Évaluation et sélection de modèles#
Biais et variance#
Tout modèle d’apprentissage automatique est soumis à une tension fondamentale entre deux sources d’erreur antagonistes : le biais et la variance. Comprendre ce dilemme est indispensable pour diagnostiquer les problèmes d’un modèle et choisir les bonnes stratégies de remédiation.
Biais et variance
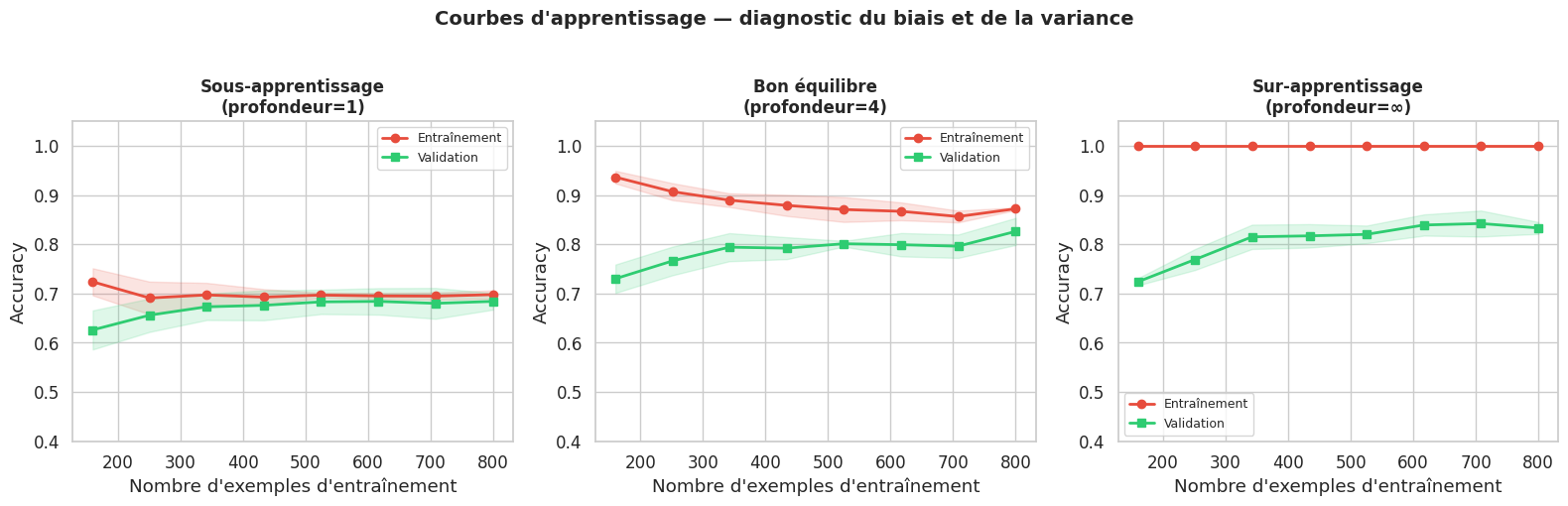
Le biais (bias) mesure à quel point les prédictions d’un modèle s’écartent systématiquement de la vérité. Un modèle à fort biais fait des hypothèses trop simplistes sur les données — il ne parvient pas à capturer la complexité réelle du phénomène. On parle de sous-apprentissage (underfitting).
La variance mesure la sensibilité du modèle aux fluctuations des données d’entraînement. Un modèle à forte variance s’est trop adapté aux données d’entraînement, au point de mémoriser leur bruit plutôt que d’apprendre la structure sous-jacente. On parle de sur-apprentissage (overfitting).
L’erreur totale d’un modèle peut se décomposer mathématiquement en trois termes :
où \(\sigma^2\) est l’erreur irréductible due au bruit inhérent aux données. Cette décomposition montre qu’il est impossible d’éliminer simultanément le biais et la variance : réduire l’un tend à augmenter l’autre. C’est le dilemme biais-variance (bias-variance tradeoff).
Note
En pratique, on distingue trois régimes :
Sous-apprentissage : le modèle est trop simple. Il réalise de mauvaises performances à la fois sur les données d’entraînement et sur les données de test. Remèdes : augmenter la complexité du modèle, ajouter des caractéristiques, réduire la régularisation.
Bon équilibre : les erreurs d’entraînement et de test sont toutes deux faibles et proches l’une de l’autre. C’est l’objectif visé.
Sur-apprentissage : le modèle est trop complexe. Il performe très bien sur l’entraînement mais mal sur le test. Remèdes : réduire la complexité, ajouter de la régularisation, collecter davantage de données.
Les courbes d’apprentissage (learning curves) sont l’outil de diagnostic par excellence. Elles représentent les performances d’entraînement et de validation en fonction du nombre d’exemples d’entraînement utilisés, et permettent d’identifier visuellement la nature du problème.
Validation croisée#
La validation croisée (cross-validation) est la technique standard pour évaluer de façon fiable les performances généralisées d’un modèle. Elle résout le problème fondamental de tout protocole d’évaluation : la variabilité liée au choix particulier du découpage entraînement/test.
Validation croisée à k plis
La validation croisée à k plis (k-fold cross-validation) divise le jeu de données en \(k\) sous-ensembles (plis) de taille approximativement égale. Le modèle est entraîné \(k\) fois : à chaque itération, \(k-1\) plis servent à l’entraînement et le pli restant sert à l’évaluation. Les \(k\) scores obtenus sont ensuite agrégés — généralement par leur moyenne et leur écart-type — pour produire une estimation robuste des performances.
La fonction cross_val_score de scikit-learn est le point d’entrée le plus direct :
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score, KFold
X_iris, y_iris = load_iris(return_X_y=True)
# Validation croisée à 5 plis
model = LogisticRegression(max_iter=200)
scores = cross_val_score(model, X_iris, y_iris, cv=5, scoring='accuracy')
print(f"Scores par pli : {scores.round(4)}")
print(f"Moyenne : {scores.mean():.4f} ± {scores.std():.4f}")
Scores par pli : [0.9667 1. 0.9333 0.9667 1. ]
Moyenne : 0.9733 ± 0.0249
La classe KFold donne un contrôle plus fin sur le découpage :
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for fold, (train_idx, val_idx) in enumerate(kf.split(X_iris)):
X_train, X_val = X_iris[train_idx], X_iris[val_idx]
y_train, y_val = y_iris[train_idx], y_iris[val_idx]
model.fit(X_train, y_train)
score = model.score(X_val, y_val)
print(f"Pli {fold + 1} — taille entraînement : {len(train_idx)}, "
f"taille validation : {len(val_idx)}, accuracy : {score:.4f}")
Pli 1 — taille entraînement : 120, taille validation : 30, accuracy : 1.0000
Pli 2 — taille entraînement : 120, taille validation : 30, accuracy : 1.0000
Pli 3 — taille entraînement : 120, taille validation : 30, accuracy : 0.9333
Pli 4 — taille entraînement : 120, taille validation : 30, accuracy : 0.9667
Pli 5 — taille entraînement : 120, taille validation : 30, accuracy : 0.9667
Pour les problèmes de classification avec des classes déséquilibrées, StratifiedKFold garantit que chaque pli respecte la distribution des classes originale :
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores_stratified = cross_val_score(model, X_iris, y_iris, cv=skf, scoring='accuracy')
print(f"StratifiedKFold — Moyenne : {scores_stratified.mean():.4f} ± {scores_stratified.std():.4f}")
StratifiedKFold — Moyenne : 0.9667 ± 0.0298
LeaveOneOut est un cas extrême de la validation croisée où \(k = n\) : chaque exemple est tour à tour le seul élément de l’ensemble de validation. Cette approche est très coûteuse en calcul mais produit une estimation presque sans biais, particulièrement utile lorsque les données sont très rares.
from sklearn.model_selection import LeaveOneOut
# Illustré sur un petit sous-ensemble équilibré (10 exemples par classe)
idx = np.concatenate([np.where(y_iris == c)[0][:10] for c in np.unique(y_iris)])
X_small, y_small = X_iris[idx], y_iris[idx]
loo = LeaveOneOut()
scores_loo = cross_val_score(model, X_small, y_small, cv=loo)
print(f"LeaveOneOut ({loo.get_n_splits(X_small)} plis) — "
f"Moyenne : {scores_loo.mean():.4f} ± {scores_loo.std():.4f}")
LeaveOneOut (30 plis) — Moyenne : 0.9667 ± 0.1795
La fonction cross_validate va plus loin que cross_val_score : elle renvoie les scores sur l’entraînement et sur la validation, ainsi que les temps d’entraînement et de prédiction.
from sklearn.model_selection import cross_validate
results = cross_validate(
model, X_iris, y_iris, cv=5,
scoring=['accuracy', 'f1_macro'],
return_train_score=True
)
for key, values in results.items():
print(f"{key:30s} : {values.round(4)}")
fit_time : [0.0167 0.0212 0.0154 0.0157 0.0151]
score_time : [0.0032 0.0032 0.0028 0.0028 0.0029]
test_accuracy : [0.9667 1. 0.9333 0.9667 1. ]
train_accuracy : [0.9667 0.9667 0.9833 0.9833 0.975 ]
test_f1_macro : [0.9666 1. 0.9327 0.9666 1. ]
train_f1_macro : [0.9666 0.9666 0.9833 0.9833 0.975 ]
Note
Le choix du nombre de plis \(k\) résulte d’un compromis. Avec \(k = 5\) ou \(k = 10\), on obtient une bonne estimation avec un coût de calcul raisonnable. Un \(k\) élevé réduit le biais de l’estimation (les modèles sont entraînés sur presque toutes les données) mais augmente la variance et le temps de calcul. La règle empirique la plus répandue est d’utiliser \(k = 5\) comme valeur par défaut et \(k = 10\) lorsque les données sont abondantes.
Métriques de régression#
Pour les problèmes de régression, plusieurs métriques permettent de quantifier la qualité des prédictions numériques. Chacune possède ses propres propriétés et interprétations.
Métriques de régression fondamentales
Soient \(y_i\) les valeurs réelles et \(\hat{y}_i\) les prédictions pour \(n\) observations :
MAE (Mean Absolute Error) : \(\text{MAE} = \frac{1}{n}\sum_{i=1}^n |y_i - \hat{y}_i|\). Robuste aux valeurs aberrantes, exprimée dans la même unité que la cible.
MSE (Mean Squared Error) : \(\text{MSE} = \frac{1}{n}\sum_{i=1}^n (y_i - \hat{y}_i)^2\). Pénalise fortement les grandes erreurs ; sensible aux outliers.
RMSE (Root MSE) : \(\text{RMSE} = \sqrt{\text{MSE}}\). Même unité que la cible, plus interprétable que le MSE.
R² (coefficient de détermination) : \(R^2 = 1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2}\). Mesure la part de variance expliquée par le modèle ; vaut 1 pour un modèle parfait et peut être négatif pour un modèle pire que la moyenne.
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
housing = fetch_california_housing()
X_h, y_h = housing.data, housing.target
X_train_h, X_test_h, y_train_h, y_test_h = train_test_split(
X_h, y_h, test_size=0.2, random_state=42
)
models_reg = {
"Régression linéaire": Pipeline([
('scaler', StandardScaler()),
('model', LinearRegression())
]),
"Ridge (α=1.0)": Pipeline([
('scaler', StandardScaler()),
('model', Ridge(alpha=1.0))
]),
"Forêt aléatoire": RandomForestRegressor(n_estimators=100, random_state=42),
}
print(f"{'Modèle':<25} {'MAE':>8} {'RMSE':>8} {'R²':>8} {'MAPE':>8}")
print("-" * 65)
for name, mdl in models_reg.items():
mdl.fit(X_train_h, y_train_h)
y_pred = mdl.predict(X_test_h)
mae = mean_absolute_error(y_test_h, y_pred)
rmse = np.sqrt(mean_squared_error(y_test_h, y_pred))
r2 = r2_score(y_test_h, y_pred)
# MAPE manuel
mape = np.mean(np.abs((y_test_h - y_pred) / (y_test_h + 1e-8))) * 100
print(f"{name:<25} {mae:>8.3f} {rmse:>8.3f} {r2:>8.3f} {mape:>7.1f}%")
Modèle MAE RMSE R² MAPE
-----------------------------------------------------------------
Régression linéaire 0.533 0.746 0.576 32.0%
Ridge (α=1.0) 0.533 0.746 0.576 32.0%
Forêt aléatoire 0.328 0.505 0.805 18.9%
Note
Le MAPE (Mean Absolute Percentage Error) est particulièrement utile lorsque les valeurs cibles sont d’ordres de grandeur très différents, car il exprime l’erreur en pourcentage. Cependant, il devient instable lorsque les valeurs cibles sont proches de zéro (division par un petit nombre). Dans ce cas, des variantes comme le sMAPE (symmetric MAPE) sont préférables.
Métriques de classification#
L’évaluation d’un classifieur est plus riche que celle d’un régresseur, car elle intègre la notion de types d’erreurs. La matrice de confusion est le point de départ de toute analyse.
Matrice de confusion et métriques dérivées
Pour un problème binaire avec une classe positive et une classe négative :
VP (vrais positifs) : exemples positifs correctement classés.
VN (vrais négatifs) : exemples négatifs correctement classés.
FP (faux positifs) : exemples négatifs classés comme positifs (erreur de type I).
FN (faux négatifs) : exemples positifs classés comme négatifs (erreur de type II).
Les métriques dérivées sont :
Accuracy : \(\frac{VP + VN}{VP + VN + FP + FN}\)
Précision : \(\frac{VP}{VP + FP}\) — parmi les prédictions positives, quelle fraction est réellement positive ?
Rappel (recall ou sensibilité) : \(\frac{VP}{VP + FN}\) — parmi les exemples réellement positifs, quelle fraction est détectée ?
F1 : \(\frac{2 \times \text{Précision} \times \text{Rappel}}{\text{Précision} + \text{Rappel}}\) — moyenne harmonique, équilibre entre précision et rappel.
X_clf, y_clf = make_classification(n_samples=1000, n_features=20,
n_informative=10, random_state=42)
X_tr, X_te, y_tr, y_te = train_test_split(X_clf, y_clf, test_size=0.3,
random_state=42)
clf_models = {
"Régression logistique": LogisticRegression(max_iter=500),
"Forêt aléatoire": RandomForestClassifier(n_estimators=100, random_state=42),
"Gradient Boosting": GradientBoostingClassifier(n_estimators=100, random_state=42),
}
for name, clf in clf_models.items():
clf.fit(X_tr, y_tr)
y_pred = clf.predict(X_te)
print(f"\n=== {name} ===")
print(classification_report(y_te, y_pred, target_names=["Classe 0", "Classe 1"]))
=== Régression logistique ===
precision recall f1-score support
Classe 0 0.88 0.78 0.83 153
Classe 1 0.80 0.88 0.84 147
accuracy 0.83 300
macro avg 0.84 0.83 0.83 300
weighted avg 0.84 0.83 0.83 300
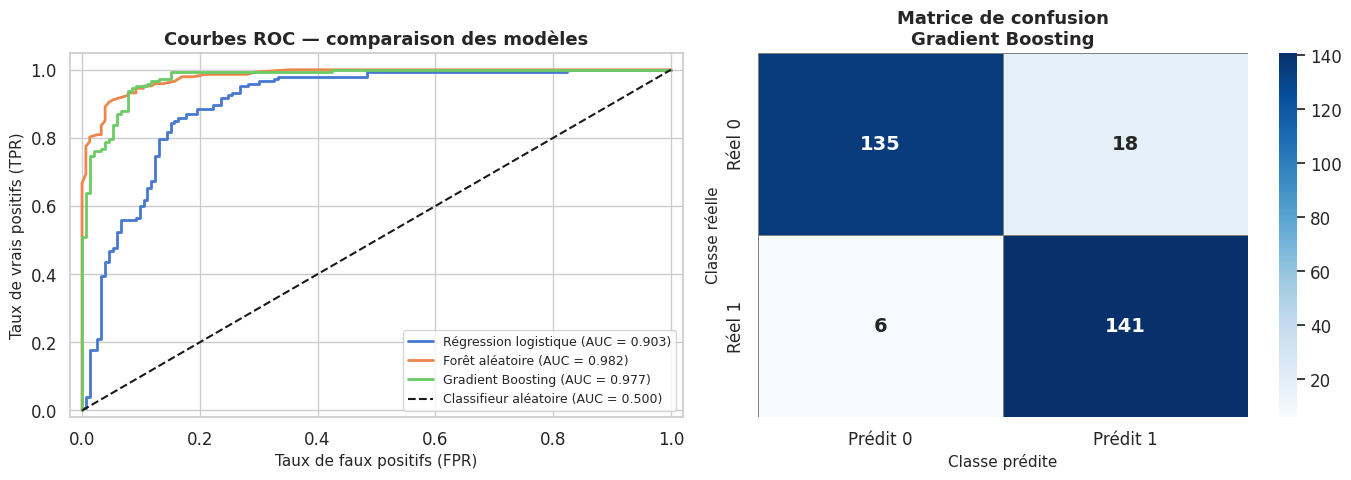
=== Forêt aléatoire ===
precision recall f1-score support
Classe 0 0.95 0.90 0.92 153
Classe 1 0.90 0.95 0.92 147
accuracy 0.92 300
macro avg 0.92 0.92 0.92 300
weighted avg 0.92 0.92 0.92 300
=== Gradient Boosting ===
precision recall f1-score support
Classe 0 0.96 0.88 0.92 153
Classe 1 0.89 0.96 0.92 147
accuracy 0.92 300
macro avg 0.92 0.92 0.92 300
weighted avg 0.92 0.92 0.92 300
La courbe ROC (Receiver Operating Characteristic) et son aire sous la courbe (AUC) permettent d’évaluer la qualité discriminante d’un classifieur indépendamment du seuil de décision.
Choisir la bonne métrique selon le contexte
Le choix de la métrique dépend du coût relatif des erreurs :
Détection de cancer : le faux négatif (ne pas détecter un cancer) est catastrophique. On privilégie le rappel maximal, quitte à tolérer plus de faux positifs.
Filtre anti-spam : un faux positif (supprimer un courriel légitime) est très gênant. On privilégie la précision élevée.
Système de recommandation : on cherche un équilibre entre précision et rappel ; le F1 ou l”AUC-ROC sont des choix pertinents.
Classes très déséquilibrées (1 % de positifs) : l’accuracy est trompeuse (un modèle qui prédit toujours « négatif » atteint 99 %). On préfère l”AUC, le F1 ou la précision-rappel AUC.
Sélection de modèles#
Sélectionner le meilleur modèle parmi plusieurs candidats requiert une démarche rigoureuse qui va au-delà de la simple comparaison des scores moyens. Il faut tenir compte de la variabilité des estimations, du coût de calcul, de l’interprétabilité et des contraintes de déploiement.
Protocole de sélection rigoureuse
Un protocole de sélection rigoureuse repose sur trois ensembles distincts :
Ensemble d’entraînement : utilisé pour ajuster les paramètres du modèle.
Ensemble de validation (ou plis de validation croisée) : utilisé pour sélectionner les hyperparamètres et comparer les architectures.
Ensemble de test : utilisé une seule fois, en fin de processus, pour estimer les performances réelles. Il ne doit jamais influencer les décisions de modélisation.
La comparaison statistique de modèles utilise souvent le test de Wilcoxon ou le test t apparié sur les scores obtenus par validation croisée :
from scipy import stats
# Comparer deux modèles par leurs scores de validation croisée
cv_lr = cross_val_score(LogisticRegression(max_iter=500), X_clf, y_clf,
cv=10, scoring='roc_auc')
cv_rf = cross_val_score(RandomForestClassifier(n_estimators=100, random_state=42),
X_clf, y_clf, cv=10, scoring='roc_auc')
stat, pvalue = stats.wilcoxon(cv_lr, cv_rf)
print(f"Régression logistique — AUC : {cv_lr.mean():.4f} ± {cv_lr.std():.4f}")
print(f"Forêt aléatoire — AUC : {cv_rf.mean():.4f} ± {cv_rf.std():.4f}")
print(f"Test de Wilcoxon : statistique = {stat:.3f}, p-valeur = {pvalue:.4f}")
print(f"Différence significative (α=0.05) : {'Oui' if pvalue < 0.05 else 'Non'}")
Régression logistique — AUC : 0.9154 ± 0.0379
Forêt aléatoire — AUC : 0.9830 ± 0.0109
Test de Wilcoxon : statistique = 0.000, p-valeur = 0.0020
Différence significative (α=0.05) : Oui
MLflow est la bibliothèque de référence pour le suivi des expériences d’apprentissage automatique. Elle permet d’enregistrer automatiquement les paramètres, les métriques et les artefacts de chaque expérience, de les comparer dans une interface web et de reproductibiliser les résultats.
import mlflow
import mlflow.sklearn
# Démarrer une expérience MLflow
mlflow.set_experiment("selection_modeles")
with mlflow.start_run(run_name="foret_aleatoire"):
# Paramètres du modèle
n_estimators = 100
max_depth = 5
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("max_depth", max_depth)
# Entraînement
rf = RandomForestClassifier(n_estimators=n_estimators,
max_depth=max_depth, random_state=42)
rf.fit(X_tr, y_tr)
# Métriques
auc_score = roc_auc_score(y_te, rf.predict_proba(X_te)[:, 1])
mlflow.log_metric("auc", auc_score)
mlflow.log_metric("accuracy", rf.score(X_te, y_te))
# Sauvegarder le modèle
mlflow.sklearn.log_model(rf, "model")
print(f"AUC enregistré : {auc_score:.4f}")
Note
L’interface web de MLflow (mlflow ui) permet de visualiser et comparer toutes les expériences passées dans un tableau de bord interactif. Elle facilite notamment la détection de corrélations entre hyperparamètres et performances, et la sélection du meilleur run pour la mise en production. MLflow s’intègre aussi bien avec scikit-learn qu’avec PyTorch, TensorFlow ou XGBoost.
Résumé#
Ce chapitre a posé les bases d’une évaluation rigoureuse des modèles d’apprentissage automatique :
Le dilemme biais-variance est la tension fondamentale de tout apprentissage : un modèle trop simple sous-apprend (fort biais), un modèle trop complexe sur-apprend (forte variance). Les courbes d’apprentissage permettent de diagnostiquer visuellement ces deux régimes.
La validation croisée est la technique standard pour estimer les performances généralisées d’un modèle.
KFold,StratifiedKFoldetcross_validateoffrent différents niveaux de contrôle et d’information.Pour la régression, le MAE, le RMSE et le R² sont les métriques principales. Le choix dépend de la sensibilité souhaitée aux valeurs aberrantes et de la nécessité d’une interprétabilité directe.
Pour la classification, la matrice de confusion révèle la nature des erreurs. La précision, le rappel, le F1 et l’AUC-ROC permettent d’évaluer différents aspects du classifieur selon le contexte métier.
La sélection de modèles doit s’appuyer sur des tests statistiques (Wilcoxon, test t) et un protocole à trois ensembles. MLflow facilite le suivi et la reproductibilité des expériences.
Le chapitre suivant marque une transition vers le deep learning : nous découvrirons PyTorch, sa représentation des données sous forme de tenseurs et son mécanisme de différentiation automatique (autograd), qui constituent le socle de tout réseau de neurones moderne.