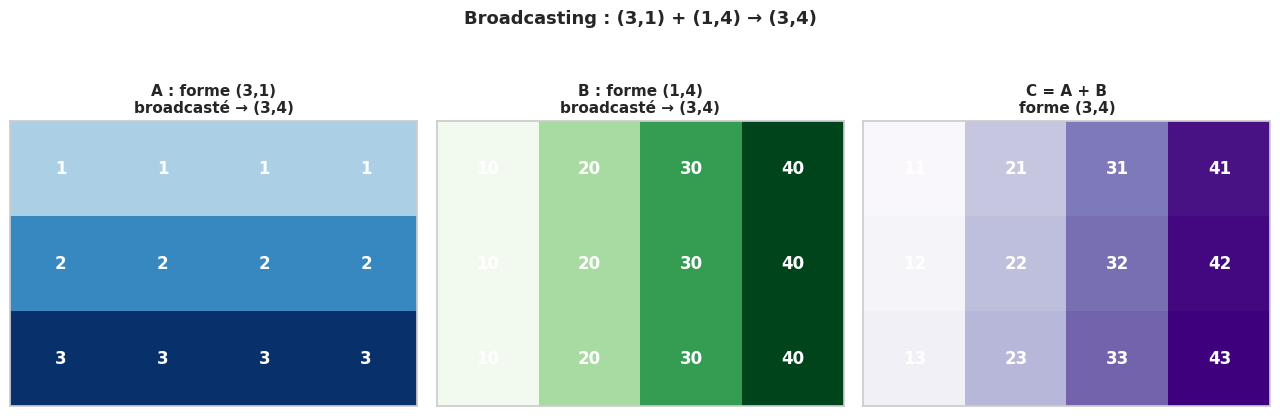
# Broadcasting (3,1) × (1,4) → (3,4)
lignes = np.array([[1], [2], [3]]) # forme (3, 1)
colonnes = np.array([[10, 20, 30, 40]]) # forme (1, 4)
produit = lignes * colonnes # forme (3, 4) par broadcasting
print("lignes :\n", lignes)
print("colonnes :", colonnes)
print("produit (3,1) × (1,4) → (3,4) :\n", produit)
lignes :
[[1]
[2]
[3]]
colonnes : [[10 20 30 40]]
produit (3,1) × (1,4) → (3,4) :
[[ 10 20 30 40]
[ 20 40 60 80]
[ 30 60 90 120]]
Erreurs courantes de broadcasting
Le broadcasting échoue dès qu’une dimension n’est ni égale à l’autre ni égale à 1. Par exemple, tenter d’additionner un tableau de forme (3, 4) avec un tableau de forme (3,) génère une erreur, car en alignant à droite on obtient (3, 4) et (3,) → la dimension 4 ne correspond pas à 3. La solution est de redimensionner explicitement : b.reshape(3, 1) transforme (3,) en (3, 1), compatible avec (3, 4). En cas de doute, afficher les formes avec print(a.shape, b.shape) avant l’opération est toujours une bonne idée.
Résumé#
Ce chapitre a introduit les fondements de NumPy, la bibliothèque sur laquelle repose toute la stack data science Python :
Les listes Python sont trop lentes pour le calcul scientifique car elles stockent des objets hétérogènes non contigus en mémoire. Le
ndarrayNumPy, homogène et contigu, permet d’exploiter les instructions SIMD du processeur et d’atteindre des performances 10 à 100 fois supérieures.Créer des tableaux se fait avec
np.array,np.zeros,np.ones,np.eye,np.arange,np.linspaceetnp.random.default_rng(). Préférer toujours le générateurdefault_rngaux fonctions globales dépréciées.Les attributs fondamentaux —
shape,dtype,ndim,size,itemsize,strides— décrivent complètement la structure d’un tableau et doivent être les premiers réflexes lors du débogage.L’indexation reprend la syntaxe Python (slices, indices négatifs) généralisée à plusieurs dimensions, et s’enrichit de l’indexation booléenne et du fancy indexing. Le slicing retourne une vue (pas de copie) ; le fancy indexing retourne une copie.
Les opérations vectorisées et les ufuncs permettent d’écrire du code expressif et performant sans boucles Python explicites.
Le broadcasting étend automatiquement les tableaux de dimensions insuffisantes selon des règles précises, permettant des opérations entre tableaux de formes compatibles sans copier les données.
Dans le chapitre suivant, nous approfondirons NumPy en explorant la manipulation des formes, l’algèbre linéaire avec np.linalg, les statistiques et les mécanismes de performance avancés comme np.einsum et la contiguïté mémoire.