API Scikit-learn et Pipeline#
L’une des raisons fondamentales du succès de Scikit-learn n’est pas uniquement la qualité de ses algorithmes, mais la cohérence exceptionnelle de son interface. Que l’on entraîne une régression linéaire, un réseau de neurones peu profond, un algorithme de clustering ou un transformateur de variables, les objets exposent toujours le même contrat d’interface. Cette uniformité permet de remplacer un modèle par un autre sans modifier le reste du code, de composer des étapes en pipeline, et d’utiliser les outils de validation croisée et de recherche d’hyperparamètres de façon universelle.
Ce chapitre explore l’API de Scikit-learn dans sa profondeur : les trois rôles d’un estimateur (estimateur, transformateur, prédicteur), les conventions d’interface, la classe Pipeline, le ColumnTransformer pour les prétraitements hétérogènes, et les bonnes pratiques qui garantissent l’absence de fuite de données (data leakage) entre l’entraînement et la validation.
Estimateurs, transformateurs, prédicteurs#
L’API Scikit-learn repose sur trois rôles fondamentaux que peuvent jouer les objets. Ces rôles ne sont pas mutuellement exclusifs : de nombreux objets combinent deux ou trois rôles.
Estimateur (Estimator)
Un estimateur est tout objet qui apprend des paramètres à partir de données. Il implémente la méthode fit(X, y=None) qui prend une matrice d’observations X (et éventuellement un vecteur cible y) et stocke les paramètres appris dans des attributs de l’instance — conventionnellement nommés avec un suffixe _ (underscore) pour indiquer qu’ils ont été calculés lors du fit. Exemples : LinearRegression, StandardScaler, KMeans.
Transformateur (Transformer)
Un transformateur est un estimateur qui, après avoir été ajusté, peut produire une nouvelle représentation des données. Il implémente la méthode transform(X) qui applique la transformation apprise lors du fit à de nouvelles données. La méthode fit_transform(X) est un raccourci équivalent à fit(X) suivi de transform(X), souvent optimisé. Exemples : StandardScaler, PCA, OneHotEncoder, SimpleImputer.
Prédicteur (Predictor)
Un prédicteur est un estimateur qui, après avoir été ajusté, peut produire des prédictions sur de nouvelles données. Il implémente la méthode predict(X) qui retourne un vecteur de prédictions (classes ou valeurs numériques). Les classifieurs implémentent également predict_proba(X) qui retourne des probabilités par classe, et score(X, y) qui retourne la métrique d’évaluation par défaut (exactitude pour les classifieurs, R² pour les régresseurs). Exemples : LinearRegression, RandomForestClassifier, SVR.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_regression
# Génération de données synthétiques
X, y = make_regression(n_samples=200, n_features=5, noise=15, random_state=42)
# StandardScaler : estimateur + transformateur
scaler = StandardScaler()
print("Avant fit — attributs appris :")
print(f" mean_ existe : {hasattr(scaler, 'mean_')}")
scaler.fit(X)
print("Après fit :")
print(f" mean_ : {scaler.mean_.round(3)}")
print(f" scale_ : {scaler.scale_.round(3)}")
X_scaled = scaler.transform(X)
print(f"\nX original — μ={X.mean():.3f}, σ={X.std():.3f}")
print(f"X normalisé — μ={X_scaled.mean():.6f}, σ={X_scaled.std():.6f}")
Avant fit — attributs appris :
mean_ existe : False
Après fit :
mean_ : [ 0.069 -0.023 -0.005 -0.014 0.07 ]
scale_ : [1.028 0.997 0.963 0.932 0.966]
X original — μ=0.019, σ=0.979
X normalisé — μ=-0.000000, σ=1.000000
# LinearRegression : estimateur + prédicteur
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y,
test_size=0.2,
random_state=42)
reg = LinearRegression()
reg.fit(X_train, y_train)
print("Paramètres appris :")
print(f" coef_ : {reg.coef_.round(2)}")
print(f" intercept_ : {reg.intercept_:.3f}")
print()
y_pred = reg.predict(X_test)
score = reg.score(X_test, y_test)
print(f"R² sur le jeu de test : {score:.4f}")
print(f"Premières prédictions : {y_pred[:5].round(2)}")
Paramètres appris :
coef_ : [ 2.75 11.26 63.11 17.28 67.13]
intercept_ : 5.645
R² sur le jeu de test : 0.9780
Premières prédictions : [-32.68 84.63 -41.14 -48.38 -55.6 ]
Convention fit/transform/predict#
La convention d’interface de Scikit-learn impose des règles précises sur les types d’entrée et de sortie, les attributs accessibles avant et après fit, et la gestion des paramètres.
Note
Toutes les configurations d’un estimateur Scikit-learn sont des hyperparamètres passés au constructeur __init__. Aucun hyperparamètre ne doit être modifié après la création de l’objet via un attribut direct — on crée un nouvel estimateur. Les attributs terminant par _ (underscore) sont des paramètres appris disponibles uniquement après fit. Tenter d’appeler transform ou predict avant fit lève une exception NotFittedError. get_params() retourne le dictionnaire des hyperparamètres, et set_params(**params) permet de les modifier (utile pour GridSearchCV).
from sklearn.ensemble import RandomForestClassifier
from sklearn.exceptions import NotFittedError
clf = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
# get_params() retourne les hyperparamètres
print(clf.get_params())
# {'bootstrap': True, 'max_depth': 5, 'n_estimators': 100, ...}
# set_params() modifie des hyperparamètres (utile dans GridSearchCV)
clf.set_params(n_estimators=200, max_depth=8)
clf.fit(X_train, y_train) # y_train est binaire ici pour illustration
y_pred = clf.predict(X_test)
y_proba = clf.predict_proba(X_test) # probabilités par classe
La méthode fit_transform(X) est définie dans la classe TransformerMixin et appelle fit(X).transform(X). Elle est généralement plus efficace que les deux appels séparés car certaines implémentations peuvent réutiliser des calculs intermédiaires.
Cycle complet d’utilisation d’un transformateur
La règle d’or pour éviter toute fuite de données est de n’appeler fit que sur les données d’entraînement, puis d’appliquer transform séparément sur le jeu d’entraînement et le jeu de test. Cette règle est automatiquement respectée par le Pipeline.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# CORRECT : fit uniquement sur l'entraînement
X_train_sc = scaler.fit_transform(X_train) # fit + transform en une fois
X_test_sc = scaler.transform(X_test) # transform seulement (pas de fit !)
# INCORRECT : data leakage !
# scaler.fit(X) # ← utilise toutes les données
# X_train_sc = scaler.transform(X_train)
# X_test_sc = scaler.transform(X_test)
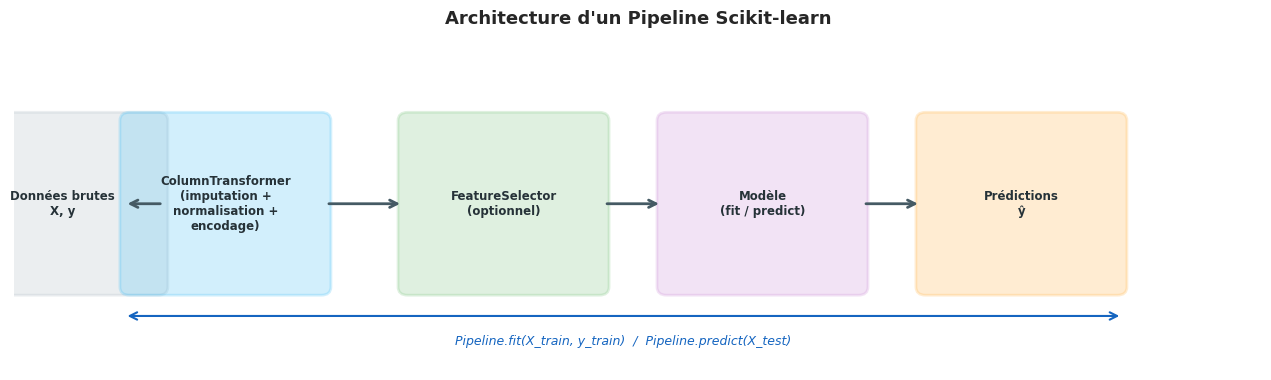
Pipeline#
La classe Pipeline enchaîne une séquence d’estimateurs en un seul objet. Toutes les étapes sauf la dernière doivent être des transformateurs (implémenter fit et transform). La dernière étape peut être un transformateur ou un prédicteur.
Pipeline
Un Pipeline est un méta-estimateur qui orchestre une séquence d’étapes. Lors d’un appel à pipeline.fit(X, y), chaque étape intermédiaire appelle fit_transform(X, y) et passe le résultat à l’étape suivante. La dernière étape appelle fit(X_transformed, y). Lors d’un appel à pipeline.predict(X), chaque étape intermédiaire appelle transform(X), et la dernière étape appelle predict(X_transformed). Le Pipeline garantit mécaniquement l’absence de fuite de données lorsqu’il est utilisé dans une validation croisée.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split, cross_val_score
X, y = make_regression(n_samples=300, n_features=10, noise=20, random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Construction du Pipeline
pipe = Pipeline([
('normalisation', StandardScaler()), # étape 1 : centrage-réduction
('regression', Ridge(alpha=1.0)), # étape 2 : prédicteur
])
# Interface identique à un estimateur ordinaire
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_test)
print(f"R² sur le test : {pipe.score(X_test, y_test):.4f}")
# Validation croisée : fit/transform respectés automatiquement
scores_cv = cross_val_score(pipe, X, y, cv=5, scoring='r2')
print(f"R² en validation croisée (5 folds) : {scores_cv.mean():.4f} ± {scores_cv.std():.4f}")
# Accès aux étapes et à leurs paramètres appris
print(f"\nMoyennes apprises par le scaler : {pipe['normalisation'].mean_[:3].round(3)}")
print(f"Coefficients de Ridge : {pipe['regression'].coef_[:3].round(3)}")
R² sur le test : 0.9865
R² en validation croisée (5 folds) : 0.9885 ± 0.0017
Moyennes apprises par le scaler : [-0.002 -0.031 -0.04 ]
Coefficients de Ridge : [18.326 69.608 80.784]
make_pipeline — syntaxe abrégée#
make_pipeline() crée un Pipeline en nommant automatiquement les étapes d’après le nom de la classe en minuscules, ce qui évite de répéter les noms explicitement pour les pipelines simples.
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import Lasso
pipe = make_pipeline(
StandardScaler(),
PolynomialFeatures(degree=2, include_bias=False),
Lasso(alpha=0.1),
)
# Les noms des étapes sont générés automatiquement
print(pipe.steps)
# [('standardscaler', StandardScaler()),
# ('polynomialfeatures', PolynomialFeatures(degree=2, ...)),
# ('lasso', Lasso(alpha=0.1))]
ColumnTransformer#
Dans les problèmes réels, les DataFrames contiennent des colonnes de natures différentes : des variables numériques qui nécessitent une normalisation, des variables catégorielles qui nécessitent un encodage, des dates qui nécessitent une extraction de caractéristiques. ColumnTransformer permet d’appliquer des transformations différentes à différentes colonnes en une seule étape.
ColumnTransformer
ColumnTransformer applique des transformations différentes à des sous-ensembles de colonnes. Chaque entrée de la liste transformers est un triplet (nom, transformateur, colonnes). La valeur 'drop' supprime les colonnes spécifiées. La valeur 'passthrough' les passe sans transformation. Par défaut, toutes les colonnes non mentionnées sont supprimées (comportement contrôlé par remainder='drop' ou remainder='passthrough').
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# Jeu de données mixte
df_mix = pd.DataFrame({
'age': [25, 32, np.nan, 45, 28],
'salaire': [38000, 52000, 61000, np.nan, 44000],
'ville': ['Paris', 'Lyon', 'Paris', 'Marseille', 'Lyon'],
'diplôme': ['Licence', 'Master', 'Master', 'Doctorat', 'Licence'],
'cible': [0, 1, 1, 1, 0],
})
X = df_mix.drop('cible', axis=1)
y = df_mix['cible']
# Colonnes par type
cols_num = ['age', 'salaire']
cols_cat = ['ville', 'diplôme']
# Transformateurs par type
num_transformer = Pipeline([
('imputation', SimpleImputer(strategy='median')),
('normalisation', StandardScaler()),
])
cat_transformer = Pipeline([
('imputation', SimpleImputer(strategy='most_frequent')),
('encodage', OneHotEncoder(handle_unknown='ignore', sparse_output=False)),
])
# Assemblage
preprocesseur = ColumnTransformer(transformers=[
('num', num_transformer, cols_num),
('cat', cat_transformer, cols_cat),
], remainder='drop')
X_transformed = preprocesseur.fit_transform(X)
print(f"Shape avant transformation : {X.shape}")
print(f"Shape après transformation : {X_transformed.shape}")
# Noms des colonnes produites
noms_num = cols_num # inchangés après StandardScaler
noms_cat = preprocesseur.named_transformers_['cat']['encodage'].get_feature_names_out(cols_cat).tolist()
print(f"\nColonnes produites : {noms_num + noms_cat}")
Shape avant transformation : (5, 4)
Shape après transformation : (5, 8)
Colonnes produites : ['age', 'salaire', 'ville_Lyon', 'ville_Marseille', 'ville_Paris', 'diplôme_Doctorat', 'diplôme_Licence', 'diplôme_Master']
Pipeline complet avec ColumnTransformer#
La combinaison d’un ColumnTransformer et d’un modèle dans un Pipeline constitue le schéma de référence pour les projets de machine learning sur données réelles.
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
pipe_complet = Pipeline([
('preprocessing', preprocesseur),
('classifieur', LogisticRegression(max_iter=1000)),
])
# Le pipeline entier peut s'utiliser avec cross_val_score
scores = cross_val_score(pipe_complet, X, y, cv=3, scoring='accuracy')
print(f"Exactitude (cross-val) : {scores.mean():.3f} ± {scores.std():.3f}")
Hyperparamètres et GridSearchCV#
L’un des avantages majeurs des Pipeline est leur intégration transparente avec les outils de recherche d’hyperparamètres. La convention de nommage étape__paramètre (double underscore) permet de cibler n’importe quel hyperparamètre d’une étape.
from sklearn.model_selection import GridSearchCV
param_grid = {
'preprocessing__num__normalisation__with_std': [True, False],
'classifieur__C': [0.01, 0.1, 1.0, 10.0],
'classifieur__penalty': ['l1', 'l2'],
}
grid_search = GridSearchCV(
pipe_complet,
param_grid,
cv=5,
scoring='f1',
n_jobs=-1, # paralléliser sur tous les cœurs
verbose=1,
)
grid_search.fit(X, y)
print(f"Meilleurs paramètres : {grid_search.best_params_}")
print(f"Meilleur score F1 : {grid_search.best_score_:.4f}")
clone — copie d’un estimateur non ajusté#
La fonction clone() crée une copie d’un estimateur avec les mêmes hyperparamètres mais sans les paramètres appris. Elle est utile pour initialiser plusieurs estimateurs identiques (par exemple dans un ensemble), ou pour s’assurer qu’un estimateur est dans son état initial.
from sklearn.base import clone
scaler_ajuste = StandardScaler().fit(X_train)
print(f"Ajusté : {hasattr(scaler_ajuste, 'mean_')}") # True
scaler_clone = clone(scaler_ajuste)
print(f"Cloné : {hasattr(scaler_clone, 'mean_')}") # False — paramètres appris supprimés
print(f"Mêmes hyperparamètres : {scaler_clone.get_params() == scaler_ajuste.get_params()}") # True
Note
Il ne faut pas confondre clone() et copy.deepcopy(). deepcopy copie l’objet en entier, y compris les paramètres appris. clone ne copie que les hyperparamètres et retourne un objet non ajusté. Pour dupliquer un modèle déjà entraîné, deepcopy est approprié. Pour réinitialiser un modèle, clone est le bon outil.
Résumé#
Ce chapitre a présenté l’architecture et les conventions de l’API Scikit-learn :
Scikit-learn repose sur trois rôles d’interface : l”estimateur (
fit), le transformateur (transform), et le prédicteur (predict). Un objet peut combiner plusieurs rôles.La convention
fit/transform/predictest universelle : les paramètres appris sont stockés dans des attributs suffixés_, les hyperparamètres sont passés au constructeur, etget_params()/set_params()permettent leur accès et modification programmatique.Le
Pipelineenchaîne des transformations et un prédicteur final en un seul objet cohérent. Il garantit l’absence de fuite de données lors de la validation croisée, carfit_transformn’est appelé que sur les données d’entraînement à chaque fold.make_pipelineest la syntaxe abrégée duPipelineavec nommage automatique des étapes.ColumnTransformerpermet d’appliquer des transformations différentes à des colonnes différentes, ce qui est indispensable pour les DataFrames avec des types mixtes. La combinaisonColumnTransformer+Pipeline+ modèle est le schéma standard pour les projets réels.clone()crée une copie non ajustée d’un estimateur, utile pour réinitialiser ou dupliquer des objets.