L’écosystème data science#
Python pour la data science#
Comment un langage de programmation généraliste, initialement conçu pour l’enseignement et l’automatisation de tâches système, est-il devenu le standard incontesté de la data science ? La réponse tient à une combinaison de facteurs techniques, sociologiques et historiques qui se sont renforcés mutuellement au fil du temps.
Au début des années 2000, le paysage de l’analyse de données scientifiques était dominé par des outils propriétaires : MATLAB pour le calcul numérique dans les universités et les laboratoires d’ingénierie, SAS et SPSS dans les entreprises, et R qui émergeait comme alternative libre dans la communauté statistique. Python était présent en périphérie — les développeurs l’utilisaient pour coller des scripts ensemble — mais il ne possédait pas encore les bibliothèques nécessaires à un usage scientifique intensif.
Tout change en 2006 avec la publication de NumPy 1.0, qui offre enfin à Python un tableau multidimensionnel performant. Puis Matplotlib, SciPy, IPython et finalement Pandas (2009) viennent compléter la stack. La création de l”IPython Notebook en 2011, devenu Jupyter en 2014, révolutionne la façon dont les data scientists explorent et présentent leurs analyses. L’essor du deep learning à partir de 2012, avec des bibliothèques comme Theano, TensorFlow puis PyTorch, se fait quasi exclusivement en Python, entraînant des millions de nouveaux utilisateurs.
Face à Python, R reste compétitif dans le domaine de la statistique pure, avec des packages comme ggplot2 pour la visualisation ou tidyverse pour la manipulation de données. Mais R est un langage spécialisé, difficile à utiliser hors de son domaine, et dont la courbe d’apprentissage est réputée abrupte. MATLAB souffre de son modèle propriétaire coûteux et de l’absence d’un écosystème open-source comparable. Julia, langage plus récent (2012), promet des performances proches du C tout en conservant une syntaxe de haut niveau, mais son adoption reste limitée malgré ses qualités techniques indéniables.
Python l’a emporté pour des raisons pragmatiques : la facilité d’apprentissage de sa syntaxe, la polyvalence qui permet de passer du prototypage à la production dans un même langage, la qualité de ses bibliothèques scientifiques, et surtout la masse critique d’utilisateurs qui génère une documentation abondante, des tutoriels, des forums d’aide et un recrutement facilité.
Stack data science
On appelle stack data science l’ensemble des bibliothèques et outils Python utilisés de façon combinée pour mener à bien des projets d’analyse de données et d’apprentissage automatique. La stack minimale comprend NumPy (calcul numérique), Pandas (données tabulaires), Matplotlib et Seaborn (visualisation) et Scikit-learn (machine learning). Elle s’étend selon les besoins avec PyTorch ou TensorFlow (deep learning), Xarray (données multidimensionnelles), Dask (calcul distribué) ou Polars (DataFrames hautes performances).
L’environnement Jupyter#
JupyterLab est l’interface de développement interactive de référence pour la data science. Il succède au Jupyter Notebook classique en proposant un environnement plus complet, proche d’un IDE, avec un gestionnaire de fichiers, un éditeur de texte, un terminal et plusieurs panneaux de notebooks côte à côte.
Un notebook (fichier .ipynb) est un document JSON qui entrelace des cellules de deux types principaux. Les cellules de code contiennent du Python exécutable : lorsqu’on les exécute, leur sortie — texte, tableau, graphique — s’affiche immédiatement en dessous. Les cellules Markdown contiennent du texte formaté, des équations LaTeX, des images et des liens hypertexte. Cette alternance de code et de narration fait du notebook un outil idéal pour l’exploration de données, la présentation de résultats et la documentation de démarches analytiques.
Note
Les raccourcis clavier essentiels de JupyterLab à maîtriser dès le début sont les suivants. En mode commande (cellule sélectionnée en bleu, touche Échap pour y entrer) : A insère une cellule au-dessus (above), B en dessous (below), D D supprime la cellule, M convertit la cellule en Markdown, Y la repasse en code, Shift+Entrée exécute et passe à la suivante, Ctrl+Entrée exécute sans avancer. En mode édition (cellule sélectionnée en vert, touche Entrée pour y entrer) : Tab active l’autocomplétion, Shift+Tab affiche la documentation de la fonction sous le curseur.
L’une des particularités importantes des notebooks est l”ordre d’exécution des cellules. Contrairement à un script Python classique exécuté de haut en bas, les cellules d’un notebook peuvent être exécutées dans n’importe quel ordre. Cette liberté est aussi un piège : il est fréquent d’obtenir des résultats différents selon l’ordre dans lequel les cellules ont été lancées, ce qui nuit à la reproductibilité. La bonne pratique est de relancer régulièrement le noyau et d’exécuter toutes les cellules (Kernel → Restart and Run All) pour vérifier que le notebook s’exécute correctement de bout en bout.
Mise en place avec uv#
uv est un gestionnaire de paquets et d’environnements Python ultrarapide, écrit en Rust, qui a largement supplanté pip et virtualenv dans les usages modernes. Il résout en quelques secondes des dépendances que pip mettait parfois des minutes à calculer.
Création d’un environnement data science avec uv
Voici la procédure complète pour créer un environnement isolé et y installer la stack data science :
# Installer uv (si ce n'est pas déjà fait)
curl -LsSf https://astral.sh/uv/install.sh | sh
# Créer un nouveau projet
uv init mon-projet-datascience
cd mon-projet-datascience
# Créer l'environnement virtuel
uv venv
# Activer l'environnement (Linux/macOS)
source .venv/bin/activate
# Installer la stack complète
uv pip install numpy pandas matplotlib seaborn scikit-learn torch torchvision xarray jupyterlab
# Lancer JupyterLab
jupyter lab
Il est fortement conseillé de figer les versions des dépendances pour garantir la reproductibilité. uv génère un fichier uv.lock qui enregistre la version exacte de chaque paquet installé, permettant de recréer l’environnement identique sur une autre machine.
# Vérifier les versions installées
import numpy as np
import pandas as pd
import sklearn
import torch
print(f"NumPy : {np.__version__}")
print(f"Pandas : {pd.__version__}")
print(f"Sklearn : {sklearn.__version__}")
print(f"PyTorch : {torch.__version__}")
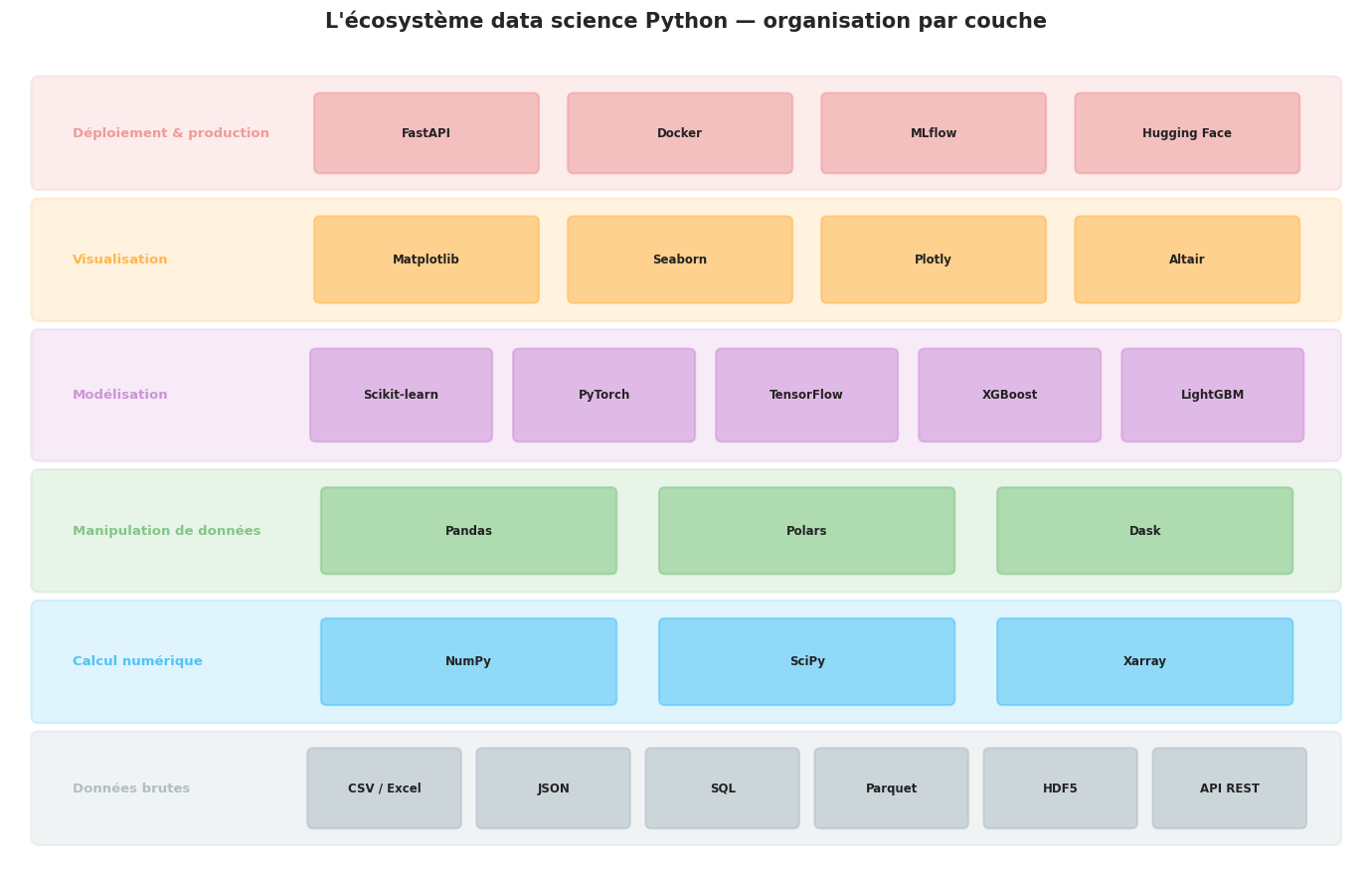
La stack scientifique#
L’écosystème data science Python s’organise en couches logiques, chacune s’appuyant sur les couches inférieures.
NumPy
NumPy (Numerical Python) est le fondement de toute la stack scientifique. Il fournit le type ndarray, un tableau multidimensionnel homogène stocké en mémoire contiguë, ainsi que des milliers de fonctions mathématiques opérant sur ces tableaux. La quasi-totalité des bibliothèques scientifiques Python acceptent et retournent des tableaux NumPy, ce qui en fait le format d’échange universel des données numériques.
Pandas
Pandas introduit deux structures de données de haut niveau : la Series (tableau unidimensionnel indexé) et le DataFrame (tableau bidimensionnel avec index et colonnes nommées). Pandas excelle dans la manipulation de données hétérogènes du monde réel : chargement de fichiers CSV, Excel, JSON et Parquet, gestion des valeurs manquantes, transformation, agrégation et fusion de tables. Son index permet l’alignement automatique des données lors des opérations, évitant de nombreuses erreurs de manipulation manuelle.
Scikit-learn
Scikit-learn est la bibliothèque de référence pour le machine learning classique. Elle propose une API remarquablement cohérente — toutes les classes exposent les méthodes fit(), predict() et transform() — ce qui facilite l’expérimentation et le remplacement d’un algorithme par un autre. La bibliothèque couvre la régression, la classification, le clustering, la réduction de dimension, la sélection de variables et l’évaluation de modèles.
PyTorch
PyTorch est un cadre de deep learning développé par Meta (Facebook) AI Research. Il se distingue par son graphe de calcul dynamique (define-by-run), qui permet de modifier l’architecture du réseau à la volée — une flexibilité particulièrement appréciée pour la recherche. PyTorch est aujourd’hui le framework dominant dans les publications académiques et s’impose également dans l’industrie.
Aux côtés de ces bibliothèques centrales, l’écosystème comprend Matplotlib pour la visualisation de bas niveau, Seaborn pour des graphiques statistiques esthétiques construits sur Matplotlib, SciPy pour les algorithmes scientifiques avancés (intégration numérique, traitement du signal, optimisation), Xarray pour les données multidimensionnelles étiquetées, et Dask pour le calcul distribué sur des volumes de données dépassant la mémoire vive disponible.
Bonnes pratiques pour les notebooks#
Un notebook bien structuré est un outil de communication autant qu’un outil de travail. Les bonnes pratiques suivantes permettent d’éviter les pièges les plus courants et d’assurer la pérennité des analyses.
Reproductibilité. Toujours fixer la graine du générateur aléatoire (np.random.seed(42) ou rng = np.random.default_rng(42)) pour que les résultats numériques soient identiques à chaque exécution. Documenter les versions des bibliothèques utilisées, idéalement dans une cellule finale affichant pip freeze ou le contenu du fichier uv.lock.
Ordre d’exécution. Un notebook doit toujours pouvoir s’exécuter de bout en bout sans erreur après un redémarrage du noyau. La commande jupyter nbconvert --to notebook --execute mon_notebook.ipynb permet de vérifier cette propriété automatiquement dans un pipeline d’intégration continue.
Structure. Un notebook se lit comme un article : commencer par une introduction qui pose le problème, organiser les sections avec des titres Markdown clairs (##, ###), et conclure par un résumé des résultats et des conclusions. Les cellules de code doivent être courtes et focalisées. Si une cellule dépasse une vingtaine de lignes, il est généralement préférable d’extraire la logique dans un module Python séparé et de l’importer.
Versionner les notebooks. Les fichiers .ipynb sont du JSON et contiennent les sorties (images, tableaux), ce qui produit des diffs Git illisibles. Plusieurs stratégies existent : utiliser Jupytext pour maintenir une version .md ou .py synchronisée du notebook, ou configurer un filtre Git avec nbstripout pour effacer les sorties avant chaque commit. Ce livre utilise Jupytext, ce qui explique le frontmatter YAML présent en en-tête de chaque fichier source.
Note
nbconvert permet d’exporter un notebook vers de nombreux formats : HTML (--to html), PDF via LaTeX (--to pdf), script Python (--to script), présentation Reveal.js (--to slides). Cette capacité d’export est précieuse pour partager des résultats avec des collaborateurs qui n’ont pas Jupyter installé, ou pour intégrer des analyses dans une documentation générée automatiquement avec Sphinx ou Jupyter Book.
Nommer les notebooks de façon explicite. Un nom comme 01_exploration_donnees_ventes.ipynb est préférable à analyse_v3_final.ipynb. La numérotation facilite le tri, et le nom doit décrire le contenu, pas l’état d’avancement.
Résumé#
Ce premier chapitre a posé les bases de l’environnement dans lequel nous allons travailler tout au long de ce livre :
Python s’est imposé comme le standard de la data science grâce à la qualité de ses bibliothèques, à sa syntaxe accessible et à la masse critique de sa communauté, supplantant progressivement R, MATLAB et Julia pour la majorité des usages.
JupyterLab offre un environnement interactif qui entrelace code exécutable et narration textuelle, idéal pour l’exploration et la présentation d’analyses. La maîtrise des raccourcis clavier et l’exécution régulière de bout en bout sont des habitudes essentielles à prendre dès le début.
uvest l’outil moderne de référence pour créer des environnements virtuels isolés et gérer les dépendances avec reproductibilité.La stack scientifique Python s’organise en couches : NumPy pour le calcul numérique bas niveau, Pandas pour les données tabulaires, Scikit-learn pour le machine learning classique, PyTorch pour le deep learning, et Matplotlib/Seaborn pour la visualisation.
Les bonnes pratiques — reproductibilité, ordre d’exécution, structure narrative, versionning avec Jupytext — transforment un notebook en document pérenne et communicable.
Dans le chapitre suivant, nous plongerons au cœur de NumPy pour comprendre pourquoi les tableaux multidimensionnels sont si fondamentaux, et comment exploiter la vectorisation pour écrire du code à la fois rapide et expressif.