Performances : Numba, Dask, Polars#
La data science en Python repose sur un écosystème de bibliothèques remarquablement efficaces, mais il arrive que l’on se retrouve face à des goulots d’étranglement qui rendent les traitements péniblement lents. Dès que l’on travaille sur des jeux de données de plusieurs gigaoctets, que l’on enchaîne des boucles Python pures sur des millions d’éléments ou que l’on souhaite exploiter plusieurs cœurs en parallèle, les approches classiques montrent leurs limites. Ce chapitre présente un ensemble d’outils complémentaires — Numba, Dask et Polars — qui permettent de repousser ces limites, chacun selon une stratégie différente. Mais avant de chercher à accélérer un code, encore faut-il savoir où il perd du temps.
Identifier les goulots d’étranglement#
Optimiser sans mesurer est l’une des erreurs les plus courantes en développement logiciel. On croit souvent savoir quelle partie du code est lente, mais l’intuition se trompe régulièrement. Les outils de profilage permettent de quantifier précisément où le temps est passé, afin de concentrer les efforts d’optimisation là où ils auront le plus d’impact.
timeit : mesurer la durée d’une expression#
L’outil le plus simple est timeit, qui exécute une expression un grand nombre de fois et en mesure la durée moyenne. En mode interactif (Jupyter ou IPython), on utilise les commandes magiques %timeit (une ligne) et %%timeit (une cellule entière).
import numpy as np
a = np.random.rand(1_000_000)
# Mesurer la somme NumPy vs Python pur
%timeit np.sum(a) # quelques microsecondes
%timeit sum(a) # plusieurs centaines de millisecondes
433 μs ± 2.1 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
86.2 ms ± 5.5 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Le facteur entre les deux peut dépasser 100×. timeit est parfait pour comparer des implémentations alternatives d’une même opération.
cProfile : profiler une fonction entière#
Pour identifier quelle fonction dans un programme consomme le plus de temps, cProfile est l’outil standard de Python. Il instrumente chaque appel de fonction et produit un rapport détaillé.
import cProfile
import pstats
def traitement_lourd(n):
total = 0
for i in range(n):
total += i ** 2
return total
profiler = cProfile.Profile()
profiler.enable()
traitement_lourd(1_000_000)
profiler.disable()
stats = pstats.Stats(profiler)
stats.sort_stats("cumulative")
stats.print_stats(10) # Affiche les 10 fonctions les plus lentes
469 function calls (459 primitive calls) in 0.080 seconds
Ordered by: cumulative time
List reduced from 89 to 10 due to restriction <10>
ncalls tottime percall cumtime percall filename:lineno(function)
3/2 0.003 0.001 0.080 0.040 /home/loc/legacy_workspace/notebooks/.venv/lib/python3.13/site-packages/IPython/core/interactiveshell.py:3665(run_code)
2 0.000 0.000 0.068 0.034 /usr/lib/python3.13/asyncio/base_events.py:1962(_run_once)
3/2 0.000 0.000 0.068 0.034 /usr/lib/python3.13/asyncio/events.py:87(_run)
3/2 0.000 0.000 0.068 0.034 {method 'run' of '_contextvars.Context' objects}
2 0.000 0.000 0.068 0.034 /home/loc/legacy_workspace/notebooks/.venv/lib/python3.13/site-packages/zmq/eventloop/zmqstream.py:573(_handle_events)
1 0.000 0.000 0.068 0.068 /home/loc/legacy_workspace/notebooks/.venv/lib/python3.13/site-packages/tornado/platform/asyncio.py:206(_handle_events)
2 0.000 0.000 0.068 0.034 /home/loc/legacy_workspace/notebooks/.venv/lib/python3.13/site-packages/zmq/eventloop/zmqstream.py:614(_handle_recv)
2 0.000 0.000 0.068 0.034 /home/loc/legacy_workspace/notebooks/.venv/lib/python3.13/site-packages/zmq/eventloop/zmqstream.py:546(_run_callback)
2 0.000 0.000 0.068 0.034 /home/loc/legacy_workspace/notebooks/.venv/lib/python3.13/site-packages/ipykernel/iostream.py:229(_handle_event)
2 0.005 0.003 0.068 0.034 /home/loc/legacy_workspace/notebooks/.venv/lib/python3.13/site-packages/ipykernel/iostream.py:348(<lambda>)
<pstats.Stats at 0x7fb776cda3c0>
Le rapport indique pour chaque fonction : le nombre d’appels, le temps total passé dans la fonction elle-même (tottime) et le temps cumulé incluant les fonctions appelées (cumtime). C’est ce dernier qui permet de remonter la chaîne d’appels jusqu’au vrai coupable.
line_profiler : profiler ligne par ligne#
Quand cProfile a identifié une fonction suspecte, line_profiler permet de descendre au niveau de chaque ligne pour voir exactement où le temps est dépensé.
# Installation : pip install line-profiler
# En Jupyter : %load_ext line_profiler
def calcul_intensif(data):
resultats = []
for x in data:
y = x ** 2 + 2 * x + 1 # Ligne coûteuse ?
resultats.append(y)
return resultats
data = list(range(100_000))
%lprun -f calcul_intensif calcul_intensif(data)
La sortie montre, pour chaque ligne, le pourcentage du temps total qu’elle représente. C’est souvent révélateur : une boucle avec un append peut être remplacée par une compréhension de liste ou une opération NumPy, avec un gain de 10× ou plus.
memory_profiler : surveiller la consommation mémoire#
Les problèmes de performance ne sont pas toujours liés au temps de calcul. Un processus qui consomme trop de mémoire peut ralentir toute la machine en forçant l’utilisation du disque comme mémoire virtuelle (swap). memory_profiler mesure la consommation mémoire ligne par ligne.
# Installation : pip install memory-profiler
# En Jupyter : %load_ext memory_profiler
@profile
def creer_grande_liste():
a = [i ** 2 for i in range(1_000_000)] # ~8 Mo
b = [x * 2 for x in a] # ~8 Mo supplémentaires
return b
%mprun -f creer_grande_liste creer_grande_liste()
Note
La règle d’or de l’optimisation est souvent résumée ainsi : « Measure, don’t guess ». Il faut toujours profiler avant d’optimiser, puis mesurer à nouveau après pour s’assurer que la modification a bien produit l’effet escompté. Une optimisation non mesurée peut parfois dégrader les performances dans certains cas particuliers tout en les améliorant dans le cas testé.
Numba : compilation JIT pour Python#
Numba est une bibliothèque qui compile du code Python en code machine natif à la volée (Just-In-Time compilation, ou JIT). Elle est particulièrement efficace pour les boucles numériques pures que NumPy ne peut pas vectoriser directement. Au lieu de réécrire le code en C ou en Fortran, on ajoute simplement un décorateur Python.
Compilation JIT
La compilation JIT (Just-In-Time) est une technique où le code source n’est pas compilé à l’avance (comme en C ou en Rust), mais lors de la première exécution. Le compilateur analyse les types réels des arguments et génère du code machine optimisé pour ces types. Les exécutions suivantes utilisent ce code compilé directement, sans passer par l’interpréteur Python. Le premier appel est plus lent (coût de compilation), mais tous les suivants sont très rapides.
@jit et @njit : accélérer des boucles#
Le décorateur le plus simple est @jit. En ajoutant nopython=True (ou en utilisant l’alias @njit), on indique à Numba de refuser silencieusement de recourir à l’interpréteur Python si une partie du code ne peut pas être compilée — ce qui garantit les meilleures performances.
from numba import jit, njit
import numpy as np
# Version Python pure
def somme_carres_python(n):
total = 0.0
for i in range(n):
total += i * i
return total
# Version Numba compilée JIT
@njit
def somme_carres_numba(n):
total = 0.0
for i in range(n):
total += i * i
return total
# Premier appel : déclenche la compilation (plus lent)
_ = somme_carres_numba(1000)
# Comparaison (après compilation)
# %timeit somme_carres_python(10_000_000) # ~ 1 seconde
# %timeit somme_carres_numba(10_000_000) # ~ 5 millisecondes
L’accélération typique avec @njit sur des boucles numériques est de l’ordre de 50× à 200× par rapport à Python pur.
@vectorize : créer des ufuncs NumPy#
Numba permet également de créer des ufuncs (universal functions) NumPy personnalisées avec le décorateur @vectorize. Une ufunc s’applique élément par élément sur des tableaux NumPy de toute dimension, comme np.sin ou np.exp.
from numba import vectorize, float64
@vectorize([float64(float64, float64)])
def activation_relu(x, seuil):
"""ReLU avec seuil personnalisé."""
return x if x > seuil else 0.0
import numpy as np
data = np.random.randn(1_000_000)
resultat = activation_relu(data, 0.0) # Appliqué sur tout le tableau, en C
Cas d’usage appropriés#
Numba excelle dans des situations précises : simulations numériques avec de nombreuses itérations, calculs sur des tableaux NumPy avec des conditions complexes, algorithmes de physique ou de finance quantitative. En revanche, Numba n’accélère pas le code qui manipule des objets Python arbitraires (dictionnaires, listes hétérogènes), ni les opérations sur les DataFrames Pandas.
Simulation de Monte-Carlo avec Numba
La simulation de Monte-Carlo pour estimer π illustre parfaitement le cas d’usage de Numba : des millions d’itérations indépendantes avec des opérations arithmétiques simples.
Dask : calcul parallèle sur de grandes données#
Dask est une bibliothèque de calcul parallèle et distribué conçue pour traiter des données qui ne tiennent pas entièrement en mémoire vive. Elle offre des interfaces familières — dask.array imite NumPy, dask.dataframe imite Pandas — mais exécute les calculs en parallèle sur plusieurs cœurs ou plusieurs machines.
Graphe de tâches (DAG)
Dask représente les calculs sous forme d’un graphe acyclique dirigé (Directed Acyclic Graph, DAG) de tâches. Chaque opération (addition, filtrage, agrégation) crée un nœud dans ce graphe, sans l’exécuter immédiatement. Ce n’est qu’à l’appel de .compute() que Dask analyse le graphe, optimise les dépendances entre tâches et les exécute en parallèle. Cette approche lazy permet d’éviter les calculs inutiles et de minimiser les transferts de données.
dask.array : NumPy sur de grands tableaux#
dask.array découpe les tableaux en morceaux (chunks) et applique les opérations NumPy sur chaque chunk indépendamment.
import dask.array as da
# Créer un tableau Dask de 10 Go (divisé en chunks de 100 Mo)
x = da.random.random((100_000, 100_000), chunks=(1_000, 1_000))
# Les opérations sont paresseuses — rien n'est calculé encore
y = x + x.T
z = y.mean(axis=0)
# Le calcul effectif se lance ici
resultat = z.compute()
dask.dataframe : Pandas sur des fichiers trop grands#
dask.dataframe est l’interface la plus utilisée en pratique. Elle permet de lire et de traiter des dizaines de fichiers CSV ou Parquet comme s’ils formaient un seul DataFrame Pandas.
import dask.dataframe as dd
# Lire tous les fichiers CSV d'un répertoire d'un coup
ddf = dd.read_csv("donnees/ventes_*.csv")
# API similaire à Pandas
resultat = (
ddf
.groupby("region")
["chiffre_affaires"]
.sum()
.compute()
)
Le scheduler et dask.distributed#
Par défaut, Dask utilise un scheduler threadé pour les tableaux et un scheduler multi-processus pour les DataFrames. Pour les workloads plus complexes ou pour distribuer les calculs sur un cluster, on utilise dask.distributed.
from dask.distributed import Client
# Démarrer un cluster local sur tous les cœurs disponibles
client = Client()
print(client) # Affiche le tableau de bord : http://localhost:8787
# Toutes les opérations Dask suivantes utilisent maintenant ce client
import dask.dataframe as dd
ddf = dd.read_parquet("donnees_enormes/")
resultat = ddf.groupby("categorie").agg({"prix": "mean"}).compute()
client.close()
Le tableau de bord Dask (accessible via le navigateur) offre une visualisation en temps réel de l’avancement des tâches, de l’utilisation mémoire et des transferts de données.
Note
Dask n’est pas toujours plus rapide que Pandas sur des données qui tiennent en mémoire. La parallélisation introduit un surcoût de coordination qui peut rendre Dask plus lent sur de petits jeux de données. Sa valeur ajoutée apparaît clairement lorsque les données dépassent la RAM disponible, ou lorsque l’on peut exploiter de nombreux cœurs CPU sur des opérations véritablement parallélisables.
Polars : DataFrames ultra-rapides en Rust#
Polars est une bibliothèque de DataFrames écrite entièrement en Rust, conçue dès le départ pour la performance et le parallélisme. Contrairement à Dask qui parallélise Pandas, Polars réécrit l’ensemble de la logique de traitement avec une architecture optimisée : colonnes stockées en mémoire contiguë, exécution parallèle sur tous les cœurs, API lazy avec optimiseur de requêtes.
Évaluation paresseuse (Lazy API)
L”API lazy de Polars permet de construire un plan de requête sans l’exécuter immédiatement. Lorsqu’on appelle .collect(), Polars analyse le plan complet, applique des optimisations (élimination des colonnes inutiles, fusion des filtres, réorganisation des opérations) puis exécute le calcul en parallèle sur tous les cœurs disponibles. Cette approche est similaire à un optimiseur SQL.
API de base : Eager vs Lazy#
import polars as pl
import numpy as np
import tempfile, os
# Génération d'un jeu de données de démonstration
rng = np.random.default_rng(42)
n = 10_000
_df_tmp = pl.DataFrame({
"region": rng.choice(["Nord", "Sud", "Est", "Ouest"], n).tolist(),
"produit": rng.choice(["A", "B", "C", "D", "E"], n).tolist(),
"montant": rng.uniform(10, 500, n).tolist(),
})
_parquet_path = os.path.join(tempfile.mkdtemp(), "ventes.parquet")
_df_tmp.write_parquet(_parquet_path)
# API eager (immédiate) — similaire à Pandas
df = pl.read_parquet(_parquet_path)
resultat_eager = (
df
.filter(pl.col("region") == "Nord")
.group_by("produit")
.agg(pl.col("montant").sum().alias("total"))
.sort("total", descending=True)
)
print("Eager :")
print(resultat_eager)
# API lazy (recommandée pour les grands jeux de données)
resultat_lazy = (
pl.scan_parquet(_parquet_path) # Lecture paresseuse
.filter(pl.col("region") == "Nord")
.group_by("produit")
.agg(pl.col("montant").sum().alias("total"))
.sort("total", descending=True)
.collect() # Exécution effective
)
print("\nLazy :")
print(resultat_lazy)
Eager :
shape: (5, 2)
┌─────────┬───────────────┐
│ produit ┆ total │
│ --- ┆ --- │
│ str ┆ f64 │
╞═════════╪═══════════════╡
│ D ┆ 140017.371045 │
│ C ┆ 134472.257434 │
│ B ┆ 129227.75842 │
│ A ┆ 126272.285371 │
│ E ┆ 124315.094142 │
└─────────┴───────────────┘
Lazy :
shape: (5, 2)
┌─────────┬───────────────┐
│ produit ┆ total │
│ --- ┆ --- │
│ str ┆ f64 │
╞═════════╪═══════════════╡
│ D ┆ 140017.371045 │
│ C ┆ 134472.257434 │
│ B ┆ 129227.75842 │
│ A ┆ 126272.285371 │
│ E ┆ 124315.094142 │
└─────────┴───────────────┘
Comparaison avec Pandas et migration progressive#
L’API de Polars diffère de celle de Pandas, mais les concepts sont proches. La migration peut se faire progressivement : on peut convertir des DataFrames entre les deux bibliothèques.
import pandas as pd
import polars as pl
# Pandas vers Polars
df_pandas = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})
df_polars = pl.from_pandas(df_pandas)
# Polars vers Pandas
df_pandas_retour = df_polars.to_pandas()
Les différences syntaxiques clés à connaître :
Opération |
Pandas |
Polars |
|---|---|---|
Sélectionner une colonne |
|
|
Filtrer |
|
|
Créer une colonne |
|
|
Grouper |
|
|
Visualisation comparative : benchmark#
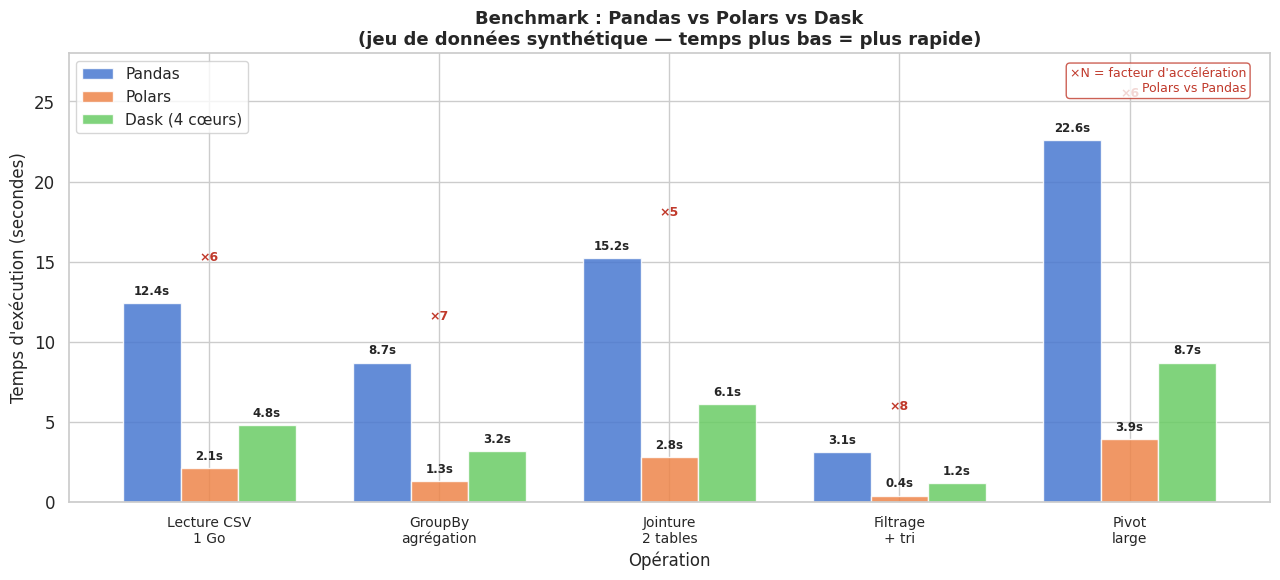
Quand utiliser quoi ?#
Le choix de l’outil dépend de plusieurs facteurs : la taille des données, le type de calcul, les ressources disponibles et la complexité acceptable du code. Le tableau suivant offre une aide à la décision.
Note
Ces catégories ne sont pas mutuellement exclusives. Dans un pipeline de production, il est courant de combiner les outils : lire les données avec Polars (rapide et expressif), utiliser Numba pour un algorithme sur-mesure qui n’existe pas dans les bibliothèques standard, et passer à Dask uniquement lorsque les données dépassent la mémoire disponible.
Situation |
Outil recommandé |
Raison |
|---|---|---|
Données < 1 Go, opérations standard |
Pandas |
Simple, bien documenté, large écosystème |
Données < 50 Go, opérations standard |
Polars |
5-20× plus rapide que Pandas |
Boucles Python intensives sur tableaux NumPy |
Numba |
Compilation JIT, accélération 50-200× |
Données > RAM disponible |
Dask |
Traitement par chunks, parallélisme |
Cluster de machines |
Dask Distributed |
Distribution sur plusieurs nœuds |
Algorithmes personnalisés vectorisés |
Numba |
ufuncs compilées en C |
SQL analytique sur Parquet/CSV |
DuckDB |
Voir chapitre 19 |
Résumé#
Ce chapitre a présenté les principaux outils pour améliorer les performances des traitements Python en data science :
Profiler avant d’optimiser :
timeitpour les micro-benchmarks,cProfilepour identifier les fonctions lentes,line_profilerpour descendre au niveau de la ligne,memory_profilerpour surveiller la mémoire.Numba compile du code Python en code machine natif via la compilation JIT. Les décorateurs
@njitet@vectorizepermettent d’accélérer des boucles numériques de 50 à 200× sans quitter Python.Dask parallélise les calculs sur des données trop grandes pour la mémoire en découpant le travail en chunks et en les traitant sur plusieurs cœurs ou machines. Son API imite NumPy et Pandas.
Polars est un moteur de DataFrames écrit en Rust qui surpasse Pandas de 5 à 20× sur les opérations courantes, grâce à son architecture parallèle et à son optimiseur de requêtes (API lazy).
Le choix de l’outil dépend de la taille des données et du type de calcul : Polars pour le traitement tabulaire rapide, Numba pour les algorithmes numériques sur-mesure, Dask pour les données qui ne tiennent pas en mémoire.
Dans le chapitre suivant, nous nous intéressons aux formats de données : comment stocker et lire efficacement de grands volumes d’informations avec Parquet, HDF5, Zarr et DuckDB.