Jointures#
Pourquoi les jointures ?#
Le modèle relationnel décompose l’information en tables distinctes pour éliminer la redondance. Mais pour répondre aux questions métier, on a souvent besoin de combiner plusieurs tables. C’est le rôle des jointures : elles reconstituent temporairement les informations provenant de tables différentes en les associant selon une condition logique.
Définition 47 (Jointure)
Une jointure est une opération qui combine les lignes de deux (ou plusieurs) tables selon une condition de jointure (le plus souvent l’égalité de valeurs entre une clé étrangère et une clé primaire). Le résultat est une table virtuelle dont les colonnes sont la concaténation des colonnes des tables source.
En algèbre relationnelle, la jointure naturelle \(R \bowtie S\) produit tous les tuples du produit cartésien \(R \times S\) qui satisfont la condition.
Mise en place du jeu de données#
conn = sqlite3.connect(":memory:")
# Schéma — executescript désactive les FK (COMMIT implicite), on les réactive ensuite
conn.executescript("""
CREATE TABLE departements (
dept_id INTEGER PRIMARY KEY,
nom TEXT NOT NULL,
ville TEXT NOT NULL
);
CREATE TABLE employes (
emp_id INTEGER PRIMARY KEY,
prenom TEXT NOT NULL,
nom TEXT NOT NULL,
salaire REAL NOT NULL,
dept_id INTEGER REFERENCES departements(dept_id)
);
CREATE TABLE projets (
projet_id INTEGER PRIMARY KEY,
nom TEXT NOT NULL,
budget REAL NOT NULL,
dept_id INTEGER REFERENCES departements(dept_id)
);
CREATE TABLE employe_projet (
emp_id INTEGER REFERENCES employes(emp_id),
projet_id INTEGER REFERENCES projets(projet_id),
role TEXT NOT NULL DEFAULT 'Membre',
PRIMARY KEY (emp_id, projet_id)
);
""")
conn.execute("PRAGMA foreign_keys = ON")
# Données — ordre respectant les FK : departements → employes → projets → employe_projet
conn.executemany("INSERT INTO departements VALUES (?,?,?)", [
(10, 'Informatique', 'Paris'),
(20, 'Comptabilité', 'Lyon'),
(30, 'Marketing', 'Bordeaux'),
(40, 'Logistique', 'Nantes'),
])
conn.executemany("INSERT INTO employes VALUES (?,?,?,?,?)", [
(1, 'Alice', 'Martin', 4500, 10),
(2, 'Bob', 'Dupont', 3800, 20),
(3, 'Charlie', 'Leroy', 5200, 10),
(4, 'Diana', 'Morel', 4100, 30),
(5, 'Eric', 'Blanc', 4700, 20),
(6, 'Fatima', 'Ahmed', 5500, 10),
(7, 'Gilles', 'Petit', 3600, None), # sans département
])
conn.executemany("INSERT INTO projets VALUES (?,?,?,?)", [
(101, 'Refonte ERP', 250000, 10),
(102, 'Audit fiscal', 80000, 20),
(103, 'Campagne social', 120000, 30),
(104, 'Portail client', 180000, 10),
])
# Projet orphelin : dept_id=50 n'existe pas — on commit avant de changer les FK
conn.commit()
conn.execute("PRAGMA foreign_keys = OFF")
conn.execute("INSERT INTO projets VALUES (105, 'Optimisation stock', 60000, 50)")
conn.commit()
conn.execute("PRAGMA foreign_keys = ON")
conn.executemany("INSERT INTO employe_projet VALUES (?,?,?)", [
(1, 101, 'Chef de projet'),
(3, 101, 'Développeur'),
(6, 101, 'Architecte'),
(2, 102, 'Analyste'),
(4, 103, 'Responsable'),
(1, 104, 'Développeur'),
(3, 104, 'Chef de projet'),
])
conn.commit()
print("Jeu de données créé.")
print("Employés :", conn.execute("SELECT COUNT(*) FROM employes").fetchone()[0])
print("Projets :", conn.execute("SELECT COUNT(*) FROM projets").fetchone()[0])
Jeu de données créé.
Employés : 7
Projets : 5
INNER JOIN#
Définition 48 (INNER JOIN (jointure interne))
L”INNER JOIN retourne uniquement les lignes pour lesquelles la condition de jointure est satisfaite dans les deux tables. Les lignes sans correspondance de l’un ou l’autre côté sont exclues.
Syntaxe : FROM table1 INNER JOIN table2 ON table1.col = table2.col
Le mot-clé INNER est optionnel : JOIN seul est équivalent à INNER JOIN.
Exemple 14 (Équi-jointure)
L”équi-jointure est le cas particulier (et de loin le plus fréquent) où la condition est une égalité : ON e.dept_id = d.dept_id. Elle correspond à la jointure naturelle quand les colonnes ont le même nom. On peut aussi utiliser USING(dept_id) comme raccourci quand les colonnes ont le même nom dans les deux tables.
# INNER JOIN : employes avec leur département (exclut Gilles, sans dept)
df = pd.read_sql("""
SELECT e.emp_id, e.prenom, e.nom, e.salaire,
d.nom AS departement, d.ville
FROM employes e
INNER JOIN departements d ON e.dept_id = d.dept_id
ORDER BY d.nom, e.nom
""", conn)
print(f"INNER JOIN — {len(df)} lignes (Gilles exclu car dept_id NULL)")
print(df.to_string(index=False))
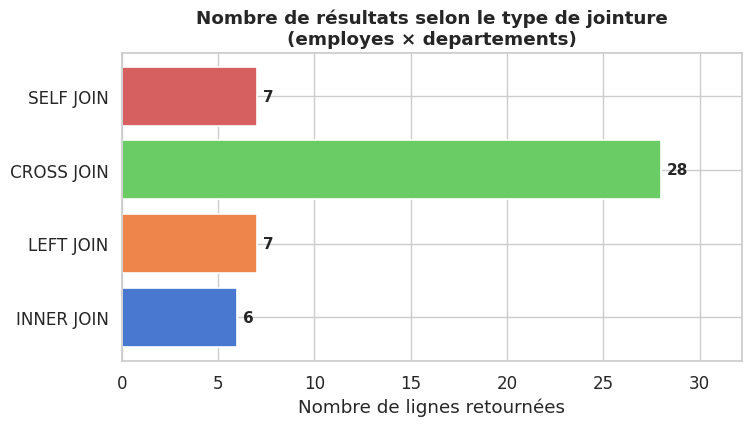
INNER JOIN — 6 lignes (Gilles exclu car dept_id NULL)
emp_id prenom nom salaire departement ville
5 Eric Blanc 4700.0 Comptabilité Lyon
2 Bob Dupont 3800.0 Comptabilité Lyon
6 Fatima Ahmed 5500.0 Informatique Paris
3 Charlie Leroy 5200.0 Informatique Paris
1 Alice Martin 4500.0 Informatique Paris
4 Diana Morel 4100.0 Marketing Bordeaux
LEFT JOIN#
Définition 49 (LEFT JOIN (jointure gauche))
Le LEFT JOIN (ou LEFT OUTER JOIN) retourne toutes les lignes de la table gauche (première table mentionnée), auxquelles sont associées les lignes correspondantes de la table droite quand elles existent. Si aucune correspondance n’existe, les colonnes de la table droite sont remplies avec NULL.
Le LEFT JOIN est utile pour trouver les lignes « sans correspondance » dans la table droite : il suffit d’ajouter WHERE table_droite.col IS NULL.
# LEFT JOIN : tous les employés, même sans département
df = pd.read_sql("""
SELECT e.prenom, e.nom, e.salaire,
COALESCE(d.nom, '(sans département)') AS departement
FROM employes e
LEFT JOIN departements d ON e.dept_id = d.dept_id
ORDER BY departement, e.nom
""", conn)
print(f"LEFT JOIN — {len(df)} lignes (tous les employés, y compris Gilles)")
print(df.to_string(index=False))
LEFT JOIN — 7 lignes (tous les employés, y compris Gilles)
prenom nom salaire departement
Gilles Petit 3600.0 (sans département)
Eric Blanc 4700.0 Comptabilité
Bob Dupont 3800.0 Comptabilité
Fatima Ahmed 5500.0 Informatique
Charlie Leroy 5200.0 Informatique
Alice Martin 4500.0 Informatique
Diana Morel 4100.0 Marketing
# Anti-jointure : employés SANS département
df_sans = pd.read_sql("""
SELECT e.prenom, e.nom
FROM employes e
LEFT JOIN departements d ON e.dept_id = d.dept_id
WHERE d.dept_id IS NULL
""", conn)
print("Anti-jointure : employés sans département")
print(df_sans.to_string(index=False))
Anti-jointure : employés sans département
prenom nom
Gilles Petit
RIGHT JOIN et FULL OUTER JOIN#
Définition 50 (RIGHT JOIN)
Le RIGHT JOIN (RIGHT OUTER JOIN) est le symétrique du LEFT JOIN : il retourne toutes les lignes de la table droite, avec NULL pour les colonnes de la table gauche quand aucune correspondance n’existe.
SQLite ne supporte pas nativement le RIGHT JOIN — on peut le simuler en inversant l’ordre des tables dans un LEFT JOIN.
Définition 51 (FULL OUTER JOIN)
Le FULL OUTER JOIN retourne toutes les lignes des deux tables. Les lignes sans correspondance reçoivent NULL dans les colonnes de l’autre table. Il combine le résultat du LEFT JOIN et du RIGHT JOIN.
SQLite ne supporte pas le FULL OUTER JOIN nativement. On peut le simuler avec LEFT JOIN UNION ALL LEFT JOIN inversé.
# Simulation du FULL OUTER JOIN dans SQLite
# (toutes les combinaisons employe <-> departement, même sans correspondance)
full_outer_query = """
SELECT e.prenom, e.nom, d.nom AS departement
FROM employes e
LEFT JOIN departements d ON e.dept_id = d.dept_id
UNION ALL
SELECT NULL AS prenom, NULL AS nom, d.nom AS departement
FROM departements d
LEFT JOIN employes e ON e.dept_id = d.dept_id
WHERE e.emp_id IS NULL
"""
df_full = pd.read_sql(full_outer_query, conn)
print(f"FULL OUTER JOIN simulé — {len(df_full)} lignes")
print(df_full.to_string(index=False))
FULL OUTER JOIN simulé — 8 lignes
prenom nom departement
Alice Martin Informatique
Bob Dupont Comptabilité
Charlie Leroy Informatique
Diana Morel Marketing
Eric Blanc Comptabilité
Fatima Ahmed Informatique
Gilles Petit NaN
NaN NaN Logistique
CROSS JOIN#
Définition 52 (CROSS JOIN (produit cartésien))
Le CROSS JOIN produit le produit cartésien des deux tables : chaque ligne de la table gauche est combinée avec chaque ligne de la table droite. Si la table gauche a \(m\) lignes et la droite \(n\) lignes, le résultat a \(m \times n\) lignes.
Il n’y a pas de condition ON. Le CROSS JOIN est rarement utilisé en production mais utile pour générer des combinaisons (ex. : grille de disponibilités, calendrier).
Remarque 17
Un INNER JOIN sans clause ON (ou avec une condition toujours vraie) est équivalent à un CROSS JOIN. L’ancienne syntaxe avec des virgules dans FROM produisait un produit cartésien : FROM employes, departements — aujourd’hui dépréciée, car elle mène facilement à des jointures oubliées.
# CROSS JOIN : toutes les combinaisons (employé, département)
df_cross = pd.read_sql("""
SELECT e.prenom AS employe, d.nom AS departement
FROM employes e
CROSS JOIN departements d
ORDER BY e.prenom, d.nom
LIMIT 12
""", conn)
n_emp = conn.execute("SELECT COUNT(*) FROM employes").fetchone()[0]
n_dept = conn.execute("SELECT COUNT(*) FROM departements").fetchone()[0]
print(f"CROSS JOIN : {n_emp} × {n_dept} = {n_emp * n_dept} combinaisons (12 premières affichées)")
print(df_cross.to_string(index=False))
CROSS JOIN : 7 × 4 = 28 combinaisons (12 premières affichées)
employe departement
Alice Comptabilité
Alice Informatique
Alice Logistique
Alice Marketing
Bob Comptabilité
Bob Informatique
Bob Logistique
Bob Marketing
Charlie Comptabilité
Charlie Informatique
Charlie Logistique
Charlie Marketing
SELF JOIN#
Définition 53 (SELF JOIN (auto-jointure))
Un SELF JOIN est une jointure d’une table avec elle-même. Il est indispensable pour représenter des relations hiérarchiques ou réflexives (ex. : un employé a un manager, qui est lui-même un employé).
On utilise obligatoirement des alias pour distinguer les deux instances de la même table.
conn.execute("""
ALTER TABLE employes ADD COLUMN manager_id INTEGER REFERENCES employes(emp_id)
""")
conn.executescript("""
UPDATE employes SET manager_id = NULL WHERE emp_id = 1; -- Alice : DG
UPDATE employes SET manager_id = 1 WHERE emp_id IN (3,6); -- sous Alice
UPDATE employes SET manager_id = 2 WHERE emp_id = 5; -- sous Bob
UPDATE employes SET manager_id = 1 WHERE emp_id = 4; -- sous Alice
UPDATE employes SET manager_id = NULL WHERE emp_id = 2; -- Bob : DG adjoint
UPDATE employes SET manager_id = NULL WHERE emp_id = 7; -- Gilles sans manager
""")
df_self = pd.read_sql("""
SELECT
e.prenom || ' ' || e.nom AS employe,
m.prenom || ' ' || m.nom AS manager
FROM employes e
LEFT JOIN employes m ON e.manager_id = m.emp_id
ORDER BY manager, employe
""", conn)
print("SELF JOIN : employé → manager")
print(df_self.to_string(index=False))
SELF JOIN : employé → manager
employe manager
Alice Martin NaN
Bob Dupont NaN
Gilles Petit NaN
Charlie Leroy Alice Martin
Diana Morel Alice Martin
Fatima Ahmed Alice Martin
Eric Blanc Bob Dupont
Jointures multiples (3+ tables)#
Définition 54 (Jointures multiples)
On peut enchaîner autant de jointures que nécessaire dans une requête. Chaque JOIN ajoute une table à l’ensemble intermédiaire. L’ordre des JOIN n’affecte pas le résultat logique (le moteur SQL optimise l’ordre d’exécution), mais peut influencer les performances.
La bonne pratique est de nommer toutes les tables avec des alias courts et de qualifier chaque colonne ambiguë par son alias de table.
# 3 tables : employes + employe_projet + projets
df_3t = pd.read_sql("""
SELECT
e.prenom || ' ' || e.nom AS employe,
p.nom AS projet,
ep.role,
p.budget
FROM employes e
INNER JOIN employe_projet ep ON e.emp_id = ep.emp_id
INNER JOIN projets p ON ep.projet_id = p.projet_id
ORDER BY p.nom, e.nom
""", conn)
print("Jointure 3 tables : employes — projets — rôles")
print(df_3t.to_string(index=False))
Jointure 3 tables : employes — projets — rôles
employe projet role budget
Bob Dupont Audit fiscal Analyste 80000.0
Diana Morel Campagne social Responsable 120000.0
Charlie Leroy Portail client Chef de projet 180000.0
Alice Martin Portail client Développeur 180000.0
Fatima Ahmed Refonte ERP Architecte 250000.0
Charlie Leroy Refonte ERP Développeur 250000.0
Alice Martin Refonte ERP Chef de projet 250000.0
# 4 tables : employes + departements + employe_projet + projets
df_4t = pd.read_sql("""
SELECT
e.prenom || ' ' || e.nom AS employe,
d.nom AS departement,
p.nom AS projet,
ep.role
FROM employes e
INNER JOIN departements d ON e.dept_id = d.dept_id
INNER JOIN employe_projet ep ON e.emp_id = ep.emp_id
INNER JOIN projets p ON ep.projet_id = p.projet_id
ORDER BY departement, employe
""", conn)
print("\nJointure 4 tables : employes — departements — projets — rôles")
print(df_4t.to_string(index=False))
Jointure 4 tables : employes — departements — projets — rôles
employe departement projet role
Bob Dupont Comptabilité Audit fiscal Analyste
Alice Martin Informatique Refonte ERP Chef de projet
Alice Martin Informatique Portail client Développeur
Charlie Leroy Informatique Refonte ERP Développeur
Charlie Leroy Informatique Portail client Chef de projet
Fatima Ahmed Informatique Refonte ERP Architecte
Diana Morel Marketing Campagne social Responsable
Pièges courants#
Exemple 15 (Pièges liés aux jointures)
Trois pièges classiques à éviter :
1. Doublons par jointure N-N : joindre sans table de jonction sur une relation N-N multiplie les lignes. Toujours vérifier COUNT(*) avant et après une jointure.
2. Colonnes ambiguës : si dept_id existe dans employes et departements, écrire SELECT dept_id provoque une erreur d’ambiguïté. Toujours préfixer : e.dept_id ou d.dept_id.
3. Jointure sur NULL : NULL = NULL est UNKNOWN, jamais TRUE. Une jointure ON e.dept_id = d.dept_id n’inclura jamais les lignes où dept_id est NULL — utiliser un LEFT JOIN pour les inclure.
# Démonstration : doublons si jointure N-N sans table de jonction
# Ici on voit qu'Alice apparaît deux fois car elle est sur 2 projets
df_doublons = pd.read_sql("""
SELECT e.prenom, COUNT(*) AS nb_lignes
FROM employes e
INNER JOIN employe_projet ep ON e.emp_id = ep.emp_id
GROUP BY e.emp_id, e.prenom
HAVING COUNT(*) > 1
""", conn)
print("Employés apparaissant sur plusieurs projets (lignes dupliquées si non groupées) :")
print(df_doublons.to_string(index=False))
Employés apparaissant sur plusieurs projets (lignes dupliquées si non groupées) :
prenom nb_lignes
Alice 2
Charlie 2
Visualisation : diagrammes de Venn#
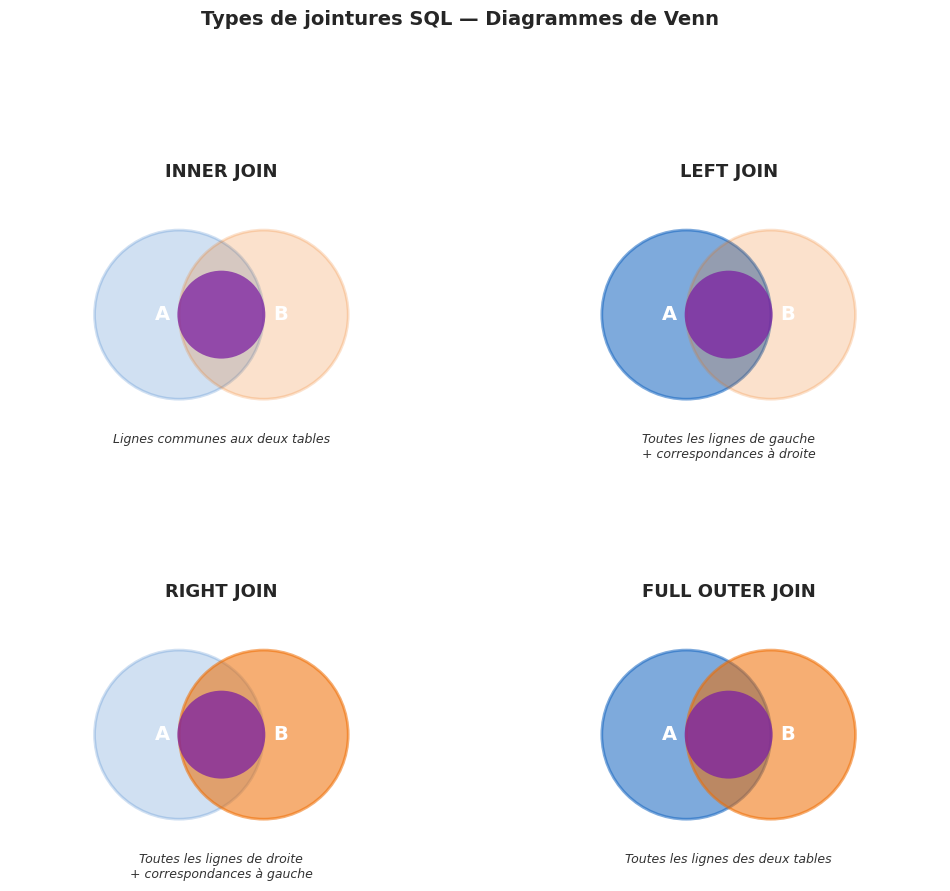
Résumé#
Ce chapitre a couvert l’ensemble des types de jointures SQL avec des exemples concrets :
INNER JOIN : lignes communes aux deux tables (le plus utilisé). Exclut les non-correspondances.
LEFT JOIN : toutes les lignes de gauche,
NULLà droite si pas de correspondance. Permet l’anti-jointure.RIGHT JOIN : symétrique du LEFT JOIN. Simulable avec un LEFT JOIN inversé.
FULL OUTER JOIN : toutes les lignes des deux côtés. Simulé en SQLite avec
UNION ALL.CROSS JOIN : produit cartésien. Puissant mais dangereux si mal maîtrisé.
SELF JOIN : jointure d’une table sur elle-même. Indispensable pour les hiérarchies.
Jointures multiples : enchaîner autant de
JOINque nécessaire, qualifier chaque colonne.
Remarque 18
Du point de vue des performances, les jointures sur des colonnes indexées sont très rapides. L’optimiseur SQL choisit automatiquement le meilleur ordre de jointure. En cas de requête lente, les outils EXPLAIN (SQLite) ou EXPLAIN ANALYZE (PostgreSQL) révèlent le plan d’exécution choisi et les éventuels manques d’index.
Remarque 19
La syntaxe JOIN … ON … a été introduite dans SQL-92 (aussi appelé SQL2). L’ancienne syntaxe avec des virgules dans FROM et la condition dans WHERE (FROM a, b WHERE a.id = b.id) est fonctionnellement équivalente à un INNER JOIN mais moins lisible et plus propice aux oublis de condition — elle est à éviter dans le code moderne.