NoSQL : Redis#
Redis (Remote Dictionary Server) est une base de données en mémoire, open-source, créée par Salvatore Sanfilippo en 2009. Contrairement aux bases relationnelles qui stockent les données sur disque et les chargent à la demande, Redis maintient tout en RAM, ce qui lui permet d’atteindre des latences inférieures à la milliseconde sur des millions d’opérations par seconde. Cette caractéristique en fait l’outil de référence pour les cas d’usage où la vitesse est critique : cache, sessions, files de messages, classements en temps réel.
Redis n’est pas une base généraliste. On l’utilise à côté d’une base relationnelle — PostgreSQL ou MySQL — pour y déporter les données chaudes, les données temporaires ou les structures de données dont la manipulation en SQL serait coûteuse ou peu naturelle. Comprendre Redis, c’est comprendre quand ne pas utiliser SQL.
Structures de données natives#
La caractéristique la plus distinctive de Redis est d’exposer directement des structures de données de haut niveau, plutôt qu’un simple stockage clé-valeur brut. Chaque clé Redis est associée à un type, et les opérations disponibles dépendent du type.
Définition 121
Redis propose sept structures de données principales :
String : valeur binaire arbitraire, jusqu’à 512 Mo. Utilisée pour les compteurs, les caches JSON, les flags.
List : liste doublement liée de strings. Insertion en O(1) en tête ou en queue. Utilisée pour les files et les piles.
Hash : dictionnaire de paires champ-valeur. Analogue à un objet ou à une ligne de table.
Set : ensemble non ordonné de strings uniques. Opérations ensemblistes (union, intersection, différence).
Sorted Set (ZSet) : ensemble ordonné par un score flottant. Parfait pour les classements.
Stream : journal de messages immuables avec groupes de consommateurs.
Bitmap / HyperLogLog : structures spécialisées pour le comptage et les statistiques approximatives.
Remarque 81
La convention habituelle pour nommer les clés Redis est type:id:champ, par exemple user:42:session ou product:123:views. Ce nommage structuré facilite la lisibilité et permet des recherches par pattern avec SCAN. Redis ne supporte pas de requêtes complexes sur les clés — la structure doit être encodée dans le nom.
Commandes fondamentales#
String : SET, GET, INCR#
Les Strings sont le type le plus simple et le plus polyvalent. Ils servent aussi bien à stocker une valeur JSON qu’à implémenter un compteur atomique.
SET compteur:visites 0
INCR compteur:visites -- atomique : renvoie 1
INCRBY compteur:visites 10 -- renvoie 11
GET compteur:visites -- renvoie "11"
SET cache:user:42 '{"nom":"Alice","role":"admin"}'
GET cache:user:42
Exemple 43
Stocker et récupérer le nombre de pages vues d’un article de blog :
Chaque requête HTTP incrémente la clé article:101:views avec INCR. L’opération est atomique — même sous charge concurrente, Redis garantit qu’aucun incrément n’est perdu. Pour lire le total, une seule commande GET suffit. La latence est inférieure à 0,1 ms, contre plusieurs millisecondes pour une requête UPDATE ... SET views = views + 1 en SQL sous charge.
List : LPUSH, RPUSH, LRANGE, LPOP#
Les Lists Redis sont des listes doublement liées. L’insertion en tête (LPUSH) ou en queue (RPUSH) est en O(1).
LPUSH notifications:user:42 "Nouveau message de Bob"
LPUSH notifications:user:42 "Votre commande est expédiée"
LRANGE notifications:user:42 0 -1 -- toute la liste (du plus récent au plus ancien)
RPOP notifications:user:42 -- consomme l'élément le plus ancien
LLEN notifications:user:42 -- longueur de la liste
Définition 122
Le pattern queue (FIFO) avec Redis s’implémente en combinant RPUSH (enqueue) et LPOP (dequeue). Pour un traitement asynchrone sans perte de messages, on préfère BLPOP — la version bloquante — qui attend qu’un élément soit disponible plutôt que de retourner nil.
Hash : HSET, HGET, HGETALL#
Les Hash permettent de stocker un objet structuré sans avoir à sérialiser/désérialiser un JSON entier à chaque accès.
HSET user:42 nom "Alice" email "alice@example.com" role "admin" points 1500
HGET user:42 nom -- "Alice"
HGETALL user:42 -- tous les champs
HINCRBY user:42 points 50 -- incrémenter un champ numérique
HDEL user:42 role -- supprimer un champ
HEXISTS user:42 email -- 1 (vrai)
Remarque 82
Stocker un objet dans un Hash plutôt que dans un String JSON a deux avantages : on peut lire ou modifier un seul champ sans toucher au reste (réduisant la bande passante), et Redis peut compresser les petits Hash en mémoire grâce à un encodage interne optimisé (ziplist). En pratique, pour des objets comportant moins d’une centaine de champs, les Hash sont plus économiques en mémoire que le String JSON.
Set : SADD, SMEMBERS, SINTER#
Les Set sont des ensembles sans doublon. Redis expose les opérations ensemblistes en O(N).
SADD tags:article:1 "python" "sql" "database"
SADD tags:article:2 "python" "nosql" "redis"
SMEMBERS tags:article:1 -- {"python", "sql", "database"}
SINTER tags:article:1 tags:article:2 -- intersection : {"python"}
SUNION tags:article:1 tags:article:2 -- union
SDIFF tags:article:1 tags:article:2 -- différence
SISMEMBER tags:article:1 "python" -- 1
Sorted Set : ZADD, ZRANGE, ZRANK#
Les Sorted Sets associent un score flottant à chaque membre. Redis maintient l’ordre automatiquement.
ZADD leaderboard 9800 "Alice"
ZADD leaderboard 9200 "Bob"
ZADD leaderboard 9950 "Clara"
ZRANGE leaderboard 0 -1 WITHSCORES REV -- classement décroissant
ZRANK leaderboard "Bob" -- rang de Bob (0-based)
ZINCRBY leaderboard 100 "Bob" -- Bob gagne 100 points
ZRANGEBYSCORE leaderboard 9000 10000 -- membres entre 9000 et 10000
Définition 123
Un Sorted Set Redis est implémenté en interne par deux structures complémentaires : une table de hachage (accès O(1) par membre) et un skip list (liste chaînée probabiliste à plusieurs niveaux permettant les opérations de rang en O(log N)). Cette dualité explique pourquoi les opérations par membre sont en O(1) alors que les opérations par plage de score sont en O(log N + K) où K est le nombre d’éléments retournés.
TTL et expiration#
Redis gère nativement l’expiration des clés, ce qui évite d’implémenter une logique de nettoyage applicative.
SET session:abc123 '{"user_id":42}' EX 3600 -- expire dans 3600 secondes
EXPIRE session:abc123 1800 -- modifier le TTL
TTL session:abc123 -- secondes restantes (-1 = jamais, -2 = inexistante)
PERSIST session:abc123 -- supprimer le TTL (rendre permanente)
PTTL session:abc123 -- TTL en millisecondes
Définition 124
Le TTL (Time To Live) est le nombre de secondes avant qu’une clé soit automatiquement supprimée par Redis. Redis utilise deux stratégies complémentaires : la suppression lazy (la clé est vérifiée lors de son prochain accès) et la suppression active (un processus en arrière-plan sample aléatoirement des clés expirées à intervalle régulier). Ces deux mécanismes garantissent que la mémoire est récupérée sans surcharge significative.
Exemple 44
Gestion de sessions HTTP avec Redis :
À la connexion, on crée une clé session:{token} de type Hash contenant l’identifiant utilisateur, le rôle et le timestamp. On lui donne un TTL de 30 minutes avec EXPIRE. À chaque requête authentifiée, on appelle HGETALL session:{token} (< 0,1 ms) et on réinitialise le TTL avec EXPIRE. Si la session expire sans activité, Redis la supprime automatiquement — pas de cron de nettoyage à écrire.
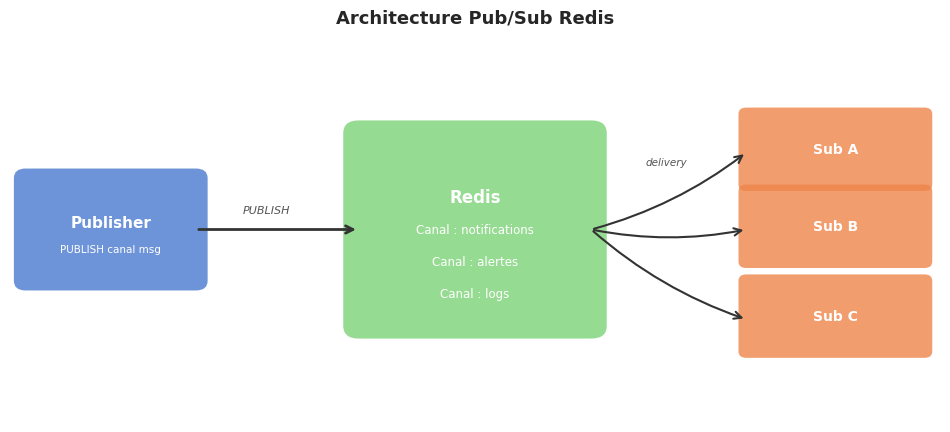
Pub/Sub : SUBSCRIBE, PUBLISH#
Redis intègre un mécanisme de messagerie publish/subscribe permettant à des processus de communiquer de manière découplée.
-- Terminal 1 (subscriber)
SUBSCRIBE notifications
-- Terminal 2 (publisher)
PUBLISH notifications "Nouveau commentaire sur votre article"
PUBLISH notifications "Votre paiement a été accepté"
Définition 125
Dans le modèle pub/sub, les publishers envoient des messages sur des canaux sans connaître les destinataires. Les subscribers s’abonnent aux canaux qui les intéressent et reçoivent tous les messages publiés. Redis supporte les abonnements par pattern avec PSUBSCRIBE notif:* (wildcard). Ce modèle est fire-and-forget : si un subscriber n’est pas connecté au moment de la publication, le message est perdu. Pour la persistance, on utilise les Streams.
Remarque 83
Les limitations du pub/sub Redis : (1) pas de persistance — les messages publiés quand aucun subscriber n’écoute sont perdus ; (2) pas de groupes de consommateurs — tous les subscribers d’un canal reçoivent tous les messages (pas de partage de charge) ; (3) pas d’acquittement. Pour des cas d’usage plus robustes, Redis Streams (XADD, XREAD, XGROUP) offrent la persistance et les groupes de consommateurs.
Persistance : RDB et AOF#
Bien que Redis soit une base en mémoire, il offre deux mécanismes de persistance sur disque pour survivre aux redémarrages.
Définition 126
RDB (Redis Database) est le mécanisme de snapshot. Redis prend périodiquement une photographie de l’état en mémoire et l’écrit dans un fichier binaire compressé dump.rdb. La configuration typique déclenche un snapshot si au moins 1 modification a eu lieu en 900 secondes, ou 10 modifications en 300 secondes. La restauration est rapide, mais les données entre le dernier snapshot et le crash sont perdues.
Définition 127
AOF (Append-Only File) est le mécanisme de journal. Chaque commande d’écriture est ajoutée au fichier appendonly.aof. Au redémarrage, Redis rejoue le journal. La politique de synchronisation est configurable : always (sync à chaque écriture, durabilité maximale, moins rapide), everysec (sync par seconde, compromis recommandé), ou no (laissé au système d’exploitation). L’AOF grossit au fil du temps ; Redis le compacte automatiquement via la réécriture AOF (BGREWRITEAOF).
Remarque 84
En production, on peut activer les deux modes simultanément : RDB pour les backups rapides et la restauration rapide, AOF pour la durabilité fine. Redis 7 introduit le format RDB+AOF qui combine les avantages des deux. Sans persistance (--save ""), Redis est un cache pur : si le processus redémarre, tout est perdu — ce qui est acceptable si la base de données principale peut repeupler le cache.
Cellule exécutable : simulation des structures Redis#
import bisect
import time
from collections import defaultdict
class RedisSimulator:
"""Simulation Python des principales structures de données Redis."""
def __init__(self):
self._store = {} # clé -> valeur (str, list, dict, set)
self._types = {} # clé -> type
self._ttls = {} # clé -> timestamp d'expiration
def _check_expired(self, key):
if key in self._ttls and time.time() > self._ttls[key]:
del self._store[key]
del self._types[key]
del self._ttls[key]
return True
return False
# --- String ---
def set(self, key, value, ex=None):
self._store[key] = str(value)
self._types[key] = 'string'
if ex:
self._ttls[key] = time.time() + ex
elif key in self._ttls:
del self._ttls[key]
def get(self, key):
if self._check_expired(key):
return None
return self._store.get(key)
def incr(self, key):
val = int(self._store.get(key, 0)) + 1
self.set(key, val)
return val
# --- Hash ---
def hset(self, key, mapping):
if key not in self._store or self._types[key] != 'hash':
self._store[key] = {}
self._types[key] = 'hash'
self._store[key].update(mapping)
def hget(self, key, field):
if self._check_expired(key):
return None
return self._store.get(key, {}).get(field)
def hgetall(self, key):
if self._check_expired(key):
return {}
return dict(self._store.get(key, {}))
def hincrby(self, key, field, amount):
if key not in self._store:
self._store[key] = {}
self._types[key] = 'hash'
self._store[key][field] = int(self._store[key].get(field, 0)) + amount
# --- List ---
def lpush(self, key, *values):
if key not in self._store or self._types[key] != 'list':
self._store[key] = []
self._types[key] = 'list'
for v in values:
self._store[key].insert(0, v)
return len(self._store[key])
def rpush(self, key, *values):
if key not in self._store or self._types[key] != 'list':
self._store[key] = []
self._types[key] = 'list'
self._store[key].extend(values)
return len(self._store[key])
def lrange(self, key, start, stop):
lst = self._store.get(key, [])
if stop == -1:
return list(lst[start:])
return list(lst[start:stop+1])
def lpop(self, key):
lst = self._store.get(key, [])
if lst:
return lst.pop(0)
return None
# --- Set ---
def sadd(self, key, *members):
if key not in self._store or self._types[key] != 'set':
self._store[key] = set()
self._types[key] = 'set'
before = len(self._store[key])
self._store[key].update(members)
return len(self._store[key]) - before
def smembers(self, key):
return set(self._store.get(key, set()))
def sinter(self, *keys):
sets = [self._store.get(k, set()) for k in keys]
return set.intersection(*sets) if sets else set()
# --- Sorted Set ---
def zadd(self, key, mapping):
if key not in self._store or self._types[key] != 'zset':
self._store[key] = {}
self._types[key] = 'zset'
self._store[key].update(mapping)
def zrange(self, key, start=0, stop=-1, reverse=False):
zset = self._store.get(key, {})
ranked = sorted(zset.items(), key=lambda x: x[1], reverse=reverse)
if stop == -1:
return ranked[start:]
return ranked[start:stop+1]
def zincrby(self, key, amount, member):
if key not in self._store:
self._store[key] = {}
self._types[key] = 'zset'
self._store[key][member] = self._store[key].get(member, 0) + amount
return self._store[key][member]
# --- TTL ---
def expire(self, key, seconds):
if key in self._store:
self._ttls[key] = time.time() + seconds
return 1
return 0
def ttl(self, key):
if key not in self._store:
return -2
if key not in self._ttls:
return -1
remaining = self._ttls[key] - time.time()
return max(0, int(remaining))
# --- Démonstration ---
r = RedisSimulator()
# String + compteur
r.set("article:101:views", 0)
for _ in range(15):
r.incr("article:101:views")
print(f"Vues article 101 : {r.get('article:101:views')}")
# Hash (profil utilisateur)
r.hset("user:42", {"nom": "Alice", "email": "alice@example.com", "points": "1500"})
r.hincrby("user:42", "points", 250)
print(f"Profil user:42 : {r.hgetall('user:42')}")
# List (file de notifications)
r.rpush("notif:42", "Message de Bob", "Commande expédiée", "Nouveau follower")
print(f"Notifications : {r.lrange('notif:42', 0, -1)}")
print(f"Pop : {r.lpop('notif:42')}")
# Set (tags)
r.sadd("tags:article:1", "python", "sql", "database")
r.sadd("tags:article:2", "python", "nosql", "redis")
print(f"Intersection tags : {r.sinter('tags:article:1', 'tags:article:2')}")
# Sorted Set (leaderboard)
r.zadd("leaderboard", {"Alice": 9800, "Bob": 9200, "Clara": 9950, "David": 8700})
r.zincrby("leaderboard", 150, "Bob")
print("\nClassement (top 3) :")
for i, (name, score) in enumerate(r.zrange("leaderboard", reverse=True)[:3], 1):
print(f" {i}. {name} — {score:.0f} pts")
# TTL
r.set("session:xyz", "user=42", ex=1800)
print(f"\nTTL session : {r.ttl('session:xyz')} secondes restantes")
Vues article 101 : 15
Profil user:42 : {'nom': 'Alice', 'email': 'alice@example.com', 'points': 1750}
Notifications : ['Message de Bob', 'Commande expédiée', 'Nouveau follower']
Pop : Message de Bob
Intersection tags : {'python'}
Classement (top 3) :
1. Clara — 9950 pts
2. Alice — 9800 pts
3. Bob — 9350 pts
TTL session : 1799 secondes restantes
Visualisation des structures#
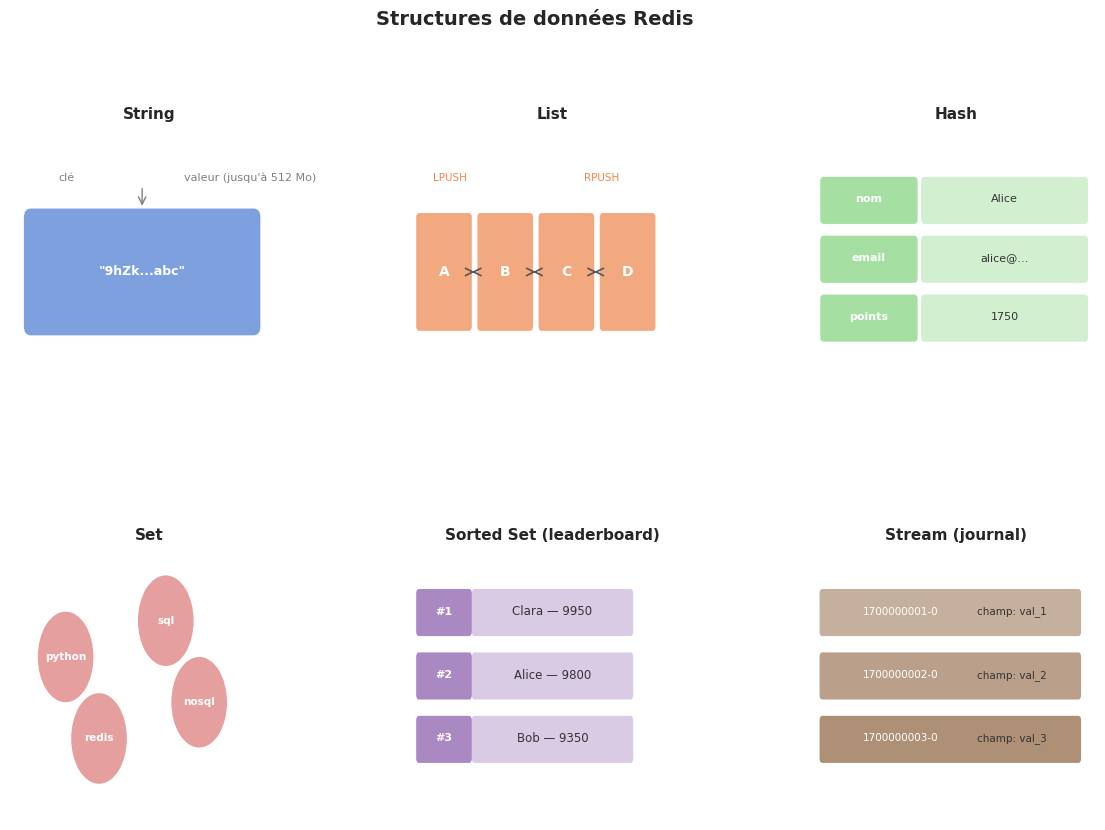
Diagramme Pub/Sub#
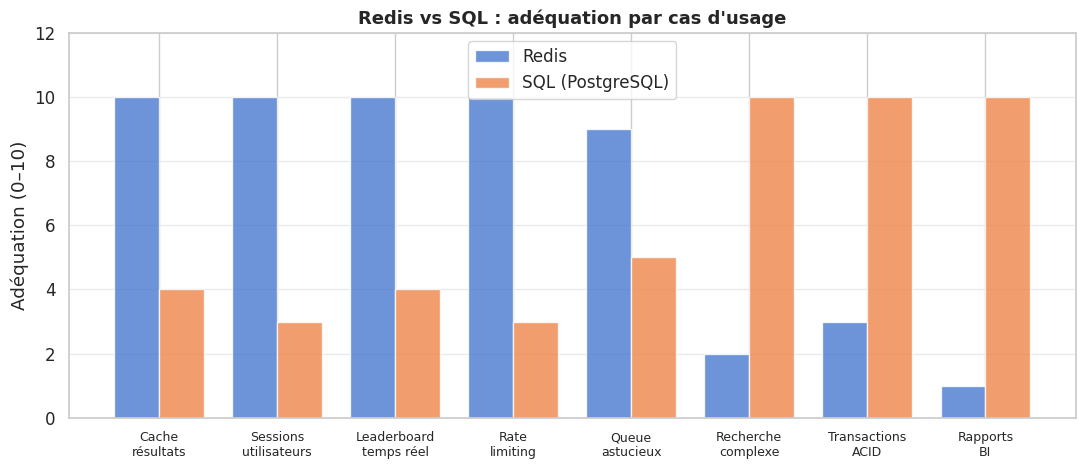
Cas d’usage : Redis vs SQL#
Exemple 45
Cache applicatif : lors d’une requête sur /api/products/bestsellers, l’application cherche d’abord la clé cache:bestsellers dans Redis (TTL 5 minutes). Si elle existe, on retourne directement la valeur JSON (0,1 ms). Sinon, on exécute la requête SQL coûteuse, on stocke le résultat dans Redis, et on le retourne. Ce pattern — appelé cache-aside — réduit la charge SQL de 80 à 95 % pour les endpoints populaires.
Exemple 46
Leaderboard en temps réel : un Sorted Set Redis stocke les scores de tous les joueurs d’un jeu. Chaque partie incrémente le score avec ZINCRBY. L’affichage du top-100 se fait avec ZRANGE leaderboard 0 99 WITHSCORES REV en O(log N + 100). En SQL, une requête SELECT ... ORDER BY score DESC LIMIT 100 sur une table de millions de joueurs nécessite un index et reste bien plus lente sous forte concurrence.
Exemple 47
Rate limiting : pour limiter une API à 100 requêtes par minute par utilisateur, on utilise un compteur avec TTL. Lors de chaque requête, INCR rate:user:42 incrémente le compteur. Si la valeur retournée vaut 1, on appelle EXPIRE rate:user:42 60. Si la valeur dépasse 100, on rejette la requête avec HTTP 429. L’implémentation tient en 3 lignes de code Redis et est atomique, sans risque de race condition.
Utilisation avec redis-py (blocs illustratifs)#
Les exemples suivants nécessitent un serveur Redis actif (redis-server) et la bibliothèque redis-py (pip install redis).
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
# String
r.set("compteur", 0)
r.incr("compteur")
# Hash
r.hset("user:42", mapping={"nom": "Alice", "points": 1500})
print(r.hgetall("user:42")) # {'nom': 'Alice', 'points': '1500'}
# TTL
r.set("session:abc", "user=42", ex=3600)
print(r.ttl("session:abc")) # ~3600
# Sorted Set
r.zadd("leaderboard", {"Alice": 9800, "Bob": 9200})
print(r.zrange("leaderboard", 0, -1, withscores=True, desc=True))
# Pub/Sub avec redis-py (processus publisher)
import redis, json
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
message = json.dumps({"type": "commande", "id": 1024, "statut": "expédiée"})
abonnés = r.publish("notifications", message)
print(f"Message envoyé à {abonnés} subscriber(s)")
# Pub/Sub avec redis-py (processus subscriber)
import redis, json
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
pubsub = r.pubsub()
pubsub.subscribe("notifications")
for message in pubsub.listen():
if message["type"] == "message":
data = json.loads(message["data"])
print(f"Reçu : {data}")
Remarque 85
Pipelines redis-py : pour envoyer plusieurs commandes en un seul aller-retour réseau, on utilise r.pipeline(). Cela réduit drastiquement la latence cumulée quand on doit exécuter des dizaines de commandes en séquence. Les pipelines ne sont pas des transactions (pour cela, utiliser r.pipeline(transaction=True) qui enveloppe dans MULTI/EXEC).
Résumé#
Redis est un outil de niche mais irremplaçable dans l’architecture moderne des applications : là où SQL excelle pour stocker, relier et interroger des données structurées durables, Redis excelle pour les données chaudes, temporaires, à faible latence.
Remarque 86
Les points clés à retenir :
Redis maintient tout en RAM — latences sub-milliseconde, throughput millions d’ops/sec.
Chaque type de données (String, List, Hash, Set, Sorted Set, Stream) a des opérations dédiées adaptées à des patterns spécifiques.
Le TTL natif simplifie la gestion du cache et des sessions sans cron de nettoyage.
Pub/Sub est fire-and-forget ; pour la durabilité, utiliser les Streams.
RDB (snapshots) et AOF (journal) offrent deux niveaux de persistance combinables.
Redis complète SQL — il ne le remplace pas. La règle d’or : si votre requête SQL est un goulot d’étranglement et que la donnée est reproductible, mettez-la dans Redis.