PyTorch — tenseurs et autograd#
Pourquoi PyTorch ?#
Le paysage du deep learning est dominé par deux grandes bibliothèques : TensorFlow (Google) et PyTorch (Meta AI, anciennement Facebook). Si TensorFlow a longtemps été privilégié en production, PyTorch s’est imposé comme le standard de la recherche académique et prend une place croissante dans les environnements industriels. Comprendre pourquoi aide à apprécier ses choix de conception.
La caractéristique la plus distinctive de PyTorch est son graphe de calcul dynamique (define-by-run). À la différence de TensorFlow 1.x, qui demandait de définir le graphe de calcul avant de l’exécuter dans une session séparée, PyTorch construit le graphe à la volée, au moment même où les opérations sont exécutées. Cela rend le code beaucoup plus intuitif : un programme PyTorch ressemble à du Python ordinaire, avec des boucles, des conditions et des appels de fonctions habituels. Le débogage devient immédiat — on peut inspecter les valeurs des tenseurs à n’importe quelle étape en utilisant print() ou un débogueur standard.
Note
PyTorch est aujourd’hui largement adopté par la communauté scientifique : la grande majorité des articles de recherche en apprentissage profond publiés dans les conférences majeures (NeurIPS, ICML, ICLR) sont accompagnés d’implémentations PyTorch. Des bibliothèques phares comme Hugging Face Transformers, Lightning, TorchVision et TorchAudio reposent toutes sur PyTorch. Sa popularité en recherche se traduit progressivement en adoption industrielle, notamment grâce à TorchScript et ONNX qui permettent d’exporter des modèles vers des environnements de production.
# Installation (si nécessaire)
# pip install torch torchvision torchaudio
# ou avec support CUDA :
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
import torch
print(f"Version de PyTorch : {torch.__version__}")
print(f"CUDA disponible : {torch.cuda.is_available()}")
print(f"MPS disponible : {torch.backends.mps.is_available()}")
# Sélection automatique du device disponible
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
print(f"Device utilisé : {device}")
Version de PyTorch : 2.10.0+cpu
CUDA disponible : False
MPS disponible : False
Device utilisé : cpu
Tenseurs#
Le tenseur est l’objet central de PyTorch. On peut le concevoir comme une généralisation des tableaux NumPy : un tableau multidimensionnel de valeurs numériques homogènes. Un scalaire est un tenseur de rang 0, un vecteur un tenseur de rang 1, une matrice un tenseur de rang 2, et ainsi de suite. Ce qui distingue les tenseurs PyTorch des tableaux NumPy, c’est leur capacité à résider sur un accélérateur matériel (GPU ou Apple Silicon) et à participer automatiquement à la différentiation.
Tenseur PyTorch
Un tenseur PyTorch est un tableau multidimensionnel caractérisé par :
Sa forme (shape) : un tuple décrivant le nombre d’éléments le long de chaque dimension.
Son type de données (dtype) :
torch.float32(par défaut),torch.float64,torch.int64,torch.bool, etc.Son device : l’emplacement physique en mémoire —
cpu,cuda:0(premier GPU NVIDIA),mps(Apple Silicon).Son
requires_grad: booléen indiquant si les opérations sur ce tenseur doivent être enregistrées pour la rétropropagation.
Création de tenseurs#
# À partir d'une liste Python
t1 = torch.tensor([1.0, 2.0, 3.0])
print(f"Depuis liste : {t1} dtype={t1.dtype} shape={t1.shape}")
# Tenseurs prédéfinis
t_zeros = torch.zeros(3, 4)
t_ones = torch.ones(2, 3, 4)
t_eye = torch.eye(4)
t_rand = torch.rand(3, 3) # uniforme sur [0, 1)
t_randn = torch.randn(3, 3) # normale standard N(0, 1)
t_arange = torch.arange(0, 10, 2, dtype=torch.float32)
print(f"zeros(3,4) shape : {t_zeros.shape}")
print(f"ones(2,3,4) shape : {t_ones.shape}")
print(f"arange : {t_arange}")
# Spécifier le dtype et le device
t_float64 = torch.tensor([1.0, 2.0], dtype=torch.float64)
t_int32 = torch.tensor([1, 2, 3], dtype=torch.int32)
t_on_dev = torch.randn(4, 4, device=device)
print(f"Sur {device} : {t_on_dev.device}")
Depuis liste : tensor([1., 2., 3.]) dtype=torch.float32 shape=torch.Size([3])
zeros(3,4) shape : torch.Size([3, 4])
ones(2,3,4) shape : torch.Size([2, 3, 4])
arange : tensor([0., 2., 4., 6., 8.])
Sur cpu : cpu
Conversion depuis NumPy#
# NumPy → PyTorch
arr = np.array([[1.0, 2.0], [3.0, 4.0]])
t_from_np = torch.from_numpy(arr) # partage la mémoire !
t_copy = torch.tensor(arr) # copie indépendante
print(f"from_numpy : {t_from_np}")
print(f"Même mémoire (from_numpy) : {t_from_np.data_ptr() == arr.ctypes.data}")
# PyTorch → NumPy (seulement sur CPU)
arr_back = t_from_np.numpy()
print(f"Retour NumPy : {arr_back}")
# Déplacer vers/depuis un device
if device.type != 'cpu':
t_gpu = t_from_np.to(device)
t_cpu = t_gpu.cpu()
from_numpy : tensor([[1., 2.],
[3., 4.]], dtype=torch.float64)
Même mémoire (from_numpy) : True
Retour NumPy : [[1. 2.]
[3. 4.]]
Note
torch.from_numpy() crée un tenseur qui partage la mémoire avec le tableau NumPy sous-jacent : modifier l’un modifie l’autre. C’est efficace mais peut être source de bugs subtils. Pour une copie indépendante, utiliser torch.tensor(arr) ou torch.from_numpy(arr).clone(). Cette contrainte de mémoire partagée disparaît dès qu’on déplace le tenseur sur un GPU (.to('cuda')) puisque la mémoire GPU est distincte de la mémoire CPU.
Opérations sur les tenseurs#
PyTorch propose une API très riche d’opérations algébriques, la plupart disponibles aussi bien comme méthodes de tenseur que comme fonctions du module torch.
a = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
b = torch.tensor([[5.0, 6.0], [7.0, 8.0]])
# Arithmétique élément par élément
print("Addition :", a + b)
print("Multiplication :", a * b)
print("Division :", b / a)
print("Puissance :", a ** 2)
# Produit matriciel
print("\nMatmul (a @ b) :\n", a @ b)
print("torch.matmul :\n", torch.matmul(a, b))
Addition : tensor([[ 6., 8.],
[10., 12.]])
Multiplication : tensor([[ 5., 12.],
[21., 32.]])
Division : tensor([[5.0000, 3.0000],
[2.3333, 2.0000]])
Puissance : tensor([[ 1., 4.],
[ 9., 16.]])
Matmul (a @ b) :
tensor([[19., 22.],
[43., 50.]])
torch.matmul :
tensor([[19., 22.],
[43., 50.]])
einsum est une notation puissante et concise qui unifie de nombreuses opérations tensorielle (transposée, produit matriciel, produit externe, contraction de tenseurs) :
# Produit matriciel avec einsum
print("einsum matmul :\n", torch.einsum('ij,jk->ik', a, b))
# Trace d'une matrice
print("Trace :", torch.einsum('ii->', a))
# Produit scalaire de deux vecteurs
v1 = torch.tensor([1.0, 2.0, 3.0])
v2 = torch.tensor([4.0, 5.0, 6.0])
print("Produit scalaire :", torch.einsum('i,i->', v1, v2))
# Produit externe
print("Produit externe :\n", torch.einsum('i,j->ij', v1, v2))
einsum matmul :
tensor([[19., 22.],
[43., 50.]])
Trace : tensor(5.)
Produit scalaire : tensor(32.)
Produit externe :
tensor([[ 4., 5., 6.],
[ 8., 10., 12.],
[12., 15., 18.]])
Le broadcasting de PyTorch suit les mêmes règles que NumPy — les dimensions sont alignées depuis la droite, et une dimension de taille 1 est étirée automatiquement pour correspondre à l’autre opérande :
# Broadcasting : ajouter un vecteur à chaque ligne d'une matrice
mat = torch.randn(4, 3)
biais = torch.tensor([0.1, 0.2, 0.3]) # shape (3,)
result = mat + biais # shape (4, 3)
print(f"mat shape : {mat.shape}, biais shape : {biais.shape} → {result.shape}")
# Opérations in-place (se terminent par _)
x = torch.ones(3)
x.add_(2.0) # équivalent à x += 2.0, modifie x sur place
print("In-place add_ :", x)
mat shape : torch.Size([4, 3]), biais shape : torch.Size([3]) → torch.Size([4, 3])
In-place add_ : tensor([3., 3., 3.])
Note
Les opérations in-place (suffixées par _) modifient le tenseur directement en mémoire sans allouer un nouveau tenseur. Elles sont plus économes en mémoire, mais incompatibles avec l’autograd si le tenseur participe à un graphe de calcul : PyTorch lève une erreur car l’opération in-place détruit des informations nécessaires à la rétropropagation. Il faut donc les éviter sur les tenseurs avec requires_grad=True.
Autograd#
L”autograd est le mécanisme de différentiation automatique de PyTorch. Il permet de calculer les gradients de n’importe quelle expression tensorielle par rapport à ses entrées, sans avoir à dériver les formules à la main. C’est le cœur du deep learning : l’optimisation des paramètres d’un réseau de neurones repose entièrement sur ce calcul automatique des gradients.
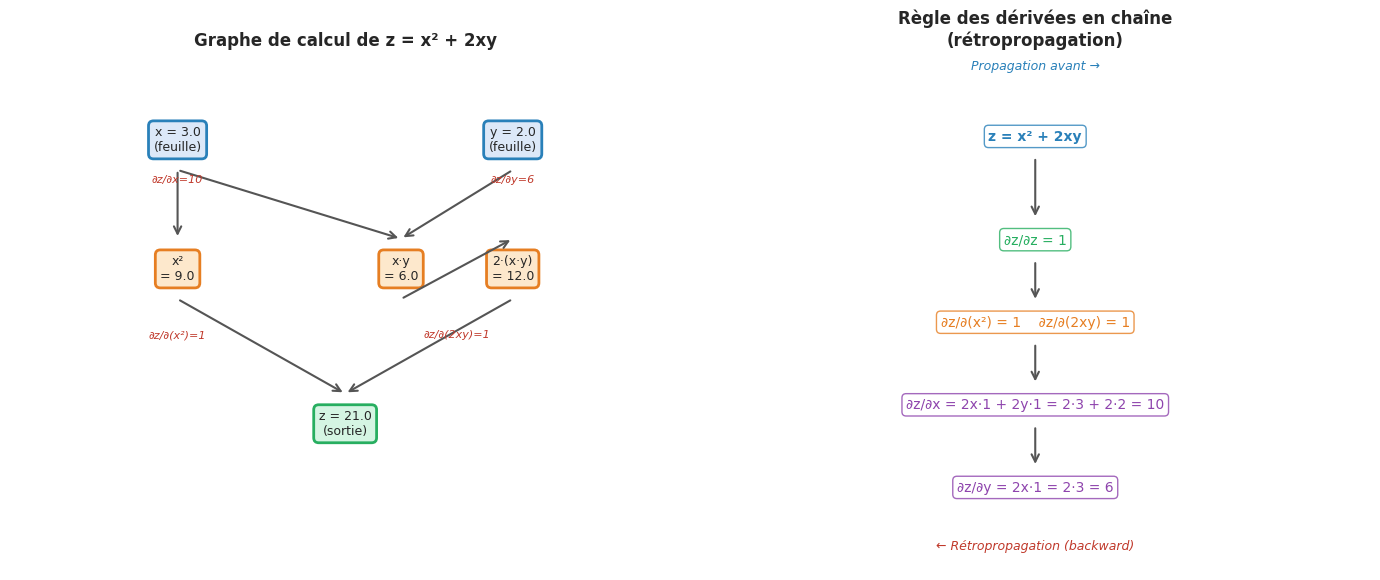
Graphe de calcul et rétropropagation
Lorsqu’un tenseur avec requires_grad=True participe à des opérations, PyTorch enregistre ces opérations dans un graphe de calcul orienté acyclique (DAG). Les noeuds feuilles sont les tenseurs d’entrée, les noeuds internes sont les résultats des opérations. L’appel à .backward() sur un tenseur scalaire déclenche la rétropropagation : PyTorch parcourt le graphe en sens inverse et accumule les gradients dans l’attribut .grad de chaque tenseur feuille avec requires_grad=True, en appliquant la règle des dérivées en chaîne.
# Exemple simple : z = x² + 2xy, dz/dx = 2x + 2y, dz/dy = 2x
x = torch.tensor(3.0, requires_grad=True)
y = torch.tensor(2.0, requires_grad=True)
z = x**2 + 2 * x * y
print(f"z = x² + 2xy = {z.item()}")
# Rétropropagation
z.backward()
print(f"dz/dx = 2x + 2y = {x.grad.item():.1f} (attendu : {2*3 + 2*2:.1f})")
print(f"dz/dy = 2x = {y.grad.item():.1f} (attendu : {2*3:.1f})")
z = x² + 2xy = 21.0
dz/dx = 2x + 2y = 10.0 (attendu : 10.0)
dz/dy = 2x = 6.0 (attendu : 6.0)
# Accumulation des gradients : les gradients s'accumulent !
x = torch.tensor(1.0, requires_grad=True)
loss1 = x ** 2
loss1.backward()
print(f"Après loss1.backward() : x.grad = {x.grad}") # 2.0
loss2 = x ** 3
loss2.backward()
print(f"Après loss2.backward() : x.grad = {x.grad}") # 2.0 + 3.0 = 5.0 !
# Il faut remettre les gradients à zéro avant chaque itération
x.grad.zero_()
loss3 = x ** 2
loss3.backward()
print(f"Après zero_() + loss3 : x.grad = {x.grad}") # 2.0
Après loss1.backward() : x.grad = 2.0
Après loss2.backward() : x.grad = 5.0
Après zero_() + loss3 : x.grad = 2.0
torch.no_grad() désactive l’enregistrement des opérations dans le graphe de calcul. On l’utilise systématiquement lors de l’inférence (évaluation, prédiction) pour économiser de la mémoire et accélérer les calculs :
x = torch.tensor(2.0, requires_grad=True)
# Avec no_grad : pas de graphe de calcul, pas de gradient possible
with torch.no_grad():
y = x ** 2 + 1
print(f"y.requires_grad = {y.requires_grad}") # False
# Hors no_grad : le graphe est construit
y = x ** 2 + 1
print(f"y.requires_grad = {y.requires_grad}") # True
y.requires_grad = False
y.requires_grad = True
Visualisation du graphe de calcul et des gradients#
torch.nn.functional#
Le module torch.nn.functional (conventionnellement importé sous l’alias F) regroupe les fonctions stateless (sans état, sans paramètres apprenables) du deep learning : fonctions d’activation, fonctions de perte, opérations de convolution, etc.
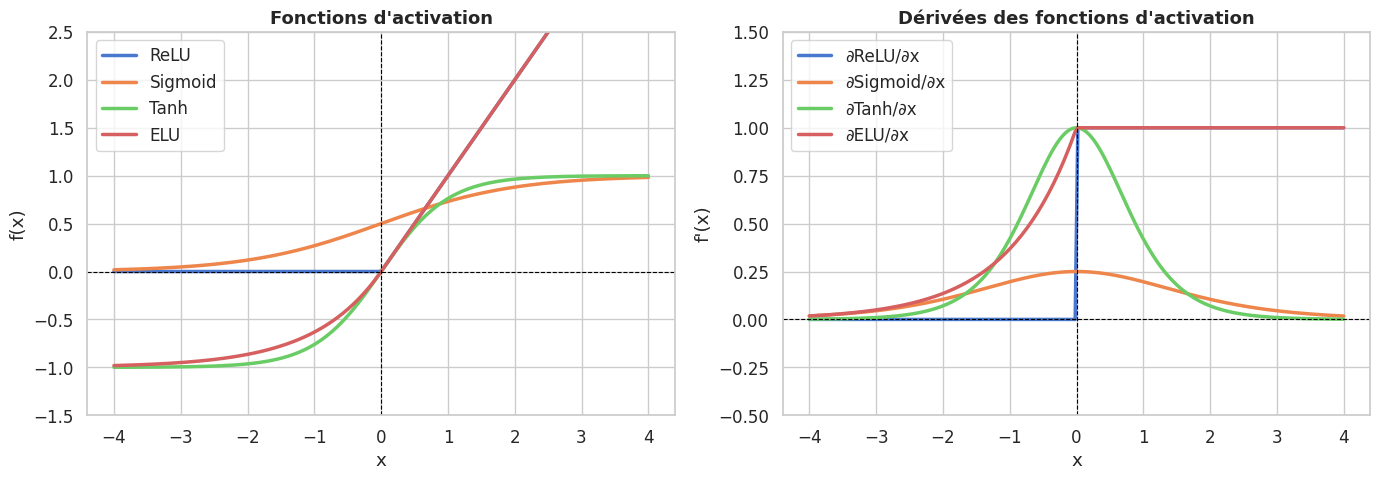
Fonctions d’activation
Les fonctions d’activation introduisent la non-linéarité indispensable aux réseaux de neurones profonds. Sans elles, un empilement de couches linéaires resterait une transformation linéaire globale. Les principales sont :
ReLU (Rectified Linear Unit) : \(f(x) = \max(0, x)\). Simple, efficace, ne souffre pas du problème de gradient qui s’évanouit pour les grandes valeurs positives.
Sigmoid : \(f(x) = \frac{1}{1 + e^{-x}}\). Sortie dans \((0, 1)\), utilisée pour les probabilités binaires. Souffre de la saturation pour les grandes valeurs.
Softmax : \(f(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}}\). Transforme un vecteur en distribution de probabilité. Utilisée en dernière couche pour la classification multi-classes.
import torch.nn.functional as F
x = torch.tensor([-2.0, -1.0, 0.0, 1.0, 2.0])
print("ReLU :", F.relu(x))
print("Sigmoid :", F.sigmoid(x).round(decimals=4))
print("Tanh :", F.tanh(x).round(decimals=4))
logits = torch.tensor([1.0, 2.0, 3.0])
print("Softmax :", F.softmax(logits, dim=0).round(decimals=4))
ReLU : tensor([0., 0., 0., 1., 2.])
Sigmoid : tensor([0.1192, 0.2689, 0.5000, 0.7311, 0.8808])
Tanh : tensor([-0.9640, -0.7616, 0.0000, 0.7616, 0.9640])
Softmax : tensor([0.0900, 0.2447, 0.6652])
# Fonctions de perte
y_true = torch.tensor([0, 1, 2, 1]) # classes réelles
logits = torch.randn(4, 3) # scores bruts du modèle (4 exemples, 3 classes)
# Cross-entropie (combine LogSoftmax + NLLLoss)
loss_ce = F.cross_entropy(logits, y_true)
print(f"CrossEntropy loss : {loss_ce.item():.4f}")
# MSE loss pour la régression
y_pred = torch.tensor([2.5, 0.0, 2.0, 8.0])
y_real = torch.tensor([3.0, -0.5, 2.0, 7.0])
loss_mse = F.mse_loss(y_pred, y_real)
print(f"MSE loss : {loss_mse.item():.4f}")
# BCE loss pour la classification binaire (après sigmoid)
y_bin = torch.tensor([1.0, 0.0, 1.0])
p_bin = torch.sigmoid(torch.tensor([2.0, -1.0, 0.5]))
loss_bce = F.binary_cross_entropy(p_bin, y_bin)
print(f"BCE loss : {loss_bce.item():.4f}")
CrossEntropy loss : 1.1239
MSE loss : 0.3750
BCE loss : 0.3048
Résumé#
Ce chapitre a introduit les fondations de PyTorch :
PyTorch se distingue par son graphe de calcul dynamique (define-by-run), qui rend le code intuitif à écrire et à déboguer. Il est devenu le standard de la recherche en deep learning et gagne en popularité dans les environnements de production.
Un tenseur est le type de données central : un tableau multidimensionnel caractérisé par sa forme, son
dtypeet sondevice. Il peut être créé depuis des listes Python, des tableaux NumPy ou des générateurs (torch.randn,torch.zeros, etc.).PyTorch offre une riche palette d”opérations : arithmétique élément par élément, produit matriciel (
@,matmul),einsumpour les contractions générales, et broadcasting automatique. Les opérations in-place (suffixe_) sont pratiques mais incompatibles avec l’autograd.L”autograd est le mécanisme de différentiation automatique. Il enregistre les opérations dans un graphe orienté acyclique et calcule les gradients par rétropropagation via
.backward().torch.no_grad()désactive ce mécanisme pour l’inférence.torch.nn.functionalregroupe les fonctions stateless : activations (ReLU, sigmoid, tanh), fonctions de perte (cross-entropie, MSE, BCE). Leurs gradients sont calculés automatiquement par autograd.
Le chapitre suivant s’appuie sur ces fondations pour construire des réseaux de neurones complets à l’aide de nn.Module, l’abstraction de haut niveau de PyTorch pour la définition d’architectures.