Index et performance#
Un index est une structure de données auxiliaire qui permet au moteur SQL de localiser rapidement les lignes sans parcourir toute la table. Bien utilisés, les index peuvent réduire le temps de requête de plusieurs ordres de grandeur. Mal gérés, ils ralentissent les écritures et occupent inutilement de l’espace.
Full table scan vs index scan#
Définition 85
Un full table scan (parcours séquentiel) consiste à lire chaque ligne de la table une par une pour trouver celles qui satisfont le prédicat. Sa complexité est O(n) — le temps de réponse croît linéairement avec le nombre de lignes.
Définition 86
Un index scan utilise une structure auxiliaire (typiquement un B-tree) pour localiser directement les lignes pertinentes. Sa complexité est O(log n) pour la recherche dans l’index, plus le coût d’accès aux lignes trouvées.
Remarque 42
Le full table scan n’est pas toujours mauvais. Si la requête retourne une grande fraction des lignes (> 20-30 %), le moteur peut choisir délibérément le full scan car l’accès séquentiel est plus efficace que de nombreux accès aléatoires via l’index.
Structure B-tree#
Définition 87
Un arbre B (Balanced Tree) est la structure la plus courante pour les index SQL. C’est un arbre de recherche équilibré dont les nœuds internes contiennent des clés de guidage et les feuilles contiennent les valeurs réelles (clés d’index + pointeurs vers les lignes). Propriétés :
Hauteur O(log n) — chaque recherche traverse au plus log₂(n) nœuds.
Les feuilles sont liées entre elles, permettant des parcours de plages efficaces.
Toutes les insertions/suppressions maintiennent l’équilibre par division et fusion de nœuds.
Remarque 43
Coût des opérations sur un B-tree de n éléments :
Recherche exacte : O(log n)
Parcours de plage
BETWEEN a AND b: O(log n + k) où k = nombre de résultatsInsertion / suppression : O(log n) avec rééquilibrage
Types d’index#
Définition 88
SQLite supporte plusieurs types d’index :
Index simple : sur une seule colonne —
CREATE INDEX idx ON t(col).Index composite : sur plusieurs colonnes —
CREATE INDEX idx ON t(col1, col2). L’ordre des colonnes est crucial (préfixe gauche).Index unique : garantit l’unicité en plus de l’accès rapide —
CREATE UNIQUE INDEX.Index partiel : n’indexe qu’un sous-ensemble de lignes —
CREATE INDEX idx ON t(col) WHERE condition.Covering index : contient toutes les colonnes nécessaires à la requête, évitant l’accès à la table principale.
Exemple 31
Un index composite (departement, annee) peut accélérer les requêtes filtrant sur departement seul ou sur (departement, annee), mais pas celles filtrant uniquement sur annee. C’est la règle du préfixe gauche (leftmost prefix rule).
Mise en place du jeu de données#
def creer_grande_table(n=100_000):
"""Crée une base SQLite en mémoire avec n lignes dans la table employes."""
conn = sqlite3.connect(":memory:")
conn.execute("PRAGMA cache_size = -64000") # 64 MB cache
conn.executescript(f"""
CREATE TABLE employes (
id INTEGER PRIMARY KEY,
nom TEXT NOT NULL,
departement TEXT NOT NULL,
ville TEXT NOT NULL,
salaire REAL NOT NULL,
annee_entree INTEGER NOT NULL,
score INTEGER NOT NULL
);
""")
import random, string
random.seed(42)
depts = ['Informatique','Marketing','Finance','RH','Logistique','Commercial','Direction']
villes = ['Paris','Lyon','Marseille','Toulouse','Bordeaux','Nantes','Strasbourg','Lille']
def rand_nom():
return ''.join(random.choices(string.ascii_uppercase, k=1)) + \
''.join(random.choices(string.ascii_lowercase, k=random.randint(4, 9)))
rows = [
(i, rand_nom(), random.choice(depts), random.choice(villes),
round(random.uniform(30000, 120000), 2),
random.randint(2000, 2024), random.randint(0, 100))
for i in range(1, n+1)
]
conn.executemany(
"INSERT INTO employes VALUES (?,?,?,?,?,?,?)", rows
)
conn.commit()
return conn
conn = creer_grande_table(100_000)
print("Table créée avec", pd.read_sql("SELECT COUNT(*) AS n FROM employes", conn).iloc[0,0], "lignes")
Table créée avec 100000 lignes
EXPLAIN QUERY PLAN#
Définition 89
EXPLAIN QUERY PLAN est une directive SQLite qui affiche le plan d’exécution choisi par le moteur sans exécuter la requête. Elle indique notamment si le moteur réalise un full table scan (SCAN) ou utilise un index (SEARCH ... USING INDEX).
# Plan sans index
print("=== SANS index ===")
plan = conn.execute("""
EXPLAIN QUERY PLAN
SELECT * FROM employes WHERE departement = 'Finance' AND annee_entree = 2020
""").fetchall()
for row in plan:
print(row)
=== SANS index ===
(2, 0, 0, 'SCAN employes')
# Création des index
conn.execute("CREATE INDEX idx_dept ON employes(departement)")
conn.execute("CREATE INDEX idx_dept_annee ON employes(departement, annee_entree)")
conn.execute("CREATE UNIQUE INDEX idx_id ON employes(id)")
conn.execute("CREATE INDEX idx_salaire ON employes(salaire)")
# Index partiel : uniquement les hauts salaires
conn.execute("CREATE INDEX idx_haut_salaire ON employes(salaire) WHERE salaire > 90000")
conn.commit()
print("=== AVEC index ===")
plan_idx = conn.execute("""
EXPLAIN QUERY PLAN
SELECT * FROM employes WHERE departement = 'Finance' AND annee_entree = 2020
""").fetchall()
for row in plan_idx:
print(row)
=== AVEC index ===
(3, 0, 0, 'SEARCH employes USING INDEX idx_dept_annee (departement=? AND annee_entree=?)')
Mesure des performances avec et sans index#
def mesurer_temps(conn, requete, iterations=5):
"""Mesure le temps médian d'exécution d'une requête sur plusieurs itérations."""
temps = []
for _ in range(iterations):
t0 = time.perf_counter()
conn.execute(requete).fetchall()
temps.append(time.perf_counter() - t0)
return min(temps) # minimum pour réduire le bruit
# Base sans index
conn_sans = creer_grande_table(100_000)
# Base avec index
conn_avec = creer_grande_table(100_000)
conn_avec.execute("CREATE INDEX idx_dept ON employes(departement)")
conn_avec.execute("CREATE INDEX idx_dept_annee ON employes(departement, annee_entree)")
conn_avec.execute("CREATE INDEX idx_salaire ON employes(salaire)")
conn_avec.commit()
requetes = {
"Filtre dept = 'Finance'":
"SELECT * FROM employes WHERE departement = 'Finance'",
"Filtre dept + annee":
"SELECT * FROM employes WHERE departement = 'Finance' AND annee_entree = 2020",
"Plage salaire [60k-80k]":
"SELECT * FROM employes WHERE salaire BETWEEN 60000 AND 80000",
"COUNT(*) par dept":
"SELECT departement, COUNT(*) FROM employes GROUP BY departement",
}
resultats = []
for label, req in requetes.items():
t_sans = mesurer_temps(conn_sans, req) * 1000
t_avec = mesurer_temps(conn_avec, req) * 1000
resultats.append({
"Requête": label,
"Sans index (ms)": round(t_sans, 2),
"Avec index (ms)": round(t_avec, 2),
"Accélération": round(t_sans / t_avec, 1) if t_avec > 0 else "—"
})
df_perf = pd.DataFrame(resultats)
df_perf
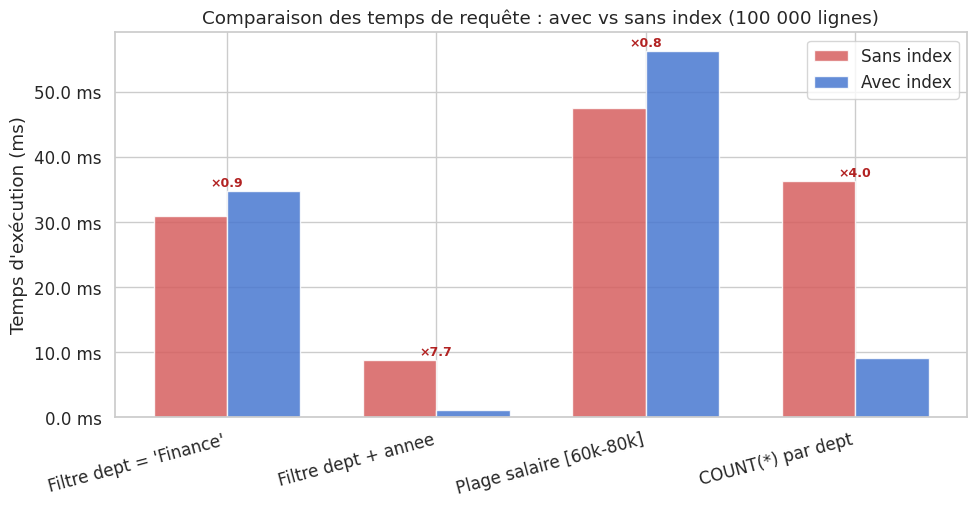
| Requête | Sans index (ms) | Avec index (ms) | Accélération | |
|---|---|---|---|---|
| 0 | Filtre dept = 'Finance' | 30.85 | 34.83 | 0.9 |
| 1 | Filtre dept + annee | 8.79 | 1.14 | 7.7 |
| 2 | Plage salaire [60k-80k] | 47.56 | 56.32 | 0.8 |
| 3 | COUNT(*) par dept | 36.36 | 9.05 | 4.0 |
Règles d’utilisation des index#
Définition 90
Quand créer un index :
Colonnes fréquemment utilisées dans
WHERE,JOIN ... ON,ORDER BY,GROUP BY.Colonnes avec haute cardinalité (beaucoup de valeurs distinctes) — un index sur un booléen est rarement utile.
Colonnes de clé étrangère (SQLite n’en crée pas automatiquement).
Remarque 44
Chaque index doit être maintenu lors de chaque INSERT, UPDATE, DELETE. Sur une table très écrite, un excès d’index dégrade significativement les performances en écriture. Il faut trouver le bon équilibre selon le ratio lecture/écriture de l’application.
Exemple 32
Un index n’est pas utilisé si :
La requête applique une fonction sur la colonne indexée :
WHERE UPPER(nom) = 'ALICE'ignore l’index surnom.La requête utilise un prédicat de type
LIKE '%motif'(joker au début).La sélectivité est trop faible (ex: colonne booléenne — le moteur préfère le full scan).
Le type de données ne correspond pas exactement (comparaison implicite de types).
# Démonstration : index inutilisé à cause d'une fonction
print("=== Index SUR salaire — utilisé ===")
plan1 = conn_avec.execute("""
EXPLAIN QUERY PLAN SELECT * FROM employes WHERE salaire > 90000
""").fetchall()
for r in plan1: print(r)
print("\n=== Index inutilisé (fonction sur la colonne) ===")
plan2 = conn_avec.execute("""
EXPLAIN QUERY PLAN SELECT * FROM employes WHERE CAST(salaire AS INTEGER) > 90000
""").fetchall()
for r in plan2: print(r)
=== Index SUR salaire — utilisé ===
(3, 0, 0, 'SEARCH employes USING INDEX idx_salaire (salaire>?)')
=== Index inutilisé (fonction sur la colonne) ===
(2, 0, 0, 'SCAN employes')
ANALYZE et statistiques#
Définition 91
La commande ANALYZE lit les tables et les index pour collecter des statistiques (distribution des valeurs, cardinalité) stockées dans la table système sqlite_stat1. L’optimiseur utilise ces statistiques pour choisir le meilleur plan d’exécution.
conn_avec.execute("ANALYZE")
conn_avec.commit()
# Consulter les statistiques collectées
pd.read_sql("""
SELECT tbl, idx, stat
FROM sqlite_stat1
ORDER BY tbl, idx
""", conn_avec)
| tbl | idx | stat | |
|---|---|---|---|
| 0 | employes | idx_dept | 100000 14286 |
| 1 | employes | idx_dept_annee | 100000 14286 572 |
| 2 | employes | idx_salaire | 100000 1 |
Remarque 45
Exécuter ANALYZE après un chargement massif de données ou après des modifications importantes de la table. Sans statistiques à jour, l’optimiseur peut choisir un plan sous-optimal, par exemple utiliser un index peu sélectif plutôt qu’un full scan plus rapide.
Pièges courants#
Remarque 46
Trop d’index — chaque index occupe de l’espace disque et ralentit les écritures. Sur une table fortement insérée (logs, événements), limiter les index aux stricts nécessaires.
Remarque 47
Covering index — si une requête ne sélectionne que des colonnes déjà présentes dans l’index, le moteur n’a même pas besoin d’accéder à la table principale. Exemple : CREATE INDEX idx_cov ON employes(departement, salaire) permet de répondre à SELECT salaire FROM employes WHERE departement='Finance' sans toucher la table.
# Covering index : le moteur ne lit pas la table principale
conn_avec.execute("CREATE INDEX idx_dept_sal ON employes(departement, salaire)")
conn_avec.execute("ANALYZE")
conn_avec.commit()
print("=== Covering index ===")
plan_cov = conn_avec.execute("""
EXPLAIN QUERY PLAN
SELECT departement, AVG(salaire)
FROM employes
WHERE departement IN ('Finance','Marketing')
GROUP BY departement
""").fetchall()
for r in plan_cov: print(r)
=== Covering index ===
(6, 0, 0, 'SEARCH employes USING COVERING INDEX idx_dept_sal (departement=?)')
Exemple 33
Un index partiel réduit la taille de l’index en n’indexant qu’un sous-ensemble de lignes. Utile pour les requêtes fréquentes sur des lignes rares (ex: commandes non traitées, comptes actifs).
# Index partiel : uniquement les scores >= 90
conn_avec.execute("DROP INDEX IF EXISTS idx_haut_score")
conn_avec.execute("CREATE INDEX idx_haut_score ON employes(score) WHERE score >= 90")
conn_avec.execute("ANALYZE")
conn_avec.commit()
print("=== Index partiel (score >= 90) ===")
plan_part = conn_avec.execute("""
EXPLAIN QUERY PLAN
SELECT nom, score FROM employes WHERE score >= 90 ORDER BY score DESC
""").fetchall()
for r in plan_part: print(r)
=== Index partiel (score >= 90) ===
(4, 0, 0, 'SEARCH employes USING INDEX idx_haut_score (score>?)')
Résumé#
Définition 92
Récapitulatif des index et de la performance :
Sans index, chaque requête filtrante est un full scan O(n).
Le B-tree est la structure d’index standard : recherche en O(log n), parcours de plages efficace.
Types d’index : simple, composite (règle du préfixe gauche), unique, partiel, covering.
EXPLAIN QUERY PLANrévèle si un index est utilisé (SEARCH ... USING INDEX) ou non (SCAN).Les index accélèrent les lectures mais ralentissent les écritures — chercher l’équilibre.
ANALYZEmet à jour les statistiques et aide l’optimiseur à choisir le bon plan.Pièges : fonctions sur colonnes indexées, LIKE avec joker initial, colonnes de faible cardinalité, index inutilisés.
Type d’index |
Cas d’usage |
Avantage |
|---|---|---|
Simple |
Filtre sur une colonne |
Rapide à créer, polyvalent |
Composite |
Filtres multi-colonnes |
Respecter l’ordre préfixe gauche |
Unique |
Contrainte d’unicité |
Double rôle : contrainte + performance |
Partiel |
Sous-ensemble de lignes |
Index plus petit, plus rapide |
Covering |
Toutes colonnes dans l’index |
Évite l’accès à la table |