Pandas — nettoyage et transformation#
La qualité des analyses et des modèles en data science dépend directement de la qualité des données en entrée. Or, dans la réalité, les données brutes sont rarement propres : elles contiennent des valeurs manquantes, des types incorrects, des chaînes de caractères mal formatées, des dates ambiguës et des structures qui ne correspondent pas à la forme attendue par les algorithmes. Ce chapitre explore les outils que Pandas met à disposition pour nettoyer, transformer et restructurer les données de manière efficace et reproductible.
La philosophie de Pandas en matière de nettoyage est celle d’une chaîne de transformations explicites. Chaque étape — identifier les valeurs manquantes, corriger les types, normaliser les chaînes, reconstruire la structure — doit être documentée et reproductible. Cette approche garantit que le pipeline de prétraitement peut être appliqué de la même façon à de nouvelles données, ce qui est indispensable en production.
Valeurs manquantes#
Les valeurs manquantes sont omniprésentes dans les jeux de données réels. Pandas les représente principalement par NaN (Not a Number), un flottant spécial défini par le standard IEEE 754, et depuis la version 1.0 par pd.NA, une valeur manquante générique compatible avec tous les types Pandas étendus (entiers nullables, booléens nullables, chaînes).
Valeur manquante (NaN / NA)
Une valeur manquante indique l’absence d’une observation pour une variable donnée. Dans Pandas, elle est représentée par float('nan') (alias np.nan) pour les colonnes numériques et par pd.NA pour les types étendus. Les deux se propagent dans les calculs arithmétiques : toute opération impliquant un NaN retourne un NaN, sauf si la méthode dispose d’un argument skipna=True (par défaut dans la plupart des méthodes d’agrégation).
Détecter les valeurs manquantes#
La première étape est toujours la détection. Pandas offre plusieurs méthodes complémentaires :
import pandas as pd
import numpy as np
# Création d'un DataFrame exemple avec des valeurs manquantes
df = pd.DataFrame({
'nom': ['Alice', 'Bob', None, 'Diana', 'Émile'],
'age': [28, np.nan, 35, 42, np.nan],
'ville': ['Paris', 'Lyon', 'Paris', None, 'Nantes'],
'salaire': [45000, 52000, np.nan, 61000, 48000],
})
print(df)
print()
print("--- isna() ---")
print(df.isna())
print()
print("--- Nombre de valeurs manquantes par colonne ---")
print(df.isna().sum())
print()
print("--- Pourcentage de valeurs manquantes ---")
print((df.isna().mean() * 100).round(1))
nom age ville salaire
0 Alice 28.0 Paris 45000.0
1 Bob NaN Lyon 52000.0
2 NaN 35.0 Paris NaN
3 Diana 42.0 NaN 61000.0
4 Émile NaN Nantes 48000.0
--- isna() ---
nom age ville salaire
0 False False False False
1 False True False False
2 True False False True
3 False False True False
4 False True False False
--- Nombre de valeurs manquantes par colonne ---
nom 1
age 2
ville 1
salaire 1
dtype: int64
--- Pourcentage de valeurs manquantes ---
nom 20.0
age 40.0
ville 20.0
salaire 20.0
dtype: float64
Supprimer les valeurs manquantes#
dropna() supprime les lignes (ou colonnes) contenant des valeurs manquantes. Le paramètre how ('any' ou 'all') et thresh permettent de contrôler le seuil de tolérance :
# Supprimer les lignes avec au moins une valeur manquante
print(df.dropna())
print()
# Conserver les lignes avec au moins 3 valeurs non manquantes
print(df.dropna(thresh=3))
print()
# Supprimer uniquement les lignes où TOUTES les valeurs sont manquantes
print(df.dropna(how='all'))
nom age ville salaire
0 Alice 28.0 Paris 45000.0
nom age ville salaire
0 Alice 28.0 Paris 45000.0
1 Bob NaN Lyon 52000.0
3 Diana 42.0 NaN 61000.0
4 Émile NaN Nantes 48000.0
nom age ville salaire
0 Alice 28.0 Paris 45000.0
1 Bob NaN Lyon 52000.0
2 NaN 35.0 Paris NaN
3 Diana 42.0 NaN 61000.0
4 Émile NaN Nantes 48000.0
Imputer les valeurs manquantes#
Supprimer des lignes n’est pas toujours souhaitable, car cela réduit la taille du jeu de données et peut introduire des biais si les données manquantes ne sont pas aléatoires (Missing At Random vs Missing Not At Random). L”imputation consiste à remplacer les valeurs manquantes par une valeur calculée.
# Imputation par la moyenne (colonnes numériques)
df_impute = df.copy()
df_impute['age'] = df_impute['age'].fillna(df_impute['age'].mean())
df_impute['salaire'] = df_impute['salaire'].fillna(df_impute['salaire'].median())
# Imputation par la valeur la plus fréquente (mode) pour les catégories
df_impute['ville'] = df_impute['ville'].fillna(df_impute['ville'].mode()[0])
df_impute['nom'] = df_impute['nom'].fillna('Inconnu')
print(df_impute)
nom age ville salaire
0 Alice 28.0 Paris 45000.0
1 Bob 35.0 Lyon 52000.0
2 Inconnu 35.0 Paris 50000.0
3 Diana 42.0 Paris 61000.0
4 Émile 35.0 Nantes 48000.0
Note
Les stratégies d’imputation les plus courantes sont :
Imputation par la moyenne : adaptée aux distributions symétriques sans valeurs aberrantes.
Imputation par la médiane : plus robuste pour les distributions asymétriques ou avec des outliers.
Imputation par le mode : utilisée pour les variables catégorielles.
Imputation par propagation :
ffill()(valeur précédente) etbfill()(valeur suivante) sont utiles pour les séries temporelles où les valeurs sont supposées persister.Imputation par modèle : utiliser un modèle de régression ou
IterativeImputerde Scikit-learn pour prédire la valeur manquante à partir des autres variables — méthode la plus sophistiquée mais aussi la plus coûteuse.
# Propagation en avant (utile pour les séries temporelles)
ts = pd.Series([1.0, np.nan, np.nan, 4.0, np.nan, 6.0])
print("ffill :", ts.ffill().tolist())
print("bfill :", ts.bfill().tolist())
print("interpolate :", ts.interpolate().tolist())
ffill : [1.0, 1.0, 1.0, 4.0, 4.0, 6.0]
bfill : [1.0, 4.0, 4.0, 4.0, 6.0, 6.0]
interpolate : [1.0, 2.0, 3.0, 4.0, 5.0, 6.0]
Nettoyage des types#
Les données importées depuis un fichier CSV ou une base de données ont souvent des types incorrects. Pandas peut lire une colonne de nombres entiers comme des chaînes de caractères si elle contient une seule valeur non numérique, ou conserver une date sous forme de texte. La correction des types est une étape fondamentale du nettoyage.
astype() — conversion directe#
astype() permet de convertir explicitement une colonne vers un type cible. Si la conversion est impossible (par exemple, convertir 'abc' en entier), elle lève une ValueError. Il faut dans ce cas passer par pd.to_numeric() avec errors='coerce'.
df_types = pd.DataFrame({
'id': ['1', '2', '3', '4'],
'score': ['87.5', '92.0', 'N/A', '78.3'],
'valide': ['True', 'False', 'True', 'True'],
'date': ['2024-01-15', '2024-02-20', '2024-03-05', '2024-04-12'],
'categorie': ['A', 'B', 'A', 'C'],
})
print("Types initiaux :")
print(df_types.dtypes)
print()
# Conversion sûre avec pd.to_numeric
df_types['id'] = df_types['id'].astype(int)
df_types['score'] = pd.to_numeric(df_types['score'], errors='coerce')
df_types['valide'] = df_types['valide'].map({'True': True, 'False': False})
# Conversion des dates
df_types['date'] = pd.to_datetime(df_types['date'])
# Type catégoriel (économie mémoire pour les colonnes à faible cardinalité)
df_types['categorie'] = pd.Categorical(df_types['categorie'])
print("Types après nettoyage :")
print(df_types.dtypes)
print()
print(df_types)
Types initiaux :
id str
score str
valide str
date str
categorie str
dtype: object
Types après nettoyage :
id int64
score float64
valide bool
date datetime64[us]
categorie category
dtype: object
id score valide date categorie
0 1 87.5 True 2024-01-15 A
1 2 92.0 False 2024-02-20 B
2 3 NaN True 2024-03-05 A
3 4 78.3 True 2024-04-12 C
Type catégoriel (pd.Categorical)
Le type Categorical de Pandas représente une variable à faible nombre de valeurs distinctes (comme un pays, une catégorie de produit ou un niveau d’éducation) en la stockant comme un tableau d’entiers pointant vers une table de correspondance. Pour une colonne de 10 millions de lignes avec 50 catégories distinctes, cela divise la consommation mémoire par un facteur 10 à 20 par rapport à une colonne de chaînes de caractères. Le type catégoriel active également des optimisations dans groupby.
Transformation de colonnes#
Une fois les types corrects, on souhaite souvent créer de nouvelles colonnes ou modifier les valeurs existantes. Pandas propose plusieurs méthodes selon le cas d’usage.
apply() — transformer ligne par ligne ou colonne par colonne#
apply() applique une fonction le long d’un axe. Avec axis=0 (défaut), la fonction reçoit chaque colonne ; avec axis=1, elle reçoit chaque ligne.
df_employes = pd.DataFrame({
'prenom': ['Alice', 'Bob', 'Charlie'],
'salaire_brut': [45000, 52000, 61000],
'taux_imposition': [0.20, 0.25, 0.30],
})
# apply sur une colonne (Series)
df_employes['salaire_net'] = df_employes['salaire_brut'].apply(
lambda x: round(x * 0.9, 2)
)
# apply sur les lignes (axis=1)
df_employes['salaire_apres_impot'] = df_employes.apply(
lambda row: row['salaire_brut'] * (1 - row['taux_imposition']),
axis=1
)
print(df_employes)
prenom salaire_brut taux_imposition salaire_net salaire_apres_impot
0 Alice 45000 0.20 40500.0 36000.0
1 Bob 52000 0.25 46800.0 39000.0
2 Charlie 61000 0.30 54900.0 42700.0
map() — correspondance valeur par valeur#
map() s’applique sur une Series et remplace chaque valeur par une correspondance définie dans un dictionnaire ou une fonction :
df_employes2 = pd.DataFrame({
'prenom': ['Alice', 'Bob', 'Charlie'],
'salaire_brut': [45000, 52000, 61000],
})
df_employes2['niveau'] = df_employes2['salaire_brut'].map({
45000: 'Junior',
52000: 'Intermédiaire',
61000: 'Senior',
})
print(df_employes2[['prenom', 'niveau']])
prenom niveau
0 Alice Junior
1 Bob Intermédiaire
2 Charlie Senior
transform() — transformer en conservant la forme#
transform() est particulièrement utile en combinaison avec groupby : elle applique une transformation et retourne un objet de même taille que l’entrée, ce qui permet d’ajouter directement une colonne calculée par groupe au DataFrame original.
df_ventes = pd.DataFrame({
'region': ['Nord', 'Sud', 'Nord', 'Sud', 'Nord', 'Sud'],
'ventes': [120, 95, 145, 110, 130, 88],
})
# Normalisation au sein de chaque région (z-score par groupe)
df_ventes['ventes_normalisees'] = df_ventes.groupby('region')['ventes'].transform(
lambda x: (x - x.mean()) / x.std()
).round(3)
print(df_ventes)
region ventes ventes_normalisees
0 Nord 120 -0.927
1 Sud 95 -0.237
2 Nord 145 1.060
3 Sud 110 1.097
4 Nord 130 -0.132
5 Sud 88 -0.860
Chaînes de caractères#
L’accesseur .str expose toutes les méthodes de manipulation de chaînes de caractères Python directement sur une Series, avec une gestion automatique des valeurs NaN.
s = pd.Series([' Alice Martin ', 'bob DUPONT', None, 'CHARLIE leroux'])
# Nettoyage élémentaire
propre = (s
.str.strip() # supprimer les espaces en début/fin
.str.lower() # mettre en minuscules
.str.title() # capitaliser chaque mot
)
print(propre)
0 Alice Martin
1 Bob Dupont
2 NaN
3 Charlie Leroux
dtype: str
Expressions régulières avec .str#
Les méthodes .str.contains(), .str.extract() et .str.replace() acceptent des expressions régulières, ce qui permet des transformations très puissantes :
emails = pd.Series([
'alice@exemple.fr',
'bob.dupont@societe.com',
'invalide-email',
'charlie@org.net',
])
# Vérifier le format d'un e-mail
pattern_email = r'^[\w\.\-]+@[\w\-]+\.[a-z]{2,}$'
emails_valides = emails.str.contains(pattern_email, regex=True, na=False)
print("E-mails valides :", emails_valides.tolist())
# Extraire le domaine (groupes de capture)
domaines = emails.str.extract(r'@([\w\-]+\.[a-z]{2,})')
print("\nDomaines :")
print(domaines)
E-mails valides : [True, True, False, True]
Domaines :
0
0 exemple.fr
1 societe.com
2 NaN
3 org.net
Nettoyage d’une colonne de numéros de téléphone
Un cas très courant est la normalisation de numéros de téléphone stockés dans des formats hétérogènes :
telephones = pd.Series([
'06 12 34 56 78',
'06.12.34.56.78',
'+33612345678',
'0612345678',
])
# Supprimer tout ce qui n'est pas un chiffre
telephones_normalises = telephones.str.replace(r'\D', '', regex=True)
# Remplacer le préfixe international 33 par 0
telephones_normalises = telephones_normalises.str.replace(r'^33', '0', regex=True)
print(telephones_normalises)
Dates et temps#
L’accesseur .dt expose des propriétés et méthodes de traitement des dates sur une Series de type datetime64.
dates = pd.to_datetime([
'2024-01-15', '2024-03-22', '2024-07-04',
'2024-10-31', '2024-12-25'
])
s_dates = pd.Series(dates)
print("Année :", s_dates.dt.year.tolist())
print("Mois :", s_dates.dt.month.tolist())
print("Jour :", s_dates.dt.day.tolist())
print("Jour sem.:", s_dates.dt.day_name().tolist())
print("Trimestre:", s_dates.dt.quarter.tolist())
Année : [2024, 2024, 2024, 2024, 2024]
Mois : [1, 3, 7, 10, 12]
Jour : [15, 22, 4, 31, 25]
Jour sem.: ['Monday', 'Friday', 'Thursday', 'Thursday', 'Wednesday']
Trimestre: [1, 1, 3, 4, 4]
resample() — rééchantillonnage de séries temporelles#
resample() est l’équivalent temporel de groupby : il regroupe les données par période (jour, semaine, mois, année) et permet d’appliquer des fonctions d’agrégation.
# Série temporelle quotidienne
index = pd.date_range('2024-01-01', periods=90, freq='D')
np.random.seed(42)
ts_quotidien = pd.Series(
100 + np.cumsum(np.random.randn(90)),
index=index,
name='prix'
)
# Rééchantillonnage mensuel
mensuel = ts_quotidien.resample('ME').agg(['mean', 'min', 'max'])
print(mensuel)
mean min max
2024-01-31 99.523935 93.753887 104.480611
2024-02-29 91.192895 87.988384 95.606165
2024-03-31 90.824053 87.753344 93.998399
Note
Les alias de fréquence les plus courants pour resample() et date_range() sont :
'D' (jour), 'W' (semaine), 'ME' (fin de mois), 'QE' (fin de trimestre), 'YE' (fin d’année), 'h' (heure), 'min' (minute). Depuis Pandas 2.2, les alias dépréciés 'M', 'Q', 'A' ont été remplacés par 'ME', 'QE', 'YE'.
Reshaping#
Souvent, la structure d’un jeu de données ne correspond pas à la forme attendue. On distingue deux formats : le format large (wide), où chaque variable occupe une colonne, et le format long (long ou tidy), où chaque observation correspond à une ligne unique.
melt() — de large à long#
df_large = pd.DataFrame({
'pays': ['France', 'Allemagne', 'Espagne'],
'2022': [2500, 3800, 1400],
'2023': [2650, 3950, 1520],
'2024': [2780, 4100, 1630],
})
df_long = df_large.melt(
id_vars='pays',
var_name='annee',
value_name='pib'
)
print(df_long)
pays annee pib
0 France 2022 2500
1 Allemagne 2022 3800
2 Espagne 2022 1400
3 France 2023 2650
4 Allemagne 2023 3950
5 Espagne 2023 1520
6 France 2024 2780
7 Allemagne 2024 4100
8 Espagne 2024 1630
pivot_table() — de long à large avec agrégation#
df_ventes2 = pd.DataFrame({
'region': ['Nord', 'Nord', 'Sud', 'Sud', 'Nord', 'Sud'],
'produit': ['A', 'B', 'A', 'B', 'A', 'B'],
'ventes': [120, 80, 95, 110, 145, 88],
})
pivot = df_ventes2.pivot_table(
values='ventes',
index='region',
columns='produit',
aggfunc='sum',
fill_value=0
)
print(pivot)
produit A B
region
Nord 265 80
Sud 95 198
stack() et unstack() — manipulation des niveaux d’index#
stack() transforme les colonnes en niveaux d’index (passage de large à long), tandis que unstack() fait l’inverse. Ces méthodes sont particulièrement utiles avec les MultiIndex.
# Créer un MultiIndex
idx = pd.MultiIndex.from_tuples(
[('Paris', 'T1'), ('Paris', 'T2'), ('Lyon', 'T1'), ('Lyon', 'T2')],
names=['ville', 'trimestre']
)
df_mi = pd.DataFrame({'ventes': [100, 120, 80, 95], 'coûts': [60, 70, 50, 55]}, index=idx)
print("DataFrame MultiIndex :")
print(df_mi)
print()
print("Après unstack() :")
print(df_mi.unstack('trimestre'))
DataFrame MultiIndex :
ventes coûts
ville trimestre
Paris T1 100 60
T2 120 70
Lyon T1 80 50
T2 95 55
Après unstack() :
ventes coûts
trimestre T1 T2 T1 T2
ville
Lyon 80 95 50 55
Paris 100 120 60 70
Visualisation — Pipeline de nettoyage étape par étape#
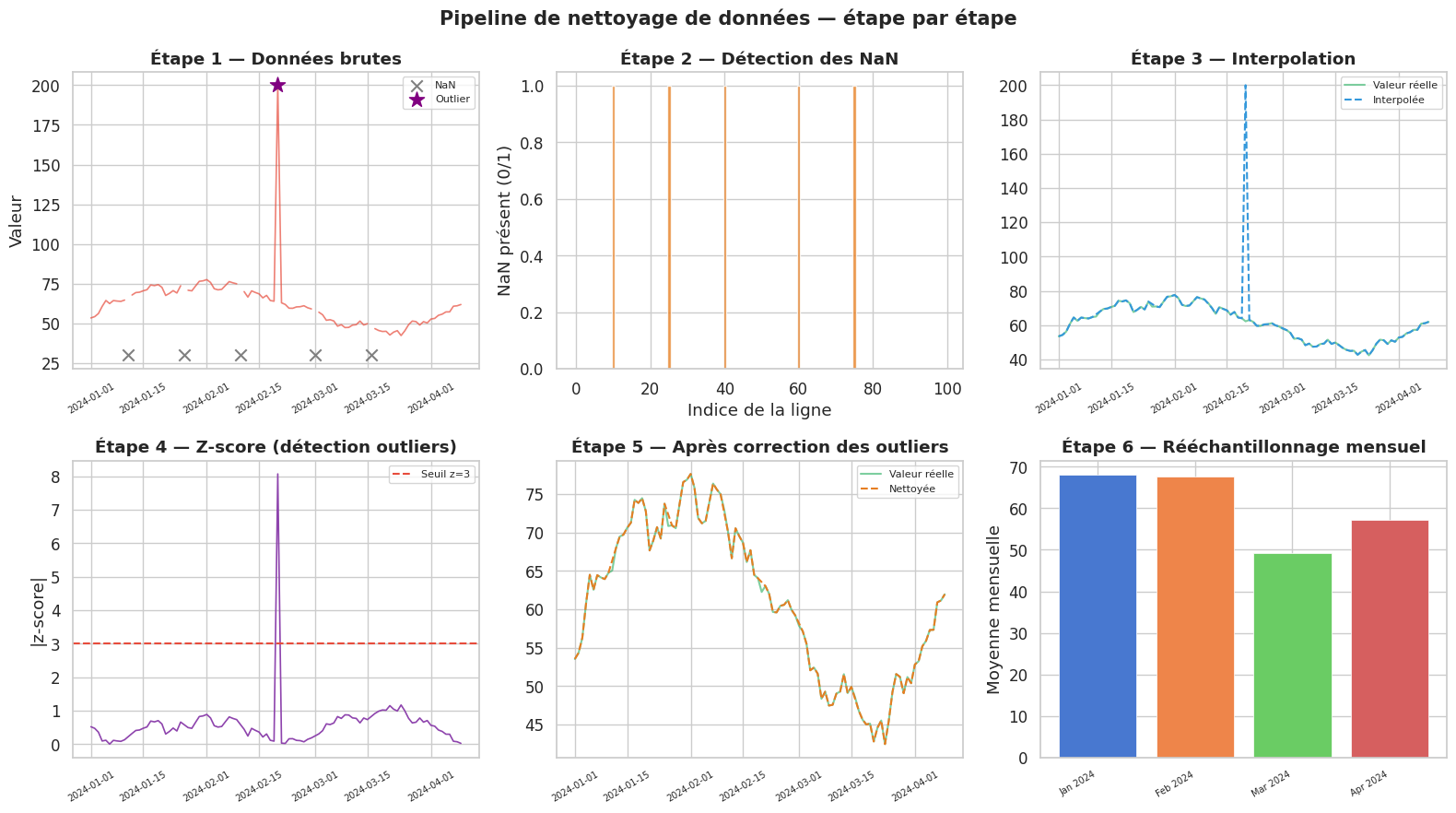
Résumé#
Ce chapitre a couvert les techniques fondamentales de nettoyage et de transformation des données avec Pandas :
Les valeurs manquantes (
NaN,pd.NA) sont détectées avecisna(), supprimées avecdropna()ou imputées avecfillna(),ffill(),bfill()etinterpolate(). Le choix de la stratégie d’imputation dépend du mécanisme d’absence des données.Le nettoyage des types passe par
astype()pour les conversions directes,pd.to_numeric()etpd.to_datetime()pour des conversions robustes avec gestion des erreurs, etpd.Categoricalpour les variables à faible cardinalité.Les transformations de colonnes utilisent
apply()pour les fonctions arbitraires,map()pour les correspondances, ettransform()pour les calculs par groupe qui conservent la forme originale.L”accesseur
.stroffre toutes les méthodes de manipulation de chaînes, y compris les expressions régulières viastr.contains(),str.extract()etstr.replace().L”accesseur
.dtexpose les propriétés temporelles, etresample()permet le rééchantillonnage par période.Le reshaping avec
melt(),pivot_table(),stack()etunstack()permet de passer du format large au format long et vice versa, selon les besoins de l’analyse.
Le chapitre suivant approfondira les opérations de groupement et d’agrégation avec groupby, les jointures entre DataFrames, et les techniques avancées de performance.