Premiers pas avec SQL#
SQL : un langage déclaratif#
SQL (Structured Query Language) est le langage standard des bases de données relationnelles. Standardisé par l’ANSI et l’ISO depuis 1987 (SQL-86), il connaît des révisions majeures tous les quelques années (SQL-92, SQL:1999, SQL:2003, SQL:2016…). Sa particularité fondamentale est d’être déclaratif : on décrit ce que l’on veut, non comment l’obtenir. C’est le moteur du SGBDR qui optimise le plan d’exécution.
SQL se divise en plusieurs sous-langages :
Définition 17 (Sous-langages SQL)
DDL (Data Definition Language) : définit la structure des données —
CREATE,ALTER,DROP,TRUNCATE.DML (Data Manipulation Language) : manipule les données —
INSERT,UPDATE,DELETE,SELECT.DCL (Data Control Language) : gère les droits —
GRANT,REVOKE.TCL (Transaction Control Language) : gère les transactions —
COMMIT,ROLLBACK,SAVEPOINT.
En pratique, SELECT est parfois isolé sous le nom DQL (Data Query Language).
Créer une base SQLite en mémoire#
SQLite est une bibliothèque embarquée qui stocke toute la base dans un seul fichier (ou en mémoire avec ":memory:"). Elle est incluse dans la bibliothèque standard Python via le module sqlite3 — aucune installation de serveur n’est nécessaire.
Définition 18 (SQLite : caractéristiques)
SQLite est un SGBDR embarqué (serverless) : la base de données est un fichier unique .db ou .sqlite. Ses caractéristiques principales :
Typage dynamique (type affinity) : une colonne
INTEGERpeut stocker du texte si on le force.Transactions ACID garanties.
Un seul écrivain à la fois (verrouillage au niveau du fichier).
Idéal pour : tests, prototypes, applications mobiles, fichiers de configuration structurés.
Limites : pas de concurrence élevée en écriture, pas de types avancés (arrays, jsonb…).
# Connexion à une base en mémoire
conn = sqlite3.connect(":memory:")
# Activer les clés étrangères (désactivées par défaut dans SQLite)
conn.execute("PRAGMA foreign_keys = ON")
print("Base de données SQLite créée en mémoire.")
print(f"Version SQLite : {sqlite3.sqlite_version}")
Base de données SQLite créée en mémoire.
Version SQLite : 3.46.1
CREATE TABLE#
Définition 19 (Instruction CREATE TABLE)
CREATE TABLE définit le schéma d’une nouvelle table : son nom, ses colonnes, leurs types et leurs contraintes. La syntaxe de base est :
CREATE TABLE nom_table (col1 TYPE1 contraintes, col2 TYPE2 contraintes, ...);
L’option IF NOT EXISTS empêche une erreur si la table existe déjà.
conn.executescript("""
CREATE TABLE IF NOT EXISTS departements (
dept_id INTEGER PRIMARY KEY AUTOINCREMENT,
nom TEXT NOT NULL UNIQUE,
budget REAL DEFAULT 0.0
);
CREATE TABLE IF NOT EXISTS employes (
emp_id INTEGER PRIMARY KEY AUTOINCREMENT,
prenom TEXT NOT NULL,
nom TEXT NOT NULL,
email TEXT UNIQUE,
salaire REAL NOT NULL CHECK(salaire >= 0),
date_embauche TEXT,
dept_id INTEGER REFERENCES departements(dept_id) ON DELETE SET NULL
);
""")
print("Tables créées avec succès.")
Tables créées avec succès.
Insérer des données : INSERT INTO#
Définition 20 (Instruction INSERT INTO)
INSERT INTO ajoute un ou plusieurs tuples dans une table.
Forme explicite :
INSERT INTO table (col1, col2) VALUES (val1, val2);Forme courte (toutes les colonnes dans l’ordre) :
INSERT INTO table VALUES (val1, val2, ...);Insertion multiple :
INSERT INTO table (col1, col2) VALUES (...), (...), (...);
conn.executescript("""
INSERT INTO departements (nom, budget) VALUES
('Informatique', 150000.0),
('Comptabilité', 80000.0),
('Marketing', 120000.0),
('Logistique', 60000.0);
INSERT INTO employes (prenom, nom, email, salaire, date_embauche, dept_id) VALUES
('Alice', 'Martin', 'alice@corp.fr', 4500.0, '2019-03-15', 1),
('Bob', 'Dupont', 'bob@corp.fr', 3800.0, '2020-07-01', 2),
('Charlie', 'Leroy', 'charlie@corp.fr', 5200.0, '2018-11-20', 1),
('Diana', 'Morel', 'diana@corp.fr', 4100.0, '2021-02-10', 3),
('Eric', 'Blanc', 'eric@corp.fr', 4700.0, '2019-09-05', 2),
('Fatima', 'Ahmed', 'fatima@corp.fr', 5500.0, '2017-06-30', 1),
('Gilles', 'Petit', 'gilles@corp.fr', 3600.0, '2022-01-15', 4),
('Hélène', 'Rousseau','helene@corp.fr', 4300.0, '2020-04-22', 3),
('Ivan', 'Girard', 'ivan@corp.fr', 4900.0, '2016-08-18', 1),
('Julie', 'Bernard', 'julie@corp.fr', 3900.0, '2021-11-03', 2);
""")
print("Données insérées.")
Données insérées.
Requêtes SELECT#
Structure générale#
Définition 21 (Instruction SELECT)
SELECT est l’instruction fondamentale de SQL pour interroger les données. Sa structure générale est :
SELECT expressions FROM table WHERE condition ORDER BY col LIMIT n OFFSET m;
Les clauses sont évaluées dans cet ordre logique : FROM → WHERE → SELECT → ORDER BY → LIMIT/OFFSET.
# SELECT simple : toutes les colonnes
df = pd.read_sql("SELECT * FROM employes", conn)
print(df.to_string(index=False))
emp_id prenom nom email salaire date_embauche dept_id
1 Alice Martin alice@corp.fr 4500.0 2019-03-15 1
2 Bob Dupont bob@corp.fr 3800.0 2020-07-01 2
3 Charlie Leroy charlie@corp.fr 5200.0 2018-11-20 1
4 Diana Morel diana@corp.fr 4100.0 2021-02-10 3
5 Eric Blanc eric@corp.fr 4700.0 2019-09-05 2
6 Fatima Ahmed fatima@corp.fr 5500.0 2017-06-30 1
7 Gilles Petit gilles@corp.fr 3600.0 2022-01-15 4
8 Hélène Rousseau helene@corp.fr 4300.0 2020-04-22 3
9 Ivan Girard ivan@corp.fr 4900.0 2016-08-18 1
10 Julie Bernard julie@corp.fr 3900.0 2021-11-03 2
# Sélection de colonnes spécifiques avec alias
query = """
SELECT
emp_id,
prenom || ' ' || nom AS nom_complet,
salaire,
dept_id
FROM employes
"""
df = pd.read_sql(query, conn)
print(df.to_string(index=False))
emp_id nom_complet salaire dept_id
1 Alice Martin 4500.0 1
2 Bob Dupont 3800.0 2
3 Charlie Leroy 5200.0 1
4 Diana Morel 4100.0 3
5 Eric Blanc 4700.0 2
6 Fatima Ahmed 5500.0 1
7 Gilles Petit 3600.0 4
8 Hélène Rousseau 4300.0 3
9 Ivan Girard 4900.0 1
10 Julie Bernard 3900.0 2
Remarque 6
L’opérateur || est la concaténation de chaînes en SQL standard (et SQLite). PostgreSQL l’accepte aussi, mais MySQL utilise la fonction CONCAT(). SQLite interprète l’opérateur + sur des chaînes comme une addition numérique — attention à ne pas confondre les langages.
Remarque 7
L’expression SELECT * retourne toutes les colonnes dans l’ordre défini par le schéma. En production, il est préférable de lister explicitement les colonnes nécessaires : cela améliore la lisibilité, réduit le volume de données transmis, et protège le code contre les ruptures si le schéma évolue (ajout ou suppression d’une colonne).
WHERE : filtrer les lignes#
Définition 22 (Clause WHERE)
La clause WHERE filtre les tuples selon une condition booléenne évaluée ligne par ligne. Seules les lignes pour lesquelles la condition est vraie sont retournées. Les opérateurs disponibles incluent : =, <> (ou !=), <, >, <=, >=, AND, OR, NOT.
# Employés avec un salaire supérieur à 4500
df = pd.read_sql(
"SELECT prenom, nom, salaire FROM employes WHERE salaire > 4500 ORDER BY salaire DESC",
conn
)
print(df.to_string(index=False))
prenom nom salaire
Fatima Ahmed 5500.0
Charlie Leroy 5200.0
Ivan Girard 4900.0
Eric Blanc 4700.0
Exemple 7 (Combinaison de conditions avec AND / OR / NOT)
Les conditions dans WHERE peuvent être combinées librement. La priorité des opérateurs est : NOT > AND > OR. Utiliser des parenthèses pour lever les ambiguïtés :
La condition salaire > 4000 OR dept_id = 1 AND salaire < 5000 est évaluée comme salaire > 4000 OR (dept_id = 1 AND salaire < 5000). Pour exiger les deux, écrire (salaire > 4000 OR dept_id = 1) AND salaire < 5000.
BETWEEN, IN, LIKE, IS NULL#
Définition 23 (Opérateurs de filtrage avancés)
BETWEEN a AND b: valeur dans l’intervalle \([a, b]\) (bornes incluses).IN (v1, v2, ...): valeur appartenant à la liste.LIKE motif: correspondance de motif avec%(n’importe quelle séquence) et_(un caractère).IS NULL/IS NOT NULL: teste la présence ou l’absence de valeurNULL.
# BETWEEN : salaires entre 4000 et 5000
df_between = pd.read_sql(
"SELECT prenom, nom, salaire FROM employes WHERE salaire BETWEEN 4000 AND 5000",
conn
)
print("=== BETWEEN 4000 AND 5000 ===")
print(df_between.to_string(index=False))
# IN : département 1 ou 3
df_in = pd.read_sql(
"SELECT prenom, nom, dept_id FROM employes WHERE dept_id IN (1, 3)",
conn
)
print("\n=== IN (1, 3) ===")
print(df_in.to_string(index=False))
# LIKE : prénom commençant par 'A' ou 'E'
df_like = pd.read_sql(
"SELECT prenom, nom FROM employes WHERE prenom LIKE 'A%' OR prenom LIKE 'E%'",
conn
)
print("\n=== LIKE 'A%' OR 'E%' ===")
print(df_like.to_string(index=False))
=== BETWEEN 4000 AND 5000 ===
prenom nom salaire
Alice Martin 4500.0
Diana Morel 4100.0
Eric Blanc 4700.0
Hélène Rousseau 4300.0
Ivan Girard 4900.0
=== IN (1, 3) ===
prenom nom dept_id
Alice Martin 1
Charlie Leroy 1
Diana Morel 3
Fatima Ahmed 1
Hélène Rousseau 3
Ivan Girard 1
=== LIKE 'A%' OR 'E%' ===
prenom nom
Alice Martin
Eric Blanc
Remarque 8
L’opérateur LIKE avec un joker % en début de motif (LIKE '%mot') est particulièrement coûteux en performance car il empêche l’utilisation d’un index B-tree. Un motif ancré à gauche (LIKE 'mot%') est en revanche efficacement indexé. Pour des recherches textuelles complexes, les SGBDR modernes proposent la recherche plein texte (Full-Text Search) : FTS5 dans SQLite, tsvector dans PostgreSQL.
Exemple 8 (Recherche insensible à la casse)
En SQL standard, LIKE est sensible à la casse pour les caractères non-ASCII. SQLite propose l’option COLLATE NOCASE pour rendre la comparaison insensible à la casse sur les caractères ASCII :
WHERE prenom LIKE 'alice%' COLLATE NOCASE retourne aussi bien « Alice » que « ALICE » ou « alice ».
ORDER BY, LIMIT, OFFSET#
Définition 24 (Tri et pagination)
ORDER BY col [ASC|DESC]: trie les résultats selon une ou plusieurs colonnes.ASCest le défaut.LIMIT n: retourne au maximum \(n\) lignes.OFFSET m: saute les \(m\) premières lignes avant de commencer à retourner des résultats. Utile pour la pagination.
Exemple 9 (Pagination avec LIMIT / OFFSET)
Pour afficher la page 2 d’une liste de 3 résultats par page (triés par salaire décroissant), on utilise LIMIT 3 OFFSET 3 : on saute les 3 premiers résultats (page 1) et on retourne les 3 suivants (page 2).
# Top 5 des salaires
df_top = pd.read_sql(
"SELECT prenom, nom, salaire FROM employes ORDER BY salaire DESC LIMIT 5",
conn
)
print("=== Top 5 salaires ===")
print(df_top.to_string(index=False))
# Page 2 : résultats 4 à 6
df_page2 = pd.read_sql(
"SELECT prenom, nom, salaire FROM employes ORDER BY salaire DESC LIMIT 3 OFFSET 3",
conn
)
print("\n=== Page 2 (LIMIT 3 OFFSET 3) ===")
print(df_page2.to_string(index=False))
=== Top 5 salaires ===
prenom nom salaire
Fatima Ahmed 5500.0
Charlie Leroy 5200.0
Ivan Girard 4900.0
Eric Blanc 4700.0
Alice Martin 4500.0
=== Page 2 (LIMIT 3 OFFSET 3) ===
prenom nom salaire
Eric Blanc 4700.0
Alice Martin 4500.0
Hélène Rousseau 4300.0
Définition 25 (Tri multi-colonnes et tri sur expressions)
ORDER BY accepte plusieurs colonnes séparées par des virgules : le tri est d’abord effectué sur la première colonne, puis en cas d’égalité sur la deuxième, etc. On peut aussi trier sur une expression calculée ou sur un alias défini dans SELECT.
ORDER BY dept_id ASC, salaire DESC trie d’abord par département croissant, puis à département égal par salaire décroissant.
Expressions dans SELECT#
Définition 26 (Expressions calculées et alias)
SELECT peut contenir des expressions arbitraires sur les colonnes : opérations arithmétiques, fonctions scalaires, concaténations. Un alias (mot-clé AS) renomme une expression dans les résultats. L’alias peut ensuite être utilisé dans ORDER BY (mais pas dans WHERE, car WHERE est évalué avant SELECT).
# Expressions : salaire mensuel → annuel, et bonus 10%
query = """
SELECT
prenom || ' ' || nom AS employe,
salaire AS salaire_mensuel,
ROUND(salaire * 12, 2) AS salaire_annuel,
ROUND(salaire * 1.10, 2) AS avec_bonus_10pct
FROM employes
ORDER BY salaire_annuel DESC
"""
df = pd.read_sql(query, conn)
print(df.to_string(index=False))
employe salaire_mensuel salaire_annuel avec_bonus_10pct
Fatima Ahmed 5500.0 66000.0 6050.0
Charlie Leroy 5200.0 62400.0 5720.0
Ivan Girard 4900.0 58800.0 5390.0
Eric Blanc 4700.0 56400.0 5170.0
Alice Martin 4500.0 54000.0 4950.0
Hélène Rousseau 4300.0 51600.0 4730.0
Diana Morel 4100.0 49200.0 4510.0
Julie Bernard 3900.0 46800.0 4290.0
Bob Dupont 3800.0 45600.0 4180.0
Gilles Petit 3600.0 43200.0 3960.0
Visualisations#
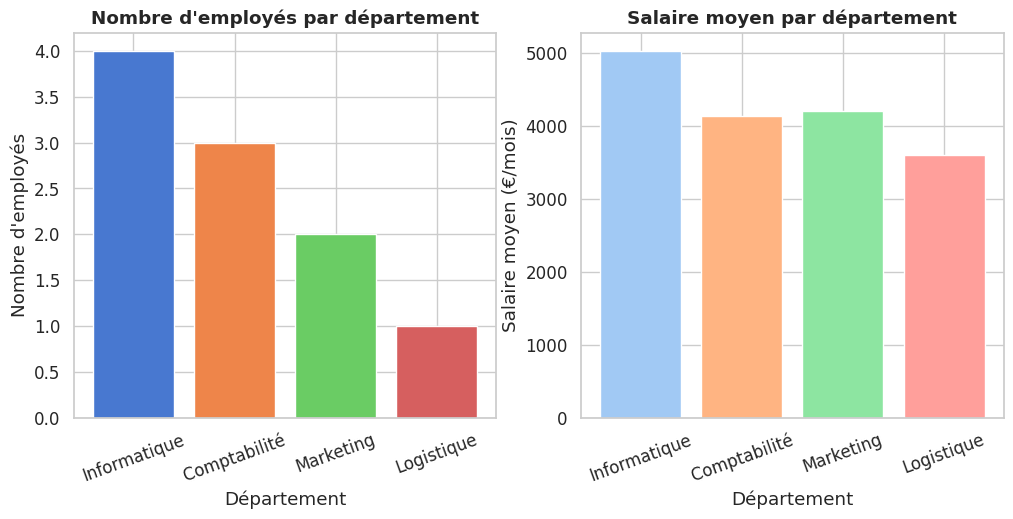
Résumé#
Dans ce chapitre, nous avons pris en main les instructions SQL fondamentales avec SQLite :
CREATE TABLE: définir le schéma avec des types et des contraintes.INSERT INTO: alimenter les tables avec des tuples individuels ou multiples.SELECT … FROM … WHERE: interroger et filtrer les données.Opérateurs :
=,<>,BETWEEN,IN,LIKE,IS NULLpour exprimer des conditions riches.ORDER BY: trier les résultats par une ou plusieurs colonnes.LIMIT/OFFSET: limiter et paginer les résultats.Expressions et alias (
AS) : calculer de nouvelles valeurs directement dansSELECT.
Remarque 9
Les exemples de ce chapitre utilisent SQLite, dont la syntaxe est conforme à SQL standard pour les instructions de base. Les différences notables avec PostgreSQL ou MySQL concernent surtout les types de données, la gestion des clés auto-incrémentées (AUTOINCREMENT vs SERIAL/GENERATED ALWAYS AS IDENTITY) et certaines fonctions de chaînes — sujets traités dans le chapitre suivant.