PostgreSQL avancé#
Note : Les exemples SQL de ce chapitre supposent une connexion à un serveur PostgreSQL. Ils sont présentés comme blocs illustratifs et ne sont pas exécutés dans ce notebook. Les cellules Python exécutables simulent certains comportements avec des structures de données Python standard.
Types JSON et JSONB#
PostgreSQL est l’un des rares SGBD relationnels à offrir un support natif et performant des données semi-structurées au format JSON.
Définition 105
PostgreSQL propose deux types JSON :
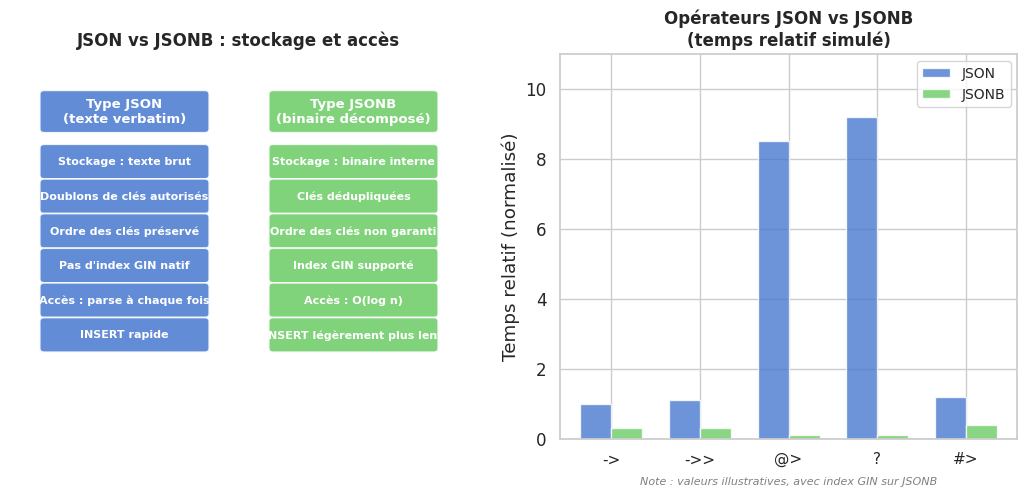
JSON: stockage textuel du document JSON, tel quel. La validation syntaxique est effectuée à l’insertion, mais aucune indexation interne n’est réalisée.JSONB(JSON Binary) : le document est décomposé et stocké dans un format binaire interne. Les clés sont dédupliquées et triées. L’accès aux champs est plus rapide, et les index GIN sont supportés. C’est le type recommandé dans la quasi-totalité des cas.
Opérateurs JSON#
Remarque 65
Les principaux opérateurs sur JSON/JSONB :
Opérateur |
Description |
Exemple |
|---|---|---|
|
Accès à une clé, retourne JSON |
|
|
Accès à une clé, retourne TEXT |
|
|
Accès par chemin (tableau de clés), retourne JSON |
|
|
Accès par chemin, retourne TEXT |
|
|
Contient (JSONB) |
|
|
Est contenu dans (JSONB) |
|
|
La clé existe (JSONB) |
|
|
Décompose en lignes clé/valeur |
Exemples illustratifs (PostgreSQL) :
-- Création d'une table avec colonne JSONB
CREATE TABLE produits (
id SERIAL PRIMARY KEY,
nom TEXT NOT NULL,
details JSONB
);
INSERT INTO produits (nom, details) VALUES
('Ordinateur', '{"marque": "Lenko", "ram_go": 16, "tags": ["laptop","pro"]}'),
('Souris', '{"marque": "Logitux", "sans_fil": true, "tags": ["peripherique"]}');
-- Lecture d'un champ
SELECT nom, details ->> 'marque' AS marque FROM produits;
-- Filtre sur une valeur JSON
SELECT nom FROM produits WHERE details @> '{"sans_fil": true}';
-- Existence d'une clé
SELECT nom FROM produits WHERE details ? 'ram_go';
-- Décomposer les paires clé/valeur
SELECT nom, cle, valeur
FROM produits, jsonb_each_text(details);
-- Mise à jour d'un champ JSONB (opérateur ||)
UPDATE produits
SET details = details || '{"stock": 42}'
WHERE nom = 'Ordinateur';
-- Index GIN pour les recherches JSONB
CREATE INDEX idx_produits_details ON produits USING GIN (details);
Exemple 38
Simulation Python du comportement de JSONB — accès et filtrage sur des documents JSON :
import json
produits = [
{"id": 1, "nom": "Ordinateur",
"details": {"marque": "Lenko", "ram_go": 16, "tags": ["laptop","pro"]}},
{"id": 2, "nom": "Souris",
"details": {"marque": "Logitux", "sans_fil": True, "tags": ["peripherique"]}},
{"id": 3, "nom": "Clavier",
"details": {"marque": "Meccasoft", "mecanique": True, "ram_go": None,
"tags": ["peripherique","pro"]}},
]
# Équivalent de : details ->> 'marque'
print("Marques :", [p["details"].get("marque") for p in produits])
# Équivalent de : details @> '{"sans_fil": true}'
sans_fil = [p["nom"] for p in produits if p["details"].get("sans_fil")]
print("Sans fil :", sans_fil)
# Équivalent de : details ? 'ram_go'
avec_ram = [p["nom"] for p in produits if "ram_go" in p["details"]]
print("Avec clé ram_go :", avec_ram)
# Équivalent de jsonb_each_text — aplatir clé/valeur
rows = []
for p in produits:
for k, v in p["details"].items():
rows.append({"produit": p["nom"], "cle": k, "valeur": str(v)})
pd.DataFrame(rows).head(8)
Marques : ['Lenko', 'Logitux', 'Meccasoft']
Sans fil : ['Souris']
Avec clé ram_go : ['Ordinateur', 'Clavier']
| produit | cle | valeur | |
|---|---|---|---|
| 0 | Ordinateur | marque | Lenko |
| 1 | Ordinateur | ram_go | 16 |
| 2 | Ordinateur | tags | ['laptop', 'pro'] |
| 3 | Souris | marque | Logitux |
| 4 | Souris | sans_fil | True |
| 5 | Souris | tags | ['peripherique'] |
| 6 | Clavier | marque | Meccasoft |
| 7 | Clavier | mecanique | True |
Tableaux (ARRAY)#
Définition 106
PostgreSQL supporte les tableaux comme type natif. Une colonne peut contenir un tableau de n’importe quel type de base (INTEGER[], TEXT[], REAL[]…). Les tableaux sont indexés à partir de 1 en PostgreSQL.
Exemples illustratifs (PostgreSQL) :
CREATE TABLE projets (
id SERIAL PRIMARY KEY,
nom TEXT,
tags TEXT[]
);
INSERT INTO projets VALUES (1, 'Alpha', ARRAY['urgent','web','frontend']);
INSERT INTO projets VALUES (2, 'Beta', '{backend,api,urgent}');
-- Accès au premier élément
SELECT nom, tags[1] AS premier_tag FROM projets;
-- Recherche : le tableau contient-il 'urgent' ?
SELECT nom FROM projets WHERE 'urgent' = ANY(tags);
-- Tous les tags doivent être présents
SELECT nom FROM projets WHERE ARRAY['urgent','web'] <@ tags;
-- Développer un tableau en lignes
SELECT nom, unnest(tags) AS tag FROM projets;
-- Agrégation en tableau
SELECT ARRAY_AGG(nom ORDER BY nom) AS noms FROM projets;
Remarque 66
Les tableaux sont préférables à JSONB quand les éléments sont homogènes (même type) et que l’on n’a pas besoin d’une structure imbriquée. Pour des structures hiérarchiques ou hétérogènes, JSONB est plus adapté.
Types personnalisés : CREATE TYPE#
Définition 107
PostgreSQL permet de définir des types personnalisés :
Type énuméré (
ENUM) : un ensemble fini de valeurs textuelles ordonnées.Type composite : un enregistrement avec des champs typés, similaire à un
struct.Type domaine : un type de base avec des contraintes supplémentaires.
Exemples illustratifs (PostgreSQL) :
-- Type énuméré
CREATE TYPE statut_commande AS ENUM (
'en_attente', 'validee', 'expediee', 'livree', 'annulee'
);
ALTER TABLE commandes ADD COLUMN statut statut_commande DEFAULT 'en_attente';
-- Les valeurs sont ordonnées : on peut comparer
SELECT * FROM commandes WHERE statut > 'validee';
-- Type composite
CREATE TYPE adresse AS (
rue TEXT,
ville TEXT,
code_postal CHAR(5)
);
CREATE TABLE clients (
id SERIAL PRIMARY KEY,
nom TEXT,
livraison adresse
);
INSERT INTO clients VALUES (1, 'Alice', ROW('12 rue des Roses', 'Paris', '75001'));
-- Accès aux champs du type composite
SELECT nom, (livraison).ville FROM clients;
-- Type domaine (contrainte sur un type de base)
CREATE DOMAIN email AS TEXT
CHECK (VALUE ~ '^[^@]+@[^@]+\.[^@]+$');
LATERAL JOIN#
Définition 108
La clause LATERAL permet à une sous-requête dans le FROM de référencer des colonnes des tables listées avant elle dans le même FROM. C’est une forme de « boucle SQL » : pour chaque ligne de la table de gauche, la sous-requête est évaluée avec les valeurs de cette ligne.
Exemples illustratifs (PostgreSQL) :
-- Pour chaque client, récupérer ses 3 dernières commandes
SELECT c.nom, cmd.id, cmd.montant, cmd.date
FROM clients c
CROSS JOIN LATERAL (
SELECT id, montant, date
FROM commandes
WHERE client_id = c.id
ORDER BY date DESC
LIMIT 3
) AS cmd;
-- LATERAL avec une fonction retournant un ensemble
SELECT p.nom, tag
FROM projets p
CROSS JOIN LATERAL unnest(p.tags) AS tag;
Remarque 67
Sans LATERAL, une sous-requête dans le FROM ne peut pas référencer d’autres tables du même FROM — elle est évaluée indépendamment. LATERAL lève cette restriction et est indispensable quand on veut appliquer une fonction de table ou une sous-requête corrélée ligne par ligne.
Window functions avancées#
Définition 109
Les fonctions de fenêtre avancées de PostgreSQL incluent des fonctions statistiques et de distribution non disponibles dans tous les SGBD :
MODE() WITHIN GROUP (ORDER BY col): valeur la plus fréquente.PERCENTILE_CONT(p) WITHIN GROUP (ORDER BY col): percentile par interpolation continue.PERCENTILE_DISC(p) WITHIN GROUP (ORDER BY col): percentile discret (valeur réellement présente dans les données).
Exemples illustratifs (PostgreSQL) :
SELECT
departement_id,
MODE() WITHIN GROUP (ORDER BY salaire) AS salaire_mode,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY salaire) AS mediane_continue,
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY salaire) AS mediane_discrete,
PERCENTILE_CONT(0.9) WITHIN GROUP (ORDER BY salaire) AS p90
FROM employes
GROUP BY departement_id;
# Simulation Python des percentiles et du mode
import statistics
donnees = {
"Informatique": [4200, 4500, 3900, 4800, 4100],
"Marketing": [3800, 4100, 3500, 3800, 4400],
"RH": [3200, 3500, 3100, 3200, 3400],
}
rows = []
for dept, salaires in donnees.items():
rows.append({
"departement": dept,
"mode": statistics.mode(salaires),
"mediane": statistics.median(salaires),
"p90": np.percentile(salaires, 90),
"salaire_moyen": round(statistics.mean(salaires), 1),
})
pd.DataFrame(rows)
| departement | mode | mediane | p90 | salaire_moyen | |
|---|---|---|---|---|---|
| 0 | Informatique | 4200 | 4200 | 4680.0 | 4300 |
| 1 | Marketing | 3800 | 3800 | 4280.0 | 3920 |
| 2 | RH | 3200 | 3200 | 3460.0 | 3280 |
Schémas et namespaces#
Remarque 68
Un schéma PostgreSQL est un espace de noms qui regroupe des objets (tables, vues, fonctions, types…). Par défaut, tout est dans le schéma public. Les schémas permettent de :
Organiser un grand nombre de tables par domaine fonctionnel.
Permettre à différentes applications de partager une même base sans collision de noms.
Contrôler les droits au niveau du schéma entier.
CREATE SCHEMA rh;
CREATE SCHEMA finance;
CREATE TABLE rh.employes (...);
CREATE TABLE finance.budgets (...);
-- Droits au niveau schéma
GRANT USAGE ON SCHEMA rh TO rh_team;
GRANT SELECT ON ALL TABLES IN SCHEMA rh TO rh_team;
-- search_path : ordre de recherche des schémas
SET search_path TO rh, public;
Extensions#
Remarque 69
PostgreSQL dispose d’un système d’extensions qui enrichit ses fonctionnalités sans modifier le code source :
Extension |
Rôle |
|---|---|
|
Statistiques sur les requêtes exécutées (temps, fréquence) |
|
Génération d’UUID (RFC 4122) |
|
Fonctions cryptographiques (hachage, chiffrement) |
|
Suppression des accents pour la recherche |
|
Support géospatial (voir chapitre suivant) |
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
SELECT uuid_generate_v4(); -- ex: a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
SELECT query, calls, total_exec_time, rows
FROM pg_stat_statements
ORDER BY total_exec_time DESC
LIMIT 10;
Full-text search#
Définition 110
PostgreSQL intègre un moteur de recherche plein texte (full-text search) basé sur deux types :
tsvector: représentation normalisée d’un document (lexèmes, positions, poids).tsquery: requête de recherche (opérateurs&,|,!,<->pour la proximité).
Les fonctions to_tsvector(langue, texte) et to_tsquery(langue, termes) convertissent texte et requête. L’opérateur @@ teste la correspondance. Un index GIN sur tsvector rend la recherche très rapide.
Exemples illustratifs (PostgreSQL) :
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
titre TEXT,
contenu TEXT,
ts_doc TSVECTOR GENERATED ALWAYS AS
(to_tsvector('french', titre || ' ' || contenu)) STORED
);
CREATE INDEX idx_articles_fts ON articles USING GIN (ts_doc);
-- Recherche
SELECT titre
FROM articles
WHERE ts_doc @@ to_tsquery('french', 'base & données');
-- Mise en évidence des termes trouvés
SELECT titre,
ts_headline('french', contenu, to_tsquery('french', 'base & données'))
FROM articles
WHERE ts_doc @@ to_tsquery('french', 'base & données');
Visualisation : JSON vs JSONB#
Résumé#
Remarque 70
PostgreSQL va bien au-delà du SQL standard et offre des fonctionnalités avancées qui en font un SGBD polyvalent :
Données semi-structurées :
JSONBstocke les documents JSON sous forme binaire indexable ; préférerJSONBàJSONdans presque tous les cas.Les opérateurs
->,->>,@>,?permettent un accès et un filtrage fins.
Types riches :
Les tableaux (
ARRAY) simplifient les listes homogènes sans table de jointure.Les types personnalisés (
ENUM, types composites, domaines) renforcent l’intégrité des données.
Requêtes avancées :
LATERALpermet des sous-requêtes corrélées dans leFROM.PERCENTILE_CONT,PERCENTILE_DISC,MODEenrichissent l’analyse statistique.
Organisation et recherche :
Les schémas organisent les objets et isolent les droits.
Les extensions (
uuid-ossp,pg_stat_statements,pgcrypto) enrichissent les fonctionnalités.Le full-text search (
tsvector,tsquery, index GIN) permet une recherche textuelle performante nativement.