Réseaux convolutifs#
<torch._C.Generator at 0x7f7188d86a90>
La convolution 2D#
Un réseau de neurones entièrement connecté (MLP) appliqué à une image de taille \(224 \times 224 \times 3\) aurait en première couche \(224 \times 224 \times 3 = 150\,528\) entrées. Avec une couche cachée de taille 4096, cela représente plus de 600 millions de paramètres pour la seule première couche — un chiffre absurde, à la fois du point de vue computationnel et du point de vue statistique (autant de paramètres nécessiteraient des dizaines de millions d’images pour éviter le sur-apprentissage). Les réseaux convolutifs (Convolutional Neural Networks, CNN) résolvent ce problème en exploitant trois propriétés fondamentales des images : la localité (les pixels proches sont fortement corrélés), l”équivariance par translation (un chat en haut à gauche et un chat en bas à droite doivent activer le même détecteur), et la hiérarchie des motifs (les arêtes forment des textures, les textures forment des parties, les parties forment des objets).
Convolution discrète 2D
La convolution discrète 2D d’une image \(X\) (de hauteur \(H\), largeur \(W\), \(C_{in}\) canaux) par un filtre (kernel) \(K\) de taille \(k_h \times k_w\) produit une carte d’activation (feature map) \(Y\) de taille \(H' \times W'\) définie par :
où \(s\) est la foulée (stride) et \(b\) un biais scalaire. Une couche convolutive apprend \(C_{out}\) filtres indépendants, produisant \(C_{out}\) cartes d’activation. La taille de la sortie vaut \(H' = \lfloor (H + 2p - k_h)/s \rfloor + 1\) avec \(p\) le rembourrage (padding).
La puissance de la convolution tient au partage des poids : le même filtre \(K\) est appliqué en chaque position \((i, j)\) de l’image. Une couche Conv2d(3, 64, kernel_size=3) n’a que \(64 \times (3 \times 3 \times 3 + 1) = 1\,792\) paramètres, quelle que soit la taille de l’image d’entrée.
import torch.nn as nn
# Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)
conv = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3,
stride=1, padding=1) # padding=1 conserve la taille spatiale
# Paramètres : 64 × (3 × 3 × 3 + 1) = 1 792
print(f"Paramètres : {sum(p.numel() for p in conv.parameters()):,}")
x = torch.randn(8, 3, 32, 32) # batch de 8 images RGB 32×32
sortie = conv(x)
print(f"Entrée : {x.shape}") # (8, 3, 32, 32)
print(f"Sortie : {sortie.shape}") # (8, 64, 32, 32) — même taille spatiale grâce à padding=1
Paramètres : 1,792
Entrée : torch.Size([8, 3, 32, 32])
Sortie : torch.Size([8, 64, 32, 32])
Note
Le choix du padding détermine si la taille spatiale est conservée après la convolution. padding=kernel_size//2 avec un stride de 1 conserve exactement la taille d’entrée (same padding). padding=0 réduit la taille de \(k-1\) pixels de chaque côté (valid padding). En pratique, on utilise padding=1 avec des filtres \(3 \times 3\) pour conserver la taille, et on réduit explicitement avec le pooling.
Pooling#
Le pooling réduit la taille spatiale des cartes d’activation, diminuant le nombre de calculs dans les couches suivantes et introduisant une forme d’invariance par translation locale. Les deux variantes les plus courantes sont le max-pooling (retient la valeur maximale dans chaque fenêtre) et l”average-pooling (retient la moyenne).
Max-pooling
Le max-pooling de taille \(k \times k\) avec stride \(s\) remplace chaque fenêtre de \(k \times k\) valeurs par leur maximum. Pour une entrée de taille \(H \times W\), la sortie a une taille \(\lfloor H/s \rfloor \times \lfloor W/s \rfloor\) (avec stride \(s = k\) typiquement). Le max-pooling est différentiable presque partout : le gradient est propagé uniquement à l’indice du maximum.
# MaxPool2d(kernel_size, stride=kernel_size par défaut)
pool = nn.MaxPool2d(kernel_size=2, stride=2) # divise la taille par 2
x = torch.randn(8, 64, 32, 32)
print(pool(x).shape) # (8, 64, 16, 16)
# AdaptiveAvgPool2d : produit toujours une sortie de taille fixée, quelle que soit l'entrée
adaptive_pool = nn.AdaptiveAvgPool2d((1, 1)) # Global Average Pooling → (B, C, 1, 1)
x = torch.randn(8, 512, 7, 7)
print(adaptive_pool(x).shape) # (8, 512, 1, 1)
print(adaptive_pool(x).squeeze(-1).squeeze(-1).shape) # (8, 512) — vecteur de classification
torch.Size([8, 64, 16, 16])
torch.Size([8, 512, 1, 1])
torch.Size([8, 512])
Le Global Average Pooling (GAP), qui réduit chaque carte d’activation à un scalaire en calculant sa moyenne globale, est devenu la norme pour connecter les couches convolutives au classifieur final. Il remplace avantageusement les larges couches entièrement connectées des architectures classiques, réduisant massivement le nombre de paramètres et améliorant la généralisation.
Architectures classiques#
LeNet-5#
LeNet-5 (LeCun et al., 1998) est l’ancêtre des CNN modernes, conçu pour la reconnaissance de chiffres manuscrits. Son architecture alterne deux blocs convolution + pooling suivis de couches entièrement connectées.
class LeNet5(nn.Module):
"""LeNet-5 adapté pour des images 32×32 en niveaux de gris."""
def __init__(self, n_classes=10):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), # (B, 1, 32, 32) → (B, 6, 28, 28)
nn.Tanh(),
nn.AvgPool2d(2), # (B, 6, 28, 28) → (B, 6, 14, 14)
nn.Conv2d(6, 16, kernel_size=5), # (B, 6, 14, 14) → (B, 16, 10, 10)
nn.Tanh(),
nn.AvgPool2d(2), # (B, 16, 10, 10) → (B, 16, 5, 5)
)
self.classifieur = nn.Sequential(
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120),
nn.Tanh(),
nn.Linear(120, 84),
nn.Tanh(),
nn.Linear(84, n_classes),
)
def forward(self, x):
return self.classifieur(self.features(x))
lenet = LeNet5()
print(f"Paramètres : {sum(p.numel() for p in lenet.parameters()):,}")
Paramètres : 61,706
VGG#
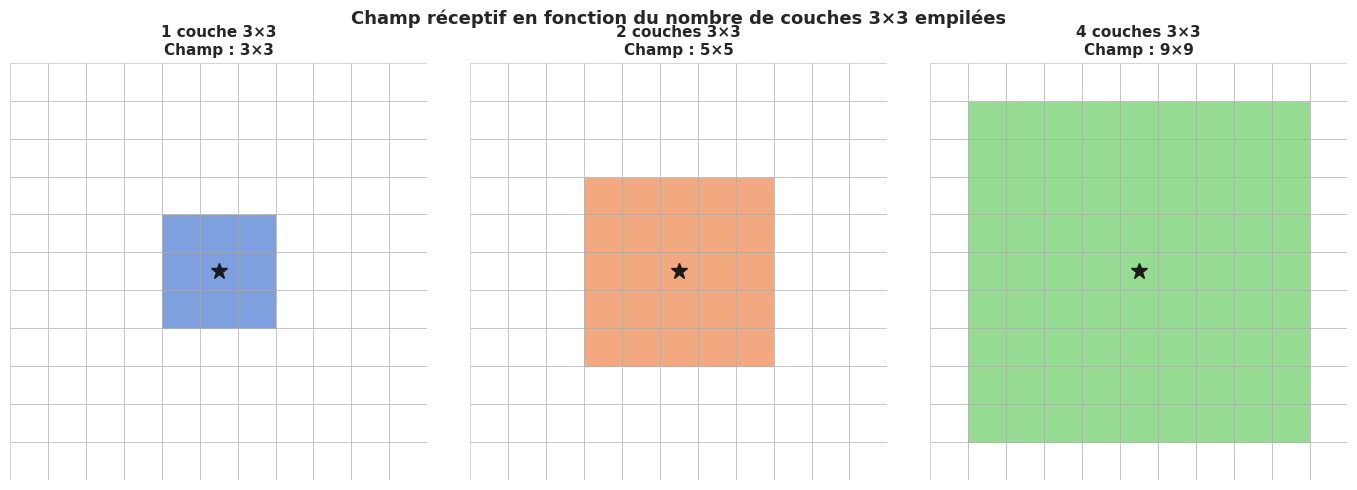
VGG (Simonyan & Zisserman, 2014) a démontré qu’empiler des convolutions \(3 \times 3\) en profondeur est plus efficace que des filtres plus grands. Deux convolutions \(3 \times 3\) ont le même champ réceptif qu’une convolution \(5 \times 5\), mais avec moins de paramètres et une non-linéarité supplémentaire.
def bloc_vgg(in_channels, out_channels, n_convolutions=2):
"""Bloc VGG : n_convolutions × (Conv 3×3 + BN + ReLU) + MaxPool."""
couches = []
for _ in range(n_convolutions):
couches += [
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels), # BN ajouté a posteriori pour stabiliser
nn.ReLU(inplace=True),
]
in_channels = out_channels
couches.append(nn.MaxPool2d(2, 2))
return nn.Sequential(*couches)
class VGG11(nn.Module):
def __init__(self, n_classes=1000):
super().__init__()
self.features = nn.Sequential(
bloc_vgg(3, 64, 1), # 224 → 112
bloc_vgg(64, 128, 1), # 112 → 56
bloc_vgg(128, 256, 2), # 56 → 28
bloc_vgg(256, 512, 2), # 28 → 14
bloc_vgg(512, 512, 2), # 14 → 7
)
self.classifieur = nn.Sequential(
nn.AdaptiveAvgPool2d((7, 7)),
nn.Flatten(),
nn.Linear(512 * 7 * 7, 4096), nn.ReLU(inplace=True), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Dropout(0.5),
nn.Linear(4096, n_classes),
)
def forward(self, x):
return self.classifieur(self.features(x))
ResNet#
ResNet (He et al., 2016) est l’architecture la plus influente de la décennie 2010. Grâce aux connexions résiduelles, elle permet d’entraîner des réseaux de 50, 101 ou même 152 couches sans dégradation des gradients. Le bloc résiduel de base implémente \(y = F(x) + x\) : si le réseau apprend \(F(x) = 0\), la sortie est simplement \(x\) (identité), ce qui rend les couches supplémentaires au pire inutiles et jamais nuisibles.
class BlocRésiduelBottleneck(nn.Module):
"""Bloc bottleneck de ResNet-50/101/152 : 1×1 → 3×3 → 1×1."""
expansion = 4
def __init__(self, in_channels, mid_channels, stride=1, downsample=None):
super().__init__()
out_channels = mid_channels * self.expansion
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, 1, bias=False),
nn.BatchNorm2d(mid_channels), nn.ReLU(inplace=True),
)
self.conv2 = nn.Sequential(
nn.Conv2d(mid_channels, mid_channels, 3, stride=stride,
padding=1, bias=False),
nn.BatchNorm2d(mid_channels), nn.ReLU(inplace=True),
)
self.conv3 = nn.Sequential(
nn.Conv2d(mid_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
)
self.downsample = downsample # projette x si les dimensions ne correspondent pas
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
identité = x if self.downsample is None else self.downsample(x)
out = self.conv3(self.conv2(self.conv1(x)))
return self.relu(out + identité)
Transfer Learning avec torchvision#
Le transfer learning (apprentissage par transfert) consiste à réutiliser un modèle pré-entraîné sur une grande tâche source (typiquement la classification d’images sur ImageNet, avec 1,2 million d’images et 1000 classes) pour résoudre une tâche cible différente et souvent plus petite. L’idée fondatrice est que les premières couches d’un CNN apprennent des détecteurs génériques — arêtes, textures, formes — transférables entre domaines.
Transfer learning
Le transfer learning exploite les représentations apprises par un modèle sur une tâche source \(\mathcal{T}_s\) pour améliorer les performances sur une tâche cible \(\mathcal{T}_t\). En vision, deux stratégies sont courantes : l”extraction de caractéristiques (feature extraction) gèle tous les paramètres du modèle pré-entraîné et n’entraîne qu’un nouveau classifieur final — adaptée quand les données cibles sont peu nombreuses. Le fine-tuning (affinage) dégèle certaines couches profondes et les réentraîne avec un faible taux d’apprentissage — adapté quand les données sont suffisantes et que la tâche cible diffère significativement de la source.
import torchvision.models as models
# ── Extraction de caractéristiques ─────────────────────────────────────────
modele = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V2)
# Geler tous les paramètres
for param in modele.parameters():
param.requires_grad = False
# Remplacer la tête de classification pour notre tâche (ex. 5 classes)
n_caractéristiques = modele.fc.in_features # 2048 pour ResNet-50
modele.fc = nn.Sequential(
nn.Dropout(0.3),
nn.Linear(n_caractéristiques, 5),
)
# Seul modele.fc est entraînable
# ── Fine-tuning partiel ────────────────────────────────────────────────────
modele_ft = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V2)
modele_ft.fc = nn.Linear(modele_ft.fc.in_features, 5)
# Dégeler uniquement les deux derniers blocs résiduels + la tête
for name, param in modele_ft.named_parameters():
if "layer3" in name or "layer4" in name or "fc" in name:
param.requires_grad = True
else:
param.requires_grad = False
# Taux d'apprentissage différencié : plus faible pour les couches pré-entraînées
optimiseur = torch.optim.AdamW([
{"params": modele_ft.layer3.parameters(), "lr": 1e-5},
{"params": modele_ft.layer4.parameters(), "lr": 1e-4},
{"params": modele_ft.fc.parameters(), "lr": 1e-3},
])
Note
torchvision.models propose des poids pré-entraînés avec l’API weights=. Il existe souvent plusieurs versions (IMAGENET1K_V1, IMAGENET1K_V2, DEFAULT) correspondant à des entraînements différents. Les poids V2 ou DEFAULT sont généralement les plus récents et les plus performants — ils ont souvent été entraînés avec des techniques d’augmentation avancées et des schedulers modernes.
Augmentation de données#
L”augmentation de données applique des transformations aléatoires aux images d’entraînement à chaque époque, augmentant artificiellement la diversité du jeu d’entraînement et réduisant le sur-apprentissage. L’idée est que la classe d’une image doit être invariante à la rotation modérée, au recadrage, au retournement horizontal ou à de légères variations de luminosité.
import torchvision.transforms.v2 as T
# Transformations d'entraînement — appliquées aléatoirement à chaque appel
transform_train = T.Compose([
T.RandomResizedCrop(224, scale=(0.8, 1.0)), # recadrage aléatoire et redimensionnement
T.RandomHorizontalFlip(p=0.5), # retournement horizontal 50% du temps
T.RandomRotation(degrees=15), # rotation ±15°
T.ColorJitter(brightness=0.3, contrast=0.3,
saturation=0.2, hue=0.1), # variation de couleur
T.RandomGrayscale(p=0.1), # conversion en niveaux de gris 10%
T.ToImage(),
T.ToDtype(torch.float32, scale=True),
T.Normalize(mean=[0.485, 0.456, 0.406], # normalisation ImageNet
std=[0.229, 0.224, 0.225]),
])
# Transformations de validation — déterministes
transform_val = T.Compose([
T.Resize(256),
T.CenterCrop(224),
T.ToImage(),
T.ToDtype(torch.float32, scale=True),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
La technique MixUp va plus loin en interpolant linéairement deux images et leurs étiquettes, forçant le réseau à produire des prédictions lisses entre les classes. CutMix remplace une région rectangulaire de l’image par la même région provenant d’une autre image. Ces augmentations avancées, disponibles dans torchvision.transforms.v2, améliorent significativement la robustesse et les performances des modèles modernes.
Pipeline complet de fine-tuning sur un jeu de données personnalisé
Voici la structure d’un fine-tuning de ResNet-18 sur un dataset personnalisé avec ImageFolder :
Résumé#
Ce chapitre a présenté les fondements théoriques et pratiques des réseaux convolutifs :
La convolution 2D exploite localité et partage des poids pour traiter les images avec un nombre de paramètres très réduit.
padding=kernel_size//2conserve la taille spatiale ; le pooling la réduit explicitement.Le max-pooling et l”average pooling réduisent la taille spatiale et introduisent une invariance locale. Le Global Average Pooling est la norme pour connecter les couches convolutives au classifieur.
L’évolution des architectures — de LeNet (1998) à VGG (2014) puis ResNet (2016) — illustre deux tendances : l’empilement de filtres \(3 \times 3\) pour augmenter le champ réceptif à moindre coût, et les connexions résiduelles pour entraîner des réseaux très profonds.
Le transfer learning est la stratégie dominante en vision pratique.
torchvision.modelsdonne accès à des dizaines de modèles pré-entraînés sur ImageNet. L’extraction de caractéristiques convient aux petits jeux de données ; le fine-tuning partiel avec taux d’apprentissage différenciés maximise les performances.L”augmentation de données — recadrage, retournement, variation de couleur, MixUp, CutMix — est indispensable pour prévenir le sur-apprentissage et améliorer la robustesse des modèles.
Le chapitre suivant aborde les réseaux récurrents, conçus pour traiter des séquences de longueur variable : texte, séries temporelles, signaux audio.