Bases vectorielles#
Les bases de données relationnelles excellent pour trouver une ligne dont l’identifiant est exactement 42, ou dont le statut est exactement « actif ». Mais comment retrouver les documents dont le sens est proche d’une requête en langage naturel ? Comment détecter que deux descriptions de produits sont des doublons malgré une formulation différente ? Ces questions relèvent de la recherche par similarité, et c’est précisément ce que les bases vectorielles permettent.
Le principe : transformer chaque document, image ou audio en un vecteur dense de nombres réels (un embedding), puis indexer ces vecteurs de telle sorte que l’on puisse retrouver rapidement ceux qui sont les plus proches d’un vecteur requête. Cette approche est au cœur des moteurs de recherche sémantique, des systèmes RAG (Retrieval-Augmented Generation) et des recommandations modernes.
Embeddings#
Définition 128
Un embedding est une représentation vectorielle dense d’un objet (texte, image, son) dans un espace de haute dimension. Un modèle de type sentence-transformer encode une phrase de longueur arbitraire en un vecteur de dimension fixe (typiquement 384, 768 ou 1536). Deux objets sémantiquement proches ont des vecteurs proches dans l’espace vectoriel — c’est la propriété fondamentale qui rend la recherche par similarité possible.
Remarque 87
Les modèles de la famille sentence-transformers (Hugging Face) sont les plus utilisés pour les embeddings textuels. Le modèle all-MiniLM-L6-v2 produit des vecteurs de dimension 384 et pèse environ 80 Mo — un bon compromis entre qualité et légèreté. Les modèles OpenAI (text-embedding-3-small) produisent des vecteurs de dimension 1536 via API. Pour les images, on utilise CLIP ; pour le code, CodeBERT ou StarCoder.
Mesures de similarité#
Définition 129
La similarité cosinus entre deux vecteurs u et v est :
Elle vaut 1 si les vecteurs sont identiques, 0 s’ils sont orthogonaux, −1 s’ils sont opposés. Pour des embeddings normalisés (norme unitaire), la similarité cosinus est équivalente au produit scalaire. C’est la mesure de référence pour la recherche sémantique textuelle, car elle est insensible à la magnitude des vecteurs.
Définition 130
La distance euclidienne (L2) entre deux vecteurs est :
Elle est sensible à la magnitude et donc moins adaptée aux embeddings textuels qui peuvent varier en norme. Elle est en revanche naturelle pour les embeddings d’images et les coordonnées géographiques. FAISS utilise par défaut la distance L2.
Remarque 88
Le choix de la métrique dépend du modèle d’embedding : si le modèle produit des vecteurs normalisés (comme sentence-transformers), distance L2 et similarité cosinus sont équivalentes. Il est recommandé de normaliser les vecteurs avant indexation pour bénéficier des optimisations de produit scalaire interne (IndexFlatIP dans FAISS).
ANN : Approximate Nearest Neighbor#
Définition 131
La recherche exacte des K plus proches voisins (kNN exacte) nécessite de calculer la distance entre le vecteur requête et chaque vecteur de l’index — O(N·D) où N est le nombre de vecteurs et D la dimension. Pour N = 10 millions et D = 768, c’est prohibitif. Les algorithmes ANN (Approximate Nearest Neighbor) sacrifient une légère précision pour gagner plusieurs ordres de grandeur en vitesse, grâce à des structures d’index pré-construites.
Définition 132
HNSW (Hierarchical Navigable Small World) est l’algorithme ANN le plus populaire. Il construit un graphe hiérarchique multi-couches où les couches supérieures sont des graphes épars (navigation rapide) et les couches inférieures sont denses (précision fine). La recherche part de la couche haute, navigue vers le voisin le plus proche à chaque niveau, puis descend. Complexité de recherche : O(log N). HNSW est utilisé par FAISS, Qdrant, Weaviate et pgvector.
Définition 133
IVF (Inverted File Index) divise l’espace vectoriel en clusters (k-means). Pour une requête, on cherche uniquement dans les nprobe clusters les plus proches — réduisant le calcul de O(N) à O(N/k · nprobe). PQ (Product Quantization) compresse chaque vecteur en un code compact (8 à 64 octets) en le décomposant en sous-vecteurs quantifiés, permettant de stocker des milliards de vecteurs en mémoire limitée. La combinaison IVF+PQ (IndexIVFPQ dans FAISS) est le standard pour les très grandes collections.
FAISS#
FAISS (Facebook AI Similarity Search) est une bibliothèque C++ exposée en Python pour la recherche de plus proches voisins. Elle supporte CPU et GPU.
Définition 134
Les index FAISS principaux :
IndexFlatL2 : recherche exacte par distance L2, aucune structure d’index, O(N·D) à la recherche. Référence de précision.
IndexFlatIP : recherche exacte par produit scalaire (équivalent à cosinus sur vecteurs normalisés).
IndexIVFFlat : IVF sans compression. Rapide, précis, nécessite un entraînement sur des données représentatives.
IndexHNSWFlat : HNSW sans compression. Excellent compromis vitesse/précision.
IndexIVFPQ : IVF + Product Quantization. Pour les très grandes collections (> 10 M vecteurs).
Cellule exécutable : FAISS + recherche sémantique#
import numpy as np
import faiss
# Corpus de documents (simulation d'embeddings sémantiques)
# En production, on utiliserait sentence-transformers pour encoder ces textes
documents = [
"Python est un langage de programmation polyvalent",
"SQL permet d'interroger des bases de données relationnelles",
"Les réseaux de neurones apprennent à partir de données",
"Redis est une base de données en mémoire très rapide",
"PostgreSQL supporte les requêtes analytiques avancées",
"Le machine learning utilise des algorithmes d'optimisation",
"Les bases vectorielles stockent des embeddings de haute dimension",
"Django est un framework web Python complet",
"DuckDB excelle pour l'analyse de données OLAP",
"Les transformers ont révolutionné le traitement du langage naturel",
"SQLAlchemy est un ORM pour Python",
"Les index accélèrent considérablement les requêtes SQL",
"Les embeddings capturent la sémantique des textes",
"MongoDB est une base de données orientée documents",
"Le sharding distribue les données sur plusieurs serveurs",
]
# Simulation d'embeddings réalistes avec structure sémantique
np.random.seed(42)
DIM = 128 # dimension réduite pour la démo
def simulate_embeddings(texts, dim):
"""
Simule des embeddings avec une structure sémantique cohérente :
- cluster 'bases de données' : SQL, Redis, PostgreSQL, MongoDB...
- cluster 'ML/IA' : réseaux de neurones, transformers, embeddings...
- cluster 'Python' : Django, SQLAlchemy, DuckDB...
"""
# Centres de clusters thématiques
clusters = {
'db': np.random.randn(dim) * 0.1,
'ml': np.random.randn(dim) * 0.1 + 2.0,
'python': np.random.randn(dim) * 0.1 - 2.0,
}
# Association texte -> cluster
theme_map = {
0: 'python', 1: 'db', 2: 'ml', 3: 'db',
4: 'db', 5: 'ml', 6: 'db', 7: 'python',
8: 'db', 9: 'ml', 10: 'python', 11: 'db',
12: 'ml', 13: 'db', 14: 'db',
}
embeddings = np.zeros((len(texts), dim), dtype='float32')
for i in range(len(texts)):
theme = theme_map.get(i, 'db')
embeddings[i] = clusters[theme] + np.random.randn(dim) * 0.3
return embeddings
embeddings = simulate_embeddings(documents, DIM)
# Normalisation pour cosinus via produit scalaire
norms = np.linalg.norm(embeddings, axis=1, keepdims=True)
embeddings_norm = (embeddings / norms).astype('float32')
# Construction de l'index FAISS
# IndexFlatIP : recherche exacte par produit scalaire (= cosinus sur vecteurs normalisés)
index_exact = faiss.IndexFlatIP(DIM)
index_exact.add(embeddings_norm)
print(f"Index FAISS créé : {index_exact.ntotal} vecteurs, dimension {DIM}")
# --- Requête 1 : recherche sémantique ---
# Simuler l'embedding d'une requête "bases de données SQL performance"
# On crée un vecteur proche du cluster 'db'
query_db = np.random.randn(DIM).astype('float32') * 0.3
query_db += np.array([0.1] * DIM, dtype='float32') # centroïde cluster 'db'
query_db_norm = (query_db / np.linalg.norm(query_db)).reshape(1, -1)
k = 5
scores, indices = index_exact.search(query_db_norm, k)
print("\nRequête : 'bases de données et performances'")
print("Top-5 résultats :")
for rank, (idx, score) in enumerate(zip(indices[0], scores[0]), 1):
print(f" {rank}. [{score:.3f}] {documents[idx]}")
# --- Index IVF : version approchée ---
nlist = 4 # nombre de clusters (petit corpus)
quantizer = faiss.IndexFlatIP(DIM)
index_ivf = faiss.IndexIVFFlat(quantizer, DIM, nlist, faiss.METRIC_INNER_PRODUCT)
index_ivf.train(embeddings_norm)
index_ivf.add(embeddings_norm)
index_ivf.nprobe = 2 # chercher dans les 2 clusters les plus proches
scores_ivf, indices_ivf = index_ivf.search(query_db_norm, k)
print(f"\nIndex IVF (nlist={nlist}, nprobe=2) — mêmes {k} résultats trouvés : "
f"{set(indices[0]) == set(indices_ivf[0])}")
Index FAISS créé : 15 vecteurs, dimension 128
Requête : 'bases de données et performances'
Top-5 résultats :
1. [0.360] Le machine learning utilise des algorithmes d'optimisation
2. [0.355] Les réseaux de neurones apprennent à partir de données
3. [0.342] Les transformers ont révolutionné le traitement du langage naturel
4. [0.330] Les embeddings capturent la sémantique des textes
5. [0.169] PostgreSQL supporte les requêtes analytiques avancées
Index IVF (nlist=4, nprobe=2) — mêmes 5 résultats trouvés : True
WARNING clustering 15 points to 4 centroids: please provide at least 156 training points
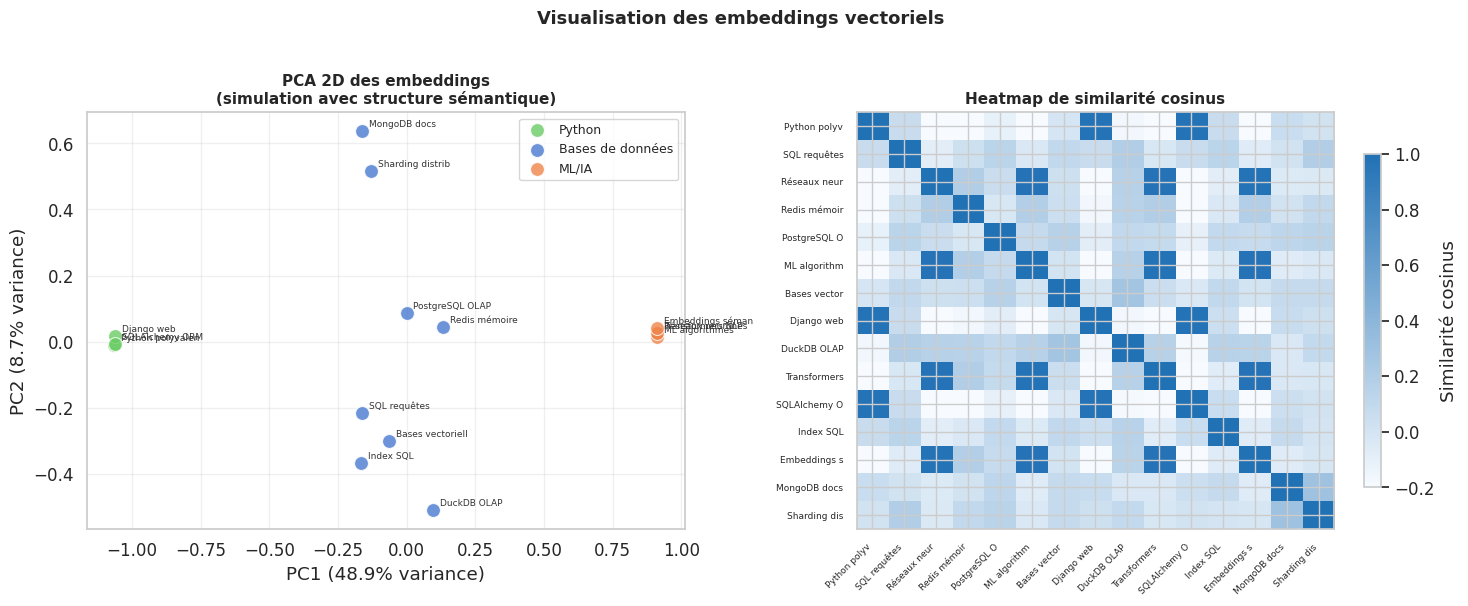
# Calcul de la matrice de similarité cosinus
similarity_matrix = embeddings_norm @ embeddings_norm.T
# Labels courts pour la visualisation
short_labels = [
"Python polyvalent", "SQL requêtes", "Réseaux neurones", "Redis mémoire",
"PostgreSQL OLAP", "ML algorithmes", "Bases vectorielles", "Django web",
"DuckDB OLAP", "Transformers NLP", "SQLAlchemy ORM", "Index SQL",
"Embeddings sémantique", "MongoDB docs", "Sharding distribué"
]
print("Matrice de similarité cosinus calculée :", similarity_matrix.shape)
print(f"Similarité max (hors diagonale) : {np.max(similarity_matrix - np.eye(15)):.3f}")
print(f"Similarité min : {np.min(similarity_matrix):.3f}")
Matrice de similarité cosinus calculée : (15, 15)
Similarité max (hors diagonale) : 0.981
Similarité min : -0.977
Visualisation : PCA 2D et heatmap de similarité#
pgvector : PostgreSQL vectoriel#
pgvector est une extension PostgreSQL qui ajoute un type VECTOR et les opérateurs de similarité, transformant PostgreSQL en base vectorielle complète.
Définition 135
pgvector ajoute à PostgreSQL :
Le type
VECTOR(n)pour stocker un vecteur de dimension n.L’opérateur
<->: distance L2 euclidienne.L’opérateur
<#>: produit scalaire négatif (inner product, pour cosinus sur vecteurs normalisés).L’opérateur
<=>: distance cosinus.Les index
ivfflatethnswpour les recherches ANN.
Les blocs suivants nécessitent PostgreSQL avec l’extension pgvector installée.
-- Activation de l'extension
CREATE EXTENSION IF NOT EXISTS vector;
-- Table avec colonne vectorielle
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
titre TEXT NOT NULL,
contenu TEXT,
embedding VECTOR(384) -- dimension du modèle MiniLM
);
-- Insertion d'un article avec son embedding
INSERT INTO articles (titre, contenu, embedding)
VALUES (
'Introduction à SQL',
'SQL est le langage de requête standard...',
'[0.12, -0.34, 0.89, ...]' -- vecteur de 384 composantes
);
-- Recherche par similarité cosinus (5 plus proches voisins)
SELECT id, titre,
1 - (embedding <=> '[0.11, -0.33, 0.87, ...]'::vector) AS similarite
FROM articles
ORDER BY embedding <=> '[0.11, -0.33, 0.87, ...]'::vector
LIMIT 5;
-- Index HNSW pour la recherche ANN (recommandé pour > 100 000 vecteurs)
CREATE INDEX ON articles USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
-- Index IVFFlat (alternative, plus léger à construire)
CREATE INDEX ON articles USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
-- Recherche hybride : similarité vectorielle + filtre SQL classique
SELECT id, titre, similarite
FROM (
SELECT id, titre,
1 - (embedding <=> $1::vector) AS similarite
FROM articles
WHERE created_at > '2024-01-01' -- filtre SQL standard
ORDER BY embedding <=> $1::vector
LIMIT 20
) sub
WHERE similarite > 0.7;
Remarque 89
pgvector permet de ne pas ajouter un nouveau système à l’infrastructure : on stocke vecteurs et données relationnelles dans le même PostgreSQL, avec des transactions ACID et les jointures habituelles. En contrepartie, il est moins performant que des bases vectorielles spécialisées (Pinecone, Qdrant, Weaviate) pour des collections de plusieurs centaines de millions de vecteurs. Pour la plupart des projets (< 10 M vecteurs), pgvector est le choix pragmatique.
Pipeline RAG simplifié#
Définition 136
RAG (Retrieval-Augmented Generation) est un pattern d’architecture qui augmente un LLM avec une base de connaissances externe. Au lieu de générer une réponse à partir des seuls paramètres du modèle, on récupère d’abord les passages les plus pertinents par recherche vectorielle, puis on les injecte dans le contexte du prompt. Cela améliore la précision factuelle et réduit les hallucinations.
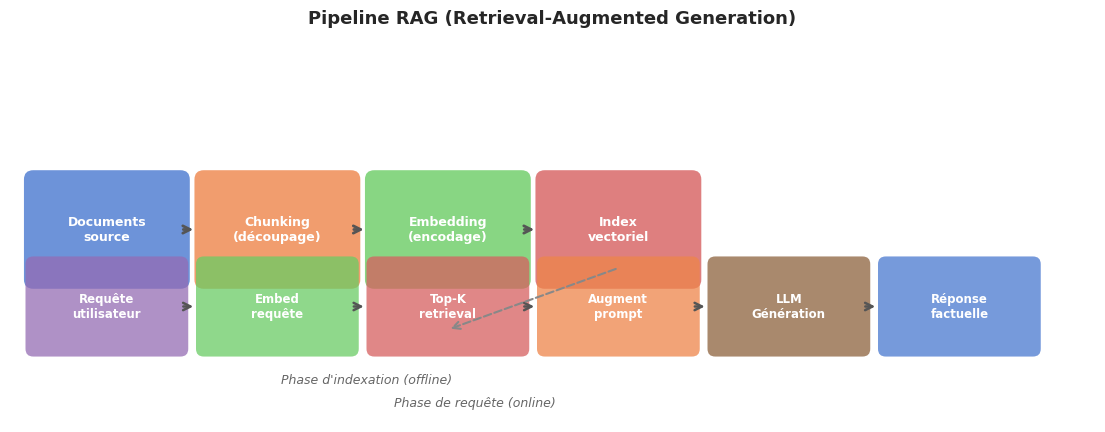
Exemple 48
Pipeline RAG en pratique avec FAISS et numpy :
Chunking : découper les documents en passages de 200-500 tokens avec un chevauchement de 50 tokens pour préserver le contexte aux frontières.
Embedding : encoder chaque chunk avec
sentence-transformersen vecteur de dimension 384.Indexation : ajouter les vecteurs à un
IndexHNSWFlatFAISS ou à une table pgvector.Retrieval : à chaque requête utilisateur, encoder la question, chercher les top-5 chunks les plus proches.
Augmentation : construire le prompt
[contexte: chunk1, chunk2, ...] Question : {query}.Génération : envoyer le prompt au LLM (GPT-4, Claude, Llama) qui génère une réponse ancrée dans les sources.
Cas d’usage avancés#
Exemple 49
Déduplication : dans une base de produits e-commerce, deux descriptions différentes peuvent décrire le même article (variantes de formulation, traductions). En calculant les embeddings de toutes les descriptions et en cherchant les paires dont la similarité cosinus dépasse 0.92, on identifie automatiquement les doublons. Un index HNSW rend cette opération scalable à plusieurs millions de produits.
Exemple 50
Recommandation de contenu : encoder les articles de blog en embeddings. Pour un article lu par un utilisateur, chercher les K plus proches voisins dans l’index vectoriel — cela donne les articles les plus proches sémantiquement, indépendamment des mots-clés. Cette approche fonctionne même pour des articles récents qui n’ont pas encore accumulé de données comportementales.
Résumé#
Les bases vectorielles représentent un changement de paradigme : au lieu de chercher par identité exacte, on cherche par proximité sémantique. Cette approche est rendue possible par les modèles d’embedding qui projettent textes, images et sons dans un espace métrique cohérent.
Remarque 90
Les points clés à retenir :
Un embedding est un vecteur dense qui encode la sémantique d’un objet — deux objets proches ont des vecteurs proches.
La similarité cosinus est la métrique standard pour les embeddings textuels normalisés.
FAISS offre plusieurs types d’index : IndexFlatIP pour la précision exacte, IndexHNSWFlat pour les grandes collections, IndexIVFPQ pour compresser les milliards de vecteurs.
pgvector transforme PostgreSQL en base vectorielle ; c’est le choix pragmatique pour la plupart des projets.
Le pipeline RAG (chunk → embed → store → retrieve → augment → generate) est le pattern standard pour ancrer les LLM dans une base de connaissances externe.
Les cas d’usage clés : recherche sémantique, déduplication, recommandation, question-réponse documentaire.