Fonctions fenêtrées#
Les fonctions fenêtrées (window functions) sont l’une des fonctionnalités les plus puissantes de SQL. Contrairement aux fonctions d’agrégat classiques, elles ne réduisent pas le nombre de lignes : chaque ligne conserve son identité et reçoit une valeur calculée sur un sous-ensemble de lignes appelé fenêtre.
conn = sqlite3.connect(":memory:")
conn.executescript("""
CREATE TABLE employes (
id INTEGER PRIMARY KEY,
nom TEXT NOT NULL,
region TEXT NOT NULL,
departement TEXT NOT NULL,
salaire REAL NOT NULL
);
CREATE TABLE ventes_mensuelles (
id INTEGER PRIMARY KEY,
employe_id INTEGER REFERENCES employes(id),
mois TEXT NOT NULL, -- 'YYYY-MM'
montant REAL NOT NULL
);
INSERT INTO employes VALUES
(1,'Alice','Nord','Informatique',62000),
(2,'Bob','Nord','Informatique',58000),
(3,'Carla','Sud','Marketing',52000),
(4,'David','Sud','Marketing',49000),
(5,'Eva','Nord','Finance',71000),
(6,'Fabien','Nord','Finance',68000),
(7,'Gina','Sud','Informatique',55000),
(8,'Hugo','Sud','Finance',60000),
(9,'Iris','Nord','Marketing',47000),
(10,'Jules','Sud','Marketing',51000);
INSERT INTO ventes_mensuelles VALUES
(1,1,'2024-01',12400),(2,1,'2024-02',15200),(3,1,'2024-03',11000),
(4,1,'2024-04',14500),(5,1,'2024-05',13800),(6,1,'2024-06',16200),
(7,2,'2024-01', 9800),(8,2,'2024-02',10500),(9,2,'2024-03', 8900),
(10,2,'2024-04',11200),(11,2,'2024-05',10800),(12,2,'2024-06',12000),
(13,3,'2024-01',22000),(14,3,'2024-02',19500),(15,3,'2024-03',21000),
(16,3,'2024-04',23500),(17,3,'2024-05',20800),(18,3,'2024-06',25000),
(19,4,'2024-01',17000),(20,4,'2024-02',14000),(21,4,'2024-03',15500),
(22,4,'2024-04',16800),(23,4,'2024-05',15200),(24,4,'2024-06',18000),
(25,5,'2024-01',31000),(26,5,'2024-02',28500),(27,5,'2024-03',33000),
(28,5,'2024-04',35000),(29,5,'2024-05',29500),(30,5,'2024-06',37000),
(31,6,'2024-01',26000),(32,6,'2024-02',29000),(33,6,'2024-03',24000),
(34,6,'2024-04',27500),(35,6,'2024-05',31000),(36,6,'2024-06',28000);
""")
pd.read_sql("SELECT * FROM employes ORDER BY region, departement", conn)
| id | nom | region | departement | salaire | |
|---|---|---|---|---|---|
| 0 | 5 | Eva | Nord | Finance | 71000.0 |
| 1 | 6 | Fabien | Nord | Finance | 68000.0 |
| 2 | 1 | Alice | Nord | Informatique | 62000.0 |
| 3 | 2 | Bob | Nord | Informatique | 58000.0 |
| 4 | 9 | Iris | Nord | Marketing | 47000.0 |
| 5 | 8 | Hugo | Sud | Finance | 60000.0 |
| 6 | 7 | Gina | Sud | Informatique | 55000.0 |
| 7 | 3 | Carla | Sud | Marketing | 52000.0 |
| 8 | 4 | David | Sud | Marketing | 49000.0 |
| 9 | 10 | Jules | Sud | Marketing | 51000.0 |
La clause OVER — principe#
Définition 68
La clause OVER transforme une fonction d’agrégat ou de classement en fonction fenêtrée. Elle définit la fenêtre : l’ensemble de lignes sur lesquelles la fonction opère pour calculer la valeur de chaque ligne.
Syntaxe générale :
fonction() OVER ([PARTITION BY ...] [ORDER BY ...] [frame_clause])
Théorème 3
Différence fondamentale entre GROUP BY et OVER :
GROUP BYréduit N lignes à 1 ligne par groupe — les lignes individuelles disparaissent.OVERlaisse toutes les lignes intactes et ajoute une colonne calculée sur la fenêtre définie pour chaque ligne.
# Illustration : même calcul avec GROUP BY (réduit) vs OVER (conserve les lignes)
print("=== Avec GROUP BY (résumé) ===")
display(pd.read_sql("""
SELECT departement, ROUND(AVG(salaire),2) AS moy_dept
FROM employes
GROUP BY departement
""", conn))
print("=== Avec OVER (toutes les lignes conservées) ===")
display(pd.read_sql("""
SELECT
nom,
departement,
salaire,
ROUND(AVG(salaire) OVER (PARTITION BY departement), 2) AS moy_dept
FROM employes
ORDER BY departement, salaire DESC
""", conn))
=== Avec GROUP BY (résumé) ===
| departement | moy_dept | |
|---|---|---|
| 0 | Finance | 66333.33 |
| 1 | Informatique | 58333.33 |
| 2 | Marketing | 49750.00 |
=== Avec OVER (toutes les lignes conservées) ===
| nom | departement | salaire | moy_dept | |
|---|---|---|---|---|
| 0 | Eva | Finance | 71000.0 | 66333.33 |
| 1 | Fabien | Finance | 68000.0 | 66333.33 |
| 2 | Hugo | Finance | 60000.0 | 66333.33 |
| 3 | Alice | Informatique | 62000.0 | 58333.33 |
| 4 | Bob | Informatique | 58000.0 | 58333.33 |
| 5 | Gina | Informatique | 55000.0 | 58333.33 |
| 6 | Carla | Marketing | 52000.0 | 49750.00 |
| 7 | Jules | Marketing | 51000.0 | 49750.00 |
| 8 | David | Marketing | 49000.0 | 49750.00 |
| 9 | Iris | Marketing | 47000.0 | 49750.00 |
Remarque 33
OVER () sans PARTITION BY ni ORDER BY définit une fenêtre couvrant toutes les lignes du résultat. C’est utile pour calculer un total global ou une moyenne globale tout en conservant le détail ligne par ligne.
PARTITION BY et ORDER BY dans la fenêtre#
Définition 69
PARTITION BY divise les lignes en partitions indépendantes. La fonction fenêtrée est appliquée séparément dans chaque partition, comme un GROUP BY qui ne réduirait pas les lignes.
Définition 70
ORDER BY dans la clause OVER définit l’ordre de traitement au sein de chaque partition. Il est indispensable pour les fonctions de classement (RANK, ROW_NUMBER) et les fonctions de décalage (LAG, LEAD). Il définit aussi le cadre de la fenêtre par défaut (de la première ligne au rang courant).
# PARTITION BY region + ORDER BY salaire : rang de chaque employé dans sa région
pd.read_sql("""
SELECT
nom,
region,
departement,
salaire,
RANK() OVER (PARTITION BY region ORDER BY salaire DESC) AS rang_region,
RANK() OVER (ORDER BY salaire DESC) AS rang_global
FROM employes
ORDER BY region, rang_region
""", conn)
| nom | region | departement | salaire | rang_region | rang_global | |
|---|---|---|---|---|---|---|
| 0 | Eva | Nord | Finance | 71000.0 | 1 | 1 |
| 1 | Fabien | Nord | Finance | 68000.0 | 2 | 2 |
| 2 | Alice | Nord | Informatique | 62000.0 | 3 | 3 |
| 3 | Bob | Nord | Informatique | 58000.0 | 4 | 5 |
| 4 | Iris | Nord | Marketing | 47000.0 | 5 | 10 |
| 5 | Hugo | Sud | Finance | 60000.0 | 1 | 4 |
| 6 | Gina | Sud | Informatique | 55000.0 | 2 | 6 |
| 7 | Carla | Sud | Marketing | 52000.0 | 3 | 7 |
| 8 | Jules | Sud | Marketing | 51000.0 | 4 | 8 |
| 9 | David | Sud | Marketing | 49000.0 | 5 | 9 |
Exemple 25
On peut appliquer plusieurs fonctions fenêtrées avec des partitions différentes dans la même requête. Par exemple, calculer simultanément le rang dans la région et le rang global, en utilisant deux clauses OVER distinctes.
Fonctions de classement#
Définition 71
ROW_NUMBER() attribue un numéro séquentiel unique à chaque ligne dans la partition, sans ex-aequo. En cas d’égalité de valeur, l’ordre d’attribution est arbitraire (dépend de l’implémentation).
Définition 72
RANK()attribue le même rang aux lignes ex-aequo, puis saute les rangs suivants (1, 2, 2, 4…).DENSE_RANK()attribue le même rang aux ex-aequo sans sauter de rang (1, 2, 2, 3…).NTILE(n)divise les lignes en n groupes de taille approximativement égale et retourne le numéro du groupe (1 à n).
# Comparaison ROW_NUMBER / RANK / DENSE_RANK / NTILE sur les salaires
pd.read_sql("""
SELECT
nom,
salaire,
ROW_NUMBER() OVER (ORDER BY salaire DESC) AS row_num,
RANK() OVER (ORDER BY salaire DESC) AS rank_,
DENSE_RANK() OVER (ORDER BY salaire DESC) AS dense_rank_,
NTILE(3) OVER (ORDER BY salaire DESC) AS quartile_3
FROM employes
ORDER BY salaire DESC
""", conn)
| nom | salaire | row_num | rank_ | dense_rank_ | quartile_3 | |
|---|---|---|---|---|---|---|
| 0 | Eva | 71000.0 | 1 | 1 | 1 | 1 |
| 1 | Fabien | 68000.0 | 2 | 2 | 2 | 1 |
| 2 | Alice | 62000.0 | 3 | 3 | 3 | 1 |
| 3 | Hugo | 60000.0 | 4 | 4 | 4 | 1 |
| 4 | Bob | 58000.0 | 5 | 5 | 5 | 2 |
| 5 | Gina | 55000.0 | 6 | 6 | 6 | 2 |
| 6 | Carla | 52000.0 | 7 | 7 | 7 | 2 |
| 7 | Jules | 51000.0 | 8 | 8 | 8 | 3 |
| 8 | David | 49000.0 | 9 | 9 | 9 | 3 |
| 9 | Iris | 47000.0 | 10 | 10 | 10 | 3 |
Exemple 26
ROW_NUMBER() avec PARTITION BY permet d’obtenir les N meilleurs enregistrements par groupe, un besoin fréquent en analyse.
# Top 2 vendeurs par région (total sur la période)
pd.read_sql("""
WITH totaux AS (
SELECT
e.nom,
e.region,
SUM(v.montant) AS total_ventes
FROM ventes_mensuelles v
JOIN employes e ON v.employe_id = e.id
GROUP BY e.id, e.nom, e.region
),
classement AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY region ORDER BY total_ventes DESC) AS rang
FROM totaux
)
SELECT nom, region, ROUND(total_ventes,2) AS total_ventes, rang
FROM classement
WHERE rang <= 2
ORDER BY region, rang
""", conn)
| nom | region | total_ventes | rang | |
|---|---|---|---|---|
| 0 | Eva | Nord | 194000.0 | 1 |
| 1 | Fabien | Nord | 165500.0 | 2 |
| 2 | Carla | Sud | 131800.0 | 1 |
| 3 | David | Sud | 96500.0 | 2 |
Remarque 34
NTILE(n) répartit les lignes le plus équitablement possible. Si le nombre de lignes n’est pas divisible par n, les premiers groupes reçoivent une ligne de plus que les derniers. Exemple : 10 lignes, NTILE(3) → groupes de 4, 3, 3 lignes.
Fonctions de décalage — LAG et LEAD#
Définition 73
LAG(col, n, defaut)retourne la valeur decolà n lignes en arrière dans la partition (par rapport à l’ordre défini).LEAD(col, n, defaut)retourne la valeur decolà n lignes en avant.Ces fonctions sont indispensables pour calculer des variations période sur période.
# Évolution mensuelle des ventes d'Alice (employe_id = 1)
pd.read_sql("""
SELECT
mois,
montant,
LAG(montant, 1) OVER (ORDER BY mois) AS mois_precedent,
ROUND(montant - LAG(montant, 1) OVER (ORDER BY mois), 2) AS variation,
ROUND(
100.0 * (montant - LAG(montant, 1) OVER (ORDER BY mois))
/ LAG(montant, 1) OVER (ORDER BY mois),
1) AS variation_pct
FROM ventes_mensuelles
WHERE employe_id = 1
ORDER BY mois
""", conn)
| mois | montant | mois_precedent | variation | variation_pct | |
|---|---|---|---|---|---|
| 0 | 2024-01 | 12400.0 | NaN | NaN | NaN |
| 1 | 2024-02 | 15200.0 | 12400.0 | 2800.0 | 22.6 |
| 2 | 2024-03 | 11000.0 | 15200.0 | -4200.0 | -27.6 |
| 3 | 2024-04 | 14500.0 | 11000.0 | 3500.0 | 31.8 |
| 4 | 2024-05 | 13800.0 | 14500.0 | -700.0 | -4.8 |
| 5 | 2024-06 | 16200.0 | 13800.0 | 2400.0 | 17.4 |
Exemple 27
LAG et LEAD acceptent un troisième argument : la valeur par défaut retournée lorsqu’il n’y a pas de ligne précédente/suivante (début ou fin de partition). Sans ce défaut, la valeur retournée est NULL.
Agrégats fenêtrés et cadre de fenêtre#
Définition 74
Le cadre de fenêtre (frame clause) précise quelles lignes de la partition sont incluses dans le calcul pour chaque ligne courante. Deux modes existent :
ROWS BETWEEN: basé sur des positions physiques de lignes.RANGE BETWEEN: basé sur des plages de valeurs.
Exemples courants :
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW— de la première ligne jusqu’à la ligne courante (cumul progressif).ROWS BETWEEN 2 PRECEDING AND CURRENT ROW— fenêtre glissante de 3 lignes.
Remarque 35
Quand ORDER BY est présent dans OVER mais qu’aucun cadre n’est spécifié, le cadre par défaut est RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Sans ORDER BY, le cadre est toute la partition.
# Cumul progressif et moyenne glissante sur 3 mois pour Alice
pd.read_sql("""
SELECT
mois,
montant,
ROUND(SUM(montant) OVER (ORDER BY mois
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW), 2) AS cumul,
ROUND(AVG(montant) OVER (ORDER BY mois
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW), 2) AS moy_3_mois
FROM ventes_mensuelles
WHERE employe_id = 1
ORDER BY mois
""", conn)
| mois | montant | cumul | moy_3_mois | |
|---|---|---|---|---|
| 0 | 2024-01 | 12400.0 | 12400.0 | 12400.00 |
| 1 | 2024-02 | 15200.0 | 27600.0 | 13800.00 |
| 2 | 2024-03 | 11000.0 | 38600.0 | 12866.67 |
| 3 | 2024-04 | 14500.0 | 53100.0 | 13566.67 |
| 4 | 2024-05 | 13800.0 | 66900.0 | 13100.00 |
| 5 | 2024-06 | 16200.0 | 83100.0 | 14833.33 |
# Ventes globales : running total et moyenne glissante 3 mois, tous employés confondus
df_global = pd.read_sql("""
SELECT
mois,
ROUND(SUM(montant), 2) AS total_mois,
ROUND(SUM(SUM(montant)) OVER (ORDER BY mois
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW), 2) AS cumul,
ROUND(AVG(SUM(montant)) OVER (ORDER BY mois
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW), 2) AS moy_3_mois
FROM ventes_mensuelles
GROUP BY mois
ORDER BY mois
""", conn)
df_global
| mois | total_mois | cumul | moy_3_mois | |
|---|---|---|---|---|
| 0 | 2024-01 | 118200.0 | 118200.0 | 118200.00 |
| 1 | 2024-02 | 116700.0 | 234900.0 | 117450.00 |
| 2 | 2024-03 | 113400.0 | 348300.0 | 116100.00 |
| 3 | 2024-04 | 128500.0 | 476800.0 | 119533.33 |
| 4 | 2024-05 | 121100.0 | 597900.0 | 121000.00 |
| 5 | 2024-06 | 136200.0 | 734100.0 | 128600.00 |
Remarque 36
ROWS BETWEEN compte des positions physiques : ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING inclut exactement la ligne précédente et la suivante, indépendamment des valeurs. RANGE BETWEEN compte des plages de valeurs : si plusieurs lignes ont la même valeur dans l”ORDER BY, elles sont toutes incluses dans le cadre — comportement différent et parfois surprenant.
Cas d’usage avancés#
Exemple 28
Le percentile peut être approximé avec NTILE ou calculé précisément avec CUME_DIST() (disponible dans SQLite >= 3.25).
# CUME_DIST : distribution cumulative des salaires
pd.read_sql("""
SELECT
nom,
salaire,
ROUND(CUME_DIST() OVER (ORDER BY salaire), 3) AS cume_dist,
ROUND(PERCENT_RANK() OVER (ORDER BY salaire), 3) AS percent_rank
FROM employes
ORDER BY salaire
""", conn)
| nom | salaire | cume_dist | percent_rank | |
|---|---|---|---|---|
| 0 | Iris | 47000.0 | 0.1 | 0.000 |
| 1 | David | 49000.0 | 0.2 | 0.111 |
| 2 | Jules | 51000.0 | 0.3 | 0.222 |
| 3 | Carla | 52000.0 | 0.4 | 0.333 |
| 4 | Gina | 55000.0 | 0.5 | 0.444 |
| 5 | Bob | 58000.0 | 0.6 | 0.556 |
| 6 | Hugo | 60000.0 | 0.7 | 0.667 |
| 7 | Alice | 62000.0 | 0.8 | 0.778 |
| 8 | Fabien | 68000.0 | 0.9 | 0.889 |
| 9 | Eva | 71000.0 | 1.0 | 1.000 |
Définition 75
Le cumul progressif (running total) est la somme de toutes les valeurs depuis le début de la série jusqu’à la ligne courante. En SQL fenêtré : SUM(col) OVER (ORDER BY date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW).
Remarque 37
La médiane mobile ne dispose pas d’une fonction native simple en SQL standard. On peut l’approximer avec une fenêtre glissante AVG ou utiliser des fonctions spécifiques aux SGBD (ex: PERCENTILE_CONT en PostgreSQL/SQL Server).
Visualisation — moyenne glissante#
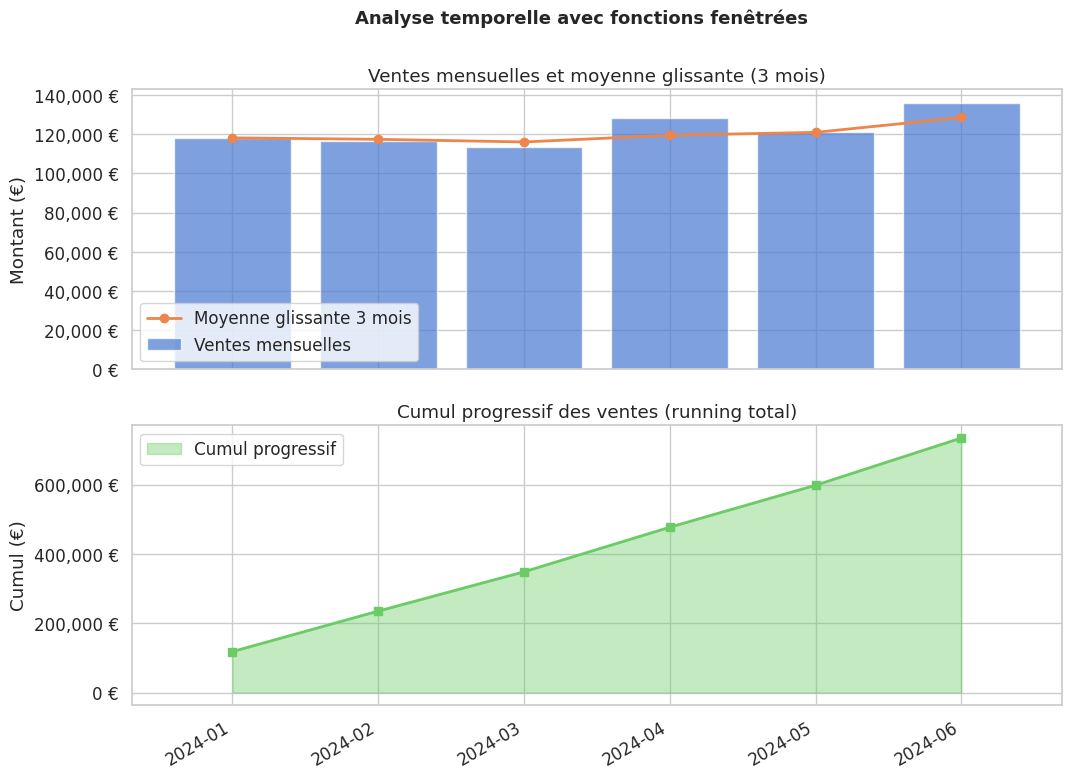
Résumé#
Définition 76
Récapitulatif des fonctions fenêtrées :
OVER (...)active le mode fenêtré : toutes les lignes sont conservées.PARTITION BYdivise les données en sous-ensembles indépendants.ORDER BYdansOVERdéfinit l’ordre intra-partition et le cadre par défaut.Classement :
ROW_NUMBER(unique),RANK(ex-aequo + saut),DENSE_RANK(ex-aequo sans saut),NTILE(n)(quantiles).Décalage :
LAG(passé),LEAD(futur) — calculs de variation période à période.Agrégats fenêtrés :
SUM,AVGavec cadreROWS BETWEENouRANGE BETWEEN— cumuls, moyennes glissantes.Distribution :
CUME_DIST,PERCENT_RANK— position relative dans la distribution.
Fonction |
Nécessite ORDER BY |
Dépend du cadre |
|---|---|---|
|
Oui |
Non |
|
Oui |
Non |
|
Oui |
Non |
|
Oui |
Non |
|
Optionnel |
Oui |
|
Oui |
Non |