Pandas — agrégation, groupby et jointures#
L’une des forces majeures de Pandas est sa capacité à agréger, résumer et combiner des données de façon expressive et efficace. Que l’on cherche à calculer des statistiques par groupe, à fusionner plusieurs sources de données ou à calculer des moyennes mobiles sur une série temporelle, Pandas offre des opérateurs de haut niveau qui évitent d’écrire des boucles explicites. Ce chapitre couvre ces opérations en profondeur, des fondamentaux du patron split-apply-combine jusqu’aux techniques avancées de performance.
La maîtrise de groupby et de merge est indispensable dans tout projet de data science : la grande majorité des analyses nécessitent de regrouper des observations par catégorie et de combiner des tables provenant de différentes sources. Ces opérations correspondent directement à ce que l’on ferait en SQL avec GROUP BY, JOIN et les fonctions de fenêtre.
groupby — le patron split-apply-combine#
Le patron split-apply-combine (diviser-appliquer-combiner) est le modèle mental qui sous-tend toutes les opérations groupby :
Split : diviser le DataFrame en sous-groupes selon une ou plusieurs clés.
Apply : appliquer une fonction à chaque sous-groupe indépendamment.
Combine : rassembler les résultats en un seul objet.
GroupBy
Un objet GroupBy est un intermédiaire paresseux (lazy) créé par df.groupby(clé). Il ne réalise aucun calcul immédiatement : il stocke uniquement la partition du DataFrame en groupes. Le calcul n’est déclenché que lorsqu’on appelle une méthode d’agrégation (sum, mean, agg, etc.), de transformation (transform) ou de filtrage (filter).
import pandas as pd
import numpy as np
np.random.seed(42)
df = pd.DataFrame({
'region': ['Nord', 'Sud', 'Est', 'Nord', 'Sud', 'Est', 'Nord', 'Sud'],
'produit': ['A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'],
'ventes': [120, 95, 145, 110, 130, 88, 160, 102],
'coûts': [60, 45, 70, 55, 65, 42, 80, 50],
})
# Agrégation simple
print("--- Ventes totales par région ---")
print(df.groupby('region')['ventes'].sum())
print()
# Agrégation multiple avec agg
print("--- Statistiques par région ---")
print(df.groupby('region')['ventes'].agg(['sum', 'mean', 'count', 'std']))
--- Ventes totales par région ---
region
Est 233
Nord 390
Sud 327
Name: ventes, dtype: int64
--- Statistiques par région ---
sum mean count std
region
Est 233 116.5 2 40.305087
Nord 390 130.0 3 26.457513
Sud 327 109.0 3 18.520259
agg avec un dictionnaire — agrégations différentes par colonne#
resultat = df.groupby('region').agg(
ventes_total=('ventes', 'sum'),
ventes_moy=('ventes', 'mean'),
coûts_total=('coûts', 'sum'),
nb_transactions=('ventes', 'count'),
)
print(resultat)
ventes_total ventes_moy coûts_total nb_transactions
region
Est 233 116.5 112 2
Nord 390 130.0 195 3
Sud 327 109.0 160 3
Agrégation par plusieurs clés#
print(df.groupby(['region', 'produit']).agg(
ventes_sum=('ventes', 'sum'),
coûts_sum=('coûts', 'sum'),
).assign(marge=lambda x: x['ventes_sum'] - x['coûts_sum']))
ventes_sum coûts_sum marge
region produit
Est A 88 42 46
B 145 70 75
Nord A 120 60 60
B 270 135 135
Sud A 225 110 115
B 102 50 52
filter — filtrer des groupes entiers#
filter conserve ou supprime des groupes entiers en fonction d’une condition portant sur le groupe :
# Conserver uniquement les régions dont la vente totale dépasse 300
df_filtre = df.groupby('region').filter(lambda x: x['ventes'].sum() > 300)
print(df_filtre)
region produit ventes coûts
0 Nord A 120 60
1 Sud A 95 45
3 Nord B 110 55
4 Sud A 130 65
6 Nord B 160 80
7 Sud B 102 50
apply — opérations arbitraires par groupe#
apply est le couteau suisse des opérations par groupe. La fonction passée reçoit le sous-DataFrame complet du groupe et peut retourner n’importe quoi (scalaire, série, DataFrame) :
def top_produit(groupe):
"""Retourne le produit le plus vendu dans le groupe."""
return groupe.loc[groupe['ventes'].idxmax(), 'produit']
print(df.groupby('region').apply(top_produit, include_groups=False))
region
Est B
Nord B
Sud A
dtype: str
Fonctions d’agrégation#
Pandas propose un large éventail de fonctions d’agrégation intégrées, optimisées en Cython pour être nettement plus rapides que leurs équivalents Python purs.
s = pd.Series([10, 20, 30, 20, 10, 40, np.nan])
# Fonctions d'agrégation courantes
print(f"sum : {s.sum()}")
print(f"mean : {s.mean():.2f}")
print(f"median : {s.median()}")
print(f"std : {s.std():.4f}")
print(f"var : {s.var():.4f}")
print(f"count : {s.count()}") # exclut NaN
print(f"nunique : {s.nunique()}") # valeurs distinctes
print(f"first : {s.first_valid_index()}")
print(f"min/max : {s.min()} / {s.max()}")
print(f"quantile : {s.quantile(0.25)}")
sum : 130.0
mean : 21.67
median : 20.0
std : 11.6905
var : 136.6667
count : 6
nunique : 4
first : 0
min/max : 10.0 / 40.0
quantile : 12.5
Agrégations personnalisées#
On peut passer des fonctions personnalisées à agg. Pour de meilleures performances, préférer les fonctions NumPy ou Numba plutôt que les fonctions Python pures :
def intervalle_confiance_95(x):
"""Retourne l'intervalle de confiance à 95 % (format chaîne)."""
n = len(x)
moy = x.mean()
ec = x.std() / np.sqrt(n)
return f"[{moy - 1.96*ec:.1f}, {moy + 1.96*ec:.1f}]"
print(df.groupby('region')['ventes'].agg(['mean', intervalle_confiance_95]))
mean intervalle_confiance_95
region
Est 116.5 [60.6, 172.4]
Nord 130.0 [100.1, 159.9]
Sud 109.0 [88.0, 130.0]
Jointures#
La combinaison de plusieurs DataFrames selon des clés communes est une opération omniprésente. Pandas implémente les quatre types de jointures SQL via merge().
Types de jointures
Inner join (
how='inner') : ne conserve que les lignes dont la clé est présente dans les deux tables — intersection.Left join (
how='left') : conserve toutes les lignes de la table gauche, et complète avec desNaNsi la clé est absente de la table droite.Right join (
how='right') : conserve toutes les lignes de la table droite, symétrique du left join.Outer join (
how='outer') : conserve toutes les lignes des deux tables — union.
clients = pd.DataFrame({
'client_id': [1, 2, 3, 4],
'nom': ['Alice', 'Bob', 'Charlie', 'Diana'],
'ville': ['Paris', 'Lyon', 'Nantes', 'Bordeaux'],
})
commandes = pd.DataFrame({
'commande_id': [101, 102, 103, 104, 105],
'client_id': [1, 2, 1, 3, 5], # client_id=5 n'existe pas dans clients
'montant': [250, 180, 320, 95, 410],
})
# Inner join
inner = pd.merge(clients, commandes, on='client_id', how='inner')
print("--- Inner join ---")
print(inner)
# Left join (tous les clients, même sans commande)
left = pd.merge(clients, commandes, on='client_id', how='left')
print("\n--- Left join ---")
print(left)
# Outer join
outer = pd.merge(clients, commandes, on='client_id', how='outer',
indicator=True)
print("\n--- Outer join avec indicateur ---")
print(outer[['nom', 'commande_id', 'montant', '_merge']])
--- Inner join ---
client_id nom ville commande_id montant
0 1 Alice Paris 101 250
1 1 Alice Paris 103 320
2 2 Bob Lyon 102 180
3 3 Charlie Nantes 104 95
--- Left join ---
client_id nom ville commande_id montant
0 1 Alice Paris 101.0 250.0
1 1 Alice Paris 103.0 320.0
2 2 Bob Lyon 102.0 180.0
3 3 Charlie Nantes 104.0 95.0
4 4 Diana Bordeaux NaN NaN
--- Outer join avec indicateur ---
nom commande_id montant _merge
0 Alice 101.0 250.0 both
1 Alice 103.0 320.0 both
2 Bob 102.0 180.0 both
3 Charlie 104.0 95.0 both
4 Diana NaN NaN left_only
5 NaN 105.0 410.0 right_only
Jointures avec clés multiples et suffixes#
stocks_2023 = pd.DataFrame({
'produit': ['A', 'B', 'C'],
'region': ['Nord', 'Nord', 'Sud'],
'stock': [500, 300, 400],
})
stocks_2024 = pd.DataFrame({
'produit': ['A', 'B', 'C'],
'region': ['Nord', 'Nord', 'Sud'],
'stock': [520, 280, 430],
})
comparaison = pd.merge(
stocks_2023, stocks_2024,
on=['produit', 'region'],
suffixes=('_2023', '_2024')
)
comparaison['évolution_%'] = (
(comparaison['stock_2024'] - comparaison['stock_2023'])
/ comparaison['stock_2023'] * 100
).round(1)
print(comparaison)
produit region stock_2023 stock_2024 évolution_%
0 A Nord 500 520 4.0
1 B Nord 300 280 -6.7
2 C Sud 400 430 7.5
Concaténation#
pd.concat() assemble plusieurs DataFrames ou Series en les empilant verticalement (axis=0) ou horizontalement (axis=1).
df_q1 = pd.DataFrame({'région': ['Nord', 'Sud'], 'ventes': [100, 90]})
df_q2 = pd.DataFrame({'région': ['Nord', 'Sud'], 'ventes': [115, 105]})
df_q3 = pd.DataFrame({'région': ['Nord', 'Sud'], 'ventes': [125, 98]})
# Concaténation verticale avec clés d'identification
annuel = pd.concat(
[df_q1, df_q2, df_q3],
keys=['T1', 'T2', 'T3'],
names=['trimestre', 'id']
)
print(annuel)
région ventes
trimestre id
T1 0 Nord 100
1 Sud 90
T2 0 Nord 115
1 Sud 105
T3 0 Nord 125
1 Sud 98
Note
Par défaut, pd.concat() avec axis=0 réinitialise l’index si ignore_index=True est passé. Sans ce paramètre, les index originaux sont conservés, ce qui peut créer des doublons. Pour axis=1, les DataFrames sont alignés par leur index : si les index ne correspondent pas, des NaN sont introduits aux positions manquantes. Il vaut mieux s’assurer de l’alignement des index avant une concaténation horizontale.
Fenêtres glissantes#
Les fenêtres glissantes permettent de calculer des statistiques sur une fenêtre mobile autour de chaque point d’une série temporelle. Elles sont particulièrement utiles pour lisser les données ou calculer des tendances.
np.random.seed(0)
idx = pd.date_range('2024-01-01', periods=60, freq='D')
prix = pd.Series(100 + np.cumsum(np.random.randn(60) * 2), index=idx)
# Moyenne mobile simple sur 7 jours
ma7 = prix.rolling(window=7).mean()
# Moyenne mobile exponentielle (plus de poids aux valeurs récentes)
ema7 = prix.ewm(span=7, adjust=False).mean()
# Fenêtre croissante (expanding) : statistique depuis le début
cummax = prix.expanding().max()
print("Rolling 7j (premières valeurs) :", ma7.head(10).round(2).tolist())
print("EWM 7j (premières valeurs) :", ema7.head(10).round(2).tolist())
Rolling 7j (premières valeurs) : [nan, nan, nan, nan, nan, nan, 109.49, 111.0, 112.38, 113.59]
EWM 7j (premières valeurs) : [103.53, 103.73, 104.37, 105.97, 108.1, 109.21, 110.52, 111.43, 112.06, 112.73]
Moyenne mobile exponentielle (EWM)
La moyenne mobile exponentielle (ewm) attribue des poids décroissants exponentiellement aux observations passées. Le paramètre span correspond approximativement au nombre de périodes considéré. Elle réagit plus vite aux changements récents qu’une moyenne mobile simple (rolling), qui pondère uniformément toutes les observations de la fenêtre.
Performance Pandas#
Pandas propose plusieurs mécanismes pour améliorer les performances sur des jeux de données volumineux.
eval() et query()#
eval() et query() utilisent le moteur numexpr pour évaluer des expressions arithmétiques ou des filtres sur des colonnes sans créer de tableaux intermédiaires, réduisant ainsi la consommation mémoire :
n = 100_000
df_perf = pd.DataFrame({
'a': np.random.randn(n),
'b': np.random.randn(n),
'c': np.random.randn(n),
'cat': np.random.choice(['X', 'Y', 'Z'], n),
})
# Approche classique (crée des tableaux intermédiaires)
# result = df_perf[(df_perf['a'] + df_perf['b']) > df_perf['c']]
# Avec query() : plus lisible, moins de mémoire
result = df_perf.query('(a + b) > c and cat == "X"')
print(f"Lignes filtrées : {len(result):,}")
# eval() pour créer une nouvelle colonne
df_perf.eval('d = a**2 + b**2 + c**2', inplace=True)
print(df_perf['d'].describe().round(3))
Lignes filtrées : 16,894
count 100000.000
mean 2.993
std 2.439
min 0.001
25% 1.211
50% 2.356
75% 4.108
max 25.513
Name: d, dtype: float64
Types catégoriels et Pandas 2.0#
Les types catégoriels réduisent drastiquement la consommation mémoire pour les colonnes à faible cardinalité, et accélèrent les opérations groupby. Avec Pandas 2.0 et le mécanisme Copy-on-Write, les modifications sur une vue ne propagent plus vers l’objet original, rendant le comportement plus prévisible :
# Comparaison mémoire : object vs Categorical
n = 1_000_000
s_object = pd.Series(np.random.choice(['Région A', 'Région B', 'Région C'], n))
s_cat = s_object.astype('category')
print(f"Mémoire (object) : {s_object.memory_usage(deep=True) / 1e6:.2f} Mo")
print(f"Mémoire (Categorical) : {s_cat.memory_usage(deep=True) / 1e6:.2f} Mo")
print(f"Facteur de réduction : {s_object.memory_usage(deep=True) / s_cat.memory_usage(deep=True):.1f}x")
Mémoire (object) : 17.00 Mo
Mémoire (Categorical) : 1.00 Mo
Facteur de réduction : 17.0x
Note
Pandas 2.0 et Copy-on-Write. Depuis Pandas 2.0, le mode Copy-on-Write (CoW) est disponible et sera activé par défaut dans les versions futures. Sous CoW, toute opération qui modifie un DataFrame crée implicitement une copie si nécessaire, éliminant le comportement ambigu SettingWithCopyWarning. Il est recommandé d’activer CoW dès aujourd’hui avec pd.options.mode.copy_on_write = True pour préparer la migration vers les versions futures.
Visualisation — Diagramme split-apply-combine#
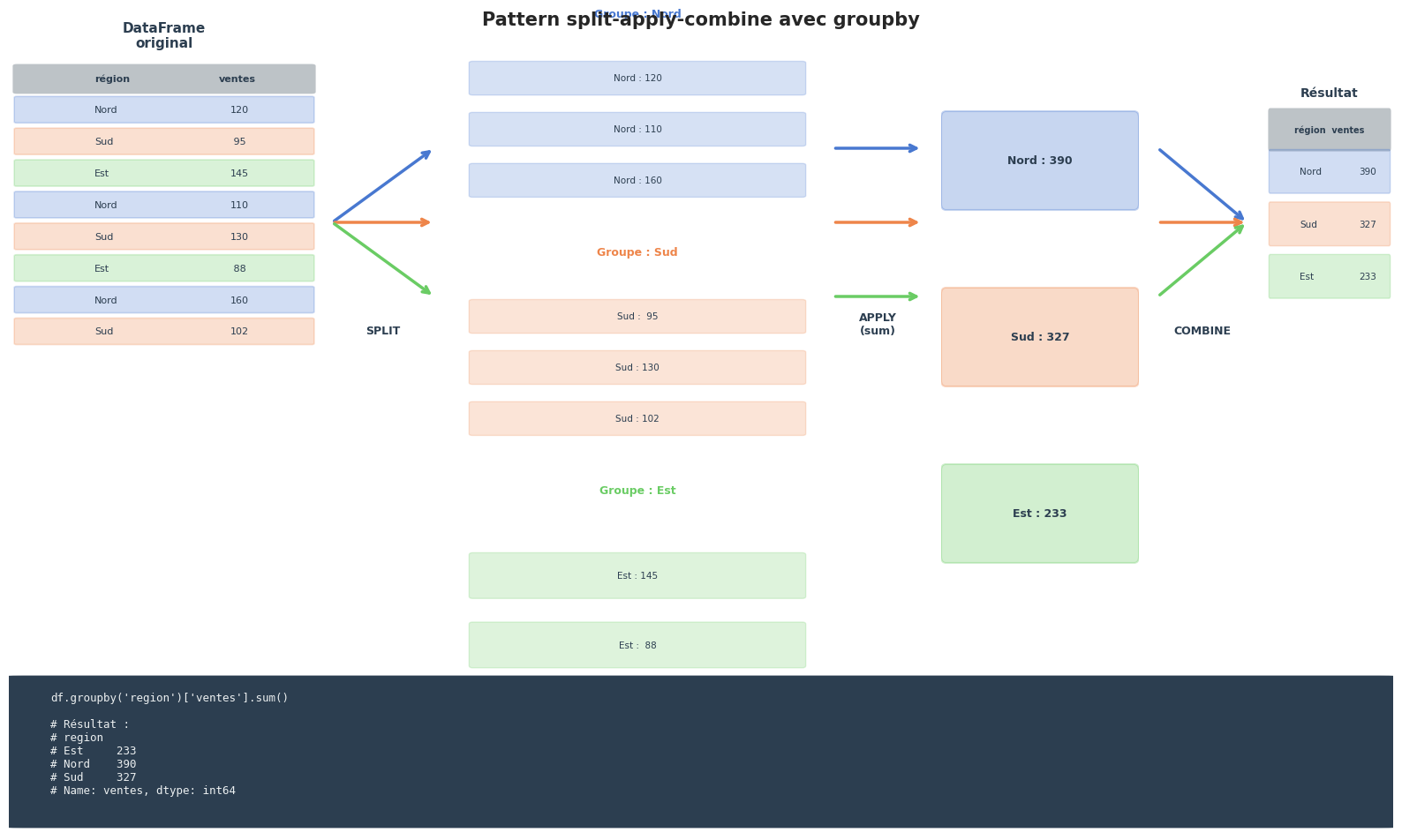
Résumé#
Ce chapitre a exploré les opérations d’agrégation, de jointure et de performance dans Pandas :
Le patron split-apply-combine est le cœur de
groupby: on divise le DataFrame par clé, on applique une fonction à chaque groupe, puis on recombine les résultats.agg,transform,filteretapplycouvrent tous les cas d’usage.Les fonctions d’agrégation intégrées (
sum,mean,count,nunique,std…) sont optimisées.aggavec un dictionnaire nommé permet de calculer plusieurs métriques en une seule passe.merge()implémente les quatre types de jointures SQL (inner, left, right, outer). L’argumentindicator=Truepermet de diagnostiquer les non-correspondances.pd.concat()assemble des tables verticalement ou horizontalement.Les fenêtres glissantes (
rolling,expanding,ewm) permettent de calculer des statistiques locales sur des séries temporelles, indispensables pour la détection de tendances.eval(),query()et les types catégoriels sont les principaux leviers de performance. Le mécanisme Copy-on-Write de Pandas 2.0 rend le comportement des copies plus prévisible.
Le chapitre suivant introduit Xarray, la bibliothèque dédiée aux données multidimensionnelles avec coordonnées nommées, particulièrement adaptée aux données climatiques, géospatiales et scientifiques.