SQL moderne et bonnes pratiques#
Ce dernier chapitre réunit les pratiques qui distinguent un SQL écrit par quelqu’un qui « sait utiliser SQL » de celui écrit par quelqu’un qui « maîtrise SQL ». Il ne s’agit pas de fonctionnalités isolées mais d’une philosophie : écrire du SQL lisible, maintenable, sécurisé et mesurable.
Style et conventions#
Formatage#
Un SQL bien formaté se lit comme de la prose structurée. Les conventions varient selon les équipes, mais la cohérence interne est primordiale.
# Exemple de style : avant / après
avant = """
select u.id,u.nom,count(c.id) as nb,sum(c.montant) as total from utilisateurs u left join commandes c on u.id=c.user_id where u.actif=1 and c.date_commande>='2024-01-01' group by u.id,u.nom having count(c.id)>5 order by total desc limit 20
"""
apres = """
SELECT
u.id,
u.nom,
COUNT(c.id) AS nb_commandes,
SUM(c.montant) AS total_achats
FROM utilisateurs AS u
LEFT JOIN commandes AS c
ON u.id = c.user_id
WHERE
u.actif = TRUE
AND c.date_commande >= '2024-01-01'
GROUP BY
u.id,
u.nom
HAVING COUNT(c.id) > 5
ORDER BY total_achats DESC
LIMIT 20;
"""
print("=== AVANT (illisible) ===")
print(avant.strip())
print("\n=== APRÈS (style professionnel) ===")
print(apres.strip())
=== AVANT (illisible) ===
select u.id,u.nom,count(c.id) as nb,sum(c.montant) as total from utilisateurs u left join commandes c on u.id=c.user_id where u.actif=1 and c.date_commande>='2024-01-01' group by u.id,u.nom having count(c.id)>5 order by total desc limit 20
=== APRÈS (style professionnel) ===
SELECT
u.id,
u.nom,
COUNT(c.id) AS nb_commandes,
SUM(c.montant) AS total_achats
FROM utilisateurs AS u
LEFT JOIN commandes AS c
ON u.id = c.user_id
WHERE
u.actif = TRUE
AND c.date_commande >= '2024-01-01'
GROUP BY
u.id,
u.nom
HAVING COUNT(c.id) > 5
ORDER BY total_achats DESC
LIMIT 20;
Règles de nommage#

Éviter les anti-patterns#
SELECT * en production#
conn = sqlite3.connect(":memory:")
conn.executescript("""
CREATE TABLE produits (
id INTEGER PRIMARY KEY,
reference TEXT,
nom TEXT,
description TEXT, -- peut être très long
prix REAL,
stock INTEGER,
image_blob BLOB, -- potentiellement des Mo
date_creation TEXT,
date_modification TEXT,
actif INTEGER DEFAULT 1
);
INSERT INTO produits VALUES
(1, 'REF-001', 'Laptop Pro', 'Description longue...', 1299.0, 50, NULL, '2024-01-01', '2024-06-01', 1),
(2, 'REF-002', 'Souris Ergo', 'Souris ergonomique...', 49.9, 200, NULL, '2024-02-01', '2024-06-15', 1);
""")
# Anti-pattern : SELECT *
print("=== Anti-pattern : SELECT * ===")
print("Problèmes :")
print(" • Transfère toutes les colonnes (y compris image_blob de plusieurs Mo)")
print(" • Casse le code si la structure de la table change")
print(" • Empêche l'optimiseur de créer des index couvrants")
print(" • Illisible : on ne sait pas quelles données sont utilisées")
print("\n=== Bonne pratique : colonnes explicites ===")
df = pd.read_sql_query("""
SELECT id, reference, nom, prix, stock
FROM produits
WHERE actif = 1
""", conn)
print(df.to_string(index=False))
print("\n→ Clair, performant, robuste aux évolutions de schéma")
=== Anti-pattern : SELECT * ===
Problèmes :
• Transfère toutes les colonnes (y compris image_blob de plusieurs Mo)
• Casse le code si la structure de la table change
• Empêche l'optimiseur de créer des index couvrants
• Illisible : on ne sait pas quelles données sont utilisées
=== Bonne pratique : colonnes explicites ===
id reference nom prix stock
1 REF-001 Laptop Pro 1299.0 50
2 REF-002 Souris Ergo 49.9 200
→ Clair, performant, robuste aux évolutions de schéma
NULL et la logique à trois valeurs#
SQL utilise une logique ternaire : TRUE, FALSE, et UNKNOWN. Toute comparaison avec NULL retourne UNKNOWN.
conn = sqlite3.connect(":memory:")
conn.executescript("""
CREATE TABLE employes (
id INTEGER PRIMARY KEY,
nom TEXT,
salaire REAL,
manager_id INTEGER -- NULL pour les directeurs
);
INSERT INTO employes VALUES
(1, 'Alice', 80000, NULL),
(2, 'Bob', 60000, 1),
(3, 'Charlie', 55000, 1),
(4, 'Diana', 70000, NULL),
(5, 'Eve', 50000, 2);
""")
# Pièges courants avec NULL
print("=== Pièges avec NULL ===\n")
# Piège 1 : WHERE col != valeur n'inclut pas les NULL
r1 = conn.execute("SELECT COUNT(*) FROM employes WHERE manager_id != 1").fetchone()[0]
r2 = conn.execute("SELECT COUNT(*) FROM employes WHERE manager_id != 1 OR manager_id IS NULL").fetchone()[0]
print(f"manager_id != 1 → {r1} résultats (les NULL sont exclus !)")
print(f"manager_id != 1 OR IS NULL → {r2} résultats (correct)")
# Piège 2 : NULL != NULL
r3 = conn.execute("SELECT NULL = NULL").fetchone()[0]
r4 = conn.execute("SELECT NULL IS NULL").fetchone()[0]
print(f"\nNULL = NULL → {r3} (UNKNOWN, pas TRUE !)")
print(f"NULL IS NULL → {r4} (TRUE, c'est la bonne façon)")
# Piège 3 : agrégats ignorent les NULL
conn.execute("UPDATE employes SET salaire = NULL WHERE id = 5")
conn.commit()
r5 = conn.execute("SELECT COUNT(*), COUNT(salaire), AVG(salaire) FROM employes").fetchone()
print(f"\nCOUNT(*) = {r5[0]}, COUNT(salaire) = {r5[1]}, AVG(salaire) = {r5[2]:.0f}")
print("→ AVG ignore les NULL (diviseur = 4, pas 5)")
# Bonne pratique : COALESCE
df = pd.read_sql_query("""
SELECT
nom,
COALESCE(salaire, 0) AS salaire,
CASE WHEN manager_id IS NULL THEN 'Directeur' ELSE 'Employé' END AS role
FROM employes
""", conn)
print(f"\n{df.to_string(index=False)}")
=== Pièges avec NULL ===
manager_id != 1 → 1 résultats (les NULL sont exclus !)
manager_id != 1 OR IS NULL → 3 résultats (correct)
NULL = NULL → None (UNKNOWN, pas TRUE !)
NULL IS NULL → 1 (TRUE, c'est la bonne façon)
COUNT(*) = 5, COUNT(salaire) = 4, AVG(salaire) = 66250
→ AVG ignore les NULL (diviseur = 4, pas 5)
nom salaire role
Alice 80000.0 Directeur
Bob 60000.0 Employé
Charlie 55000.0 Employé
Diana 70000.0 Directeur
Eve 0.0 Employé
Requêtes N+1#
L’anti-pattern N+1 consiste à exécuter une requête pour obtenir N lignes, puis N requêtes supplémentaires pour les détails — soit N+1 allers-retours en base.
conn = sqlite3.connect(":memory:")
conn.executescript("""
CREATE TABLE auteurs (id INTEGER PRIMARY KEY, nom TEXT);
CREATE TABLE livres (id INTEGER PRIMARY KEY, titre TEXT, auteur_id INTEGER);
INSERT INTO auteurs VALUES (1,'Zola'),(2,'Hugo'),(3,'Balzac');
INSERT INTO livres VALUES
(1,'Germinal',1),(2,'Nana',1),(3,'Les Misérables',2),
(4,'Notre-Dame',2),(5,'Le Père Goriot',3),(6,'Eugénie Grandet',3);
""")
import time
# Anti-pattern N+1
debut = time.perf_counter()
auteurs = conn.execute("SELECT id, nom FROM auteurs").fetchall()
total_queries = 1
for auteur_id, nom in auteurs:
livres = conn.execute(
"SELECT titre FROM livres WHERE auteur_id = ?", (auteur_id,)
).fetchall()
total_queries += 1
fin = time.perf_counter()
print(f"Anti-pattern N+1 : {total_queries} requêtes pour {len(auteurs)} auteurs")
# Solution : une seule requête avec JOIN
debut2 = time.perf_counter()
df = pd.read_sql_query("""
SELECT a.nom AS auteur, l.titre
FROM auteurs a
JOIN livres l ON a.id = l.auteur_id
ORDER BY a.nom, l.titre
""", conn)
fin2 = time.perf_counter()
print(f"Solution JOIN : 1 requête pour tous les auteurs et livres")
print(f"\n{df.to_string(index=False)}")
Anti-pattern N+1 : 4 requêtes pour 3 auteurs
Solution JOIN : 1 requête pour tous les auteurs et livres
auteur titre
Balzac Eugénie Grandet
Balzac Le Père Goriot
Hugo Les Misérables
Hugo Notre-Dame
Zola Germinal
Zola Nana
Sécurité#
Injection SQL#
L’injection SQL est la vulnérabilité de sécurité la plus classique des applications de base de données. Elle survient quand des données utilisateur sont concaténées directement dans une requête SQL.
conn = sqlite3.connect(":memory:")
conn.executescript("""
CREATE TABLE utilisateurs (id INTEGER PRIMARY KEY, nom TEXT, mot_de_passe TEXT, role TEXT);
INSERT INTO utilisateurs VALUES
(1, 'alice', 'secret123', 'user'),
(2, 'admin', 'tr3s_s3cr3t', 'admin');
""")
print("=== VULNÉRABILITÉ : concaténation de chaîne ===\n")
def login_vulnerable(nom, mdp):
"""NE JAMAIS FAIRE CECI."""
query = f"SELECT * FROM utilisateurs WHERE nom = '{nom}' AND mot_de_passe = '{mdp}'"
print(f"Requête exécutée : {query}")
return conn.execute(query).fetchall()
# Attaque classique : ' OR '1'='1
print("Tentative d'injection :")
resultats = login_vulnerable("admin' --", "n'importe quoi")
print(f"Résultat : {resultats}")
print("→ L'attaquant est connecté sans connaître le mot de passe !\n")
print("=== SOLUTION : requêtes paramétrées ===\n")
def login_securise(nom, mdp):
"""Toujours utiliser des paramètres."""
query = "SELECT * FROM utilisateurs WHERE nom = ? AND mot_de_passe = ?"
print(f"Requête : {query}")
print(f"Paramètres : ({nom!r}, {mdp!r})")
return conn.execute(query, (nom, mdp)).fetchall()
print("Même tentative d'injection avec requête paramétrée :")
resultats = login_securise("admin' --", "n'importe quoi")
print(f"Résultat : {resultats}")
print("→ Aucun résultat, l'injection est bloquée")
=== VULNÉRABILITÉ : concaténation de chaîne ===
Tentative d'injection :
Requête exécutée : SELECT * FROM utilisateurs WHERE nom = 'admin' --' AND mot_de_passe = 'n'importe quoi'
Résultat : [(2, 'admin', 'tr3s_s3cr3t', 'admin')]
→ L'attaquant est connecté sans connaître le mot de passe !
=== SOLUTION : requêtes paramétrées ===
Même tentative d'injection avec requête paramétrée :
Requête : SELECT * FROM utilisateurs WHERE nom = ? AND mot_de_passe = ?
Paramètres : ("admin' --", "n'importe quoi")
Résultat : []
→ Aucun résultat, l'injection est bloquée
Principe du moindre privilège#
-- Créer des rôles avec des droits minimaux
CREATE ROLE lecture_seule;
GRANT CONNECT ON DATABASE ma_base TO lecture_seule;
GRANT USAGE ON SCHEMA public TO lecture_seule;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO lecture_seule;
-- Rôle pour l'application (lecture + écriture, sans DDL)
CREATE ROLE app_web;
GRANT CONNECT ON DATABASE ma_base TO app_web;
GRANT USAGE ON SCHEMA public TO app_web;
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO app_web;
GRANT USAGE ON ALL SEQUENCES IN SCHEMA public TO app_web;
-- Révoquer les droits inutiles
REVOKE CREATE ON SCHEMA public FROM PUBLIC;
-- Audit : qui a accès à quoi ?
SELECT grantee, table_name, privilege_type
FROM information_schema.role_table_grants
WHERE table_schema = 'public'
ORDER BY grantee, table_name;
Migrations et versionnement#
Principe des migrations#
Une migration est un script SQL (ou Python) qui fait évoluer le schéma de façon contrôlée et reproductible. Chaque migration a un identifiant unique et ne s’exécute qu’une seule fois.
conn = sqlite3.connect(":memory:")
# Simulation d'un système de migrations minimal
conn.executescript("""
CREATE TABLE schema_migrations (
version TEXT PRIMARY KEY,
appliquee TEXT DEFAULT (datetime('now')),
description TEXT
);
""")
migrations = [
("001", "Création table utilisateurs", """
CREATE TABLE utilisateurs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
email TEXT UNIQUE NOT NULL,
nom TEXT NOT NULL,
actif INTEGER DEFAULT 1,
cree_le TEXT DEFAULT (datetime('now'))
);
"""),
("002", "Ajout table commandes", """
CREATE TABLE commandes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INTEGER NOT NULL REFERENCES utilisateurs(id),
total REAL NOT NULL,
statut TEXT DEFAULT 'en_attente',
cree_le TEXT DEFAULT (datetime('now'))
);
"""),
("003", "Index email utilisateurs", """
CREATE INDEX idx_utilisateurs_email ON utilisateurs(email);
"""),
("004", "Ajout colonne telephone", """
ALTER TABLE utilisateurs ADD COLUMN telephone TEXT;
"""),
]
def appliquer_migration(conn, version, description, sql):
"""Applique une migration si elle n'a pas déjà été exécutée."""
deja = conn.execute(
"SELECT version FROM schema_migrations WHERE version = ?", (version,)
).fetchone()
if deja:
print(f" [SKIP] {version} — déjà appliquée")
return
conn.executescript(sql)
conn.execute(
"INSERT INTO schema_migrations (version, description) VALUES (?, ?)",
(version, description)
)
conn.commit()
print(f" [OK] {version} — {description}")
print("Application des migrations :")
for v, desc, sql in migrations:
appliquer_migration(conn, v, desc, sql)
print("\nHistorique des migrations :")
df = pd.read_sql_query(
"SELECT version, description, appliquee FROM schema_migrations ORDER BY version",
conn
)
print(df.to_string(index=False))
Application des migrations :
[OK] 001 — Création table utilisateurs
[OK] 002 — Ajout table commandes
[OK] 003 — Index email utilisateurs
[OK] 004 — Ajout colonne telephone
Historique des migrations :
version description appliquee
001 Création table utilisateurs 2026-03-31 23:05:21
002 Ajout table commandes 2026-03-31 23:05:21
003 Index email utilisateurs 2026-03-31 23:05:21
004 Ajout colonne telephone 2026-03-31 23:05:21
Alembic avec SQLAlchemy#
En production Python, Alembic gère les migrations avec un système de révisions chaînées :
# Initialisation
# alembic init alembic
# alembic revision --autogenerate -m "add telephone column"
# Fichier de migration généré : alembic/versions/abc123_add_telephone.py
from alembic import op
import sqlalchemy as sa
def upgrade():
op.add_column(
'utilisateurs',
sa.Column('telephone', sa.String(20), nullable=True)
)
op.create_index('idx_users_email', 'utilisateurs', ['email'], unique=True)
def downgrade():
op.drop_index('idx_users_email', table_name='utilisateurs')
op.drop_column('utilisateurs', 'telephone')
# Appliquer : alembic upgrade head
# Annuler : alembic downgrade -1
# Historique : alembic history --verbose
SQL moderne : fonctionnalités récentes#
Colonnes générées#
conn = sqlite3.connect(":memory:")
# SQLite supporte les colonnes générées depuis 3.31.0
conn.executescript("""
CREATE TABLE produits (
id INTEGER PRIMARY KEY,
prix_ht REAL NOT NULL,
tva_taux REAL NOT NULL DEFAULT 0.20,
prix_ttc REAL GENERATED ALWAYS AS (prix_ht * (1 + tva_taux)) STORED,
categorie TEXT
);
INSERT INTO produits (id, prix_ht, categorie) VALUES
(1, 100.0, 'Électronique'),
(2, 50.0, 'Alimentation'),
(3, 200.0, 'Vêtements');
UPDATE produits SET tva_taux = 0.055 WHERE categorie = 'Alimentation';
""")
df = pd.read_sql_query("SELECT id, prix_ht, tva_taux, prix_ttc, categorie FROM produits", conn)
print("Colonnes générées (prix_ttc calculé automatiquement) :")
print(df.to_string(index=False))
Colonnes générées (prix_ttc calculé automatiquement) :
id prix_ht tva_taux prix_ttc categorie
1 100.0 0.200 120.00 Électronique
2 50.0 0.055 52.75 Alimentation
3 200.0 0.200 240.00 Vêtements
FILTER dans les agrégats#
conn = sqlite3.connect(":memory:")
conn.executescript("""
CREATE TABLE ventes (
id INTEGER PRIMARY KEY,
region TEXT,
annee INTEGER,
montant REAL
);
""")
import random
random.seed(42)
regions = ['Nord', 'Sud', 'Est', 'Ouest']
for i in range(1, 201):
conn.execute(
"INSERT INTO ventes VALUES (?, ?, ?, ?)",
(i, random.choice(regions), random.choice([2022, 2023, 2024]),
round(random.uniform(100, 10000), 2))
)
conn.commit()
# FILTER : agrégats conditionnels sans CASE WHEN imbriqué
df = pd.read_sql_query("""
SELECT
region,
COUNT(*) AS total_ventes,
SUM(montant) FILTER (WHERE annee = 2022) AS ca_2022,
SUM(montant) FILTER (WHERE annee = 2023) AS ca_2023,
SUM(montant) FILTER (WHERE annee = 2024) AS ca_2024
FROM ventes
GROUP BY region
ORDER BY region
""", conn)
df[['ca_2022', 'ca_2023', 'ca_2024']] = df[['ca_2022', 'ca_2023', 'ca_2024']].round(0)
print("Agrégats avec FILTER (syntaxe moderne vs CASE WHEN) :")
print(df.to_string(index=False))
Agrégats avec FILTER (syntaxe moderne vs CASE WHEN) :
region total_ventes ca_2022 ca_2023 ca_2024
Est 48 92538.0 60937.0 72916.0
Nord 56 113580.0 69338.0 111019.0
Ouest 43 78484.0 88232.0 55891.0
Sud 53 69735.0 55093.0 122433.0
RETURNING#
-- Récupérer les données insérées/modifiées sans requête supplémentaire
-- PostgreSQL, SQLite 3.35+
INSERT INTO commandes (user_id, total, statut)
VALUES (42, 299.99, 'en_attente')
RETURNING id, cree_le;
-- → retourne l'id auto-généré et la date de création
UPDATE commandes
SET statut = 'expédié', date_expedition = NOW()
WHERE id = 1234
RETURNING id, statut, date_expedition;
-- → confirme les valeurs après mise à jour
DELETE FROM logs
WHERE cree_le < NOW() - INTERVAL '90 days'
RETURNING COUNT(*);
-- → nombre de lignes supprimées
Outils et écosystème#

Checklist de qualité SQL#
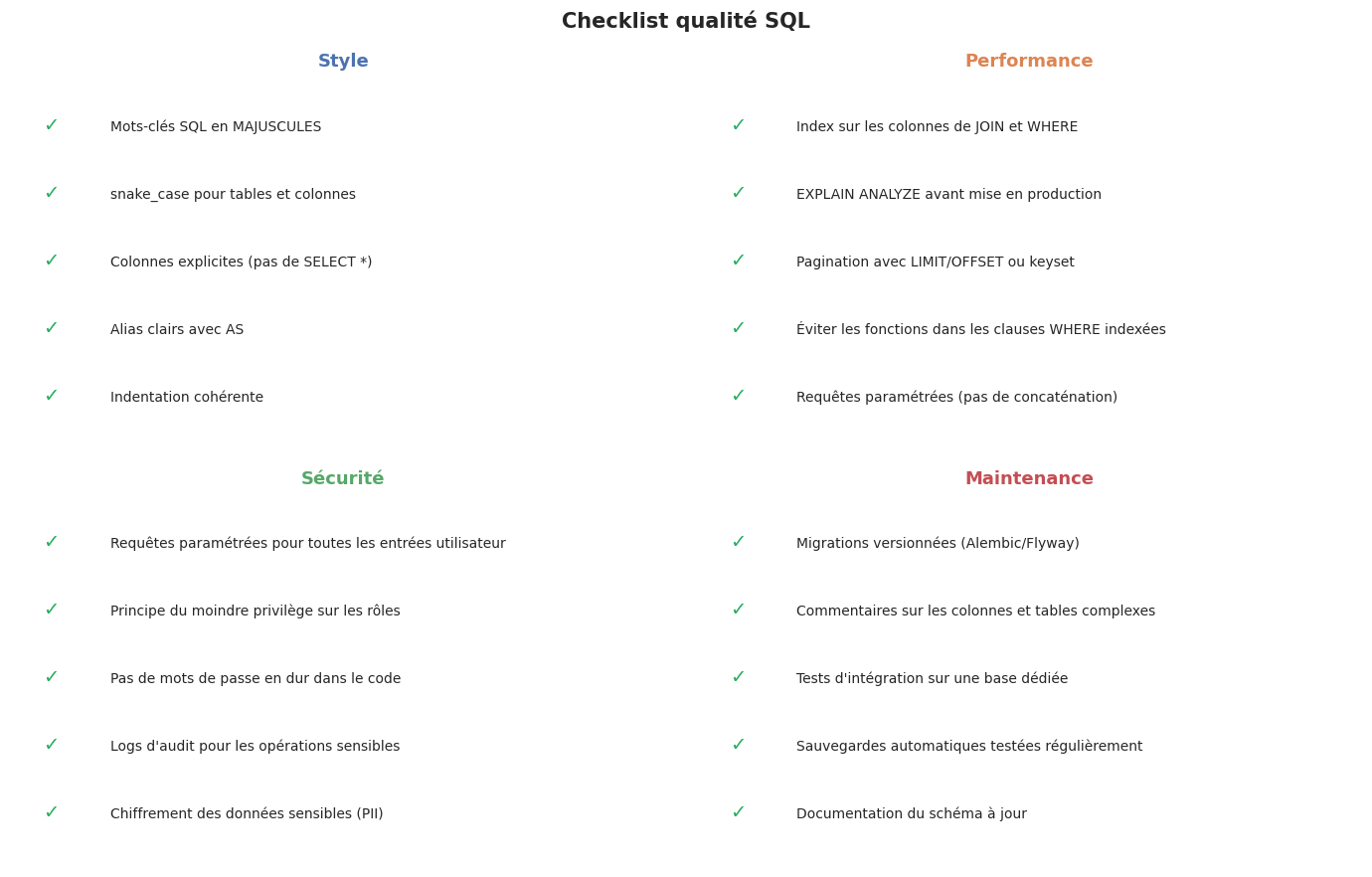
Pour aller plus loin#
Ressources recommandées
Livres
SQL Performance Explained — Markus Winand (use-the-index-luke.com)
The Art of PostgreSQL — Dimitri Fontaine
Database Internals — Alex Petrov (architecture des SGBD)
En ligne
use-the-index-luke.com — index et performance expliqués
pgexercises.com — exercices PostgreSQL progressifs
sqlzoo.net — pratique interactive
Documentation officielle PostgreSQL — la meilleure du secteur
Pratique
Contribuer à un projet open source qui utilise une base de données
Analyser les slow queries de votre application avec
pg_stat_statementsPratiquer sur des jeux de données publics (data.gouv.fr, Kaggle)
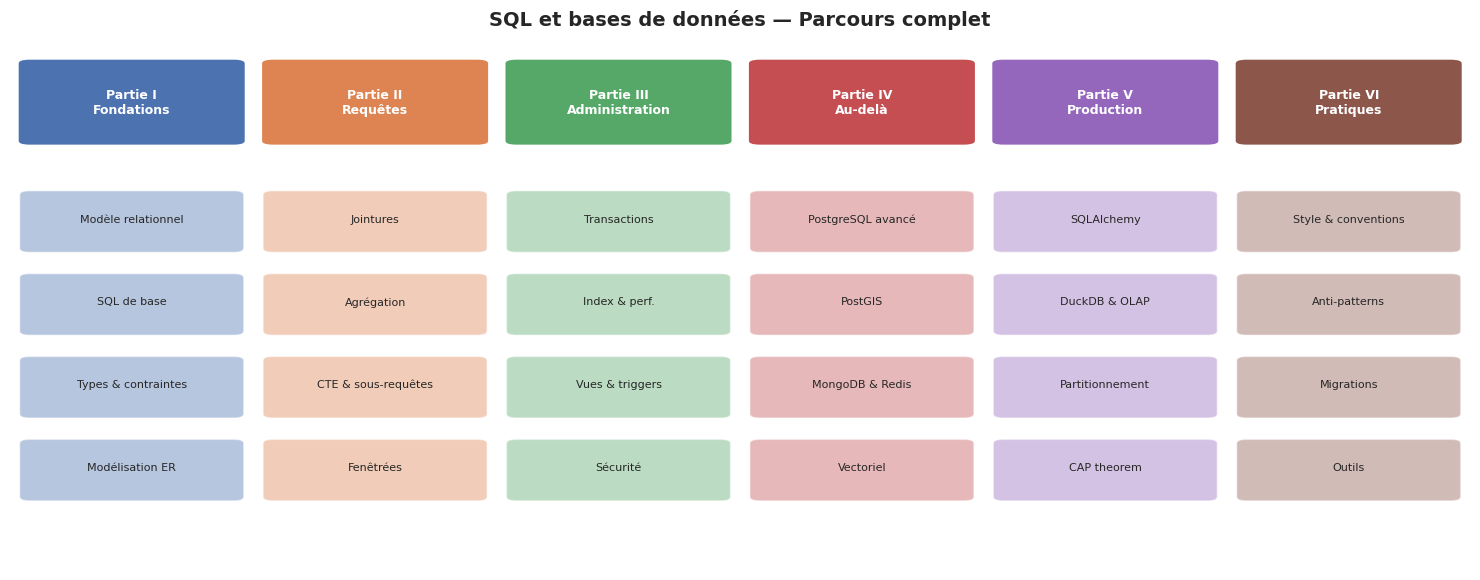
Résumé du livre#
Ce livre a couvert SQL des fondations aux architectures distribuées :
SQL est un langage vieux de cinquante ans qui n’a cessé de s’enrichir. Sa simplicité apparente cache une profondeur remarquable : un bon DBA ou développeur data peut passer des années à en explorer les subtilités. Ce livre vous a donné les fondations et les outils pour progresser — maintenant, la meilleure façon d’apprendre est de pratiquer sur de vrais projets, d’analyser des requêtes lentes, de concevoir des schémas, et de mesurer l’impact de vos décisions.