Formats de données : Parquet, HDF5, Zarr#
Choisir le bon format de stockage est une décision architecturale fondamentale dans tout projet de data science. Un mauvais choix peut multiplier par dix les temps de chargement, gaspiller plusieurs gigaoctets d’espace disque ou rendre impossible le traitement de données trop volumineuses pour tenir en mémoire. À l’inverse, un format bien adapté au cas d’usage rend les pipelines de données plus rapides, plus fiables et plus faciles à maintenir. Ce chapitre explore les principaux formats modernes — Parquet, HDF5, Zarr et DuckDB — en commençant par comprendre pourquoi le format CSV, omniprésent, ne suffit pas pour les usages avancés.
CSV et ses limites#
Le format CSV (Comma-Separated Values) est universellement lisible : n’importe quel tableur, n’importe quel langage de programmation peut l’ouvrir. C’est la raison pour laquelle il reste si répandu. Mais cette simplicité a un prix, et ce prix devient prohibitif dès que les données dépassent quelques mégaoctets.
Format CSV
Un fichier CSV est un fichier texte brut où chaque ligne représente un enregistrement et chaque valeur est séparée par une virgule (ou un point-virgule, ou une tabulation selon les variantes). Il n’existe aucun standard officiel rigoureux, ce qui entraîne de nombreuses ambiguïtés : encodage des caractères, traitement des guillemets, représentation des valeurs manquantes, format des dates.
Les problèmes structurels du CSV sont nombreux :
Absence de types. Tout est du texte. Lorsque Pandas lit un CSV, il doit inférer le type de chaque colonne en analysant toutes les valeurs. Cette inférence est coûteuse, parfois incorrecte (une colonne de codes postaux peut être lue comme des entiers), et doit être répétée à chaque lecture.
Lenteur de lecture. Le parsing ligne par ligne d’un fichier texte est fondamentalement lent. Lire un CSV de 10 Go prend plusieurs minutes, là où un format binaire colonnaire peut accomplir la même opération en secondes.
Taille. Les nombres sont stockés sous forme textuelle (3.14159265358979 occupe 17 octets, contre 8 octets en virgule flottante double précision). Un fichier CSV est souvent 3 à 10 fois plus volumineux que son équivalent binaire compressé.
Pas d’accès aléatoire. Pour lire la ligne 1 000 000 d’un CSV, il faut parcourir toutes les lignes précédentes. Il est impossible de sauter directement à une position ou de ne lire qu’un sous-ensemble de colonnes sans charger l’intégralité du fichier.
Pas de schéma intégré. Le fichier CSV ne contient aucune information sur le nombre de colonnes, leurs noms, leurs types ou leurs unités. Cette information vit dans la tête du développeur, dans un fichier de documentation séparé, ou dans le code lui-même — toutes des solutions fragiles.
Note
Malgré ses défauts, le CSV reste utile pour les petits jeux de données (quelques milliers de lignes), pour les échanges avec des outils non-techniques (tableurs, outils bureautiques) et pour le débogage (on peut l’ouvrir avec un simple éditeur de texte). Pour tout usage en production avec des volumes importants, un format binaire est préférable.
Parquet : le format colonnaire de référence#
Apache Parquet est un format de fichier binaire à orientation colonnaire, conçu par l’écosystème Hadoop et aujourd’hui largement adopté dans l’ensemble de la data science et de l’ingénierie des données. C’est le format de facto pour les pipelines analytiques modernes.
Stockage colonnaire
Dans un format orienté lignes (comme CSV ou les tables relationnelles traditionnelles), toutes les valeurs d’un enregistrement sont stockées ensemble. Dans un format orienté colonnes, toutes les valeurs d’une même colonne sont stockées ensemble. Pour les requêtes analytiques qui ne lisent que quelques colonnes sur des millions de lignes, le format colonnaire est radicalement plus efficace : on ne lit physiquement que les colonnes nécessaires.
Avantages de Parquet#
Compression efficace. Les valeurs d’une même colonne ont souvent le même type et une distribution similaire. Les algorithmes de compression (Snappy, ZSTD, GZIP) exploitent cette régularité pour obtenir des taux de compression très élevés : un fichier CSV de 10 Go peut tenir en 1 Go au format Parquet.
Schéma intégré. Parquet stocke le schéma complet (noms et types des colonnes) dans les métadonnées du fichier. À la lecture, Pandas ou Polars connaît exactement les types de chaque colonne sans avoir à les inférer.
Projection de colonnes. On peut demander de ne lire que certaines colonnes sans lire le reste du fichier. Sur une table de 100 colonnes dont on n’en utilise que 5, le gain est immédiat.
Partitionnement. On peut diviser un dataset en plusieurs fichiers Parquet selon les valeurs d’une colonne (par exemple, une partition par mois), ce qui permet de ne lire que la partition pertinente.
Utilisation avec Pandas et PyArrow#
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Créer un DataFrame exemple
df = pd.DataFrame({
"date": pd.date_range("2024-01-01", periods=1_000_000, freq="s"),
"valeur": np.random.randn(1_000_000),
"categorie": np.random.choice(["A", "B", "C"], 1_000_000),
})
# Écriture au format Parquet
df.to_parquet("donnees.parquet", compression="snappy", index=False)
# Lecture complète
df_lu = pd.read_parquet("donnees.parquet")
# Lecture de colonnes spécifiques seulement
df_partiel = pd.read_parquet("donnees.parquet", columns=["date", "valeur"])
# Via PyArrow pour plus de contrôle
table = pq.read_table("donnees.parquet", columns=["valeur"])
# Partitionnement par colonne
df.to_parquet(
"donnees_partitionnees/",
partition_cols=["categorie"],
compression="zstd",
)
# Crée : donnees_partitionnees/categorie=A/, categorie=B/, categorie=C/
Compatibilité avec l’écosystème#
Parquet est lu et écrit nativement par Apache Spark, Dask, Polars, DuckDB, AWS Athena, Google BigQuery et tous les grands outils de l’ingénierie des données modernes. Un fichier écrit par un outil Python peut être lu par un cluster Spark sans aucune conversion.
Lecture de Parquet partitionné avec filtrage
PyArrow permet d’appliquer des filtres au niveau du fichier, ce qui évite de charger en mémoire les partitions non pertinentes.
import pyarrow.parquet as pq
import pyarrow.compute as pc
dataset = pq.ParquetDataset(
"donnees_partitionnees/",
filters=[("categorie", "=", "A")],
)
table = dataset.read(columns=["date", "valeur"])
df = table.to_pandas()
HDF5 : format hiérarchique pour les données scientifiques#
HDF5 (Hierarchical Data Format version 5) est un format binaire conçu pour stocker de grandes quantités de données numériques avec une organisation hiérarchique. Il est très utilisé en physique, en bioinformatique, en climatologie et en astrophysique, où les données sont souvent des tableaux multidimensionnels de grande taille.
Structure hiérarchique HDF5
Un fichier HDF5 est organisé comme un système de fichiers virtuel. Il contient des groupes (analogues à des répertoires) et des datasets (analogues à des fichiers, contenant des tableaux numériques). Chaque groupe et dataset peut avoir des attributs — des métadonnées arbitraires (unités, date de création, paramètres d’expérience). Cette organisation permet de stocker de nombreux jeux de données liés dans un seul fichier.
Utilisation avec h5py#
import h5py
import numpy as np
# Créer un fichier HDF5
with h5py.File("experience.h5", "w") as f:
# Créer des groupes (comme des répertoires)
grp_mesures = f.create_group("mesures")
grp_config = f.create_group("configuration")
# Créer des datasets avec compression
temperatures = np.random.randn(1000, 1000)
ds = grp_mesures.create_dataset(
"temperatures",
data=temperatures,
compression="gzip",
compression_opts=6,
chunks=(100, 100), # Chunking pour l'accès partiel
)
# Ajouter des métadonnées (attributs)
ds.attrs["unites"] = "Celsius"
ds.attrs["instrument"] = "Thermomètre IR"
ds.attrs["date"] = "2024-01-15"
grp_config.create_dataset("frequence_Hz", data=np.array([100.0]))
# Lire en accès partiel (sans charger tout le fichier en mémoire)
with h5py.File("experience.h5", "r") as f:
# Accès à un sous-ensemble du dataset
sous_ensemble = f["mesures/temperatures"][0:100, 200:300]
# Lister les attributs
for cle, valeur in f["mesures/temperatures"].attrs.items():
print(f"{cle}: {valeur}")
date: 2024-01-15
instrument: Thermomètre IR
unites: Celsius
Compression et chunking#
Le chunking est une fonctionnalité essentielle de HDF5 : au lieu de stocker le tableau de façon contiguë, on le divise en blocs (chunks) de taille fixe. Cela permet de lire ou écrire uniquement les blocs nécessaires, sans charger tout le dataset en mémoire. C’est particulièrement utile pour les données multidimensionnelles où l’on accède souvent à des tranches (par exemple, une série temporelle sur un sous-ensemble de capteurs).
Note
HDF5 est un format orienté lignes (ou plutôt orienté tableaux multidimensionnels), ce qui le rend moins adapté que Parquet pour les requêtes analytiques typiques de la data science (sélectionner des colonnes sur des millions de lignes). Son point fort est le stockage de tableaux numériques de grande dimension avec des métadonnées riches — ce que Parquet ne gère pas aussi naturellement.
Zarr : stockage en chunks pour le cloud et le calcul distribué#
Zarr est un format de stockage de tableaux numériques en chunks, conçu spécifiquement pour le cloud et le calcul distribué. Contrairement à HDF5 qui stocke tout dans un seul fichier, Zarr stocke chaque chunk dans un fichier séparé (ou un objet cloud séparé), ce qui permet des lectures et écritures parallèles massives.
Store Zarr
Un store Zarr est le backend de stockage utilisé pour persister les chunks. Il peut s’agir d’un répertoire local (chaque chunk est un fichier), d’un bucket S3 (chaque chunk est un objet S3), d’un store GCS, Azure Blob, ou même d’un store en mémoire pour les tests. Cette abstraction permet d’utiliser le même code quelle que soit l’infrastructure de stockage sous-jacente.
Utilisation locale et sur S3#
import zarr
import numpy as np
# Créer un tableau Zarr local
store = zarr.DirectoryStore("tableau.zarr")
root = zarr.group(store=store)
# Créer un dataset avec chunking et compression
z = root.zeros(
"temperatures",
shape=(10_000, 10_000),
chunks=(1_000, 1_000),
dtype="float32",
compressor=zarr.Blosc(cname="zstd", clevel=3),
)
z[:] = np.random.randn(10_000, 10_000)
# Lecture partielle
sous_tableau = z[500:600, 200:400]
# Store sur S3 (nécessite s3fs)
import s3fs
s3 = s3fs.S3FileSystem(anon=False)
store_s3 = s3fs.S3Map(root="mon-bucket/donnees.zarr", s3=s3)
z_s3 = zarr.open(store_s3, mode="r")
Compatibilité avec Xarray#
Zarr est le format de stockage privilégié de Xarray, la bibliothèque Python pour les données multidimensionnelles étiquetées (données climatiques, données satellite, données océanographiques). La combinaison Xarray + Zarr + Dask est la stack standard pour le traitement de grands volumes de données scientifiques.
import xarray as xr
# Ouvrir un dataset Zarr avec Xarray et Dask (lecture paresseuse)
ds = xr.open_zarr("temperatures_globales.zarr", chunks={"temps": 100})
# Calculer la moyenne annuelle avec Dask en arrière-plan
moyenne = ds["temperature"].mean(dim="temps").compute()
DuckDB : SQL analytique haute performance#
DuckDB est un moteur de base de données SQL analytique conçu pour s’exécuter directement dans le processus Python, sans serveur externe. Il peut lire des fichiers Parquet, CSV et JSON directement, sans les importer dans une base de données, et ses performances sur les requêtes analytiques sont exceptionnelles.
Base de données en mémoire (in-process)
DuckDB est une base de données en mémoire et in-process : elle s’exécute dans le même processus que Python, sans serveur, sans port réseau. Elle stocke ses données soit en mémoire, soit dans un fichier .duckdb. Sa conception orientée colonnes la rend particulièrement efficace pour les requêtes analytiques (agrégations, jointures, fenêtres) sur de grandes tables.
Requêtes SQL sur des fichiers Parquet et Pandas#
import duckdb
import pandas as pd
# Connexion (en mémoire)
con = duckdb.connect()
# Requête SQL directement sur un fichier Parquet
resultat = con.execute("""
SELECT
categorie,
AVG(montant) AS montant_moyen,
COUNT(*) AS nb_transactions
FROM read_parquet('ventes.parquet')
WHERE YEAR(date) = 2024
GROUP BY categorie
ORDER BY montant_moyen DESC
""").df() # .df() retourne un DataFrame Pandas
# DuckDB peut aussi interroger un DataFrame Pandas existant directement
df_pandas = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})
resultat2 = duckdb.query("SELECT a, b, a * b AS produit FROM df_pandas").df()
# Exporter le résultat en Parquet
con.execute("""
COPY (SELECT * FROM read_parquet('ventes.parquet') WHERE montant > 1000)
TO 'ventes_filtrees.parquet' (FORMAT PARQUET)
""")
DuckDB excelle pour les analyses ad hoc : explorer un fichier Parquet inconnu, effectuer des jointures entre plusieurs fichiers, ou exécuter des fenêtres glissantes complexes. Sa syntaxe SQL est riche (fenêtres, CTEs, UNNEST, JSON, expressions régulières) et il gère des fichiers de plusieurs dizaines de gigaoctets sans sourciller.
Visualisation : comparaison des formats#
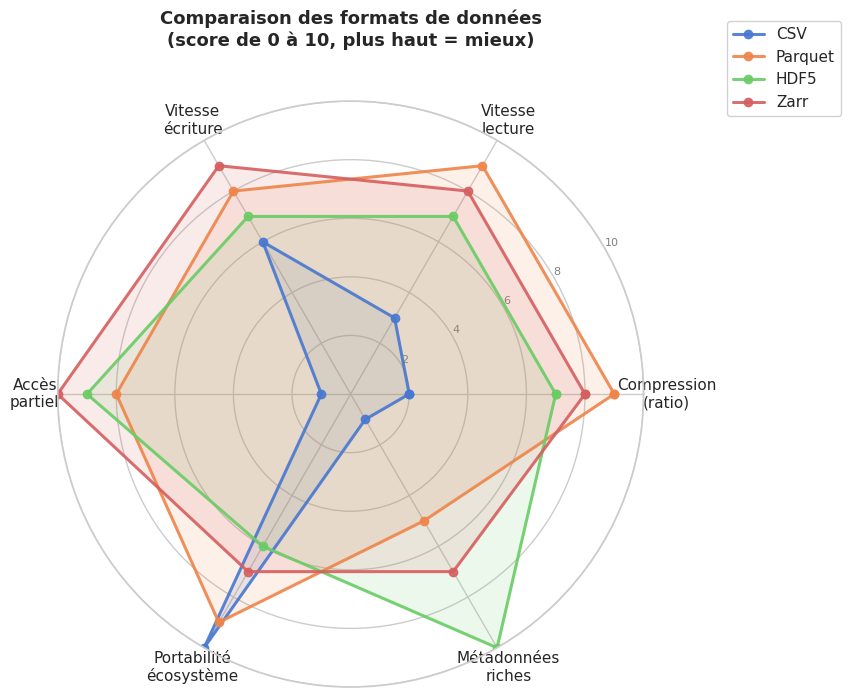
Choisir le bon format#
Le choix du format dépend du contexte d’utilisation. Le tableau suivant synthétise les critères décisifs.
Format |
Taille typique |
Usage principal |
Points forts |
Limites |
|---|---|---|---|---|
CSV |
Quelques Mo |
Échange, débogage |
Universel, lisible |
Lent, pas de types, volumineux |
Parquet |
Go à To |
Data science, ETL |
Rapide, compressé, schéma intégré |
Pas idéal pour les données multidimensionnelles |
HDF5 |
Go à Po |
Science (physique, biologie) |
Hiérarchique, métadonnées riches, accès partiel |
Un seul fichier, pas adapté au cloud |
Zarr |
Go à Po |
Cloud, calcul distribué |
Chunks parallèles, S3 natif, Xarray |
Moins portable que Parquet |
DuckDB |
Go à To |
SQL analytique ad hoc |
SQL expressif, très rapide, pas de serveur |
Pas un format de stockage en soi |
Note
Pour les nouveaux projets de data science, la recommandation générale est la suivante : utiliser Parquet comme format de stockage principal (compatible avec tout l’écosystème), DuckDB pour les explorations et requêtes ad hoc, Zarr si les données sont multidimensionnelles et doivent être accessibles depuis le cloud, et HDF5 uniquement si l’on s’intègre dans un écosystème scientifique qui l’utilise déjà (HEP, bioinformatique, climatologie).
Résumé#
Ce chapitre a présenté les principaux formats de données pour la data science moderne :
CSV : universel et lisible, mais lent, volumineux, sans types et sans schéma. À réserver aux petits jeux de données et aux échanges avec des outils non-techniques.
Parquet : le format colonnaire de référence. Compression efficace, schéma intégré, lecture partielle par colonnes, compatible avec tout l’écosystème (Spark, Dask, Polars, DuckDB). À utiliser par défaut pour les données tabulaires.
HDF5 : format hiérarchique pour les données scientifiques multidimensionnelles. Groupes, datasets, attributs, chunking et compression. Idéal pour les données physiques, biologiques ou climatiques.
Zarr : concurrent de HDF5, conçu pour le cloud et le calcul distribué. Chaque chunk est un fichier ou un objet cloud indépendant, ce qui permet des lectures/écritures parallèles massives. S’intègre nativement avec Xarray et Dask.
DuckDB : moteur SQL in-process ultra-rapide, capable de requêter directement des fichiers Parquet et CSV. Outil d’exploration et d’analyse ad hoc incontournable.
Dans le chapitre suivant, nous abordons les pipelines de données et l’orchestration : comment automatiser, reproduire et surveiller l’enchaînement de ces traitements avec Prefect, MLflow et DVC.