Conception avancée : partitionnement, réplication et CAP#
À mesure qu’une base de données grandit en volume et en trafic, les approches standards atteignent leurs limites. Une table de 10 milliards de lignes ne se gère pas comme une table de 10 000 lignes. Un service consulté par un million d’utilisateurs simultanés ne peut pas reposer sur un seul serveur. Ce chapitre couvre les techniques de partitionnement pour gérer le volume, de réplication pour la disponibilité, et le théorème CAP pour comprendre les compromis fondamentaux des systèmes distribués.
Partitionnement#
Pourquoi partitionner ?#
Le partitionnement consiste à diviser une grande table en sous-ensembles physiques appelés partitions, tout en conservant une vue logique unifiée. Les bénéfices sont multiples :
Performance : une requête sur janvier 2024 ne scanne que la partition correspondante
Maintenance : archiver ou supprimer une période entière devient instantané (
DROP PARTITION)Parallélisme : plusieurs partitions peuvent être lues simultanément
import sqlite3
# Simulation du concept de partitionnement par plage de dates
conn = sqlite3.connect(":memory:")
# Schéma : une table de ventes avec des partitions simulées
conn.executescript("""
CREATE TABLE ventes_2022 (
id INTEGER PRIMARY KEY,
date_vente TEXT,
montant REAL,
produit TEXT
);
CREATE TABLE ventes_2023 (
id INTEGER PRIMARY KEY,
date_vente TEXT,
montant REAL,
produit TEXT
);
CREATE TABLE ventes_2024 (
id INTEGER PRIMARY KEY,
date_vente TEXT,
montant REAL,
produit TEXT
);
""")
# Insertion de données
import random
from datetime import date, timedelta
random.seed(42)
produits = ["Laptop", "Souris", "Clavier", "Écran", "Casque"]
for annee, table in [(2022, "ventes_2022"), (2023, "ventes_2023"), (2024, "ventes_2024")]:
debut = date(annee, 1, 1)
for i in range(1, 201):
j = random.randint(0, 364)
d = debut + timedelta(days=j)
conn.execute(
f"INSERT INTO {table} VALUES (?, ?, ?, ?)",
(i, d.isoformat(), round(random.uniform(20, 2000), 2), random.choice(produits))
)
conn.commit()
# Vue unifiée via UNION ALL (équivalent d'une table partitionnée)
conn.execute("""
CREATE VIEW ventes AS
SELECT *, '2022' AS annee FROM ventes_2022
UNION ALL
SELECT *, '2023' AS annee FROM ventes_2023
UNION ALL
SELECT *, '2024' AS annee FROM ventes_2024
""")
# Requête sur une seule partition (scan réduit)
df = pd.read_sql_query("""
SELECT annee, COUNT(*) AS nb_ventes, ROUND(SUM(montant), 2) AS total
FROM ventes
GROUP BY annee
ORDER BY annee
""", conn)
print(df.to_string(index=False))
annee nb_ventes total
2022 200 188766.69
2023 200 211351.51
2024 200 201347.84
Stratégies de partitionnement#
Partitionnement par plage (RANGE) — le plus courant pour les données temporelles :
-- PostgreSQL
CREATE TABLE ventes (
id SERIAL,
date_vente DATE NOT NULL,
montant NUMERIC(10,2),
produit TEXT
) PARTITION BY RANGE (date_vente);
CREATE TABLE ventes_2023 PARTITION OF ventes
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
CREATE TABLE ventes_2024 PARTITION OF ventes
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');
Partitionnement par liste (LIST) — par valeur discrète (région, statut) :
CREATE TABLE commandes (
id SERIAL,
region TEXT,
total NUMERIC
) PARTITION BY LIST (region);
CREATE TABLE commandes_europe PARTITION OF commandes
FOR VALUES IN ('FR', 'DE', 'ES', 'IT');
CREATE TABLE commandes_amerique PARTITION OF commandes
FOR VALUES IN ('US', 'CA', 'MX');
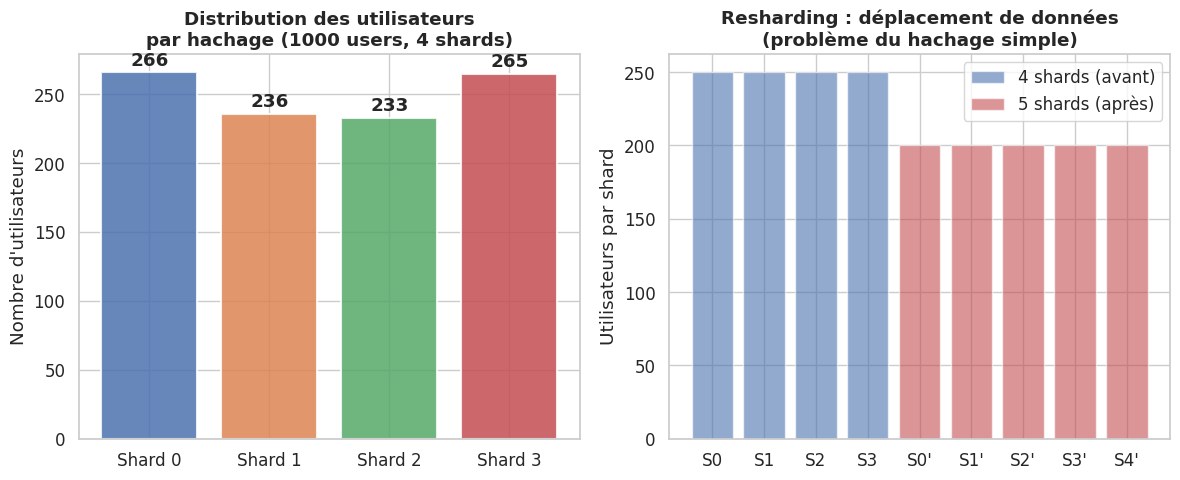
Partitionnement par hachage (HASH) — distribution uniforme sans logique métier :
CREATE TABLE sessions (
id UUID,
user_id INT,
données JSONB
) PARTITION BY HASH (user_id);
CREATE TABLE sessions_0 PARTITION OF sessions
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
CREATE TABLE sessions_1 PARTITION OF sessions
FOR VALUES WITH (MODULUS 4, REMAINDER 1);
-- etc.

Partition pruning#
L’élimination de partitions (partition pruning) est le mécanisme par lequel le planificateur de requêtes ignore automatiquement les partitions non pertinentes :
-- Cette requête ne scanne QUE la partition ventes_2024
SELECT SUM(montant)
FROM ventes
WHERE date_vente BETWEEN '2024-01-01' AND '2024-12-31';
-- EXPLAIN révèle le pruning
EXPLAIN SELECT SUM(montant) FROM ventes
WHERE date_vente >= '2024-01-01';
-- → Seq Scan on ventes_2024 (les autres partitions ignorées)
Réplication#
Principe et topologies#
La réplication consiste à maintenir des copies identiques d’une base sur plusieurs serveurs. Elle sert deux objectifs distincts :
Haute disponibilité : si le serveur principal tombe, un réplica prend le relais
Scalabilité en lecture : les requêtes
SELECTsont distribuées sur plusieurs réplicas
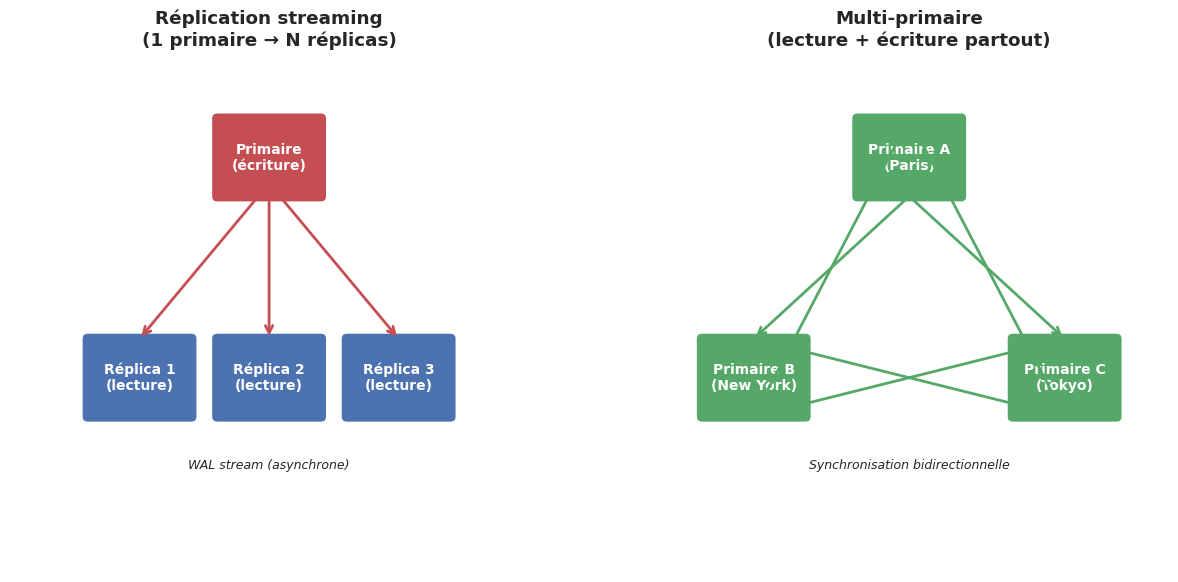
Réplication synchrone vs asynchrone#
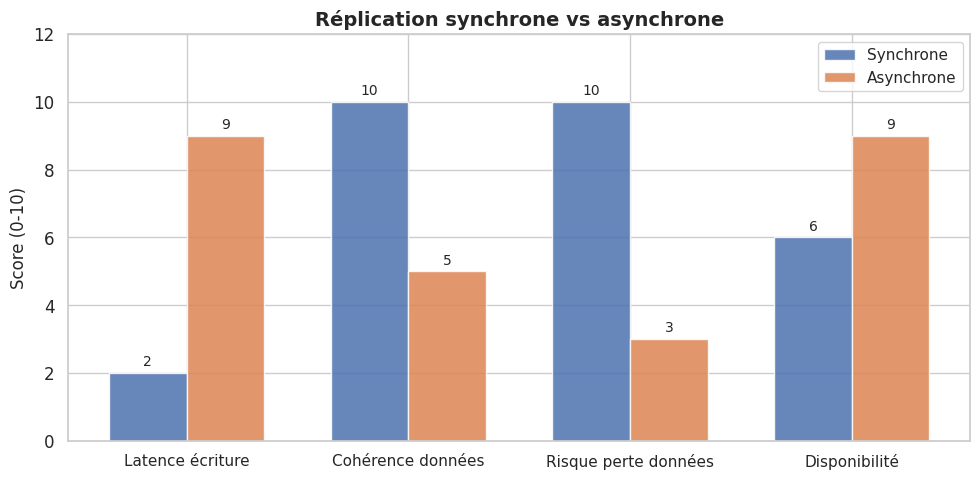
Configuration PostgreSQL pour la réplication :
-- Sur le primaire (postgresql.conf)
wal_level = replica
max_wal_senders = 10
synchronous_commit = on -- ou 'off' pour asynchrone
-- Réplication synchrone pour un réplica critique
synchronous_standby_names = 'réplica_paris'
-- Sur le réplica (recovery.conf / postgresql.auto.conf)
primary_conninfo = 'host=primaire port=5432 user=replicateur'
Failover automatique#
Outils de haute disponibilité PostgreSQL
Patroni : gestionnaire de cluster HA, s’appuie sur etcd/Consul pour l’élection du leader
pgBouncer : pooler de connexions, transparent pour l’application lors d’un failover
Repmgr : gestion de la réplication et failover automatique
pg_auto_failover : solution intégrée Citus/Microsoft
En production, on déploie typiquement : 1 primaire + 2 réplicas + 1 pooler + 1 service de découverte.
Sharding#
Le sharding va plus loin que la réplication : il distribue les données elles-mêmes sur plusieurs serveurs independants (shards). Chaque shard est une base à part entière, responsable d’un sous-ensemble des données.
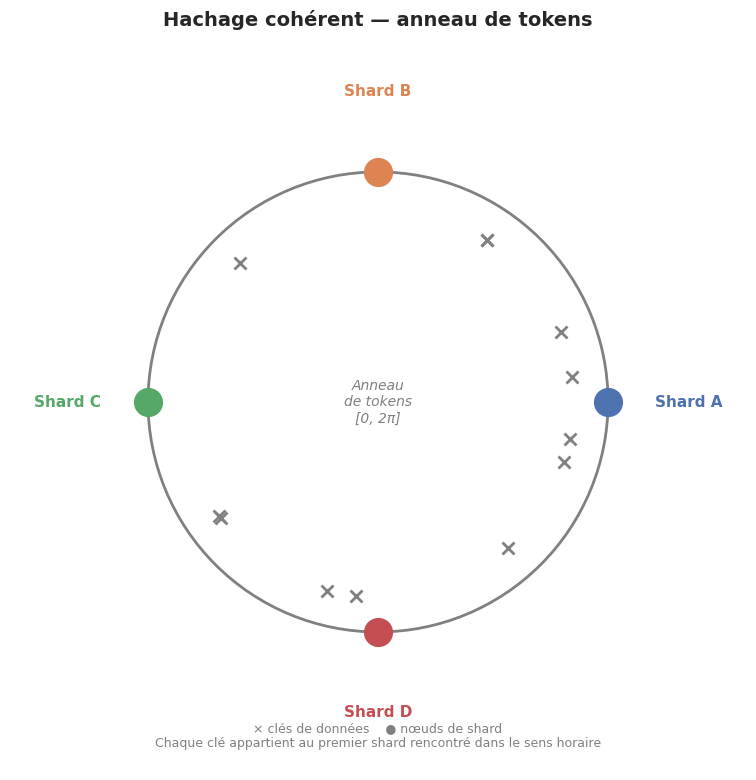
Hachage cohérent (consistent hashing)#
Le hachage cohérent minimise les déplacements de données lors d’un resharding :
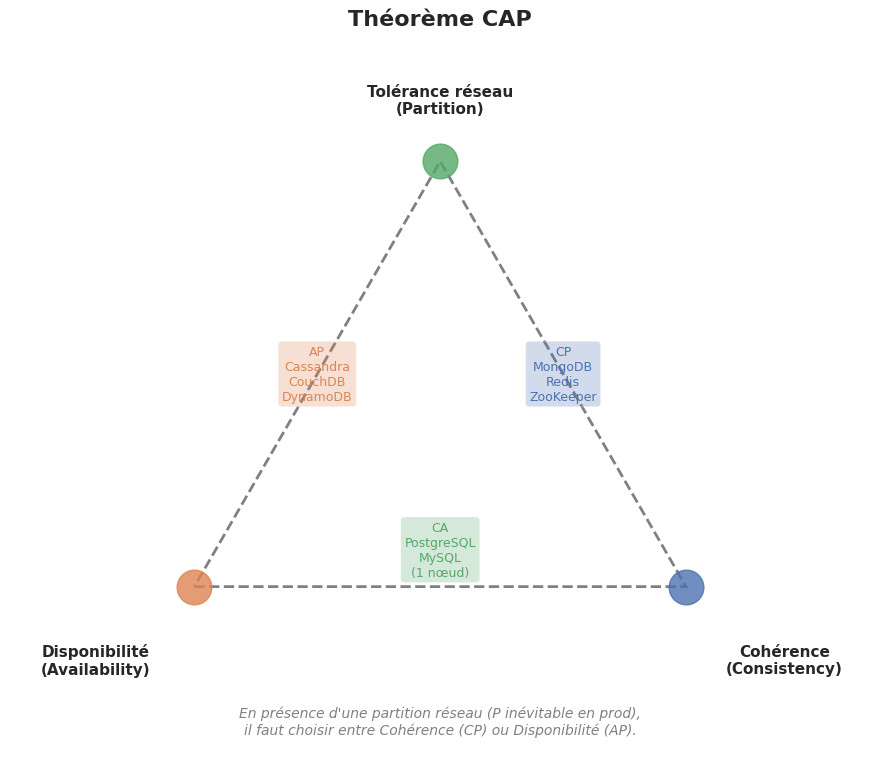
Le théorème CAP#
Énoncé#
Formulé par Eric Brewer (2000) et démontré par Gilbert & Lynch (2002), le théorème CAP stipule qu’un système distribué ne peut garantir simultanément que deux des trois propriétés suivantes :
Cohérence (Consistency) : tous les nœuds voient les mêmes données au même instant
Disponibilité (Availability) : chaque requête reçoit une réponse (sans garantie qu’elle soit à jour)
Tolérance au partitionnement (Partition tolerance) : le système continue de fonctionner malgré des pannes réseau
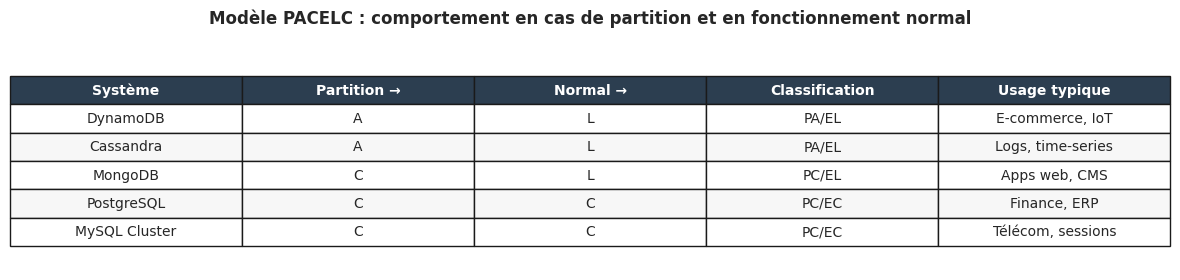
PACELC : au-delà de CAP#
CAP raisonne en présence d’une panne. Le modèle PACELC étend ce cadre au cas normal :
En cas de Partition (P) → choisir entre Availability (A) et Consistency (C)
Else (E) (fonctionnement normal) → choisir entre Latency (L) et Consistency (C)
Base de données distribuée : exemple avec Citus#
Citus est une extension PostgreSQL qui transforme une instance PostgreSQL standard en base distribuée. Elle est idéale pour passer à l’échelle sans changer d’interface SQL.
-- Installation de l'extension Citus
CREATE EXTENSION citus;
-- Déclarer les nœuds workers
SELECT citus_add_node('worker1', 5432);
SELECT citus_add_node('worker2', 5432);
SELECT citus_add_node('worker3', 5432);
-- Distribuer une table existante par user_id
-- (les données sont automatiquement réparties sur les workers)
SELECT create_distributed_table('commandes', 'user_id');
-- Co-localiser les tables liées (même clé de distribution)
SELECT create_distributed_table('paiements', 'user_id');
-- Les jointures sur user_id s'exécutent localement sur chaque shard
SELECT u.nom, COUNT(c.id) AS nb_commandes
FROM utilisateurs u
JOIN commandes c ON u.id = c.user_id
GROUP BY u.nom
ORDER BY nb_commandes DESC
LIMIT 10;
-- → Citus exécute cette requête en parallèle sur tous les shards
Règles de conception pour Citus
Choisir la bonne clé de distribution : toutes les tables liées doivent partager la même clé (ex:
tenant_id,user_id)Éviter les jointures cross-shard : elles nécessitent des transferts réseau coûteux
Tables de référence : les petites tables (pays, catégories) peuvent être répliquées sur tous les shards avec
create_reference_table()Surveiller le déséquilibre : certaines clés populaires créent des « hot shards » — utiliser des clés à haute cardinalité
Récapitulatif : choisir la bonne architecture#
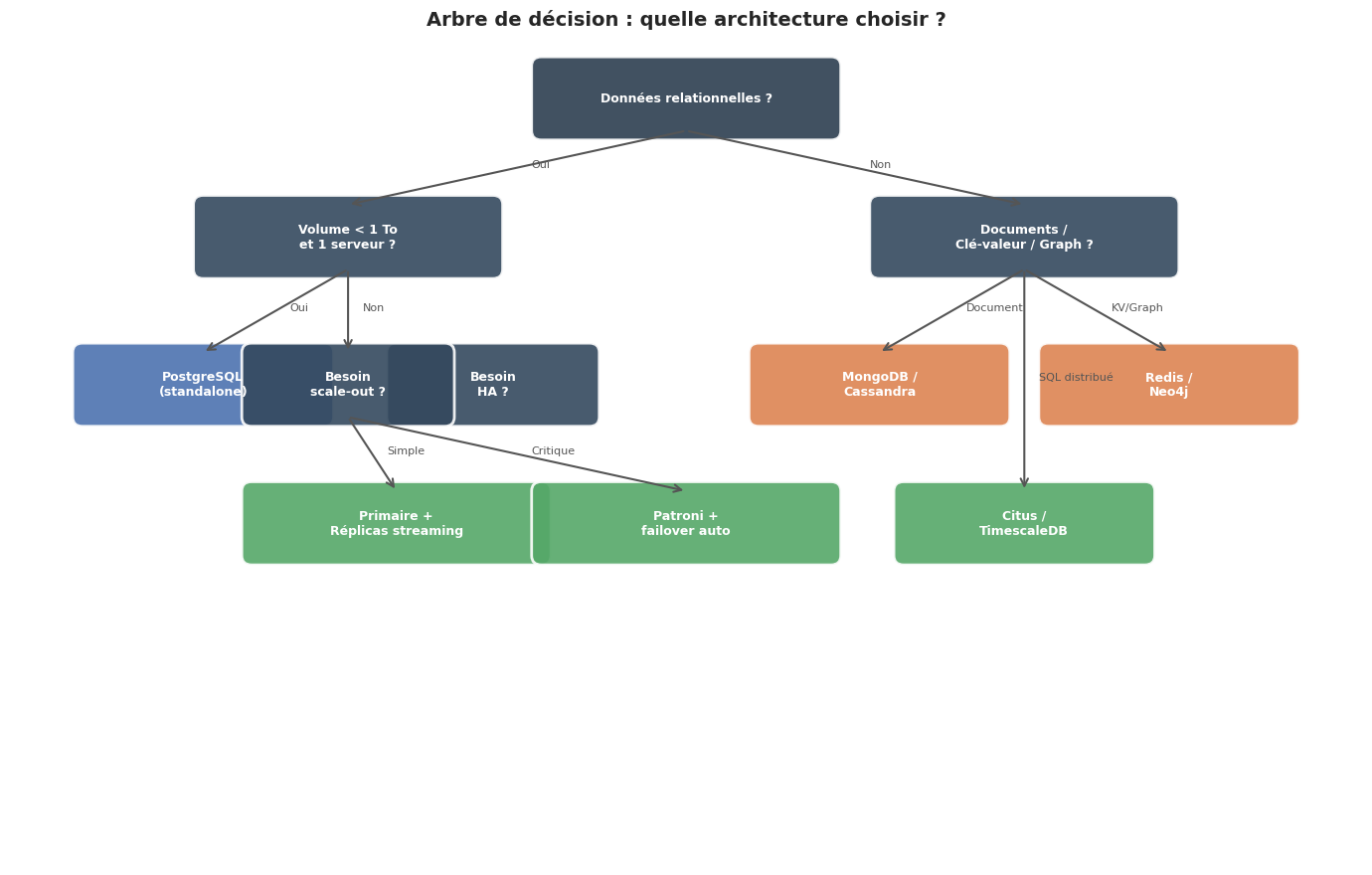
Résumé#
Technique |
Problème résolu |
Coût |
|---|---|---|
Partitionnement |
Volume (tables géantes) |
Complexité de conception |
Réplication |
Disponibilité + lecture scale-out |
Lag, cohérence éventuelle |
Sharding |
Écriture scale-out |
Complexité applicative |
CAP/PACELC |
Comprendre les compromis |
(framework de raisonnement) |
Citus |
Scale-out PostgreSQL transparent |
Infrastructure distribuée |
La règle d’or : n’ajouter de complexité que lorsqu’elle est justifiée par des mesures. Un PostgreSQL bien configuré sur un bon serveur gère des dizaines de milliers de requêtes par seconde. La distribution est une solution à des problèmes à grande échelle, pas une architecture de départ.