Sous-requêtes et expressions de table communes (CTE)#
Une sous-requête est une requête SELECT imbriquée à l’intérieur d’une autre requête. Les CTE (Common Table Expressions) offrent une syntaxe plus lisible pour nommer et réutiliser des résultats intermédiaires. Ces deux mécanismes permettent de décomposer des problèmes analytiques complexes en étapes claires.
conn = sqlite3.connect(":memory:")
conn.executescript("""
CREATE TABLE employes (
id INTEGER PRIMARY KEY,
nom TEXT NOT NULL,
manager_id INTEGER REFERENCES employes(id),
departement TEXT,
salaire REAL
);
CREATE TABLE ventes (
id INTEGER PRIMARY KEY,
employe_id INTEGER REFERENCES employes(id),
montant REAL NOT NULL,
mois INTEGER NOT NULL,
annee INTEGER NOT NULL
);
-- Organigramme hiérarchique
INSERT INTO employes VALUES
(1, 'Directeur Général', NULL, 'Direction', 120000),
(2, 'Responsable Info', 1, 'Informatique', 85000),
(3, 'Responsable Mktg', 1, 'Marketing', 80000),
(4, 'Responsable Finance', 1, 'Finance', 90000),
(5, 'Alice', 2, 'Informatique', 62000),
(6, 'Bob', 2, 'Informatique', 58000),
(7, 'Carla', 3, 'Marketing', 52000),
(8, 'David', 3, 'Marketing', 49000),
(9, 'Eva', 4, 'Finance', 71000),
(10, 'Fabien', 4, 'Finance', 68000),
(11, 'Gina', 5, 'Informatique', 45000),
(12, 'Hugo', 5, 'Informatique', 43000);
INSERT INTO ventes VALUES
(1,5,12400,1,2024),(2,5,15200,2,2024),(3,5,11000,3,2024),(4,5,14500,4,2024),
(5,6, 9800,1,2024),(6,6,10500,2,2024),(7,6, 8900,3,2024),
(8,7,22000,1,2024),(9,7,19500,2,2024),(10,7,21000,3,2024),(11,7,23000,4,2024),
(12,8,17000,1,2024),(13,8,14000,2,2024),(14,8,15500,3,2024),
(15,9,31000,1,2024),(16,9,28500,2,2024),(17,9,33000,3,2024),(18,9,35000,4,2024),
(19,10,26000,1,2024),(20,10,29000,2,2024),(21,10,24000,3,2024),
(22,11, 5000,1,2024),(23,11, 6200,2,2024),
(24,12, 4800,1,2024),(25,12, 5500,2,2024),(26,12, 6100,3,2024);
""")
pd.read_sql("SELECT * FROM employes", conn)
| id | nom | manager_id | departement | salaire | |
|---|---|---|---|---|---|
| 0 | 1 | Directeur Général | NaN | Direction | 120000.0 |
| 1 | 2 | Responsable Info | 1.0 | Informatique | 85000.0 |
| 2 | 3 | Responsable Mktg | 1.0 | Marketing | 80000.0 |
| 3 | 4 | Responsable Finance | 1.0 | Finance | 90000.0 |
| 4 | 5 | Alice | 2.0 | Informatique | 62000.0 |
| 5 | 6 | Bob | 2.0 | Informatique | 58000.0 |
| 6 | 7 | Carla | 3.0 | Marketing | 52000.0 |
| 7 | 8 | David | 3.0 | Marketing | 49000.0 |
| 8 | 9 | Eva | 4.0 | Finance | 71000.0 |
| 9 | 10 | Fabien | 4.0 | Finance | 68000.0 |
| 10 | 11 | Gina | 5.0 | Informatique | 45000.0 |
| 11 | 12 | Hugo | 5.0 | Informatique | 43000.0 |
Sous-requêtes scalaires#
Définition 60
Une sous-requête scalaire retourne exactement une ligne et une colonne. Elle peut apparaître partout où une valeur scalaire est attendue : dans le SELECT, le WHERE, le HAVING ou le FROM.
Exemple 20
On peut calculer la différence entre le salaire de chaque employé et le salaire moyen global en plaçant la sous-requête dans le SELECT.
pd.read_sql("""
SELECT
nom,
salaire,
ROUND((SELECT AVG(salaire) FROM employes), 2) AS moyenne_globale,
ROUND(salaire - (SELECT AVG(salaire) FROM employes), 2) AS ecart_a_la_moyenne
FROM employes
WHERE salaire IS NOT NULL
ORDER BY ecart_a_la_moyenne DESC
""", conn)
| nom | salaire | moyenne_globale | ecart_a_la_moyenne | |
|---|---|---|---|---|
| 0 | Directeur Général | 120000.0 | 68583.33 | 51416.67 |
| 1 | Responsable Finance | 90000.0 | 68583.33 | 21416.67 |
| 2 | Responsable Info | 85000.0 | 68583.33 | 16416.67 |
| 3 | Responsable Mktg | 80000.0 | 68583.33 | 11416.67 |
| 4 | Eva | 71000.0 | 68583.33 | 2416.67 |
| 5 | Fabien | 68000.0 | 68583.33 | -583.33 |
| 6 | Alice | 62000.0 | 68583.33 | -6583.33 |
| 7 | Bob | 58000.0 | 68583.33 | -10583.33 |
| 8 | Carla | 52000.0 | 68583.33 | -16583.33 |
| 9 | David | 49000.0 | 68583.33 | -19583.33 |
| 10 | Gina | 45000.0 | 68583.33 | -23583.33 |
| 11 | Hugo | 43000.0 | 68583.33 | -25583.33 |
# Sous-requête dans le WHERE : employés gagnant plus que la moyenne
pd.read_sql("""
SELECT nom, departement, salaire
FROM employes
WHERE salaire > (SELECT AVG(salaire) FROM employes)
ORDER BY salaire DESC
""", conn)
| nom | departement | salaire | |
|---|---|---|---|
| 0 | Directeur Général | Direction | 120000.0 |
| 1 | Responsable Finance | Finance | 90000.0 |
| 2 | Responsable Info | Informatique | 85000.0 |
| 3 | Responsable Mktg | Marketing | 80000.0 |
| 4 | Eva | Finance | 71000.0 |
Sous-requêtes corrélées#
Définition 61
Une sous-requête corrélée fait référence à une colonne de la requête extérieure. Elle est réévaluée pour chaque ligne de la requête principale, ce qui peut être coûteux sur de grandes tables mais est souvent la formulation la plus naturelle.
Remarque 27
Les sous-requêtes corrélées ont une complexité O(n × m) où n est le nombre de lignes de la table externe et m le coût de la sous-requête interne. Sur de grandes tables, privilégier des jointures ou des CTE avec agrégation préalable.
# Employés dont le salaire est supérieur à la moyenne de leur département
pd.read_sql("""
SELECT
e.nom,
e.departement,
e.salaire,
ROUND((
SELECT AVG(e2.salaire)
FROM employes e2
WHERE e2.departement = e.departement
), 2) AS moy_dept
FROM employes e
WHERE e.salaire > (
SELECT AVG(e2.salaire)
FROM employes e2
WHERE e2.departement = e.departement
)
ORDER BY e.departement, e.salaire DESC
""", conn)
| nom | departement | salaire | moy_dept | |
|---|---|---|---|---|
| 0 | Responsable Finance | Finance | 90000.0 | 76333.33 |
| 1 | Responsable Info | Informatique | 85000.0 | 58600.00 |
| 2 | Alice | Informatique | 62000.0 | 58600.00 |
| 3 | Responsable Mktg | Marketing | 80000.0 | 60333.33 |
IN, EXISTS, NOT EXISTS#
Définition 62
IN (sous-requête): teste si une valeur appartient à l’ensemble retourné par la sous-requête. Équivaut à une série de comparaisons=reliées parOR.EXISTS (sous-requête): retourneTRUEsi la sous-requête renvoie au moins une ligne. La sous-requête ne retourne pas de données, elle teste seulement l’existence.NOT EXISTS: l’inverse d”EXISTS, utile pour les requêtes de type « qui n’a pas fait X ».
Remarque 28
EXISTS est généralement plus efficace que IN car le moteur peut s’arrêter dès qu’une ligne correspondante est trouvée (short-circuit). IN avec sous-requête peut se comporter comme EXISTS selon l’optimiseur, mais EXISTS est plus prévisible.
# IN : employés ayant réalisé des ventes
pd.read_sql("""
SELECT nom, departement
FROM employes
WHERE id IN (SELECT DISTINCT employe_id FROM ventes)
ORDER BY nom
""", conn)
| nom | departement | |
|---|---|---|
| 0 | Alice | Informatique |
| 1 | Bob | Informatique |
| 2 | Carla | Marketing |
| 3 | David | Marketing |
| 4 | Eva | Finance |
| 5 | Fabien | Finance |
| 6 | Gina | Informatique |
| 7 | Hugo | Informatique |
# NOT EXISTS : employés n'ayant réalisé aucune vente
pd.read_sql("""
SELECT nom, departement
FROM employes
WHERE NOT EXISTS (
SELECT 1 FROM ventes v WHERE v.employe_id = employes.id
)
ORDER BY nom
""", conn)
| nom | departement | |
|---|---|---|
| 0 | Directeur Général | Direction |
| 1 | Responsable Finance | Finance |
| 2 | Responsable Info | Informatique |
| 3 | Responsable Mktg | Marketing |
# EXISTS : départements ayant au moins un employé avec ventes > 20 000 sur un mois
pd.read_sql("""
SELECT DISTINCT e.departement
FROM employes e
WHERE EXISTS (
SELECT 1
FROM ventes v
WHERE v.employe_id = e.id
AND v.montant > 20000
)
ORDER BY e.departement
""", conn)
| departement | |
|---|---|
| 0 | Finance |
| 1 | Marketing |
Remarque 29
NOT IN (sous-requête) se comporte de manière surprenante si la sous-requête retourne une valeur NULL : la comparaison valeur NOT IN (NULL, ...) est toujours UNKNOWN (jamais TRUE), ce qui supprime toutes les lignes. Préférer NOT EXISTS pour éviter ce piège.
Exemple 21
Si employe_id contient un NULL dans la table ventes, WHERE id NOT IN (SELECT employe_id FROM ventes) ne retourne aucune ligne — même si des employés n’ont aucune vente. NOT EXISTS est immunisé contre ce comportement.
ANY et ALL#
Définition 63
val > ANY (sous-requête): vrai sivalest supérieure à au moins une valeur de la sous-requête. Équivalent àval > MIN(sous-requête).val > ALL (sous-requête): vrai sivalest supérieure à toutes les valeurs. Équivalent àval > MAX(sous-requête).
# Employés gagnant plus que TOUS les membres du département Marketing
# SQLite ne supporte pas ALL/ANY — équivalent : > MAX(...) pour ALL, > MIN(...) pour ANY
pd.read_sql("""
SELECT nom, departement, salaire
FROM employes
WHERE salaire > (
SELECT MAX(salaire) FROM employes
WHERE departement = 'Marketing'
AND salaire IS NOT NULL
)
ORDER BY salaire DESC
""", conn)
| nom | departement | salaire | |
|---|---|---|---|
| 0 | Directeur Général | Direction | 120000.0 |
| 1 | Responsable Finance | Finance | 90000.0 |
| 2 | Responsable Info | Informatique | 85000.0 |
Remarque 30
ANY et ALL subissent les problèmes liés aux NULL : val > ALL (SELECT ...) retourne FALSE dès qu’un NULL est présent dans la sous-requête. Filtrer avec WHERE col IS NOT NULL est indispensable. SQLite ne supporte pas la syntaxe ANY/ALL — on utilise leurs équivalents : > MAX(...) pour ALL et > MIN(...) pour ANY.
CTE avec WITH#
Définition 64
Une expression de table commune (CTE, Common Table Expression) est définie avec le mot-clé WITH avant la requête principale. Elle crée un résultat nommé et temporaire, réutilisable dans la requête principale. La syntaxe est :
WITH nom_cte AS (SELECT ...) SELECT ... FROM nom_cte
Remarque 31
Les CTE améliorent considérablement la lisibilité par rapport aux sous-requêtes imbriquées. Elles permettent de nommer les étapes intermédiaires, de les documenter et de les réutiliser plusieurs fois dans la même requête — ce qu’une sous-requête répétée ne peut pas faire élégamment.
# CTE : top 3 vendeurs par montant total avec leur rang
pd.read_sql("""
WITH total_par_employe AS (
SELECT
e.nom,
e.departement,
SUM(v.montant) AS total_ventes
FROM ventes v
JOIN employes e ON v.employe_id = e.id
GROUP BY e.id, e.nom, e.departement
),
stats AS (
SELECT AVG(total_ventes) AS moyenne FROM total_par_employe
)
SELECT
t.nom,
t.departement,
ROUND(t.total_ventes, 2) AS total_ventes,
ROUND(s.moyenne, 2) AS moyenne_globale,
ROUND(t.total_ventes - s.moyenne, 2) AS ecart
FROM total_par_employe t, stats s
ORDER BY t.total_ventes DESC
""", conn)
| nom | departement | total_ventes | moyenne_globale | ecart | |
|---|---|---|---|---|---|
| 0 | Eva | Finance | 127500.0 | 56050.0 | 71450.0 |
| 1 | Carla | Marketing | 85500.0 | 56050.0 | 29450.0 |
| 2 | Fabien | Finance | 79000.0 | 56050.0 | 22950.0 |
| 3 | Alice | Informatique | 53100.0 | 56050.0 | -2950.0 |
| 4 | David | Marketing | 46500.0 | 56050.0 | -9550.0 |
| 5 | Bob | Informatique | 29200.0 | 56050.0 | -26850.0 |
| 6 | Hugo | Informatique | 16400.0 | 56050.0 | -39650.0 |
| 7 | Gina | Informatique | 11200.0 | 56050.0 | -44850.0 |
Exemple 22
Les CTE permettent de retrouver la N-ième valeur d’une série sans recourir aux fonctions fenêtrées. On utilise LIMIT et OFFSET.
# 2e salaire le plus élevé (sans fonctions fenêtrées)
pd.read_sql("""
WITH salaires_distincts AS (
SELECT DISTINCT salaire FROM employes
WHERE salaire IS NOT NULL
ORDER BY salaire DESC
)
SELECT salaire AS deuxieme_plus_eleve
FROM salaires_distincts
LIMIT 1 OFFSET 1
""", conn)
| deuxieme_plus_eleve | |
|---|---|
| 0 | 90000.0 |
Exemple 23
Plusieurs CTE peuvent être enchaînées dans un seul bloc WITH, séparées par des virgules. Chaque CTE peut référencer les CTE définies avant elle. C’est un mécanisme équivalent à des vues temporaires locales à la requête.
Définition 65
En SQL standard, une CTE est évaluée une fois et son résultat peut être réutilisé dans la requête principale. Certains SGBD (PostgreSQL) proposent la directive MATERIALIZED / NOT MATERIALIZED pour contrôler si le résultat est mis en cache ou réinline à chaque utilisation.
CTE récursives — hiérarchies#
Définition 66
Une CTE récursive se compose de deux parties reliées par UNION ALL :
Membre de base (anchor) : le cas initial (racine de la hiérarchie).
Membre récursif : fait référence à la CTE elle-même pour parcourir les niveaux suivants.
La récursion s’arrête quand le membre récursif ne produit plus de lignes.
Remarque 32
SQLite supporte les CTE récursives depuis la version 3.8.3. La clause WITH RECURSIVE est obligatoire. Par défaut, SQLite limite la profondeur de récursion à 1000 niveaux (paramètre SQLITE_MAX_EXPR_DEPTH).
# CTE récursive : organigramme complet avec niveau hiérarchique
df_org = pd.read_sql("""
WITH RECURSIVE organigramme AS (
-- Membre de base : le sommet de la hiérarchie
SELECT
id,
nom,
manager_id,
0 AS niveau,
nom AS chemin
FROM employes
WHERE manager_id IS NULL
UNION ALL
-- Membre récursif : les subordonnés de chaque niveau
SELECT
e.id,
e.nom,
e.manager_id,
o.niveau + 1,
o.chemin || ' > ' || e.nom
FROM employes e
JOIN organigramme o ON e.manager_id = o.id
)
SELECT
niveau,
REPLACE(' ', ' ', SUBSTR(' ', 1, niveau*4)) || nom AS poste,
chemin
FROM organigramme
ORDER BY chemin
""", conn)
df_org
| niveau | poste | chemin | |
|---|---|---|---|
| 0 | 0 | Directeur Général | Directeur Général |
| 1 | 1 | Responsable Finance | Directeur Général > Responsable Finance |
| 2 | 2 | Eva | Directeur Général > Responsable Finance > Eva |
| 3 | 2 | Fabien | Directeur Général > Responsable Finance > Fabien |
| 4 | 1 | Responsable Info | Directeur Général > Responsable Info |
| 5 | 2 | Alice | Directeur Général > Responsable Info > Alice |
| 6 | 3 | Gina | Directeur Général > Responsable Info > Alice >... |
| 7 | 3 | Hugo | Directeur Général > Responsable Info > Alice >... |
| 8 | 2 | Bob | Directeur Général > Responsable Info > Bob |
| 9 | 1 | Responsable Mktg | Directeur Général > Responsable Mktg |
| 10 | 2 | Carla | Directeur Général > Responsable Mktg > Carla |
| 11 | 2 | David | Directeur Général > Responsable Mktg > David |
# CTE récursive pour générer une séquence de nombres (1 à 12)
pd.read_sql("""
WITH RECURSIVE seq(n) AS (
SELECT 1
UNION ALL
SELECT n + 1 FROM seq WHERE n < 12
)
SELECT n AS mois FROM seq
""", conn)
| mois | |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
| 5 | 6 |
| 6 | 7 |
| 7 | 8 |
| 8 | 9 |
| 9 | 10 |
| 10 | 11 |
| 11 | 12 |
Exemple 24
La colonne chemin construite par concaténation (||) dans la CTE récursive matérialise le chemin complet de la racine à chaque nœud. Cette technique est classique pour détecter les cycles (si chemin LIKE '%>' || e.nom || '>%') ou pour afficher des arborescences lisibles.
Visualisation — organigramme#
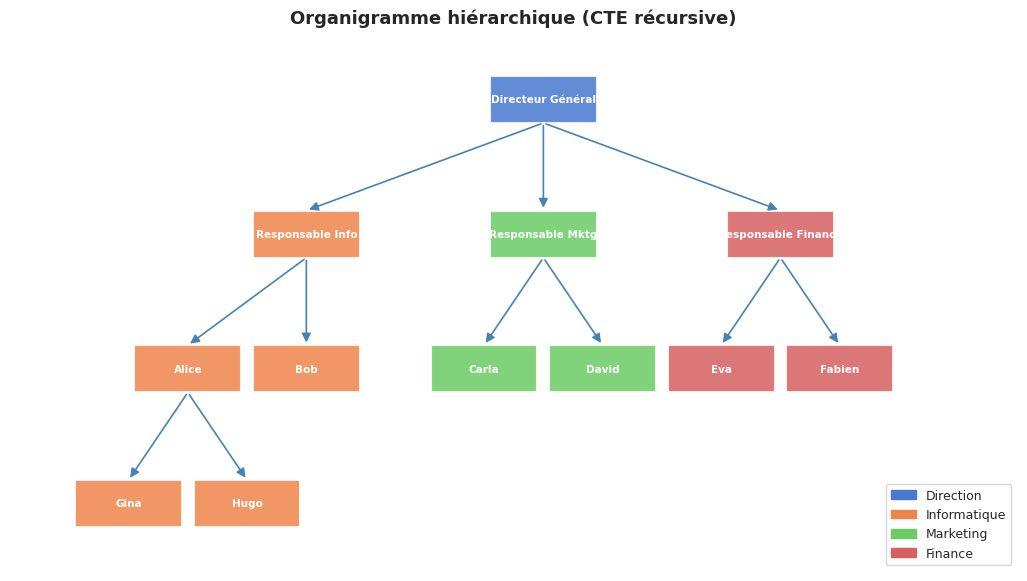
Résumé#
Définition 67
Récapitulatif :
Les sous-requêtes scalaires retournent une seule valeur et peuvent apparaître dans
SELECT,WHEREouHAVING.Les sous-requêtes corrélées référencent la requête externe ; elles sont réévaluées pour chaque ligne.
INteste l’appartenance à un ensemble ;EXISTS/NOT EXISTSteste l’existence de lignes.ANYetALLpermettent des comparaisons avec un ensemble de valeurs.Les CTE (
WITH) nomment des résultats intermédiaires pour améliorer la lisibilité et la réutilisabilité.Les CTE récursives (
WITH RECURSIVE) parcourent des hiérarchies et des graphes, en alternant un membre de base et un membre récursif.
Mécanisme |
Cas d’usage |
Performance |
|---|---|---|
Sous-requête scalaire |
Valeur de référence globale |
Bonne si non corrélée |
Sous-requête corrélée |
Calcul par ligne avec contexte |
Potentiellement O(n²) |
|
Filtrage par appartenance |
|
CTE simple |
Lisibilité, réutilisation |
Équivalent à une sous-requête |
CTE récursive |
Hiérarchies, graphes, séquences |
Dépend de la profondeur |