RNN, LSTM et séquences#
<torch._C.Generator at 0x7efc4df2ea90>
Le problème des données séquentielles#
Un MLP ou un CNN traite des entrées de dimension fixe, indépendantes les unes des autres. Or, une vaste catégorie de problèmes du monde réel implique des données séquentielles : des phrases dont le sens dépend de l’ordre des mots, des séries temporelles où la valeur à l’instant \(t\) dépend des instants précédents, des séquences génomiques ou des signaux audio. Dans tous ces cas, l’hypothèse d’indépendance des exemples est violée, et la longueur de la séquence peut varier d’un exemple à l’autre.
Les réseaux de neurones récurrents (Recurrent Neural Networks, RNN) ont été conçus pour traiter exactement ce type de données. L’idée centrale est d’introduire un état caché (hidden state) qui résume l’information accumulée jusqu’à l’instant courant, et de le mettre à jour à chaque pas de temps en fonction du nouvel élément de la séquence.
RNN vanille#
RNN vanille
Un RNN vanille traite une séquence \(\{x_1, x_2, \ldots, x_T\}\) en mettant à jour récursivement un état caché \(h_t \in \mathbb{R}^d\) :
où \(W_{hh}\) est la matrice de récurrence, \(W_{xh}\) la matrice d’entrée, et \(b_h\) le biais. La sortie à l’instant \(t\) est optionnellement calculée par \(y_t = W_{hy}\, h_t + b_y\). Les paramètres \(W_{hh}\), \(W_{xh}\), \(b_h\) sont partagés à tous les pas de temps, ce qui permet au modèle de traiter des séquences de longueur arbitraire avec un nombre fixe de paramètres.
# RNN vanille manuel (pour illustrer le mécanisme)
class RNNVanilla(nn.Module):
def __init__(self, dim_entrée, dim_cachée):
super().__init__()
self.W_xh = nn.Linear(dim_entrée, dim_cachée, bias=False)
self.W_hh = nn.Linear(dim_cachée, dim_cachée, bias=True)
def forward(self, x, h0=None):
# x : (batch_size, seq_len, dim_entrée)
B, T, _ = x.shape
d = self.W_hh.out_features
h = torch.zeros(B, d, device=x.device) if h0 is None else h0
sorties = []
for t in range(T):
h = torch.tanh(self.W_xh(x[:, t, :]) + self.W_hh(h))
sorties.append(h)
# sorties : liste de T tenseurs (B, d)
return torch.stack(sorties, dim=1), h # (B, T, d), (B, d)
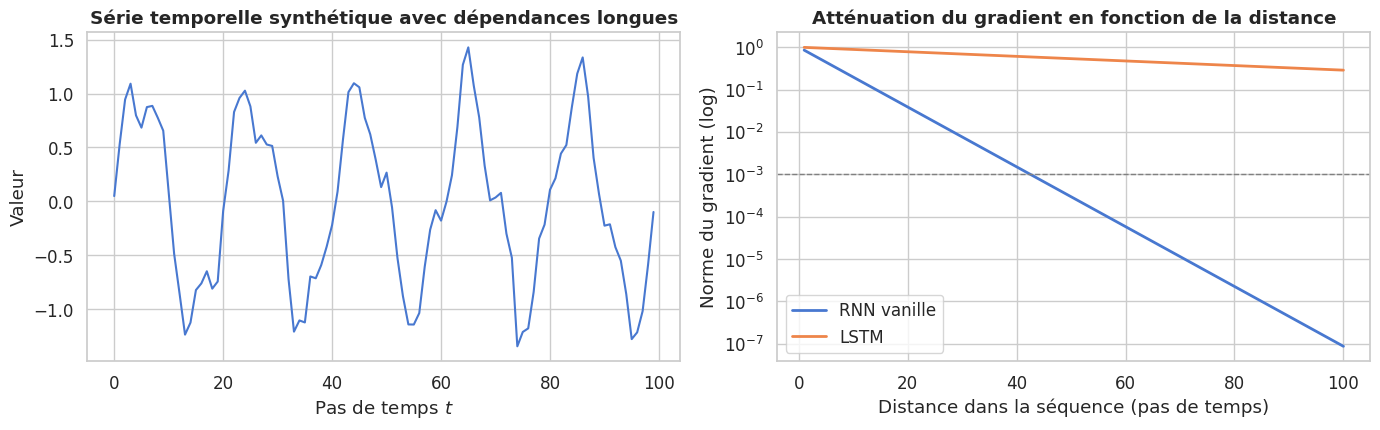
Le problème du gradient qui s’évanouit#
Le défaut majeur du RNN vanille est son incapacité à capturer des dépendances à long terme. Intuitivement, l’état caché \(h_t\) est le résultat de l’application successive de la même transformation non linéaire sur \(T\) pas de temps. Lors de la rétropropagation à travers le temps (Backpropagation Through Time, BPTT), le gradient de la perte par rapport à \(h_0\) fait intervenir le produit :
Si les valeurs propres de la matrice jacobienne \(\partial h_t / \partial h_{t-1}\) sont inférieures à 1 en norme (ce qui arrive facilement avec \(\tanh\)), ce produit de \(T\) matrices converge géométriquement vers zéro : c’est le gradient qui s’évanouit (vanishing gradient). Le réseau ne peut plus apprendre de dépendances séparant deux éléments par plus de quelques pas de temps. Inversement, si les valeurs propres sont supérieures à 1, le produit explose : c’est le gradient qui explose (exploding gradient), partiellement remédié par l’écrêtage des gradients (gradient clipping).
Note
L”écrêtage des gradients (gradient clipping) est une technique empirique simple pour contenir l’explosion des gradients : si la norme du gradient dépasse un seuil \(\tau\), on le rescale pour qu’elle soit exactement \(\tau\). En PyTorch : torch.nn.utils.clip_grad_norm_(modele.parameters(), max_norm=1.0). Cet appel doit se placer entre loss.backward() et optimizer.step(). Il ne résout pas le problème des gradients qui s’évanouissent, mais stabilise l’entraînement des RNN et LSTM.
LSTM#
Le Long Short-Term Memory (LSTM, Hochreiter & Schmidhuber, 1997) est la réponse architecturale au problème du gradient qui s’évanouit. L’idée centrale est d’introduire une cellule mémoire \(c_t\) à longue durée de vie, dont les informations peuvent être lues, écrites et effacées grâce à des mécanismes de portes (gates) différentiables.
LSTM
Un LSTM maintient deux états à chaque pas de temps : l’état caché \(h_t\) et la cellule mémoire \(c_t\). Quatre transformations linéaires, appliquées à la concaténation \([h_{t-1}, x_t]\), contrôlent le flux d’information :
Porte d’oubli : \(f_t = \sigma(W_f [h_{t-1}, x_t] + b_f)\) — détermine quelle fraction de \(c_{t-1}\) conserver.
Porte d’entrée : \(i_t = \sigma(W_i [h_{t-1}, x_t] + b_i)\) — détermine quelle nouvelle information écrire.
Candidat mémoire : \(\tilde{c}_t = \tanh(W_c [h_{t-1}, x_t] + b_c)\) — le contenu potentiel à écrire.
Porte de sortie : \(o_t = \sigma(W_o [h_{t-1}, x_t] + b_o)\) — détermine quelle partie de \(c_t\) exposer comme \(h_t\).
Mise à jour de la cellule : \(c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t\)
État caché : \(h_t = o_t \odot \tanh(c_t)\)
Le chemin de gradient à travers \(c_t\) est une somme (opération \(+\)), non un produit de matrices, ce qui permet à l’information de se propager sur de longues séquences sans s’évanouir.
# LSTM en PyTorch
lstm = nn.LSTM(
input_size=64, # dimension des vecteurs d'entrée
hidden_size=128, # dimension de h_t et c_t
num_layers=2, # LSTM empilés
batch_first=True, # format (batch, seq, features)
dropout=0.3, # dropout entre les couches (pas sur la dernière)
bidirectional=False,
)
# Entrée : (batch_size=8, seq_len=20, input_size=64)
x = torch.randn(8, 20, 64)
h0 = torch.zeros(2, 8, 128) # (num_layers, batch, hidden_size)
c0 = torch.zeros(2, 8, 128)
sorties, (hn, cn) = lstm(x, (h0, c0))
print(f"sorties : {sorties.shape}") # (8, 20, 128) — sortie à chaque pas de temps
print(f"hn : {hn.shape}") # (2, 8, 128) — état caché final par couche
print(f"cn : {cn.shape}") # (2, 8, 128) — cellule mémoire finale par couche
sorties : torch.Size([8, 20, 128])
hn : torch.Size([2, 8, 128])
cn : torch.Size([2, 8, 128])
GRU#
Le Gated Recurrent Unit (GRU, Cho et al., 2014) est une simplification du LSTM qui fusionne les portes d’oubli et d’entrée en une seule porte de réinitialisation, et fusionne \(h_t\) et \(c_t\) en un seul état caché. Le GRU a moins de paramètres que le LSTM et converge souvent plus vite, tout en atteignant des performances comparables sur la plupart des tâches.
GRU
Un GRU calcule l’état caché \(h_t\) à partir de deux portes :
Porte de mise à jour : \(z_t = \sigma(W_z [h_{t-1}, x_t])\) — contrôle combien de l’état précédent est conservé.
Porte de réinitialisation : \(r_t = \sigma(W_r [h_{t-1}, x_t])\) — contrôle combien de l’état précédent influence le candidat.
Candidat : \(\tilde{h}_t = \tanh(W [r_t \odot h_{t-1}, x_t])\)
État caché : \(h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t\)
Quand \(z_t \approx 0\), l’état précédent est intégralement conservé. Quand \(z_t \approx 1\), le candidat \(\tilde{h}_t\) remplace l’état précédent. Le GRU possède \(\frac{2}{3}\) des paramètres d’un LSTM de même dimension.
gru = nn.GRU(input_size=64, hidden_size=128, num_layers=2,
batch_first=True, dropout=0.3)
x = torch.randn(8, 20, 64)
h0 = torch.zeros(2, 8, 128)
sorties, hn = gru(x, h0)
print(f"sorties : {sorties.shape}") # (8, 20, 128)
print(f"hn : {hn.shape}") # (2, 8, 128)
sorties : torch.Size([8, 20, 128])
hn : torch.Size([2, 8, 128])
Séquences de longueur variable et padding#
En pratique, les séquences d’un même batch ont rarement la même longueur. On complète les séquences courtes avec des valeurs neutres (généralement des zéros) jusqu’à la longueur maximale du batch : c’est le padding. PyTorch fournit pack_padded_sequence et pad_packed_sequence pour que le RNN ne traite pas les positions de padding, améliorant l’efficacité et la précision du calcul.
Padding et masquage
Le padding consiste à allonger les séquences courtes avec une valeur spéciale (souvent 0) pour qu’elles atteignent toutes la même longueur \(T_{max}\). Le masquage consiste à ignorer les positions de padding lors du calcul de la perte et lors du traitement par le RNN. En PyTorch, nn.utils.rnn.pack_padded_sequence crée un objet PackedSequence qui compacte les données en éliminant les positions de padding, permettant au RNN de traiter efficacement des batches de séquences hétérogènes.
from torch.nn.utils.rnn import pad_sequence, pack_padded_sequence, pad_packed_sequence
# Séquences de longueurs différentes
sequences = [
torch.randn(15, 64), # séquence de longueur 15
torch.randn(8, 64), # séquence de longueur 8
torch.randn(20, 64), # séquence de longueur 20
torch.randn(5, 64), # séquence de longueur 5
]
longueurs = torch.tensor([15, 8, 20, 5])
# Trier par longueur décroissante (requis pour pack_padded_sequence)
longueurs, ordre = longueurs.sort(descending=True)
sequences = [sequences[i] for i in ordre]
# Padder jusqu'à la longueur maximale
batch_padded = pad_sequence(sequences, batch_first=True, padding_value=0.0)
# batch_padded : (4, 20, 64)
# Compacter pour le RNN — ignore les positions de padding
batch_packed = pack_padded_sequence(batch_padded, longueurs, batch_first=True)
lstm = nn.LSTM(64, 128, batch_first=True)
sorties_packed, (hn, cn) = lstm(batch_packed)
# Décompacter la sortie
sorties, _ = pad_packed_sequence(sorties_packed, batch_first=True)
# sorties : (4, 20, 128) — les positions de padding contiennent des zéros
Application : classification de texte#
La classification de texte est l’une des applications les plus courantes des LSTM. Le pipeline standard encode chaque token en un vecteur dense via une couche d”embedding, traite la séquence avec un LSTM bidirectionnel, et classifie à partir de l’état caché final ou d’un pooling sur toutes les sorties.
Classifieur de texte avec LSTM bidirectionnel
Voici un classifieur de sentiment (positif / négatif) basé sur un LSTM bidirectionnel :
Application : prévision de séries temporelles#
Les séries temporelles constituent l’autre domaine d’application majeur des RNN. L’objectif est souvent de prédire les valeurs futures à partir des valeurs passées : prévision de la consommation électrique, des cours boursiers, des données météorologiques.
class PrévisionSérie(nn.Module):
"""LSTM pour prédire h_horizon pas de temps dans le futur."""
def __init__(self, n_variables, dim_cachée=64, n_couches=2,
horizon=1, dropout=0.2):
super().__init__()
self.lstm = nn.LSTM(n_variables, dim_cachée, n_couches,
batch_first=True, dropout=dropout)
self.tête = nn.Sequential(
nn.Linear(dim_cachée, dim_cachée // 2),
nn.ReLU(),
nn.Linear(dim_cachée // 2, n_variables * horizon),
)
self.horizon = horizon
self.n_variables = n_variables
def forward(self, x):
# x : (B, T, n_variables) — fenêtre temporelle passée
sorties, (hn, _) = self.lstm(x)
# Utiliser le dernier état caché pour la prédiction
prédiction = self.tête(sorties[:, -1, :]) # (B, n_variables * horizon)
return prédiction.view(-1, self.horizon, self.n_variables)
# Exemple : prédire 24h à l'avance à partir de 168h (1 semaine) de données horaires
modele_ts = PrévisionSérie(n_variables=5, dim_cachée=128, horizon=24)
x = torch.randn(32, 168, 5)
print(modele_ts(x).shape) # (32, 24, 5)
torch.Size([32, 24, 5])
Note
Les LSTM et GRU ont été largement supplantés par les transformers pour les tâches de traitement du langage naturel depuis 2018. Les transformers exploitent un mécanisme d”attention permettant à chaque position de la séquence d’interagir directement avec toutes les autres, sans la limitation des dépendances bornées des RNN. Cependant, les LSTM et GRU restent pertinents pour les séries temporelles à faible latence d’inférence, les systèmes embarqués où la mémoire est contrainte, et les tâches où la longueur de séquence est modérée (quelques centaines de pas).
Résumé#
Ce chapitre a présenté les architectures récurrentes pour le traitement des séquences :
Le RNN vanille introduit l’état caché \(h_t\) mis à jour récursivement, permettant de traiter des séquences de longueur variable avec un nombre fixe de paramètres. Son défaut fondamental est le gradient qui s’évanouit : les dépendances au-delà de quelques dizaines de pas de temps ne peuvent pas être apprises.
Le LSTM résout ce problème grâce à une cellule mémoire \(c_t\) et quatre portes différentiables. Le chemin de gradient à travers \(c_t\) est additif plutôt que multiplicatif, permettant aux informations de se propager sur des centaines de pas de temps.
Le GRU est une simplification du LSTM avec deux portes au lieu de quatre, offrant un rapport paramètres/performance souvent favorable. Il est à préférer quand les données sont limitées ou la latence critique.
Le padding et les
PackedSequencepermettent de traiter efficacement des batches de séquences hétérogènes sans calcul inutile sur les positions rembourées.La classification de texte avec LSTM bidirectionnel et la prévision de séries temporelles sont les deux applications paradigmatiques présentées. Dans les deux cas, le modèle est relativement simple à implémenter mais requiert un soin particulier dans la gestion des longueurs variables et le choix de la dimension de l’état caché.
Le chapitre suivant abordera les pipelines de données et l’orchestration de workflows ML, essentiels pour passer du prototype à un système reproductible et maintenable.