Entraînement, optimisation et régularisation#
<torch._C.Generator at 0x7fbc65792a90>
La boucle d’entraînement PyTorch#
L’entraînement d’un réseau de neurones consiste à ajuster itérativement ses paramètres de façon à minimiser une fonction de perte sur un ensemble de données. PyTorch ne fournit pas de boucle d’entraînement automatique à la manière de Keras : le praticien écrit lui-même cette boucle, ce qui lui donne un contrôle total sur chaque étape du processus. Cette transparence a un coût — quelques dizaines de lignes de code supplémentaires — mais elle est la source d’une flexibilité incomparable pour la recherche et pour l’implémentation d’algorithmes non standard.
La boucle d’entraînement canonique en PyTorch suit invariablement la même structure à cinq temps. Premièrement, on effectue une passe avant (forward pass) : le batch d’entrée traverse le réseau, produisant des prédictions. Deuxièmement, on calcule la perte en comparant les prédictions aux étiquettes cibles. Troisièmement, on appelle optimizer.zero_grad() pour remettre à zéro les gradients accumulés dans les paramètres : PyTorch accumule les gradients par défaut, il est donc indispensable de les effacer avant chaque rétropropagation. Quatrièmement, on effectue la rétropropagation avec loss.backward(), qui calcule le gradient de la perte par rapport à chaque paramètre via la règle de dérivation en chaîne. Cinquièmement, on appelle optimizer.step(), qui met à jour les paramètres dans la direction opposée au gradient.
Époque et itération
Une époque (epoch) correspond à un passage complet sur l’ensemble d’entraînement : chaque exemple a été vu exactement une fois par le réseau. Une itération (iteration ou step) correspond à la mise à jour des paramètres à partir d’un seul batch. Si l’ensemble d’entraînement contient \(N\) exemples et que la taille de batch est \(B\), une époque contient \(\lceil N/B \rceil\) itérations.
def boucle_entrainement(modele, loader_train, loader_val,
critere, optimiseur, n_epoques, device):
historique = {"train_loss": [], "val_loss": [], "val_acc": []}
for epoque in range(1, n_epoques + 1):
# ── Phase d'entraînement ─────────────────────────────────────
modele.train() # active le dropout, la batch norm en mode train
train_loss_cumul = 0.0
for x_batch, y_batch in loader_train:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
optimiseur.zero_grad() # 1. remise à zéro des gradients
predictions = modele(x_batch) # 2. passe avant
perte = critere(predictions, y_batch) # 3. calcul de la perte
perte.backward() # 4. rétropropagation
optimiseur.step() # 5. mise à jour des paramètres
train_loss_cumul += perte.item() * x_batch.size(0)
train_loss = train_loss_cumul / len(loader_train.dataset)
# ── Phase de validation ───────────────────────────────────────
modele.eval() # désactive le dropout, batch norm en mode eval
val_loss_cumul = 0.0
n_corrects = 0
with torch.no_grad(): # désactive le calcul des gradients
for x_batch, y_batch in loader_val:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
predictions = modele(x_batch)
perte = critere(predictions, y_batch)
val_loss_cumul += perte.item() * x_batch.size(0)
n_corrects += (predictions.argmax(1) == y_batch).sum().item()
val_loss = val_loss_cumul / len(loader_val.dataset)
val_acc = n_corrects / len(loader_val.dataset)
historique["train_loss"].append(train_loss)
historique["val_loss"].append(val_loss)
historique["val_acc"].append(val_acc)
print(f"Époque {epoque:03d}/{n_epoques} | "
f"train={train_loss:.4f} | val={val_loss:.4f} | acc={val_acc:.3f}")
return historique
Note
L’alternance entre modele.train() et modele.eval() est essentielle et souvent oubliée par les débutants. Ces appels basculent certaines couches dans des comportements différents selon la phase. Le dropout est actif en entraînement (les neurones sont éteints aléatoirement) et désactivé en évaluation (tous les neurones transmettent leur valeur, pondérée pour conserver l’espérance). La batch normalization utilise les statistiques du batch courant en entraînement et les statistiques globales accumulées (moyenne et variance mobiles) en évaluation. Omettre modele.eval() pendant la validation produit des résultats bruités et non reproductibles.
DataLoader et Dataset#
Charger les données par batch, mélanger l’ensemble d’entraînement à chaque époque, et exploiter plusieurs cœurs CPU pour la préparation des données en parallèle de l’entraînement GPU : ce sont les rôles du tandem Dataset / DataLoader de PyTorch.
Dataset et DataLoader
Un Dataset est un objet qui encapsule les données brutes et définit comment accéder à un exemple individuel. Il doit implémenter deux méthodes : __len__() (nombre d’exemples) et __getitem__(idx) (accès à l’exemple d’index idx). Un DataLoader enveloppe un Dataset et gère automatiquement le découpage en batches, le mélange aléatoire, et le chargement parallèle en arrière-plan via des workers.
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
class MonDataset(Dataset):
"""Dataset personnalisé pour des données tabulaires."""
def __init__(self, X: np.ndarray, y: np.ndarray):
self.X = torch.from_numpy(X).float()
self.y = torch.from_numpy(y).long()
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
# Création des DataLoaders
dataset_train = MonDataset(X_train, y_train)
dataset_val = MonDataset(X_val, y_val)
loader_train = DataLoader(
dataset_train,
batch_size=64,
shuffle=True, # mélange l'ordre à chaque époque
num_workers=4, # chargement parallèle sur 4 cœurs CPU
pin_memory=True, # accélère le transfert vers le GPU
)
loader_val = DataLoader(
dataset_val,
batch_size=256, # batch plus grand en validation (pas de gradient)
shuffle=False,
num_workers=4,
pin_memory=True,
)
La valeur num_workers=4 lance quatre processus Python parallèles qui préparent les batches pendant que le GPU effectue le calcul du batch précédent. Ce pipeline de données asynchrone est fondamental pour éviter que le chargement des données devienne le goulot d’étranglement de l’entraînement, surtout lorsque les données requièrent des transformations coûteuses (redimensionnement d’images, augmentation de données).
Optimiseurs#
Un optimiseur met à jour les paramètres du réseau à partir des gradients calculés par la rétropropagation. Tous les optimiseurs PyTorch résident dans torch.optim et partagent la même interface : zero_grad(), step().
Descente de gradient stochastique (SGD)
La descente de gradient stochastique (Stochastic Gradient Descent, SGD) met à jour chaque paramètre \(\theta\) selon la règle :
où \(\eta\) est le taux d’apprentissage (learning rate) et \(\nabla_\theta \mathcal{L}\) est le gradient de la perte calculé sur un mini-batch. La variante avec momentum introduit une variable d’élan \(v_t\) qui accumule les gradients passés, accélère la convergence dans les directions cohérentes et amortit les oscillations :
où \(\mu \in [0, 1)\) est le coefficient de momentum, typiquement \(0.9\).
Adam et AdamW
Adam (Adaptive Moment Estimation) maintient pour chaque paramètre une estimation adaptative du taux d’apprentissage, basée sur les premier et second moments des gradients :
Après correction du biais d’initialisation : \(\hat{m}_t = m_t/(1-\beta_1^t)\), \(\hat{v}_t = v_t/(1-\beta_2^t)\)
Les valeurs par défaut \(\beta_1 = 0.9\), \(\beta_2 = 0.999\), \(\epsilon = 10^{-8}\) fonctionnent bien dans la plupart des situations. AdamW corrige un défaut d’Adam : la décroissance des poids (weight decay) est découplée de l’adaptation du taux d’apprentissage, ce qui correspond mieux à la régularisation L2 souhaitée.
import torch.optim as optim
# SGD avec momentum — souvent utilisé pour les CNN après un warm-up
optimiseur_sgd = optim.SGD(
modele.parameters(),
lr=0.01,
momentum=0.9,
weight_decay=1e-4, # régularisation L2
nesterov=True, # variante de Nesterov : calcule le gradient à la position projetée
)
# Adam — bon choix par défaut pour la plupart des architectures
optimiseur_adam = optim.Adam(
modele.parameters(),
lr=1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0, # ⚠ weight_decay couplé dans Adam, utiliser AdamW à la place
)
# AdamW — recommandé pour les transformers et les architectures modernes
optimiseur_adamw = optim.AdamW(
modele.parameters(),
lr=1e-3,
betas=(0.9, 0.999),
weight_decay=1e-2, # découplé : appliqué directement aux paramètres
)
Le choix de l’optimiseur dépend du type d’architecture et de la tâche. SGD avec momentum reste compétitif pour les CNN entraînés sur des jeux de données larges comme ImageNet, à condition de bien régler le taux d’apprentissage et d’utiliser un scheduler. Adam et AdamW convergent plus vite et sont moins sensibles au réglage du taux d’apprentissage initial, ce qui les rend populaires pour les transformers, les réseaux de langage et le prototypage rapide.
Schedulers de taux d’apprentissage#
Le taux d’apprentissage est le hyperparamètre le plus critique de l’entraînement. Un taux trop élevé en fin d’entraînement empêche la convergence fine ; un taux trop faible au début ralentit inutilement l’apprentissage. Les schedulers font varier automatiquement le taux d’apprentissage au fil des époques ou des itérations.
# StepLR : divise le lr par `gamma` tous les `step_size` époques
scheduler_step = optim.lr_scheduler.StepLR(optimiseur, step_size=10, gamma=0.5)
# CosineAnnealingLR : suit une courbe en cosinus de lr_max à lr_min
scheduler_cos = optim.lr_scheduler.CosineAnnealingLR(
optimiseur, T_max=100, eta_min=1e-6
)
# OneCycleLR : warm-up puis décroissance — très efficace en pratique
scheduler_onecycle = optim.lr_scheduler.OneCycleLR(
optimiseur,
max_lr=1e-2,
steps_per_epoch=len(loader_train),
epochs=50,
pct_start=0.3, # 30% du temps consacré au warm-up
anneal_strategy='cos',
)
# ReduceLROnPlateau : réduit le lr quand la métrique stagne
scheduler_plateau = optim.lr_scheduler.ReduceLROnPlateau(
optimiseur,
mode='min', # surveille une métrique à minimiser (ex. val_loss)
factor=0.5, # multiplie le lr par 0.5
patience=5, # attend 5 époques sans amélioration
min_lr=1e-7,
)
# Dans la boucle d'entraînement :
# scheduler_step.step() # appelé après chaque époque
# scheduler_onecycle.step() # appelé après chaque batch
# scheduler_plateau.step(val_loss) # appelé après chaque époque avec la métrique
Note
La politique OneCycleLR, proposée par Smith & Touvron (2018), fait d’abord croître le taux d’apprentissage (warm-up) puis le fait décroître selon une courbe en cosinus. Cette stratégie permet d’utiliser des taux d’apprentissage bien plus élevés qu’avec une décroissance simple, ce qui accélère considérablement l’entraînement. En pratique, OneCycleLR avec AdamW est une combinaison très performante pour la majorité des architectures modernes.
Régularisation#
La régularisation désigne l’ensemble des techniques destinées à réduire le sur-apprentissage (overfitting) — la situation où le modèle performe bien sur les données d’entraînement mais généralise mal sur des données inconnues. Le sur-apprentissage est d’autant plus fréquent que le modèle est grand et que les données sont peu nombreuses.
Dropout#
Le dropout est la technique de régularisation la plus utilisée pour les réseaux entièrement connectés. Pendant l’entraînement, chaque neurone est éteint indépendamment avec une probabilité \(p\) à chaque passe avant. Le réseau est ainsi forcé à apprendre des représentations redondantes et robustes, car il ne peut pas s’appuyer sur des neurones spécifiques. En évaluation, tous les neurones sont actifs, et leurs sorties sont multipliées par \((1-p)\) pour conserver l’espérance (ou, comme le fait PyTorch, les sorties sont mises à l’échelle par \(1/(1-p)\) pendant l’entraînement — variante dite inverted dropout).
Dropout
Le dropout (Srivastava et al., 2014) applique à chaque neurone un masque binaire aléatoire pendant l’entraînement. Si \(h\) désigne le vecteur d’activations avant dropout et \(p\) le taux de dropout :
Le dénominateur \(1-p\) est la mise à l’échelle inverted qui garantit que l’espérance de la sortie est identique en entraînement et en évaluation. Des valeurs typiques de \(p\) sont \(0.1\) à \(0.3\) pour les couches convolutives et \(0.5\) pour les couches entièrement connectées.
Batch Normalization#
La normalisation par batch (batch normalization, BN) normalise les activations d’une couche au sein de chaque mini-batch, puis les remet à l’échelle avec des paramètres appris \(\gamma\) (échelle) et \(\beta\) (biais). Introduite par Ioffe & Szegedy (2015), la BN accélère considérablement l’entraînement en réduisant la dépendance à l’initialisation des poids, permet d’utiliser des taux d’apprentissage plus élevés, et a un effet régularisant modéré qui rend parfois le dropout superflu.
Batch Normalization
Pour un batch d’activations \(\{x_1, \ldots, x_B\}\) en une dimension donnée, la batch normalization calcule :
où \(\mu_B = \frac{1}{B}\sum_i x_i\) et \(\sigma_B^2 = \frac{1}{B}\sum_i (x_i - \mu_B)^2\) sont les statistiques du batch courant. Pendant l’inférence, \(\mu_B\) et \(\sigma_B^2\) sont remplacées par des moyennes mobiles exponentielles calculées sur l’ensemble d’entraînement.
Weight Decay#
La décroissance des poids (weight decay) est l’implémentation de la régularisation L2 : un terme \(\frac{\lambda}{2}\|\theta\|^2\) est ajouté à la fonction de perte, ce qui pénalise les poids de grande amplitude et les pousse vers zéro. Son effet est de simplifier le modèle et de réduire la variance des prédictions. Dans PyTorch, weight_decay s’applique directement dans l’optimiseur.
# Appliquer le weight decay seulement aux poids (pas aux biais ni aux paramètres de BN)
def configure_weight_decay(modele, weight_decay):
"""Sépare les paramètres selon qu'ils doivent être régularisés ou non."""
avec_decay = []
sans_decay = []
for name, param in modele.named_parameters():
if not param.requires_grad:
continue
# Les biais et paramètres de normalisation ne sont pas régularisés
if param.ndim == 1 or name.endswith(".bias"):
sans_decay.append(param)
else:
avec_decay.append(param)
return [
{"params": avec_decay, "weight_decay": weight_decay},
{"params": sans_decay, "weight_decay": 0.0},
]
groupes = configure_weight_decay(modele, weight_decay=1e-2)
optimiseur = optim.AdamW(groupes, lr=1e-3)
Early Stopping#
L”arrêt précoce (early stopping) surveille la perte de validation au fil des époques et interrompt l’entraînement dès que cette perte cesse de diminuer pendant un certain nombre d’époques consécutives (la patience). C’est à la fois une technique de régularisation — on évite de suroptimiser les données d’entraînement — et un gain de temps computationnel.
class EarlyStopping:
"""Arrête l'entraînement si la val_loss ne s'améliore plus."""
def __init__(self, patience=10, delta=1e-4, chemin="meilleur_modele.pt"):
self.patience = patience
self.delta = delta
self.chemin = chemin
self.meilleure_perte = float("inf")
self.compteur = 0
self.stop = False
def __call__(self, val_loss, modele):
if val_loss < self.meilleure_perte - self.delta:
# Amélioration : sauvegarder le modèle et réinitialiser le compteur
self.meilleure_perte = val_loss
self.compteur = 0
torch.save(modele.state_dict(), self.chemin)
else:
self.compteur += 1
if self.compteur >= self.patience:
self.stop = True
# Utilisation dans la boucle d'entraînement
early_stopping = EarlyStopping(patience=15, chemin="best_model.pt")
for epoque in range(n_epoques):
# ... entraînement ...
early_stopping(val_loss, modele)
if early_stopping.stop:
print(f"Arrêt précoce à l'époque {epoque}")
break
# Recharger le meilleur modèle
modele.load_state_dict(torch.load("best_model.pt"))
Sauvegarde et chargement de modèles#
PyTorch distingue deux façons de sauvegarder un modèle. La recommandation officielle est de ne sauvegarder que le state_dict — le dictionnaire qui associe chaque couche à ses tenseurs de paramètres — et non l’objet modèle entier. Cela évite les problèmes de sérialisation liés aux changements de code source et rend la sauvegarde indépendante de la structure du projet.
# ── Sauvegarde complète d'un checkpoint ────────────────────────────────────
checkpoint = {
"epoque": epoque,
"modele": modele.state_dict(),
"optimiseur": optimiseur.state_dict(),
"scheduler": scheduler.state_dict(),
"val_loss": val_loss,
"historique": historique,
}
torch.save(checkpoint, "checkpoint_epoque_42.pt")
# ── Chargement d'un checkpoint pour reprendre l'entraînement ────────────────
checkpoint = torch.load("checkpoint_epoque_42.pt", map_location=device)
modele.load_state_dict(checkpoint["modele"])
optimiseur.load_state_dict(checkpoint["optimiseur"])
scheduler.load_state_dict(checkpoint["scheduler"])
epoque_reprise = checkpoint["epoque"]
# ── Chargement pour l'inférence seule ──────────────────────────────────────
modele_inférence = MonArchitecture(...)
modele_inférence.load_state_dict(torch.load("meilleur_modele.pt", map_location="cpu"))
modele_inférence.eval()
Courbes d’entraînement typiques
Voici comment tracer les courbes de perte et d’accuracy à partir de l’historique retourné par la boucle d’entraînement :
fig, axes = plt.subplots(1, 2, figsize=(13, 4))
axes[0].plot(historique["train_loss"], label="Entraînement")
axes[0].plot(historique["val_loss"], label="Validation")
axes[0].set_xlabel("Époque")
axes[0].set_ylabel("Perte (Cross-Entropy)")
axes[0].set_title("Évolution de la perte")
axes[0].legend()
axes[1].plot(historique["val_acc"])
axes[1].set_xlabel("Époque")
axes[1].set_ylabel("Exactitude")
axes[1].set_title("Exactitude de validation")
plt.tight_layout()
plt.show()
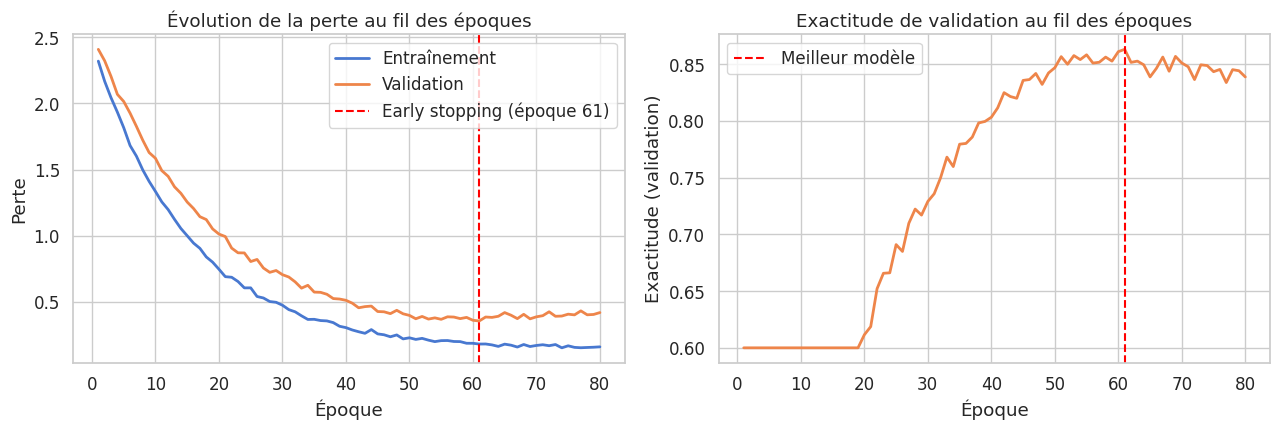
Résumé#
Ce chapitre a couvert l’ensemble du cycle d’entraînement d’un réseau de neurones PyTorch :
La boucle d’entraînement suit cinq étapes invariantes :
zero_grad(), passe avant, calcul de la perte,backward(),optimizer.step(). L’alternance entremodel.train()etmodel.eval()est indispensable pour le comportement correct du dropout et de la batch normalization.Le tandem
Dataset/DataLoaderdécouple la logique d’accès aux données de la boucle d’entraînement, gère le batching, le mélange et le chargement parallèle.pin_memory=Trueetnum_workers > 0sont essentiels pour éviter que le pipeline de données devienne un goulot d’étranglement.Les optimiseurs — SGD avec momentum, Adam, AdamW — diffèrent par leur façon d’adapter le taux d’apprentissage. AdamW est le choix par défaut recommandé pour les architectures modernes.
Les schedulers font varier dynamiquement le taux d’apprentissage.
OneCycleLRest particulièrement efficace pour accélérer la convergence tout en atteignant une meilleure performance finale.La régularisation — dropout, batch normalization, weight decay — réduit le sur-apprentissage. Appliquer le weight decay uniquement aux poids (pas aux biais ni aux paramètres de normalisation) est une bonne pratique souvent négligée.
L”early stopping arrête l’entraînement au moment optimal et préserve le meilleur modèle observé, évitant à la fois le sur-apprentissage et le gaspillage de temps de calcul.
La sauvegarde par
state_dictest la méthode recommandée : les checkpoints complets incluent l’état de l’optimiseur et du scheduler, permettant de reprendre un entraînement exactement là où il s’était arrêté.
Le chapitre suivant introduit les réseaux convolutifs, qui exploitent la structure spatiale des images pour réduire drastiquement le nombre de paramètres par rapport aux réseaux entièrement connectés.