Xarray — données multidimensionnelles#
Pourquoi Xarray ?#
NumPy est une bibliothèque remarquablement efficace pour manipuler des tableaux multidimensionnels. Cependant, ses tableaux sont anonymes : les axes n’ont pas de nom, les positions n’ont pas de coordonnées, et rien n’empêche de confondre l’axe des latitudes avec celui des longitudes. Pour un tableau de forme (12, 180, 360), il est impossible de savoir, sans documentation externe, si la première dimension représente les mois, les latitudes ou autre chose.
Ce problème s’aggrave dès que les données ont des coordonnées irrégulières, des trous, ou que l’on veut effectuer des opérations d’alignement entre plusieurs jeux de données provenant de sources différentes. C’est précisément le cas des données scientifiques les plus courantes : données climatiques (température en fonction du temps, de la latitude et de la longitude), données de télédétection, simulations numériques, imagerie médicale.
Xarray résout ces problèmes en ajoutant une couche d’abstraction au-dessus de NumPy : les dimensions ont des noms, les coordonnées sont des valeurs explicites associées à chaque dimension, et les opérations respectent ces métadonnées. Xarray s’inspire directement de Pandas — dont il adopte la philosophie des données étiquetées — mais l’étend au cas multidimensionnel.
Xarray
Xarray est une bibliothèque Python conçue pour manipuler des données multidimensionnelles étiquetées. Elle fournit deux structures principales : DataArray (un tableau N-dimensionnel avec dimensions nommées et coordonnées) et Dataset (un dictionnaire de DataArray partageant les mêmes coordonnées). Xarray supporte nativement le format NetCDF, le calcul parallèle avec Dask et le stockage cloud avec Zarr.
Les cas d’usage typiques de Xarray incluent :
Données climatiques et météorologiques : température, pression, précipitations en fonction du temps et de la position géographique.
Données géospatiales raster : images satellitaires avec bandes spectrales, résolution spatiale et horodatage.
Simulations numériques : sorties de modèles de physique ou de chimie en plusieurs dimensions.
Données de séries temporelles multivariées avec coordonnées irrégulières ou alignement nécessaire.
DataArray — le tableau étiqueté#
Le DataArray est l’élément de base de Xarray. Il encapsule un tableau NumPy en y associant :
des dimensions nommées (ex. :
'time','lat','lon') ;des coordonnées : des tableaux de valeurs associées à chaque dimension ;
des attributs : métadonnées libres (unités, source, description…).
import xarray as xr
import numpy as np
import pandas as pd
# Création d'un DataArray de températures fictives
np.random.seed(42)
temps = pd.date_range('2024-01', periods=12, freq='ME')
latitudes = np.arange(-90, 91, 15, dtype=float) # 13 valeurs
longitudes = np.arange(-180, 181, 30, dtype=float) # 13 valeurs
# Données : 12 mois × 13 lat × 13 lon
data_temp = (
15 # température de base
- 0.5 * np.abs(latitudes)[np.newaxis, :, np.newaxis] # gradient latitudinal
+ 5 * np.sin(np.arange(12)[:, np.newaxis, np.newaxis] * np.pi / 6) # cycle saisonnier
+ np.random.randn(12, 13, 13) * 2 # bruit aléatoire
)
da_temp = xr.DataArray(
data_temp,
dims=['time', 'lat', 'lon'],
coords={
'time': temps,
'lat': latitudes,
'lon': longitudes,
},
attrs={
'units': '°C',
'long_name': 'Température de surface',
'source': 'Simulation fictive',
},
name='temperature',
)
print(da_temp)
<xarray.DataArray 'temperature' (time: 12, lat: 13, lon: 13)> Size: 16kB
array([[[-29.00657169, -30.2765286 , -28.70462292, ..., -30.92683539,
-30.93145951, -29.51607546],
[-26.32656049, -25.94983567, -23.62457506, ..., -25.34949637,
-23.58876545, -22.27815482],
[-17.30198715, -14.24860396, -16.20127738, ..., -14.58227281,
-18.91934025, -17.6563721 ],
...,
[-18.10132686, -14.86287405, -17.12460743, ..., -14.54508013,
-12.38571449, -18.21496647],
[-22.13073228, -21.98023441, -20.93635426, ..., -22.03549261,
-21.91385505, -23.92870284],
[-26.26845098, -29.05233416, -32.38260699, ..., -28.35587968,
-26.20641403, -30.49077623]],
[[-29.00747233, -29.27902886, -29.13162057, ..., -22.05966167,
-26.2486653 , -29.21431511],
[-22.141785 , -19.03505517, -20.44692557, ..., -19.57181251,
-22.49147756, -19.65363815],
[-11.72936524, -14.26771487, -12.19254979, ..., -14.37565008,
-11.46992947, -11.4724281 ],
...
[-19.59264095, -19.17642325, -19.77983898, ..., -17.91369817,
-18.86369476, -17.42385375],
[-26.25587869, -28.05500177, -26.10711997, ..., -26.64443722,
-26.51041423, -28.8854773 ],
[-31.79871134, -36.06247672, -32.39121262, ..., -31.54519642,
-34.83022005, -33.75273976]],
[[-31.97935632, -32.76861748, -30.87838345, ..., -33.32162858,
-34.71140934, -32.92984206],
[-25.61606857, -23.44067894, -22.37938251, ..., -27.46869774,
-26.18492852, -25.05281151],
[-16.93967768, -19.11920704, -16.65187791, ..., -18.24002206,
-18.01759213, -14.30270566],
...,
[-16.63615491, -15.89918095, -15.99141734, ..., -18.98980529,
-18.85035655, -17.78903734],
[-26.58483984, -25.61592306, -28.78722933, ..., -26.5382847 ,
-26.8798062 , -23.34105032],
[-32.88765228, -33.02902968, -36.50772473, ..., -32.13230091,
-28.89897764, -30.02210729]]], shape=(12, 13, 13))
Coordinates:
* time (time) datetime64[us] 96B 2024-01-31 2024-02-29 ... 2024-12-31
* lat (lat) float64 104B -90.0 -75.0 -60.0 -45.0 ... 45.0 60.0 75.0 90.0
* lon (lon) float64 104B -180.0 -150.0 -120.0 -90.0 ... 120.0 150.0 180.0
Attributes:
units: °C
long_name: Température de surface
source: Simulation fictive
Note
Le DataArray affiche automatiquement son résumé : dimensions, coordonnées, attributs et un aperçu des données. Cette transparence est l’un des grands avantages de Xarray sur NumPy : on sait toujours avec quoi on travaille, sans avoir à consulter de documentation externe. Les attributs (attrs) permettent de conserver les métadonnées (unités, source, conventions) tout au long du pipeline de traitement.
Dataset — plusieurs variables partageant les mêmes coordonnées#
Un Dataset est un conteneur de plusieurs DataArray partageant les mêmes coordonnées. Il est analogue à un DataFrame Pandas, mais pour des données multidimensionnelles : là où Pandas associe des colonnes à des valeurs 1D, Xarray associe des variables à des tableaux ND.
# Ajout d'une variable précipitations
data_precip = (
50
+ 30 * np.cos(latitudes)[np.newaxis, :, np.newaxis]
+ 20 * np.random.rand(12, 13, 13)
).clip(min=0)
da_precip = xr.DataArray(
data_precip,
dims=['time', 'lat', 'lon'],
coords={'time': temps, 'lat': latitudes, 'lon': longitudes},
attrs={'units': 'mm/mois', 'long_name': 'Précipitations'},
name='precipitation',
)
# Création du Dataset
ds = xr.Dataset({
'temperature': da_temp,
'precipitation': da_precip,
})
print(ds)
<xarray.Dataset> Size: 33kB
Dimensions: (time: 12, lat: 13, lon: 13)
Coordinates:
* time (time) datetime64[us] 96B 2024-01-31 ... 2024-12-31
* lat (lat) float64 104B -90.0 -75.0 -60.0 -45.0 ... 60.0 75.0 90.0
* lon (lon) float64 104B -180.0 -150.0 -120.0 ... 120.0 150.0 180.0
Data variables:
temperature (time, lat, lon) float64 16kB -29.01 -30.28 ... -28.9 -30.02
precipitation (time, lat, lon) float64 16kB 37.99 50.21 ... 46.28 38.74
# Accéder à une variable
print("Variable 'temperature' :")
print(ds['temperature'])
print()
# Informations sur le Dataset
print("Dimensions :", dict(ds.sizes))
print("Variables :", list(ds.data_vars))
print("Coordonnées:", list(ds.coords))
Variable 'temperature' :
<xarray.DataArray 'temperature' (time: 12, lat: 13, lon: 13)> Size: 16kB
array([[[-29.00657169, -30.2765286 , -28.70462292, ..., -30.92683539,
-30.93145951, -29.51607546],
[-26.32656049, -25.94983567, -23.62457506, ..., -25.34949637,
-23.58876545, -22.27815482],
[-17.30198715, -14.24860396, -16.20127738, ..., -14.58227281,
-18.91934025, -17.6563721 ],
...,
[-18.10132686, -14.86287405, -17.12460743, ..., -14.54508013,
-12.38571449, -18.21496647],
[-22.13073228, -21.98023441, -20.93635426, ..., -22.03549261,
-21.91385505, -23.92870284],
[-26.26845098, -29.05233416, -32.38260699, ..., -28.35587968,
-26.20641403, -30.49077623]],
[[-29.00747233, -29.27902886, -29.13162057, ..., -22.05966167,
-26.2486653 , -29.21431511],
[-22.141785 , -19.03505517, -20.44692557, ..., -19.57181251,
-22.49147756, -19.65363815],
[-11.72936524, -14.26771487, -12.19254979, ..., -14.37565008,
-11.46992947, -11.4724281 ],
...
[-19.59264095, -19.17642325, -19.77983898, ..., -17.91369817,
-18.86369476, -17.42385375],
[-26.25587869, -28.05500177, -26.10711997, ..., -26.64443722,
-26.51041423, -28.8854773 ],
[-31.79871134, -36.06247672, -32.39121262, ..., -31.54519642,
-34.83022005, -33.75273976]],
[[-31.97935632, -32.76861748, -30.87838345, ..., -33.32162858,
-34.71140934, -32.92984206],
[-25.61606857, -23.44067894, -22.37938251, ..., -27.46869774,
-26.18492852, -25.05281151],
[-16.93967768, -19.11920704, -16.65187791, ..., -18.24002206,
-18.01759213, -14.30270566],
...,
[-16.63615491, -15.89918095, -15.99141734, ..., -18.98980529,
-18.85035655, -17.78903734],
[-26.58483984, -25.61592306, -28.78722933, ..., -26.5382847 ,
-26.8798062 , -23.34105032],
[-32.88765228, -33.02902968, -36.50772473, ..., -32.13230091,
-28.89897764, -30.02210729]]], shape=(12, 13, 13))
Coordinates:
* time (time) datetime64[us] 96B 2024-01-31 2024-02-29 ... 2024-12-31
* lat (lat) float64 104B -90.0 -75.0 -60.0 -45.0 ... 45.0 60.0 75.0 90.0
* lon (lon) float64 104B -180.0 -150.0 -120.0 -90.0 ... 120.0 150.0 180.0
Attributes:
units: °C
long_name: Température de surface
source: Simulation fictive
Dimensions : {'time': 12, 'lat': 13, 'lon': 13}
Variables : ['temperature', 'precipitation']
Coordonnées: ['time', 'lat', 'lon']
Dataset Xarray
Un Dataset Xarray est un dictionnaire ordonné de DataArray partageant un système de coordonnées commun. Il peut contenir des variables de dimensions différentes — par exemple, une variable 3D (time, lat, lon) et une variable 1D (lat) représentant l’altitude — à condition que les coordonnées partagées soient identiques. Le Dataset est le conteneur naturel pour représenter un fichier NetCDF ou une sortie de modèle climatique.
Sélection et indexation#
Xarray propose deux méthodes de sélection complémentaires : .sel() pour sélectionner par valeur de coordonnée et .isel() pour sélectionner par position entière (comme NumPy).
# Sélection par valeur de coordonnée
temp_paris = da_temp.sel(lat=45, lon=0, method='nearest')
print("Température à lat≈45°N, lon≈0° :")
print(temp_paris.values.round(2))
print()
# Sélection d'une plage
temp_europe = da_temp.sel(lat=slice(30, 75), lon=slice(-15, 45))
print("Shape sous-région Europe :", temp_europe.shape)
print()
# Sélection par position
temp_jan = da_temp.isel(time=0)
print("Température en janvier (isel) :", temp_jan.shape)
print()
# Sélection temporelle intuitive
temp_ete = da_temp.sel(time=slice('2024-06', '2024-08'))
print("Température été 2024 :", temp_ete.shape)
Température à lat≈45°N, lon≈0° :
[-10.3 -6.18 -3.1 -5.88 -3.11 -5.08 -9.96 -9.94 -10.53 -14.62
-10.04 -11.25]
Shape sous-région Europe : (12, 4, 2)
Température en janvier (isel) : (13, 13)
Température été 2024 : (3, 13, 13)
Interpolation#
.interp() interpole les valeurs à des coordonnées arbitraires, ce qui est très utile pour regriller des données :
# Interpolation à une latitude et longitude précises
temp_interpol = da_temp.interp(lat=48.85, lon=2.35) # Paris approximatif
print("Températures interpolées (Paris) :")
print(temp_interpol.values.round(2))
Températures interpolées (Paris) :
[-11.66 -7.53 -4.36 -7.29 -4.25 -6.98 -11.59 -11.97 -13.55 -15.25
-13.02 -12.18]
Opérations#
Agrégation le long d’une dimension#
# Moyenne temporelle (climatologie annuelle)
temp_climatologie = da_temp.mean(dim='time')
print("Climatologie (mean sur time) :", temp_climatologie.shape)
# Moyenne zonale (sur les longitudes)
temp_zonale = da_temp.mean(dim='lon')
print("Profil zonal (mean sur lon) :", temp_zonale.shape)
# Écart-type interannuel
temp_std = da_temp.std(dim='time')
print("Variabilité (std sur time) :", temp_std.shape)
Climatologie (mean sur time) : (13, 13)
Profil zonal (mean sur lon) : (12, 13)
Variabilité (std sur time) : (13, 13)
Broadcasting automatique#
Xarray effectue automatiquement le broadcasting en alignant les dimensions par leur nom, ce qui évite les erreurs classiques de NumPy dues aux dimensions implicites :
# Anomalie par rapport à la moyenne temporelle (broadcasting automatique)
anomalie = da_temp - da_temp.mean(dim='time')
print("Anomalie shape :", anomalie.shape)
print("Min anomalie :", float(anomalie.min().values.round(2)))
print("Max anomalie :", float(anomalie.max().values.round(2)))
Anomalie shape : (12, 13, 13)
Min anomalie : -11.45
Max anomalie : 9.89
groupby sur les coordonnées#
Xarray supporte groupby sur n’importe quelle coordonnée, y compris des composantes dérivées des dates :
# Climatologie mensuelle (moyenne de chaque mois sur tous les pixels)
# Ici, comme nous n'avons qu'une année, on regroupe par mois
temp_par_saison = da_temp.groupby('time.season').mean('time')
print("Température par saison :", temp_par_saison)
Température par saison : <xarray.DataArray 'temperature' (season: 4, lat: 13, lon: 13)> Size: 5kB
array([[[-2.99978001e+01, -3.07747250e+01, -2.95715423e+01,
-2.85070554e+01, -3.10943556e+01, -2.91020706e+01,
-2.95040639e+01, -2.87913448e+01, -2.85928234e+01,
-3.05420421e+01, -2.87693752e+01, -3.06305114e+01,
-3.05534109e+01],
[-2.46948047e+01, -2.28085233e+01, -2.21502944e+01,
-2.17687645e+01, -2.23497887e+01, -2.32933832e+01,
-2.51283571e+01, -2.30700457e+01, -2.23049597e+01,
-2.08069935e+01, -2.41300022e+01, -2.40883905e+01,
-2.23282015e+01],
[-1.53236767e+01, -1.58785086e+01, -1.50152350e+01,
-1.54715496e+01, -1.61727528e+01, -1.31624335e+01,
-1.46308603e+01, -1.52740304e+01, -1.38221752e+01,
-1.67912507e+01, -1.57326483e+01, -1.61356206e+01,
-1.44771686e+01],
[-6.65144775e+00, -4.63618816e+00, -6.54052454e+00,
-7.04260142e+00, -6.28265153e+00, -7.80499236e+00,
-8.26161040e+00, -7.00263508e+00, -8.35771943e+00,
-8.17997852e+00, -9.79488581e+00, -7.13406586e+00,
-5.05860581e+00],
...
[-1.00428496e+01, -1.30214794e+01, -1.18471014e+01,
-1.15233231e+01, -1.19988581e+01, -1.12002886e+01,
-1.17316005e+01, -1.20275325e+01, -1.24926207e+01,
-1.34224697e+01, -1.20329017e+01, -9.98620817e+00,
-1.25736710e+01],
[-1.82724159e+01, -1.96390180e+01, -1.97889764e+01,
-1.91393699e+01, -2.05834930e+01, -2.03203561e+01,
-2.04190566e+01, -1.84421021e+01, -1.92271298e+01,
-1.69573087e+01, -1.95361525e+01, -2.06894763e+01,
-1.82951349e+01],
[-2.46599436e+01, -2.61026193e+01, -2.66730397e+01,
-2.74697104e+01, -2.60256136e+01, -2.61921749e+01,
-2.77189078e+01, -2.79291252e+01, -2.85714058e+01,
-2.81476312e+01, -2.62167563e+01, -2.66974691e+01,
-2.62902256e+01],
[-3.26364642e+01, -3.34803073e+01, -3.49559862e+01,
-3.41285747e+01, -3.54782482e+01, -3.52167031e+01,
-3.51880568e+01, -3.48078401e+01, -3.20856104e+01,
-3.48897019e+01, -3.41737926e+01, -3.32951954e+01,
-3.37195364e+01]]])
Coordinates:
* season (season) object 32B 'DJF' 'JJA' 'MAM' 'SON'
* lat (lat) float64 104B -90.0 -75.0 -60.0 -45.0 ... 45.0 60.0 75.0 90.0
* lon (lon) float64 104B -180.0 -150.0 -120.0 -90.0 ... 120.0 150.0 180.0
Attributes:
units: °C
long_name: Température de surface
source: Simulation fictive
Cycle saisonnier
L’extraction du cycle saisonnier est une opération fondamentale en climatologie :
# Température moyenne par mois (cycle saisonnier)
cycle_mensuel = da_temp.groupby('time.month').mean('time')
# Anomalie saisonnière
anomalie_saisonniere = da_temp.groupby('time.month') - cycle_mensuel
Cette syntaxe, qui ressemble à groupby de Pandas, effectue automatiquement l’alignement sur la dimension time et retourne un DataArray de même forme que l’entrée.
Entrées/sorties#
NetCDF — le format standard des sciences de la Terre#
NetCDF (Network Common Data Form) est le format de référence pour les données scientifiques multidimensionnelles. Xarray le lit et l’écrit nativement :
# Lecture d'un fichier NetCDF
ds = xr.open_dataset('donnees_climatiques.nc')
# Écriture
ds.to_netcdf('sortie.nc')
# Lecture de plusieurs fichiers en un seul Dataset (données réparties par année)
ds_multi = xr.open_mfdataset('donnees_*.nc', combine='by_coords')
Zarr — pour les données cloud#
Zarr est un format de stockage optimisé pour le cloud et le calcul parallèle. Contrairement à NetCDF, Zarr stocke les données en chunks pouvant être lus indépendamment, ce qui permet de ne charger que les parties nécessaires :
# Écriture au format Zarr
ds.to_zarr('donnees.zarr', mode='w')
# Lecture (lazy, avec Dask)
ds_zarr = xr.open_zarr('donnees.zarr')
Intégration avec Pandas#
Xarray s’intègre naturellement avec Pandas pour les analyses 1D ou 2D :
# Convertir un DataArray 1D en Series Pandas
temp_serie = da_temp.sel(lat=45, lon=0, method='nearest').to_series()
print(type(temp_serie))
print(temp_serie.round(2))
<class 'pandas.Series'>
time
2024-01-31 -10.30
2024-02-29 -6.18
2024-03-31 -3.10
2024-04-30 -5.88
2024-05-31 -3.11
2024-06-30 -5.08
2024-07-31 -9.96
2024-08-31 -9.94
2024-09-30 -10.53
2024-10-31 -14.62
2024-11-30 -10.04
2024-12-31 -11.25
Freq: ME, Name: temperature, dtype: float64
Visualisation — Dataset climatique fictif#
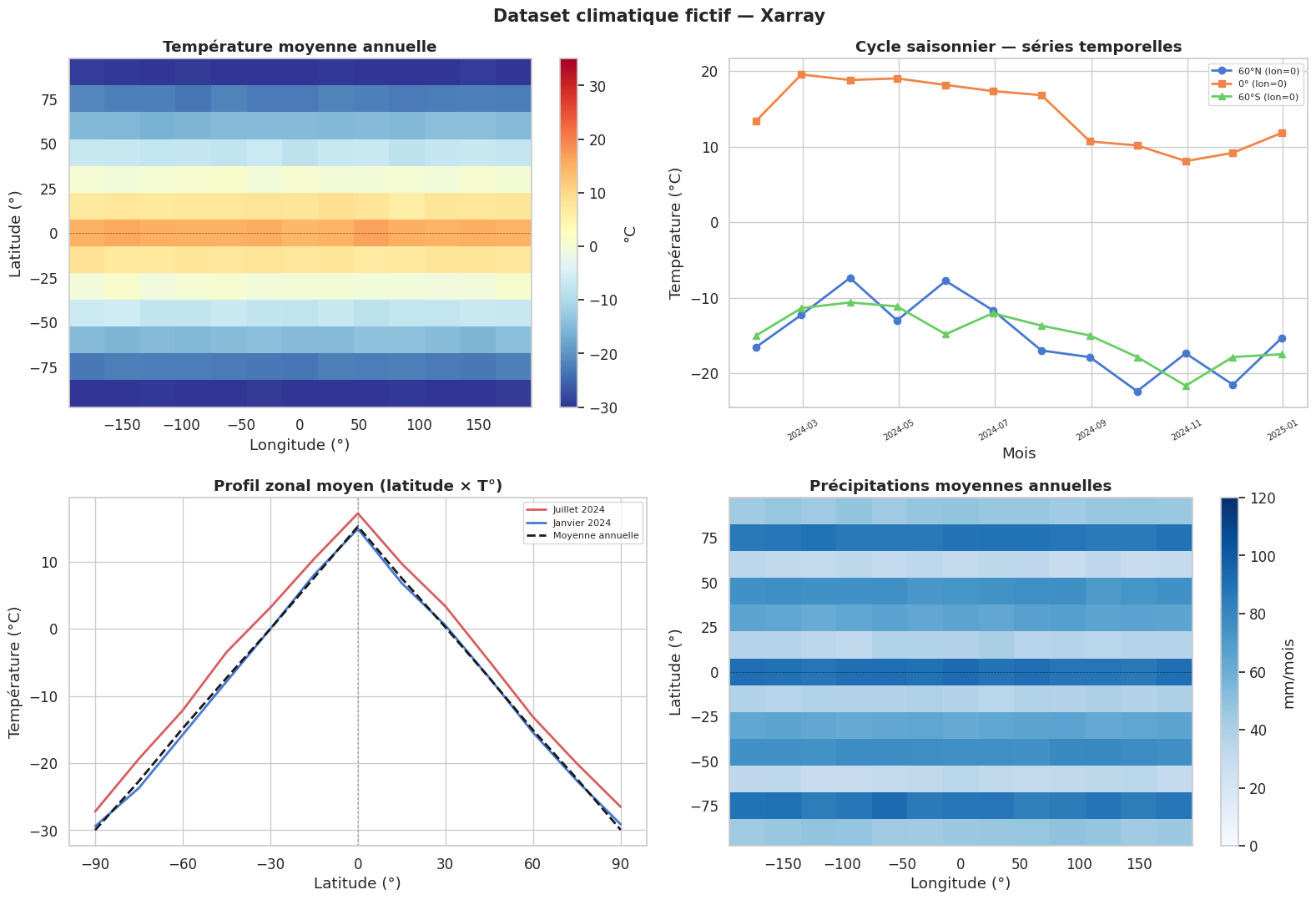
Résumé#
Ce chapitre a présenté Xarray, la bibliothèque de référence pour les données multidimensionnelles étiquetées :
Pourquoi Xarray : les tableaux NumPy sont anonymes — les axes n’ont pas de nom et les positions n’ont pas de coordonnées. Xarray résout ce problème pour les données scientifiques (climatologie, géospatial, simulations) en ajoutant des dimensions nommées et des coordonnées explicites.
Le
DataArrayest l’unité de base : un tableau N-dimensionnel avecdims,coordsetattrs. Il conserve les métadonnées tout au long du pipeline.Le
Datasetregroupe plusieurs variables partageant les mêmes coordonnées, à l’image d’un fichier NetCDF ou d’une sortie de modèle.La sélection se fait par valeur avec
.sel()(intuitive) ou par position avec.isel()(NumPy-style)..interp()permet l’interpolation à des coordonnées arbitraires.Les opérations (agrégation, broadcasting,
groupby) respectent automatiquement les dimensions nommées, éliminant les erreurs classiques de NumPy.Xarray lit et écrit NetCDF nativement, supporte Zarr pour le cloud, et s’intègre naturellement avec Pandas.
Le chapitre suivant introduit Scikit-learn et son API cohérente fit/transform/predict, point d’entrée vers le machine learning en Python.