ORM et Python avec SQLAlchemy#
Écrire du SQL dans du code Python, c’est mélanger deux langages aux paradigmes opposés : SQL opère sur des ensembles de lignes, Python manipule des objets. Les ORM (Object-Relational Mappers) comblent ce fossé en projetant les tables sur des classes Python et les lignes sur des instances d’objets. SQLAlchemy est l’ORM de référence de l’écosystème Python : puissant, flexible, utilisé par Flask, FastAPI et des milliers de projets en production.
SQLAlchemy propose deux niveaux d’abstraction complémentaires :
SQLAlchemy Core : constructeur de requêtes SQL expressif en Python, proche du SQL mais sans mapping objet.
SQLAlchemy ORM : mapping objet-relationnel complet, avec sessions, relations et chargement automatique.
Pourquoi un ORM ?#
Définition 137
Un ORM (Object-Relational Mapper) est une bibliothèque qui établit une correspondance bidirectionnelle entre les tables d’une base relationnelle et les classes d’un langage orienté objet. Il traduit les opérations CRUD sur des objets en requêtes SQL, gère les connexions et les transactions, et matérialise les lignes en instances typées. L’ORM joue le rôle d’une couche d’abstraction entre le code métier et la base de données.
Remarque 91
Avantages d’un ORM : productivité (moins de SQL boilerplate), portabilité entre SGBD (SQLite, PostgreSQL, MySQL), sécurité (requêtes paramétrées automatiques), navigation objet des relations. Inconvénients : abstraction qui fuit (le SQL généré peut être sous-optimal), courbe d’apprentissage, risque de N+1 queries si mal utilisé. La règle pragmatique : utiliser l’ORM pour le CRUD courant, écrire du SQL brut pour les requêtes analytiques complexes.
SQLAlchemy Core#
SQLAlchemy Core permet de construire des requêtes SQL de façon programmatique sans définir de classes de modèles.
Définition 138
L”Engine est le point d’entrée de SQLAlchemy. Il encapsule une URL de connexion, un dialecte SQL (sqlite, postgresql, mysql…) et un pool de connexions. On le crée avec create_engine(url). L’Engine ne crée pas de connexion immédiatement — il est lazy. La connexion est établie lors du premier contexte with engine.connect() as conn.
from sqlalchemy import (
create_engine, MetaData, Table, Column,
Integer, String, Float, ForeignKey, Date, Text,
select, insert, update, delete, func, and_, or_
)
from sqlalchemy.orm import (
DeclarativeBase, Session, relationship,
selectinload, joinedload, mapped_column, Mapped
)
from datetime import date, timedelta
import random
# Engine SQLite en mémoire
engine = create_engine("sqlite:///:memory:", echo=False)
metadata = MetaData()
# Définition des tables avec SQLAlchemy Core
auteurs_table = Table("auteurs", metadata,
Column("id", Integer, primary_key=True, autoincrement=True),
Column("nom", String(100), nullable=False),
Column("prenom", String(100), nullable=False),
Column("nationalite", String(50)),
)
livres_table = Table("livres", metadata,
Column("id", Integer, primary_key=True, autoincrement=True),
Column("titre", String(200), nullable=False),
Column("annee", Integer),
Column("prix", Float),
Column("auteur_id", Integer, ForeignKey("auteurs.id"), nullable=False),
)
emprunts_table = Table("emprunts", metadata,
Column("id", Integer, primary_key=True, autoincrement=True),
Column("livre_id", Integer, ForeignKey("livres.id"), nullable=False),
Column("emprunteur", String(100), nullable=False),
Column("date_debut", Date, nullable=False),
Column("date_retour", Date),
)
metadata.create_all(engine)
# Insertion avec Core
with engine.connect() as conn:
conn.execute(insert(auteurs_table), [
{"nom": "Knuth", "prenom": "Donald", "nationalite": "Américain"},
{"nom": "Martin", "prenom": "Robert", "nationalite": "Américain"},
{"nom": "Fowler", "prenom": "Martin", "nationalite": "Britannique"},
{"nom": "Kleppmann","prenom": "Martin", "nationalite": "Allemand"},
])
conn.execute(insert(livres_table), [
{"titre": "The Art of Computer Programming", "annee": 1968, "prix": 89.99, "auteur_id": 1},
{"titre": "Clean Code", "annee": 2008, "prix": 34.99, "auteur_id": 2},
{"titre": "The Pragmatic Programmer", "annee": 1999, "prix": 39.99, "auteur_id": 3},
{"titre": "Designing Data-Intensive Applications", "annee": 2017, "prix": 49.99, "auteur_id": 4},
{"titre": "Refactoring", "annee": 2018, "prix": 44.99, "auteur_id": 3},
])
conn.execute(insert(emprunts_table), [
{"livre_id": 1, "emprunteur": "Alice", "date_debut": date(2024, 1, 10), "date_retour": date(2024, 2, 5)},
{"livre_id": 2, "emprunteur": "Bob", "date_debut": date(2024, 2, 1), "date_retour": date(2024, 2, 28)},
{"livre_id": 2, "emprunteur": "Alice", "date_debut": date(2024, 3, 5), "date_retour": None},
{"livre_id": 4, "emprunteur": "Clara", "date_debut": date(2024, 3, 12), "date_retour": None},
{"livre_id": 3, "emprunteur": "David", "date_debut": date(2024, 1, 20), "date_retour": date(2024, 2, 15)},
])
conn.commit()
# Requête Core : jointure avec alias
stmt = (
select(
livres_table.c.titre,
auteurs_table.c.nom.label("auteur_nom"),
livres_table.c.prix,
)
.join(auteurs_table, livres_table.c.auteur_id == auteurs_table.c.id)
.order_by(livres_table.c.prix.desc())
)
with engine.connect() as conn:
result = conn.execute(stmt)
print("Livres par prix décroissant :")
for row in result:
print(f" {row.titre[:40]:<40} | {row.auteur_nom:<10} | {row.prix:.2f} €")
Livres par prix décroissant :
The Art of Computer Programming | Knuth | 89.99 €
Designing Data-Intensive Applications | Kleppmann | 49.99 €
Refactoring | Fowler | 44.99 €
The Pragmatic Programmer | Fowler | 39.99 €
Clean Code | Martin | 34.99 €
SQLAlchemy ORM : modèles et sessions#
Définition 139
DeclarativeBase est la classe de base de l’ORM moderne (SQLAlchemy 2.x). On en hérite pour définir des modèles : chaque sous-classe représente une table, chaque attribut mapped_column(...) représente une colonne. L’ORM maintient un registre interne qui associe les classes aux tables et permet l’introspection.
Définition 140
La Session est l’unité de travail de l’ORM. Elle maintient un cache d’identité (chaque objet est chargé une seule fois par identifiant) et une unit of work (elle accumule les modifications et les envoie en bloc à la base lors du flush ou du commit). On l’instancie avec Session(engine) et on l’utilise dans un contexte with.
# Définition des modèles ORM (base séparée, SQLite en mémoire)
engine_orm = create_engine("sqlite:///:memory:", echo=False)
class Base(DeclarativeBase):
pass
class Auteur(Base):
__tablename__ = "auteurs"
id: Mapped[int] = mapped_column(Integer, primary_key=True)
nom: Mapped[str] = mapped_column(String(100), nullable=False)
prenom: Mapped[str] = mapped_column(String(100), nullable=False)
nationalite: Mapped[str] = mapped_column(String(50), nullable=True)
livres: Mapped[list["Livre"]] = relationship("Livre", back_populates="auteur",
cascade="all, delete-orphan")
def __repr__(self):
return f"Auteur({self.prenom} {self.nom})"
class Livre(Base):
__tablename__ = "livres"
id: Mapped[int] = mapped_column(Integer, primary_key=True)
titre: Mapped[str] = mapped_column(String(200), nullable=False)
annee: Mapped[int] = mapped_column(Integer, nullable=True)
prix: Mapped[float] = mapped_column(Float, nullable=True)
auteur_id: Mapped[int] = mapped_column(ForeignKey("auteurs.id"), nullable=False)
auteur: Mapped["Auteur"] = relationship("Auteur", back_populates="livres")
emprunts: Mapped[list["Emprunt"]] = relationship("Emprunt", back_populates="livre")
def __repr__(self):
return f"Livre({self.titre[:30]})"
class Emprunt(Base):
__tablename__ = "emprunts"
id: Mapped[int] = mapped_column(Integer, primary_key=True)
livre_id: Mapped[int] = mapped_column(ForeignKey("livres.id"), nullable=False)
emprunteur: Mapped[str] = mapped_column(String(100), nullable=False)
date_debut: Mapped[date] = mapped_column(Date, nullable=False)
date_retour: Mapped[date] = mapped_column(Date, nullable=True)
livre: Mapped["Livre"] = relationship("Livre", back_populates="emprunts")
def __repr__(self):
return f"Emprunt({self.emprunteur}, {self.date_debut})"
Base.metadata.create_all(engine_orm)
# Peuplement
with Session(engine_orm) as session:
auteurs = [
Auteur(nom="Knuth", prenom="Donald", nationalite="Américain"),
Auteur(nom="Martin", prenom="Robert", nationalite="Américain"),
Auteur(nom="Fowler", prenom="Martin", nationalite="Britannique"),
Auteur(nom="Kleppmann",prenom="Martin", nationalite="Allemand"),
]
session.add_all(auteurs)
session.flush() # obtenir les IDs
livres = [
Livre(titre="The Art of Computer Programming", annee=1968, prix=89.99, auteur=auteurs[0]),
Livre(titre="Clean Code", annee=2008, prix=34.99, auteur=auteurs[1]),
Livre(titre="The Pragmatic Programmer", annee=1999, prix=39.99, auteur=auteurs[2]),
Livre(titre="Designing Data-Intensive Applications", annee=2017, prix=49.99, auteur=auteurs[3]),
Livre(titre="Refactoring", annee=2018, prix=44.99, auteur=auteurs[2]),
]
session.add_all(livres)
session.flush()
emprunts = [
Emprunt(livre=livres[0], emprunteur="Alice", date_debut=date(2024,1,10), date_retour=date(2024,2,5)),
Emprunt(livre=livres[1], emprunteur="Bob", date_debut=date(2024,2,1), date_retour=date(2024,2,28)),
Emprunt(livre=livres[1], emprunteur="Alice", date_debut=date(2024,3,5), date_retour=None),
Emprunt(livre=livres[3], emprunteur="Clara", date_debut=date(2024,3,12), date_retour=None),
]
session.add_all(emprunts)
session.commit()
print("Base ORM créée et peuplée.")
Base ORM créée et peuplée.
Requêtes ORM#
Exemple 51
Les requêtes ORM utilisent select() avec des classes plutôt que des tables.
# Requêtes ORM illustratives
with Session(engine_orm) as session:
# 1. Tous les livres d'un auteur
stmt = select(Livre).join(Auteur).where(Auteur.nom == "Fowler").order_by(Livre.annee)
livres_fowler = session.scalars(stmt).all()
print("Livres de Fowler :")
for l in livres_fowler:
print(f" - {l.titre} ({l.annee})")
# 2. Agrégation : nombre de livres et prix moyen par nationalité
stmt2 = (
select(
Auteur.nationalite,
func.count(Livre.id).label("nb_livres"),
func.avg(Livre.prix).label("prix_moyen"),
)
.join(Livre, Auteur.id == Livre.auteur_id)
.group_by(Auteur.nationalite)
.order_by(func.count(Livre.id).desc())
)
print("\nNb livres et prix moyen par nationalité :")
with engine_orm.connect() as conn:
for row in conn.execute(stmt2):
print(f" {row.nationalite:<15} {row.nb_livres} livre(s) — {row.prix_moyen:.2f} € moyen")
# 3. Livres actuellement empruntés (date_retour IS NULL)
stmt3 = (
select(Livre.titre, Emprunt.emprunteur, Emprunt.date_debut)
.join(Emprunt, Livre.id == Emprunt.livre_id)
.where(Emprunt.date_retour == None)
.order_by(Emprunt.date_debut)
)
print("\nLivres actuellement empruntés :")
with engine_orm.connect() as conn:
for row in conn.execute(stmt3):
print(f" '{row.titre[:35]}' — {row.emprunteur} depuis {row.date_debut}")
# 4. Mise à jour (update)
stmt4 = update(Livre).where(Livre.id == 1).values(prix=79.99)
session.execute(stmt4)
session.commit()
l = session.get(Livre, 1)
print(f"\nPrix mis à jour : {l.titre[:30]} → {l.prix} €")
Livres de Fowler :
- The Pragmatic Programmer (1999)
- Refactoring (2018)
Nb livres et prix moyen par nationalité :
Britannique 2 livre(s) — 42.49 € moyen
Américain 2 livre(s) — 62.49 € moyen
Allemand 1 livre(s) — 49.99 € moyen
Livres actuellement empruntés :
'Clean Code' — Alice depuis 2024-03-05
'Designing Data-Intensive Applicatio' — Clara depuis 2024-03-12
Prix mis à jour : The Art of Computer Programmin → 79.99 €
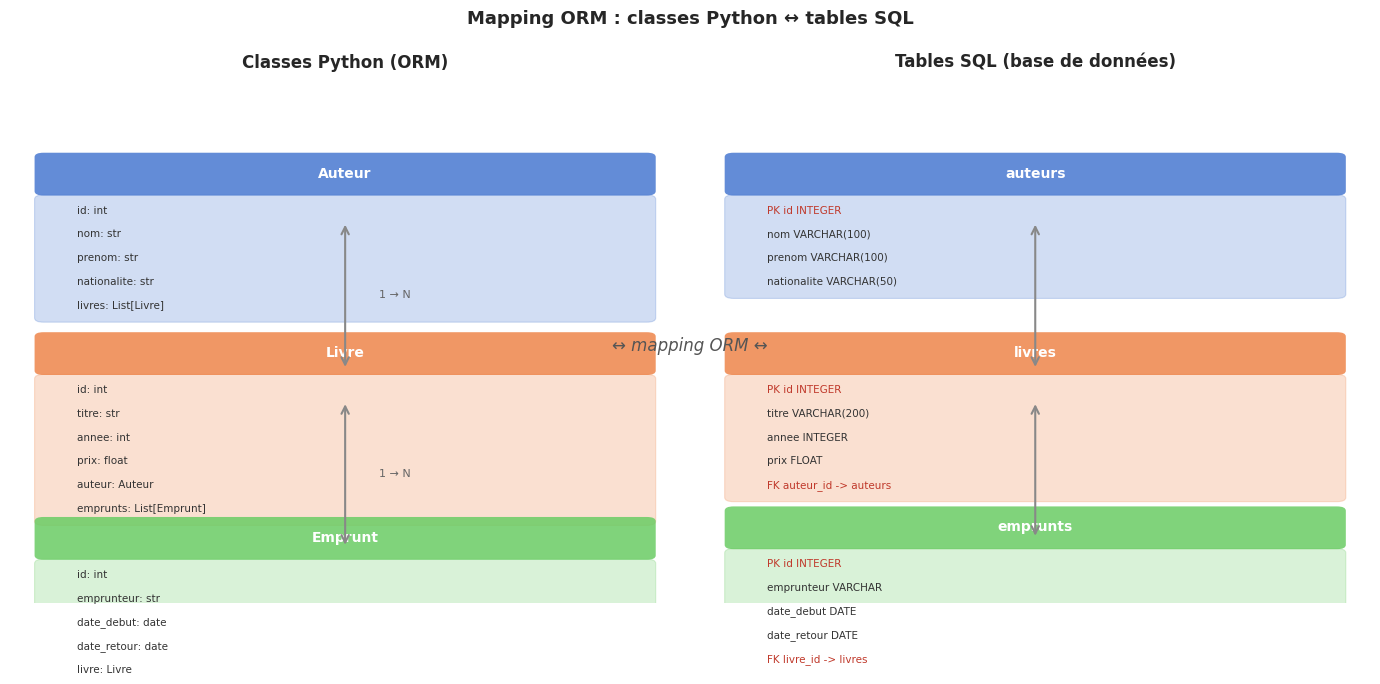
Relations : one-to-many et many-to-many#
Définition 141
SQLAlchemy modélise les relations entre tables via relationship() :
One-to-many :
Auteur.livres→ un auteur a plusieurs livres. Le côté « many » porte la clé étrangère.Many-to-many : via une table d’association (secondary table). Par exemple, un livre peut avoir plusieurs genres et un genre peut s’appliquer à plusieurs livres.
Exemple 52
Modélisation d’un lien Livre ↔ Genre (many-to-many) avec une table d’association :
Une table livre_genre contient deux colonnes de clés étrangères : livre_id et genre_id. SQLAlchemy gère automatiquement les insertions dans cette table lorsqu’on manipule livre.genres.append(genre).
Lazy vs Eager loading et le problème N+1#
Définition 142
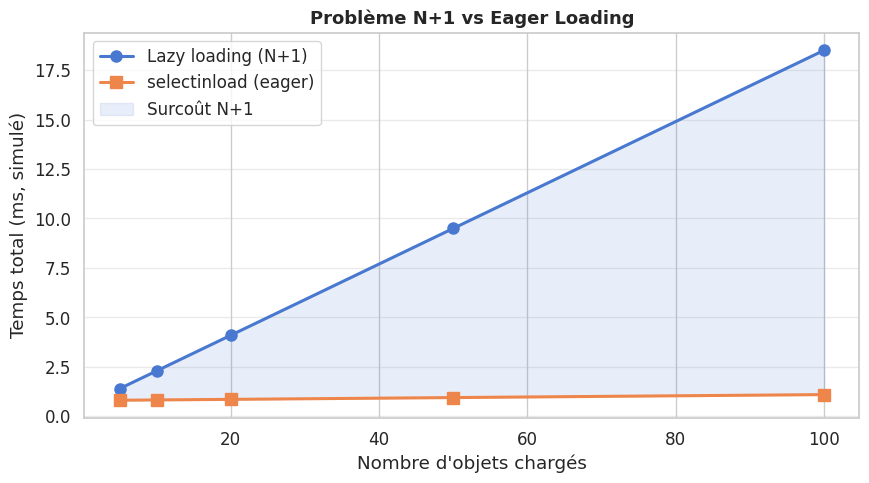
Le lazy loading (chargement paresseux) est le comportement par défaut de SQLAlchemy ORM : les attributs de relation ne sont chargés que lorsqu’on y accède. Si on itère sur N objets et accède à la relation de chacun, cela génère N+1 requêtes SQL (1 pour la liste, 1 par objet pour la relation) — le problème N+1.
L”eager loading charge les relations en une seule requête supplémentaire dès le départ :
selectinload: émet une deuxième requêteSELECT ... WHERE id IN (...).joinedload: fait une jointure SQL et charge tout en une seule requête.
Remarque 92
Le problème N+1 est l’antipattern ORM le plus fréquent. Symptôme : le log SQL montre une requête principale suivie de dizaines de requêtes identiques (une par objet). Solution : utiliser selectinload() ou joinedload() dans les select(), ou configurer lazy='selectin' au niveau du modèle.
import time
# Simulation du problème N+1 vs eager loading
with Session(engine_orm) as session:
# -- N+1 (lazy loading simulé) --
t0 = time.perf_counter()
livres_lazy = session.scalars(select(Livre)).all()
# Accéder à auteur déclenche 1 requête par livre
for l in livres_lazy:
_ = l.auteur.nom # N requêtes supplémentaires
t_lazy = (time.perf_counter() - t0) * 1000
session.expire_all() # vider le cache
# -- Eager loading avec selectinload --
t0 = time.perf_counter()
livres_eager = session.scalars(
select(Livre).options(selectinload(Livre.auteur))
).all()
for l in livres_eager:
_ = l.auteur.nom # données déjà chargées, pas de requête
t_eager = (time.perf_counter() - t0) * 1000
print(f"Lazy loading (N+1) : {t_lazy:.2f} ms")
print(f"Eager (selectinload) : {t_eager:.2f} ms")
print(f"\nRelations chargées avec selectinload :")
for l in livres_eager:
print(f" {l.titre[:35]:<35} → {l.auteur.prenom} {l.auteur.nom}")
Lazy loading (N+1) : 4.46 ms
Eager (selectinload) : 3.64 ms
Relations chargées avec selectinload :
The Art of Computer Programming → Donald Knuth
Clean Code → Robert Martin
The Pragmatic Programmer → Martin Fowler
Designing Data-Intensive Applicatio → Martin Kleppmann
Refactoring → Martin Fowler
Alembic : migrations de schéma#
Définition 143
Alembic est l’outil de migration de schéma officiel de SQLAlchemy. Il gère l’évolution du schéma dans le temps sous forme de scripts versionnés, à la manière de Git pour les fichiers. Chaque migration est un fichier Python avec deux fonctions : upgrade() (appliquer le changement) et downgrade() (l’annuler). Alembic maintient une table alembic_version dans la base pour savoir quelle migration a été appliquée en dernier.
Remarque 93
Workflow Alembic standard :
alembic init alembic— initialiser le répertoire de migrations.Configurer
alembic.iniavec l’URL de connexion.alembic revision --autogenerate -m "add colonne isbn"— générer automatiquement le script de migration en comparant les modèles aux tables existantes.Relire et ajuster le fichier généré (autogenerate n’est pas parfait).
alembic upgrade head— appliquer toutes les migrations en attente.alembic downgrade -1— annuler la dernière migration.
Les blocs suivants illustrent la structure d’un fichier de migration Alembic.
# alembic/versions/001_add_isbn_to_livres.py
"""add colonne isbn to livres
Revision ID: a1b2c3d4e5f6
Down revision: None
Create Date: 2024-03-15
"""
from alembic import op
import sqlalchemy as sa
def upgrade():
op.add_column(
'livres',
sa.Column('isbn', sa.String(20), nullable=True)
)
op.create_index('ix_livres_isbn', 'livres', ['isbn'])
def downgrade():
op.drop_index('ix_livres_isbn', table_name='livres')
op.drop_column('livres', 'isbn')
Exemple 53
Renommer une colonne sans perte de données avec Alembic (PostgreSQL) :
Dans le script upgrade(), on appelle op.alter_column('livres', 'auteur_id', new_column_name='fk_auteur'). Dans downgrade(), on inverse. Alembic génère le SQL adapté au dialecte cible — la syntaxe est différente selon que l’on cible SQLite, PostgreSQL ou MySQL.
Résumé#
SQLAlchemy offre deux modes d’accès complémentaires à une base de données relationnelle : Core pour le contrôle SQL fin, ORM pour la productivité et la navigation objet.
Remarque 94
Les points clés à retenir :
L’Engine encapsule l’URL et le pool de connexions ; la Session est l’unité de travail de l’ORM.
DeclarativeBaseetmapped_columndéfinissent le mapping classe → table de façon déclarative et typée (SQLAlchemy 2.x).relationship()avecback_populatespermet la navigation bidirectionnelle ;cascade="all, delete-orphan"propage les suppressions.Le problème N+1 est l’antipattern ORM le plus courant ;
selectinload()le résout en émettant une seule requête IN.Alembic versionne les migrations de schéma ;
autogenerateaccélère la rédaction des scripts.Règle d’or : ORM pour le CRUD, SQL brut (via
text()ou Core) pour les requêtes analytiques complexes.