NoSQL : MongoDB#
Note : Les exemples MongoDB (JavaScript et pymongo) de ce chapitre sont des blocs illustratifs non exécutables — MongoDB nécessite un serveur. Les cellules Python exécutables utilisent des listes de dictionnaires pour simuler le comportement d’une collection MongoDB.
Pourquoi NoSQL ?#
Le modèle relationnel est remarquablement adapté à de nombreux problèmes : intégrité des données, requêtes complexes ad hoc, cohérence transactionnelle. Cependant, certains contextes l’ont mis en difficulté avec la montée en puissance du web :
Remarque 75
Les limitations du modèle relationnel dans certains contextes :
Schéma rigide : modifier le schéma d’une table de plusieurs milliards de lignes peut prendre des heures et bloquer les écritures.
Scalabilité horizontale difficile : sharding d’une base relationnelle est complexe ; la cohérence ACID distribuée (distributed transactions) est coûteuse.
Objets hiérarchiques : stocker un objet JSON imbriqué (commande avec ses lignes et les détails de livraison) en relationnel nécessite plusieurs tables et jointures.
Schéma hétérogène : dans un catalogue de produits, chaque catégorie a des attributs différents (une chaussure a une pointure, un livre a un ISBN) — difficile à modéliser en relationnel sans tables auxiliaires.
Les systèmes NoSQL ont émergé pour répondre à ces besoins spécifiques.
Taxonomie NoSQL#
Définition 117
Les systèmes NoSQL se regroupent en quatre familles principales :
Famille |
Modèle |
Exemples |
Usage typique |
|---|---|---|---|
Document |
Documents JSON/BSON semi-structurés |
MongoDB, CouchDB, Firestore |
Catalogues, CMS, profils utilisateurs |
Clé-valeur |
Paires clé/valeur opaques |
Redis, DynamoDB, Riak |
Cache, sessions, files de messages |
Colonne large |
Tables avec colonnes dynamiques par ligne |
Cassandra, HBase |
Logs, séries temporelles, IoT |
Graphe |
Nœuds et arêtes typés |
Neo4j, Amazon Neptune |
Réseaux sociaux, recommandations, fraude |
MongoDB : documents, BSON et collections#
Définition 118
Dans MongoDB, les données sont stockées sous forme de documents au format BSON (Binary JSON), une extension binaire de JSON. BSON ajoute des types natifs absents de JSON : Date, ObjectId, BinData, Int32, Int64, Decimal128.
Un document MongoDB est l’unité de base — équivalent d’une ligne en relationnel. Une collection regroupe des documents — équivalent d’une table. La différence fondamentale : les documents d’une même collection peuvent avoir des structures différentes (schéma flexible).
Remarque 76
Chaque document possède un champ _id unique dans la collection. Par défaut, MongoDB génère un ObjectId : un identifiant de 12 octets encodant un timestamp, un identifiant de machine, un PID et un compteur. Cela garantit l’unicité globale sans coordination centrale — utile dans les clusters distribués.
Exemple de document MongoDB (bloc illustratif) :
// Collection "produits"
{
"_id": ObjectId("64f1a2b3c4d5e6f7a8b9c0d1"),
"nom": "Laptop Pro 15",
"marque": "Lenko",
"prix": 1299.99,
"stock": 42,
"tags": ["laptop", "pro", "15pouces"],
"specs": {
"ram_go": 16,
"stockage": "512 Go SSD",
"processeur": "Core i7-1260P"
},
"avis": [
{"utilisateur": "alice", "note": 5, "commentaire": "Excellent"},
{"utilisateur": "bob", "note": 4, "commentaire": "Très bien"}
],
"date_ajout": ISODate("2024-09-01T00:00:00Z")
}
CRUD MongoDB#
Définition 119
Les opérations CRUD dans MongoDB :
Opération |
Méthode MongoDB |
SQL équivalent |
|---|---|---|
Créer |
|
|
Lire |
|
|
Modifier |
|
|
Supprimer |
|
|
Exemples illustratifs (shell MongoDB — requiert un serveur MongoDB) :
// Insertion
db.produits.insertOne({
nom: "Souris sans fil",
prix: 49.99,
stock: 150,
tags: ["peripherique", "sans_fil"]
});
// Insertion multiple
db.produits.insertMany([
{ nom: "Clavier mécanique", prix: 89.99, stock: 80 },
{ nom: "Moniteur 27\"", prix: 399.0, stock: 30 }
]);
// Lecture de tous les documents
db.produits.find({});
// Lecture avec filtre
db.produits.find({ prix: { $lt: 100 } });
// Mise à jour d'un document
db.produits.updateOne(
{ nom: "Souris sans fil" },
{ $set: { prix: 44.99 }, $inc: { stock: -1 } }
);
// Suppression
db.produits.deleteOne({ nom: "Clavier mécanique" });
Opérateurs de requête#
Remarque 77
MongoDB dispose d’un riche ensemble d’opérateurs de requête :
Opérateur |
Description |
Exemple |
|---|---|---|
|
Égalité |
|
|
Différent |
|
|
Supérieur (ou égal) |
|
|
Inférieur (ou égal) |
|
|
Dans une liste |
|
|
Pas dans une liste |
|
|
ET logique |
|
|
OU logique |
|
|
Expression régulière |
|
|
Existence d’un champ |
|
Pipeline d’agrégation#
Définition 120
Le pipeline d’agrégation est le mécanisme de traitement analytique de MongoDB. Un pipeline est une liste de stages (étapes) : chaque stage reçoit des documents, les transforme, et passe le résultat au stage suivant.
Stage |
Description |
SQL équivalent |
|---|---|---|
|
Filtre les documents |
|
|
Regroupe et agrège |
|
|
Trie les résultats |
|
|
Sélectionne/transforme les champs |
|
|
Limite le nombre de documents |
|
|
Jointure avec une autre collection |
|
|
Décompose un tableau en documents |
|
Exemple illustratif (shell MongoDB) :
// Chiffre d'affaires par marque, pour les marques avec CA > 1000
db.produits.aggregate([
{ $match: { stock: { $gt: 0 } } },
{ $group: {
_id: "$marque",
ca: { $sum: { $multiply: ["$prix", "$stock"] } },
nb_ref: { $count: {} },
prix_moyen: { $avg: "$prix" }
}},
{ $match: { ca: { $gt: 1000 } } },
{ $sort: { ca: -1 } },
{ $project: {
marque: "$_id",
ca: { $round: ["$ca", 2] },
nb_ref: 1,
prix_moyen: { $round: ["$prix_moyen", 2] }
}}
]);
Exemple illustratif pymongo (Python — requiert un serveur MongoDB) :
from pymongo import MongoClient
client = MongoClient("mongodb://localhost:27017/")
db = client["catalogue"]
pipeline = [
{"$match": {"stock": {"$gt": 0}}},
{"$group": {
"_id": "$marque",
"ca": {"$sum": {"$multiply": ["$prix", "$stock"]}},
"nb_ref": {"$count": {}},
"prix_moyen": {"$avg": "$prix"}
}},
{"$sort": {"ca": -1}},
{"$project": {
"marque": "$_id",
"ca": {"$round": ["$ca", 2]},
"nb_ref": 1
}}
]
resultats = list(db.produits.aggregate(pipeline))
Index MongoDB#
Remarque 78
MongoDB supporte plusieurs types d’index :
Type |
Description |
Création |
|---|---|---|
Simple |
Sur un champ |
|
Composé |
Sur plusieurs champs |
|
Texte |
Recherche plein texte |
|
Géospatial |
2dsphere pour GeoJSON |
|
Unique |
Contrainte d’unicité |
|
Sparse |
N’indexe que les docs avec le champ |
|
TTL |
Expiration automatique |
|
Sans index, toute requête effectue un COLLSCAN (parcours complet de la collection). La commande explain("executionStats") permet d’analyser l’utilisation des index.
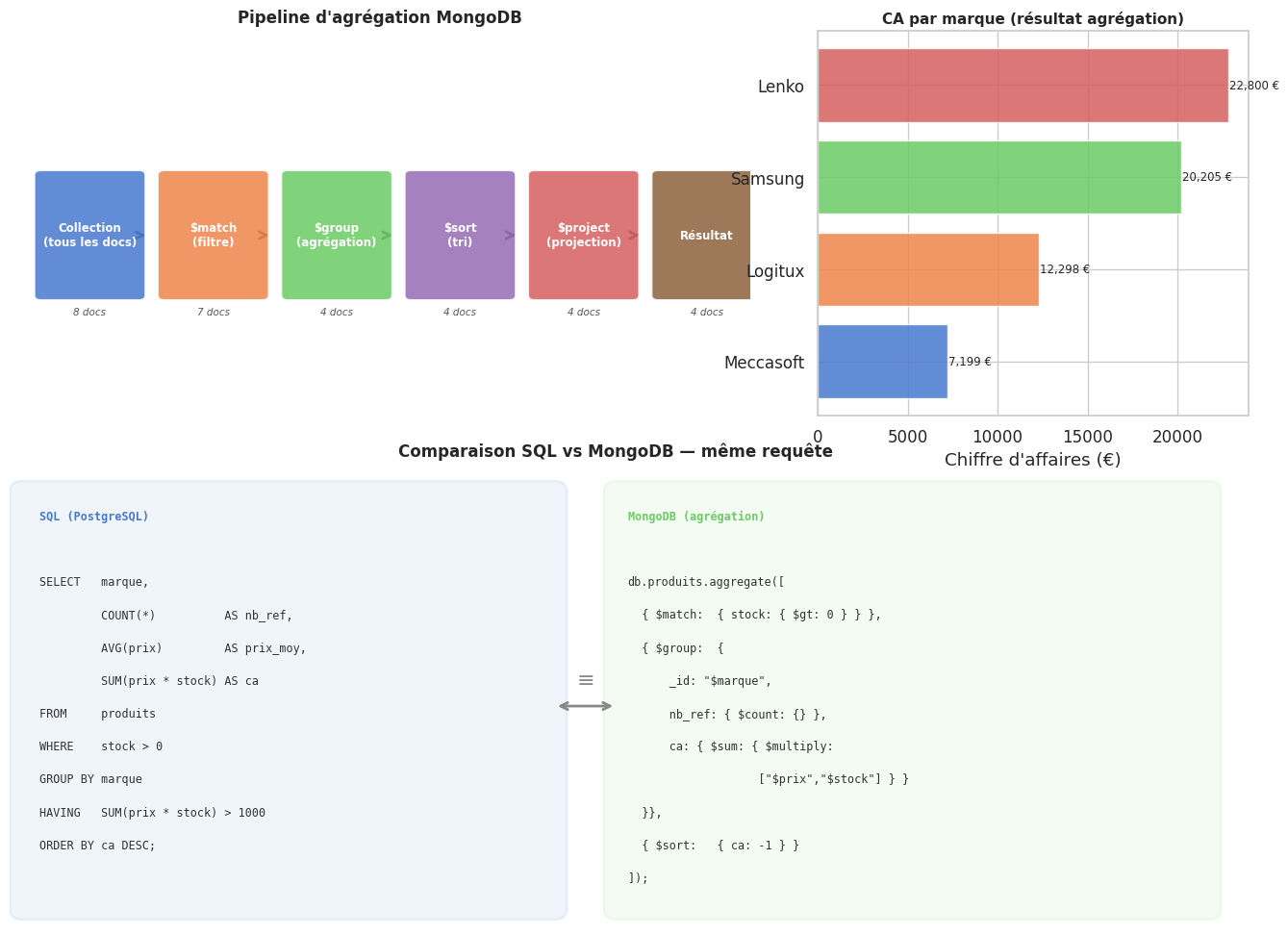
Comparaison SQL vs MongoDB#
Exemple 42
La même requête analytique exprimée en SQL et en MongoDB :
SQL (PostgreSQL) :
SELECT marque,
COUNT(*) AS nb_references,
ROUND(AVG(prix)::numeric,2) AS prix_moyen,
SUM(prix * stock) AS chiffre_affaires
FROM produits
WHERE stock > 0
GROUP BY marque
HAVING SUM(prix * stock) > 1000
ORDER BY chiffre_affaires DESC;
MongoDB (agrégation) :
db.produits.aggregate([
{ $match: { stock: { $gt: 0 } } },
{ $group: {
_id: "$marque",
nb_references: { $count: {} },
prix_moyen: { $avg: "$prix" },
chiffre_affaires: { $sum: { $multiply: ["$prix", "$stock"] } }
}},
{ $match: { chiffre_affaires: { $gt: 1000 } } },
{ $sort: { chiffre_affaires: -1 } }
]);
Simulation Python : agrégation sur liste de dictionnaires#
# Simulation d'une collection MongoDB avec une liste de dictionnaires Python
documents = [
{"_id": 1, "nom": "Laptop Pro 15", "marque": "Lenko", "prix": 1299.99, "stock": 12,
"tags": ["laptop","pro"]},
{"_id": 2, "nom": "Laptop Air 13", "marque": "Lenko", "prix": 899.99, "stock": 8,
"tags": ["laptop","leger"]},
{"_id": 3, "nom": "Souris sans fil", "marque": "Logitux", "prix": 49.99, "stock": 150,
"tags": ["peripherique","sans_fil"]},
{"_id": 4, "nom": "Souris gaming", "marque": "Logitux", "prix": 79.99, "stock": 60,
"tags": ["peripherique","gaming"]},
{"_id": 5, "nom": "Clavier mécanique", "marque": "Meccasoft","prix": 89.99, "stock": 80,
"tags": ["peripherique","mecanique"]},
{"_id": 6, "nom": "Moniteur 27\"", "marque": "Samsung", "prix": 399.00, "stock": 30,
"tags": ["ecran"]},
{"_id": 7, "nom": "Moniteur 32\"", "marque": "Samsung", "prix": 549.00, "stock": 15,
"tags": ["ecran","4k"]},
{"_id": 8, "nom": "Webcam HD", "marque": "Logitux", "prix": 69.99, "stock": 0,
"tags": ["peripherique","video"]},
]
print(f"Collection : {len(documents)} documents")
pd.DataFrame([{k: v for k, v in d.items() if k != 'tags'} for d in documents])
Collection : 8 documents
| _id | nom | marque | prix | stock | |
|---|---|---|---|---|---|
| 0 | 1 | Laptop Pro 15 | Lenko | 1299.99 | 12 |
| 1 | 2 | Laptop Air 13 | Lenko | 899.99 | 8 |
| 2 | 3 | Souris sans fil | Logitux | 49.99 | 150 |
| 3 | 4 | Souris gaming | Logitux | 79.99 | 60 |
| 4 | 5 | Clavier mécanique | Meccasoft | 89.99 | 80 |
| 5 | 6 | Moniteur 27" | Samsung | 399.00 | 30 |
| 6 | 7 | Moniteur 32" | Samsung | 549.00 | 15 |
| 7 | 8 | Webcam HD | Logitux | 69.99 | 0 |
# Stage $match : stock > 0 (équivalent de WHERE stock > 0)
stage_match = [d for d in documents if d["stock"] > 0]
print(f"Après $match (stock > 0) : {len(stage_match)} documents")
# Stage $group : regrouper par marque
groupes = defaultdict(lambda: {"nb": 0, "somme_prix": 0.0, "ca": 0.0})
for d in stage_match:
m = d["marque"]
groupes[m]["nb"] += 1
groupes[m]["somme_prix"] += d["prix"]
groupes[m]["ca"] += d["prix"] * d["stock"]
resultats = [
{
"marque": marque,
"nb_references": g["nb"],
"prix_moyen": round(g["somme_prix"] / g["nb"], 2),
"chiffre_affaires": round(g["ca"], 2),
}
for marque, g in groupes.items()
]
# Stage $match HAVING : CA > 1000
resultats = [r for r in resultats if r["chiffre_affaires"] > 1000]
# Stage $sort : tri décroissant par CA
resultats.sort(key=lambda r: r["chiffre_affaires"], reverse=True)
df_agg = pd.DataFrame(resultats)
print("\nRésultat de l'agrégation (équivalent pipeline MongoDB) :")
display(df_agg)
Après $match (stock > 0) : 7 documents
Résultat de l'agrégation (équivalent pipeline MongoDB) :
| marque | nb_references | prix_moyen | chiffre_affaires | |
|---|---|---|---|---|
| 0 | Lenko | 2 | 1099.99 | 22799.8 |
| 1 | Samsung | 2 | 474.00 | 20205.0 |
| 2 | Logitux | 2 | 64.99 | 12297.9 |
| 3 | Meccasoft | 1 | 89.99 | 7199.2 |
# Simulation de $lookup (jointure) — commandes enrichies avec les détails produit
commandes = [
{"_id": 101, "client": "Alice", "produit_id": 1, "quantite": 2},
{"_id": 102, "client": "Bob", "produit_id": 3, "quantite": 5},
{"_id": 103, "client": "Alice", "produit_id": 6, "quantite": 1},
{"_id": 104, "client": "Carol", "produit_id": 2, "quantite": 1},
]
# Équivalent de $lookup (LEFT JOIN)
produit_par_id = {d["_id"]: d for d in documents}
commandes_enrichies = []
for cmd in commandes:
prod = produit_par_id.get(cmd["produit_id"], {})
commandes_enrichies.append({
"id_commande": cmd["_id"],
"client": cmd["client"],
"produit": prod.get("nom", "Inconnu"),
"marque": prod.get("marque", "?"),
"prix_unit": prod.get("prix", 0),
"quantite": cmd["quantite"],
"total": round(prod.get("prix", 0) * cmd["quantite"], 2),
})
print("Commandes avec $lookup (jointure simulée) :")
pd.DataFrame(commandes_enrichies)
Commandes avec $lookup (jointure simulée) :
| id_commande | client | produit | marque | prix_unit | quantite | total | |
|---|---|---|---|---|---|---|---|
| 0 | 101 | Alice | Laptop Pro 15 | Lenko | 1299.99 | 2 | 2599.98 |
| 1 | 102 | Bob | Souris sans fil | Logitux | 49.99 | 5 | 249.95 |
| 2 | 103 | Alice | Moniteur 27" | Samsung | 399.00 | 1 | 399.00 |
| 3 | 104 | Carol | Laptop Air 13 | Lenko | 899.99 | 1 | 899.99 |
# Simulation de $unwind sur les tags
rows_unwind = []
for d in documents:
for tag in d.get("tags", []):
rows_unwind.append({"nom": d["nom"], "marque": d["marque"], "tag": tag})
df_unwind = pd.DataFrame(rows_unwind)
# Compter les documents par tag (équivalent $unwind + $group + $sort)
tags_counts = df_unwind.groupby("tag").size().sort_values(ascending=False)
print("Fréquence des tags (après $unwind + $group) :")
print(tags_counts.to_string())
Fréquence des tags (après $unwind + $group) :
tag
peripherique 4
ecran 2
laptop 2
4k 1
leger 1
gaming 1
mecanique 1
pro 1
sans_fil 1
video 1
Visualisation : pipeline d’agrégation et comparaison SQL/MongoDB#
Quand choisir MongoDB ?#
Remarque 79
MongoDB est bien adapté quand :
Les données sont naturellement hiérarchiques (documents avec sous-documents imbriqués) et les jointures fréquentes nuiraient aux performances.
Le schéma évolue fréquemment : ajouter un champ à un document ne nécessite pas d’ALTER TABLE.
Le volume nécessite un sharding horizontal (MongoDB gère nativement le sharding par clé de shard).
Les données sont hétérogènes : chaque document peut avoir ses propres champs.
MongoDB est moins adapté quand :
Les relations entre entités sont nombreuses et complexes (préférer le modèle relationnel avec ses jointures).
L’intégrité transactionnelle multi-collection est critique (MongoDB supporte les transactions depuis la v4.0, mais c’est plus performant en relationnel).
Les requêtes analytiques ad hoc sur des données bien structurées sont la norme (PostgreSQL + DuckDB excellent dans ce cas).
Résumé#
Remarque 80
Ce chapitre a introduit MongoDB et le monde NoSQL :
Contexte :
Le NoSQL répond aux limites du modèle relationnel pour les données hétérogènes, les schémas évolutifs et la scalabilité horizontale.
Quatre familles : document, clé-valeur, colonne large, graphe.
MongoDB :
Les données sont des documents BSON flexibles, regroupés en collections.
_id(ObjectId) identifie chaque document de façon unique et distribuée.Le CRUD s’exprime avec
insertOne,find,updateOne,deleteOneet leurs variantes*Many.
Requêtes et agrégation :
Les opérateurs
$eq,$gt,$in,$and,$or,$regex,$existsfiltrent les documents.Le pipeline d’agrégation (
$match,$group,$sort,$project,$lookup,$unwind) est l’équivalent des requêtes analytiques SQL.$lookupréalise des jointures entre collections.
Index :
Simple, composé, texte, géospatial (2dsphere), unique, TTL.
Sans index → COLLSCAN (parcours complet) ; avec index → IXSCAN.
SQL vs MongoDB :
Les deux approches expriment les mêmes traitements analytiques mais avec une syntaxe et une philosophie différentes.
Le choix dépend de la structure des données, des besoins de schéma flexible, et des patterns d’accès.