Réseaux de neurones avec nn.Module#
<torch._C.Generator at 0x7fde8d592a90>
nn.Module#
PyTorch organise les réseaux de neurones autour de la classe abstraite torch.nn.Module. Tout composant d’un réseau — une couche, un bloc, ou le réseau entier — est une sous-classe de nn.Module. Cette conception est élégante car elle est récursive : un nn.Module peut contenir d’autres nn.Module comme attributs, formant ainsi un arbre de composants imbriqués.
```{admonition} nn.Module
:class: tip
torch.nn.Module est la classe de base de tous les composants de réseaux de neurones en PyTorch. Toute sous-classe doit implémenter :
__init__(self): appellesuper().__init__()et définit les sous-modules (couches) et les paramètres apprenables.forward(self, x): définit le calcul effectué par le module à partir d’une entréex. Ne jamais appelerforward()directement — appeler l’instance comme une fonction (model(x)) déclenche des mécanismes internes supplémentaires.
class MonPremierReseau(nn.Module):
def __init__(self, n_entrees, n_cachees, n_sorties):
super().__init__()
self.couche1 = nn.Linear(n_entrees, n_cachees)
self.couche2 = nn.Linear(n_cachees, n_sorties)
self.activation = nn.ReLU()
def forward(self, x):
x = self.activation(self.couche1(x))
x = self.couche2(x)
return x
modele = MonPremierReseau(n_entrees=10, n_cachees=32, n_sorties=3)
print(modele)
# Paramètres apprenables
total_params = sum(p.numel() for p in modele.parameters())
trainable_params = sum(p.numel() for p in modele.parameters() if p.requires_grad)
print(f"\nParamètres totaux : {total_params:,}")
print(f"Paramètres entraînable: {trainable_params:,}")
for name, param in modele.named_parameters():
print(f" {name:20s} : {list(param.shape)} ({param.numel()} paramètres)")
# Passe avant sur un batch de 8 exemples
x_batch = torch.randn(8, 10)
sortie = modele(x_batch)
print(f"\nEntrée : {x_batch.shape}")
print(f"Sortie : {sortie.shape}")
MonPremierReseau(
(couche1): Linear(in_features=10, out_features=32, bias=True)
(couche2): Linear(in_features=32, out_features=3, bias=True)
(activation): ReLU()
)
Paramètres totaux : 451
Paramètres entraînable: 451
couche1.weight : [32, 10] (320 paramètres)
couche1.bias : [32] (32 paramètres)
couche2.weight : [3, 32] (96 paramètres)
couche2.bias : [3] (3 paramètres)
Entrée : torch.Size([8, 10])
Sortie : torch.Size([8, 3])
Note
Appeler model(x) plutôt que model.forward(x) déclenche le mécanisme __call__ de PyTorch, qui exécute des hooks enregistrés avant et après le calcul forward. Ces hooks sont utilisés par des outils de profilage, de débogage et par certaines bibliothèques (comme Captum pour l’explicabilité). Ne jamais appeler forward() directement sauf dans les situations très particulières où on veut contourner les hooks.
Couches fondamentales#
PyTorch propose dans torch.nn une bibliothèque très riche de couches prédéfinies. Connaître les plus courantes est indispensable.
nn.Linear est la couche linéaire (aussi appelée couche entièrement connectée ou fully connected) : \(y = xW^T + b\).
# nn.Linear(in_features, out_features, bias=True)
lineaire = nn.Linear(5, 3)
print(f"Poids : {lineaire.weight.shape}") # (3, 5)
print(f"Biais : {lineaire.bias.shape}") # (3,)
x = torch.randn(4, 5)
print(f"Sortie : {lineaire(x).shape}") # (4, 3)
Poids : torch.Size([3, 5])
Biais : torch.Size([3])
Sortie : torch.Size([4, 3])
Les fonctions d’activation sont disponibles sous forme de modules (avec état) dans nn :
# Fonctions d'activation en tant que modules
relu = nn.ReLU()
sigmoid = nn.Sigmoid()
tanh = nn.Tanh()
x = torch.tensor([-2.0, -0.5, 0.0, 1.0, 3.0])
print(f"ReLU : {relu(x)}")
print(f"Sigmoid : {sigmoid(x).round(decimals=3)}")
print(f"Tanh : {tanh(x).round(decimals=3)}")
ReLU : tensor([0., 0., 0., 1., 3.])
Sigmoid : tensor([0.1190, 0.3780, 0.5000, 0.7310, 0.9530])
Tanh : tensor([-0.9640, -0.4620, 0.0000, 0.7620, 0.9950])
nn.Dropout désactive aléatoirement une fraction des neurones pendant l’entraînement pour régulariser le réseau :
dropout = nn.Dropout(p=0.5)
x = torch.ones(10)
# Mode entraînement : certains neurones sont mis à zéro et les autres sont mis à l'échelle
dropout.train()
print(f"Train : {dropout(x)}")
# Mode évaluation : le dropout est désactivé
dropout.eval()
print(f"Eval : {dropout(x)}")
Train : tensor([2., 0., 0., 2., 2., 0., 2., 2., 2., 2.])
Eval : tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
nn.BatchNorm1d normalise les activations au sein d’un batch, ce qui stabilise l’entraînement et accélère la convergence :
# BatchNorm1d(num_features)
bn = nn.BatchNorm1d(8)
x = torch.randn(16, 8) # batch de 16 exemples, 8 caractéristiques
bn.train()
sortie_bn = bn(x)
print(f"Entrée — moyenne : {x.mean():.4f}, std : {x.std():.4f}")
print(f"Sortie — moyenne : {sortie_bn.mean():.4f}, std : {sortie_bn.std():.4f}")
print(f"Gamma (appris) : {bn.weight.data}")
print(f"Beta (appris) : {bn.bias.data}")
Entrée — moyenne : -0.0095, std : 0.9702
Sortie — moyenne : -0.0000, std : 1.0039
Gamma (appris) : tensor([1., 1., 1., 1., 1., 1., 1., 1.])
Beta (appris) : tensor([0., 0., 0., 0., 0., 0., 0., 0.])
nn.Sequential#
nn.Sequential est un conteneur qui applique les couches dans l’ordre où elles ont été ajoutées. C’est la façon la plus concise de définir un réseau linéaire simple.
# Construction avec des arguments positionnels
mlp = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 10),
)
print(mlp)
total = sum(p.numel() for p in mlp.parameters())
print(f"\nTotal de paramètres : {total:,}")
Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Dropout(p=0.3, inplace=False)
(4): Linear(in_features=512, out_features=256, bias=True)
(5): ReLU()
(6): Dropout(p=0.3, inplace=False)
(7): Linear(in_features=256, out_features=10, bias=True)
)
Total de paramètres : 536,842
On peut aussi construire un Sequential à partir d’un dictionnaire ordonné pour donner des noms aux couches :
from collections import OrderedDict
mlp_nomme = nn.Sequential(OrderedDict([
('fc1', nn.Linear(784, 256)),
('relu1', nn.ReLU()),
('drop1', nn.Dropout(0.3)),
('fc2', nn.Linear(256, 10)),
]))
print(mlp_nomme)
# Accès par nom
print(f"\nPoids de fc1 : {mlp_nomme.fc1.weight.shape}")
Sequential(
(fc1): Linear(in_features=784, out_features=256, bias=True)
(relu1): ReLU()
(drop1): Dropout(p=0.3, inplace=False)
(fc2): Linear(in_features=256, out_features=10, bias=True)
)
Poids de fc1 : torch.Size([256, 784])
Note
nn.Sequential est idéal pour les architectures simples et linéaires. Ses limites apparaissent dès que l’architecture devient plus complexe : connexions résiduelles, sorties multiples, branches parallèles, accès aux activations intermédiaires. Dans ces cas, il faut impérativement recourir à l’héritage direct de nn.Module avec un forward personnalisé.
Réseaux personnalisés#
La véritable puissance de nn.Module se révèle lorsqu’on définit des architectures personnalisées avec un forward explicite. Voici un exemple avec des connexions résiduelles (residual connections), le mécanisme central des architectures ResNet.
Connexion résiduelle
Une connexion résiduelle (ou skip connection) permet à l’entrée d’un bloc de « court-circuiter » ce bloc et de s’additionner à sa sortie : \(y = F(x) + x\). Cette idée simple, introduite par He et al. (2016) dans ResNet, résout le problème de la dégradation des gradients dans les très réseaux profonds : le gradient peut circuler directement via la connexion résiduelle, sans traverser les couches du bloc.
class BlocResiduel(nn.Module):
"""Bloc résiduel simple : y = F(x) + x"""
def __init__(self, n_features):
super().__init__()
self.couche1 = nn.Linear(n_features, n_features)
self.bn1 = nn.BatchNorm1d(n_features)
self.couche2 = nn.Linear(n_features, n_features)
self.bn2 = nn.BatchNorm1d(n_features)
self.relu = nn.ReLU()
def forward(self, x):
residuel = x # ← la connexion résiduelle
x = self.relu(self.bn1(self.couche1(x)))
x = self.bn2(self.couche2(x))
x = self.relu(x + residuel) # ← addition du résidu
return x
class ReseauResiduel(nn.Module):
"""MLP avec blocs résiduels."""
def __init__(self, n_entrees, n_cachees, n_sorties, n_blocs=3):
super().__init__()
self.projection = nn.Linear(n_entrees, n_cachees)
self.blocs = nn.ModuleList([
BlocResiduel(n_cachees) for _ in range(n_blocs)
])
self.classifieur = nn.Linear(n_cachees, n_sorties)
def forward(self, x):
x = F.relu(self.projection(x))
for bloc in self.blocs:
x = bloc(x)
x = self.classifieur(x)
return x
resnet_mlp = ReseauResiduel(n_entrees=20, n_cachees=64, n_sorties=5, n_blocs=4)
print(resnet_mlp)
print(f"\nParamètres totaux : {sum(p.numel() for p in resnet_mlp.parameters()):,}")
ReseauResiduel(
(projection): Linear(in_features=20, out_features=64, bias=True)
(blocs): ModuleList(
(0-3): 4 x BlocResiduel(
(couche1): Linear(in_features=64, out_features=64, bias=True)
(bn1): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(couche2): Linear(in_features=64, out_features=64, bias=True)
(bn2): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(classifieur): Linear(in_features=64, out_features=5, bias=True)
)
Paramètres totaux : 35,973
Note
nn.ModuleList et nn.ModuleDict sont des conteneurs spéciaux qui permettent de stocker des listes ou des dictionnaires de sous-modules tout en les enregistrant correctement auprès de PyTorch. Si on utilise une liste Python ordinaire (self.blocs = [...]), les modules ne seront pas détectés par parameters(), state_dict() ou les appels .to(device). Il faut donc toujours utiliser nn.ModuleList pour les listes de modules.
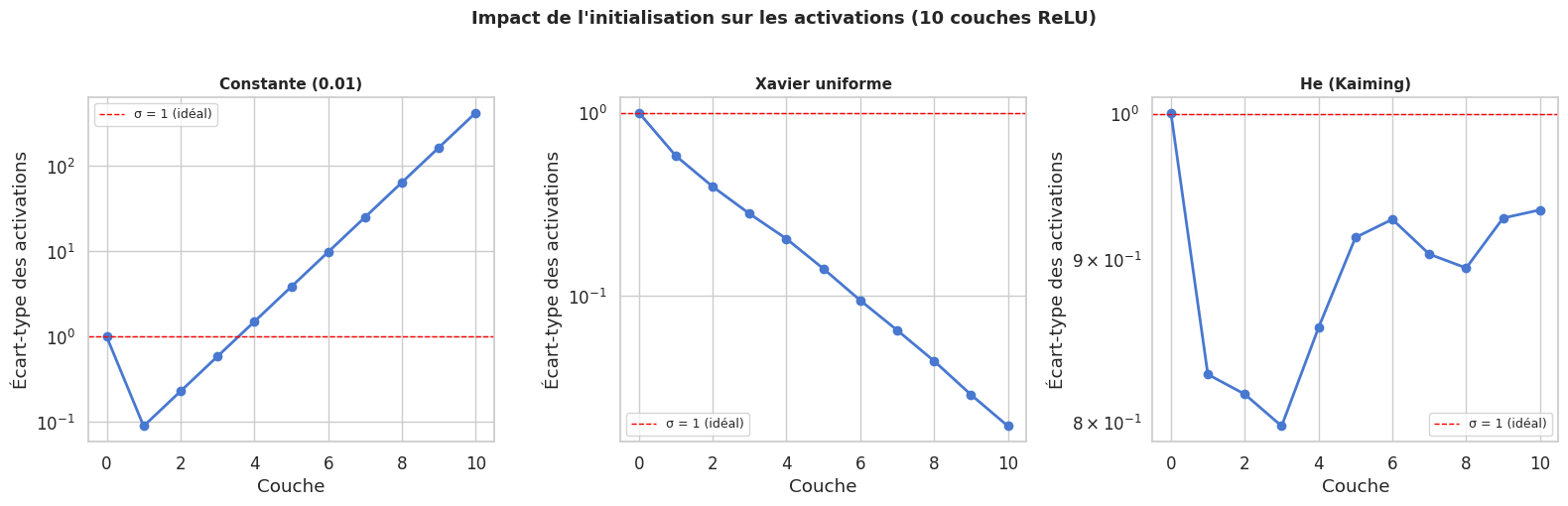
Initialisation des poids#
L’initialisation des poids d’un réseau de neurones a un impact majeur sur la convergence de l’entraînement. Une mauvaise initialisation peut provoquer l’explosion ou la disparition des gradients dès les premières itérations.
Initialisation de Xavier et de He
Initialisation de Xavier (Glorot) : \(W \sim \mathcal{U}\left(-\sqrt{\frac{6}{n_{in} + n_{out}}},\ \sqrt{\frac{6}{n_{in} + n_{out}}}\right)\). Conçue pour les activations symétriques (tanh, sigmoid). Elle assure que la variance des activations reste constante à travers les couches.
Initialisation de He (Kaiming) : \(W \sim \mathcal{N}\left(0,\ \frac{2}{n_{in}}\right)\). Conçue pour les activations ReLU, qui suppriment la moitié des activations. Elle tient compte de ce facteur en doublant la variance cible.
def initialiser_poids(modele):
"""Applique l'initialisation de He à toutes les couches linéaires."""
for module in modele.modules():
if isinstance(module, nn.Linear):
nn.init.kaiming_normal_(module.weight, mode='fan_in',
nonlinearity='relu')
if module.bias is not None:
nn.init.zeros_(module.bias)
elif isinstance(module, nn.BatchNorm1d):
nn.init.ones_(module.weight)
nn.init.zeros_(module.bias)
# Avant initialisation personnalisée
modele_avant = nn.Linear(10, 5)
print(f"Avant — moyenne : {modele_avant.weight.mean():.4f}, "
f"std : {modele_avant.weight.std():.4f}")
# Après initialisation de He
nn.init.kaiming_normal_(modele_avant.weight, nonlinearity='relu')
print(f"Après He — moyenne : {modele_avant.weight.mean():.4f}, "
f"std : {modele_avant.weight.std():.4f}")
# Initialisation de Xavier uniforme
nn.init.xavier_uniform_(modele_avant.weight)
print(f"Après Xavier — moyenne : {modele_avant.weight.mean():.4f}, "
f"std : {modele_avant.weight.std():.4f}")
Avant — moyenne : -0.0088, std : 0.1885
Après He — moyenne : 0.0821, std : 0.4061
Après Xavier — moyenne : 0.0268, std : 0.3675
Architecture MLP complète pour la classification MNIST
Voici un réseau MLP complet pour classer les chiffres manuscrits MNIST (28×28 pixels, 10 classes) :
class MLP_MNIST(nn.Module):
def __init__(self, dropout_rate=0.3):
super().__init__()
self.reseau = nn.Sequential(
nn.Flatten(), # (B, 1, 28, 28) → (B, 784)
nn.Linear(784, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(dropout_rate),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(dropout_rate),
nn.Linear(256, 10), # 10 classes, pas de softmax
)
# Initialisation de He
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight)
nn.init.zeros_(m.bias)
def forward(self, x):
return self.reseau(x)
modele = MLP_MNIST()
x_test = torch.randn(32, 1, 28, 28)
print(modele(x_test).shape) # torch.Size([32, 10])
Résumé#
Ce chapitre a détaillé l’architecture des réseaux de neurones en PyTorch :
nn.Moduleest la classe de base universelle. Toute architecture, simple ou complexe, hérite denn.Moduleet implémente__init__(définition des sous-modules) etforward(calcul de la sortie). Les paramètres apprenables sont automatiquement détectés et accessibles viaparameters().Les couches fondamentales du module
nn—Linear,ReLU,Sigmoid,Tanh,Dropout,BatchNorm1d— couvrent la majorité des besoins pour les réseaux entièrement connectés. Chacune a ses cas d’usage spécifiques : la BatchNorm stabilise l’entraînement, le Dropout régularise.nn.Sequentialpermet de construire rapidement des architectures linéaires en empilant des couches.OrderedDictpermet de nommer chaque couche. Ses limites apparaissent pour les architectures non linéaires.Les réseaux personnalisés s’appuient sur l’héritage de
nn.Moduleet unforwardexplicite. Les connexions résiduelles (ResNet) illustrent la puissance de cette approche : elles permettent d’entraîner des réseaux très profonds en préservant le flux des gradients.L”initialisation des poids est cruciale : l’initialisation de He est recommandée pour les activations ReLU, Xavier pour tanh et sigmoid. Une mauvaise initialisation peut provoquer l’explosion ou la disparition des gradients dès le début de l’entraînement.
Le chapitre suivant explique comment entraîner concrètement ces réseaux : la boucle d’entraînement, les optimiseurs, les fonctions de perte et les techniques de régularisation avancées.