Le modèle relationnel#
Contexte historique#
À la fin des années 1960, les bases de données reposaient sur des modèles hiérarchiques (IMS d’IBM, 1966) ou réseau (CODASYL, 1969). Ces systèmes obligeaient le programmeur à naviguer manuellement dans des structures arborescentes ou en graphe pour accéder aux données : une opération fastidieuse, fragile, et intimement liée à la représentation physique du stockage.
En juin 1970, Edgar Frank Codd, chercheur chez IBM, publie l’article fondateur « A Relational Model of Data for Large Shared Data Banks » dans les Communications of the ACM. Cette publication introduit le modèle relationnel, fondé sur la théorie des ensembles et la logique du premier ordre. Deux idées révolutionnaires y sont présentées :
Les données sont organisées en relations (tables), indépendamment de leur stockage physique.
Un langage déclaratif (l’algèbre relationnelle) permet d’interroger les données sans décrire comment les parcourir.
Remarque 1
L’article de Codd de 1970 est considéré comme l’un des textes les plus influents de l’informatique. Il vaudra à son auteur le prix Turing en 1981. Le concept central est la séparation entre la vue logique des données et leur implémentation physique, nommée indépendance des données.
IBM System R (1974–1979) est le premier prototype de système de gestion de base de données relationnelle (SGBDR). Il donne naissance à SEQUEL, rebaptisé SQL (Structured Query Language). En parallèle, Michael Stonebraker développe INGRES à Berkeley. Les premières bases commerciales apparaissent vers 1979 : Oracle (Relational Software Inc.), puis DB2 d’IBM (1983). Aujourd’hui, MySQL, PostgreSQL, SQLite, SQL Server et des dizaines d’autres systèmes perpétuent ce modèle.
Le modèle relationnel : concepts fondamentaux#
Relation, tuple, attribut, domaine#
Définition 1 (Domaine)
Un domaine \(D\) est un ensemble de valeurs atomiques du même type. Par exemple : l’ensemble des entiers naturels, l’ensemble des chaînes de caractères de longueur inférieure à 50, ou l’ensemble des dates valides. Chaque attribut d’une relation est défini sur un domaine.
Définition 2 (Relation)
Soit \(D_1, D_2, \ldots, D_n\) des domaines (non nécessairement distincts). Une relation \(R\) de degré \(n\) est un sous-ensemble fini du produit cartésien \(D_1 \times D_2 \times \cdots \times D_n\).
En pratique, une relation est une table composée de :
un schéma : la liste des attributs et leurs domaines, noté \(R(A_1 : D_1, \ldots, A_n : D_n)\),
une extension : l’ensemble des tuples (lignes) actuellement stockés.
Définition 3 (Tuple)
Un tuple est un élément du produit cartésien, c’est-à-dire une ligne de la table. Un tuple de degré \(n\) associe à chaque attribut \(A_i\) une valeur du domaine \(D_i\) (ou la valeur spéciale NULL).
Exemple 1 (Exemple de relation)
La relation EMPLOYE(id: ℕ, nom: chaîne, salaire: ℝ⁺, dept_id: ℕ) peut contenir les tuples :
id |
nom |
salaire |
dept_id |
|---|---|---|---|
1 |
Alice |
4500 |
10 |
2 |
Bob |
3800 |
20 |
3 |
Charlie |
5200 |
10 |
Chaque ligne est un tuple ; les colonnes sont les attributs ; l’ensemble des lignes est l’extension de la relation.
Remarque 2
Dans le modèle théorique, les tuples d’une relation ne sont pas ordonnés : une relation est un ensemble, non une liste. En pratique, SQL renvoie les lignes dans un ordre arbitraire sauf si une clause ORDER BY est spécifiée.
Les clés#
Clé candidate#
Définition 4 (Super-clé et clé candidate)
Une super-clé d’une relation \(R\) est un sous-ensemble d’attributs \(K \subseteq \{A_1, \ldots, A_n\}\) tel que deux tuples distincts ne peuvent jamais avoir les mêmes valeurs sur \(K\).
Une clé candidate est une super-clé minimale : aucun sous-ensemble propre de \(K\) n’est lui-même une super-clé.
Exemple 2 (Clés candidates)
Dans la relation EMPLOYE(id, nom, email, salaire) :
{id}est une clé candidate (l’identifiant est unique et minimal).{email}peut aussi être une clé candidate si les emails sont uniques.{id, nom}est une super-clé mais pas une clé candidate (car{id}seul suffit).
Clé primaire#
Définition 5 (Clé primaire)
La clé primaire (PRIMARY KEY) est la clé candidate choisie par le concepteur pour identifier sans ambiguïté chaque tuple d’une relation. Elle est unique et ne peut pas contenir de valeur NULL. Une relation possède exactement une clé primaire.
Clé étrangère#
Définition 6 (Clé étrangère)
Une clé étrangère (FOREIGN KEY) est un attribut (ou groupe d’attributs) d’une relation \(R_1\) dont les valeurs doivent correspondre à la clé primaire d’une relation \(R_2\). Elle matérialise une association entre deux relations et garantit l”intégrité référentielle.
Clé naturelle vs surrogate#
Définition 7 (Clé naturelle et clé surrogate)
Une clé naturelle est un attribut porteur de sens métier qui identifie naturellement une entité : le numéro de sécurité sociale, l’ISBN d’un livre, l’adresse email d’un utilisateur.
Une clé surrogate (ou artificielle) est un identifiant technique sans signification métier, généralement un entier auto-incrémenté (
SERIAL,AUTO_INCREMENT) ou un UUID. Elle est stable dans le temps et indépendante des évolutions métier.
En pratique, on préfère souvent une clé surrogate comme clé primaire, quitte à placer une contrainte UNIQUE sur la clé naturelle.
Contraintes d’intégrité#
Définition 8 (Intégrité d’entité)
La contrainte d”intégrité d’entité stipule que la clé primaire d’une relation ne peut pas contenir de valeur NULL. Chaque tuple doit être identifiable de façon certaine.
Définition 9 (Intégrité référentielle)
La contrainte d”intégrité référentielle stipule que toute valeur d’une clé étrangère doit soit être NULL, soit correspondre à une valeur existante de la clé primaire référencée dans la relation parente.
Autrement dit, il ne peut pas exister de tuple « orphelin » qui pointerait vers une entité inexistante.
Définition 10 (Intégrité de domaine)
La contrainte d”intégrité de domaine exige que chaque valeur d’un attribut appartienne au domaine défini pour cet attribut : le bon type de données, dans la plage de valeurs autorisée, respectant les contraintes CHECK définies.
Remarque 3
Les SGBDR modernes peuvent imposer automatiquement l’intégrité d’entité (via PRIMARY KEY) et l’intégrité référentielle (via FOREIGN KEY avec ON DELETE / ON UPDATE). L’intégrité de domaine est assurée par les types et les contraintes CHECK.
Normalisation#
La normalisation est un processus de décomposition des relations visant à éliminer les redondances et les anomalies. Elle s’appuie sur la notion de dépendance fonctionnelle.
Définition 11 (Dépendance fonctionnelle)
Soit une relation \(R\) et deux ensembles d’attributs \(X\) et \(Y\). On dit que \(X\) détermine fonctionnellement \(Y\) (noté \(X \rightarrow Y\)) si, pour tout état de \(R\), deux tuples ayant les mêmes valeurs sur \(X\) ont nécessairement les mêmes valeurs sur \(Y\).
\(X\) est l”antécédent (déterminant) et \(Y\) le conséquent (déterminé).
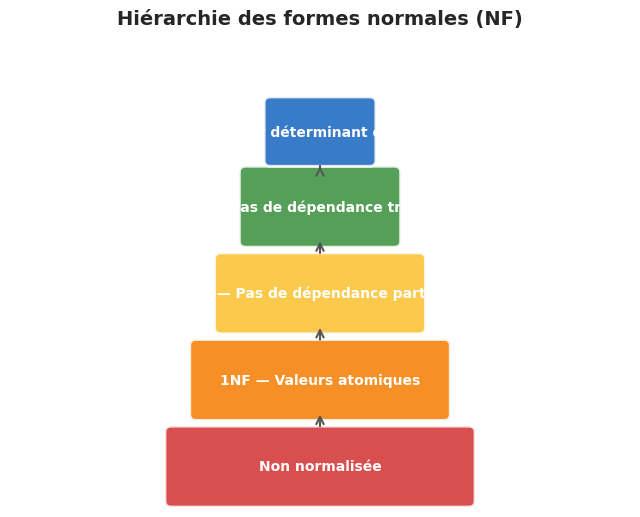
Première forme normale (1NF)#
Définition 12 (Première forme normale)
Une relation est en première forme normale (1NF) si et seulement si :
Tous les attributs contiennent des valeurs atomiques (non décomposables).
Il n’existe pas de groupes répétitifs ou de listes dans un attribut.
Chaque ligne est identifiable par une clé primaire.
Exemple 3 (Violation de la 1NF)
La table suivante viole la 1NF car l’attribut téléphones contient plusieurs valeurs :
id |
nom |
téléphones |
|---|---|---|
1 |
Alice |
06-11-22-33, 01-44-55 |
La solution est de créer une table séparée TELEPHONE(employe_id, numero).
Deuxième forme normale (2NF)#
Définition 13 (Deuxième forme normale)
Une relation est en deuxième forme normale (2NF) si elle est en 1NF et si tout attribut non-clé dépend fonctionnellement de la totalité de la clé primaire (pas d’une partie seulement).
La 2NF n’est pertinente que lorsque la clé primaire est composite (constituée de plusieurs attributs).
Exemple 4 (Violation de la 2NF)
La relation INSCRIPTION(etudiant_id, cours_id, note, nom_cours) avec clé {etudiant_id, cours_id} viole la 2NF car nom_cours dépend uniquement de cours_id (dépendance partielle).
Correction : décomposer en INSCRIPTION(etudiant_id, cours_id, note) et COURS(cours_id, nom_cours).
Troisième forme normale (3NF)#
Définition 14 (Troisième forme normale)
Une relation est en troisième forme normale (3NF) si elle est en 2NF et s’il n’existe pas de dépendance transitive : aucun attribut non-clé ne dépend fonctionnellement d’un autre attribut non-clé.
Autrement dit, les seules dépendances fonctionnelles admises sont de la forme \(\text{clé} \rightarrow \text{attribut non-clé}\).
Exemple 5 (Violation de la 3NF)
La relation EMPLOYE(id, nom, dept_id, nom_dept) viole la 3NF car nom_dept dépend de dept_id (attribut non-clé), et non directement de id.
Correction : EMPLOYE(id, nom, dept_id) et DEPARTEMENT(dept_id, nom_dept).
Forme normale de Boyce-Codd (BCNF)#
Définition 15 (Forme normale de Boyce-Codd)
Une relation est en forme normale de Boyce-Codd (BCNF) si, pour toute dépendance fonctionnelle non triviale \(X \rightarrow Y\), \(X\) est une super-clé de la relation.
La BCNF est plus stricte que la 3NF : elle élimine des anomalies résiduelles liées à certaines configurations de clés candidates multiples.
Remarque 4
Toute relation en BCNF est en 3NF. L’inverse n’est pas toujours vrai. La décomposition en BCNF préserve les dépendances fonctionnelles dans la majorité des cas pratiques, mais pas toujours.
Anomalies de mise à jour#
Quand une relation n’est pas normalisée, trois types d’anomalies peuvent survenir lors des opérations de modification :
Définition 16 (Anomalies de mise à jour)
Anomalie d’insertion : il est impossible d’insérer certaines informations sans en fournir d’autres qui n’ont pas encore de valeur (ex. : on ne peut pas enregistrer un département sans avoir au moins un employé).
Anomalie de suppression : supprimer un tuple entraîne involontairement la perte d’informations sur une autre entité (ex. : supprimer le dernier employé d’un département efface aussi les informations sur ce département).
Anomalie de modification : mettre à jour une valeur implique de modifier plusieurs tuples, sous peine d’incohérence (ex. : changer le nom d’un département nécessite de modifier toutes les lignes des employés de ce département).
Exemple 6 (Illustration des anomalies)
Considérons la relation dénormalisée EMP_DEPT(emp_id, emp_nom, dept_id, dept_nom, dept_ville).
Insertion : ajouter le département « Recherche » (dept_id=30) sans employé est impossible si
emp_idest la clé primaire.Suppression : supprimer l’unique employé du département « Logistique » (dept_id=40) détruit toute trace de ce département.
Modification : déplacer le département « Ventes » de Paris à Lyon nécessite de mettre à jour chaque ligne de chaque employé de ce département.
Visualisations#
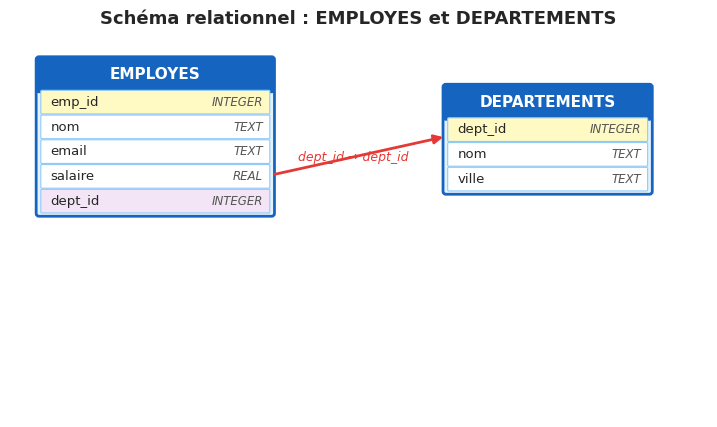
import sqlite3
import pandas as pd
# Exemple : relation EMPLOYE avec ses attributs
conn = sqlite3.connect(":memory:")
conn.executescript("""
CREATE TABLE departements (
dept_id INTEGER PRIMARY KEY,
nom TEXT NOT NULL,
ville TEXT NOT NULL
);
CREATE TABLE employes (
emp_id INTEGER PRIMARY KEY,
nom TEXT NOT NULL,
email TEXT UNIQUE,
salaire REAL CHECK(salaire > 0),
dept_id INTEGER REFERENCES departements(dept_id)
);
INSERT INTO departements VALUES (10, 'Informatique', 'Paris');
INSERT INTO departements VALUES (20, 'Comptabilité', 'Lyon');
INSERT INTO departements VALUES (30, 'Ressources Humaines', 'Bordeaux');
INSERT INTO employes VALUES (1, 'Alice Martin', 'alice@corp.fr', 4500.0, 10);
INSERT INTO employes VALUES (2, 'Bob Dupont', 'bob@corp.fr', 3800.0, 20);
INSERT INTO employes VALUES (3, 'Charlie Leroy', 'charlie@corp.fr',5200.0, 10);
INSERT INTO employes VALUES (4, 'Diana Morel', 'diana@corp.fr', 4100.0, 30);
INSERT INTO employes VALUES (5, 'Eric Blanc', 'eric@corp.fr', 4700.0, 20);
""")
print("=== Table EMPLOYES ===")
df_emp = pd.read_sql("SELECT * FROM employes", conn)
print(df_emp.to_string(index=False))
print("\n=== Table DEPARTEMENTS ===")
df_dept = pd.read_sql("SELECT * FROM departements", conn)
print(df_dept.to_string(index=False))
=== Table EMPLOYES ===
emp_id nom email salaire dept_id
1 Alice Martin alice@corp.fr 4500.0 10
2 Bob Dupont bob@corp.fr 3800.0 20
3 Charlie Leroy charlie@corp.fr 5200.0 10
4 Diana Morel diana@corp.fr 4100.0 30
5 Eric Blanc eric@corp.fr 4700.0 20
=== Table DEPARTEMENTS ===
dept_id nom ville
10 Informatique Paris
20 Comptabilité Lyon
30 Ressources Humaines Bordeaux
Résumé#
Dans ce chapitre, nous avons posé les bases théoriques du modèle relationnel, héritage direct des travaux de Codd (1970). Les points clés à retenir sont :
Relation = table : un ensemble non ordonné de tuples partageant le même schéma.
Clés : candidate (unique et minimale), primaire (choisie), étrangère (référence vers une autre table), naturelle ou surrogate.
Contraintes d’intégrité : entité (PK ≠ NULL), référentielle (FK valide), domaine (valeurs dans la plage attendue).
Normalisation : processus de décomposition pour éliminer les redondances :
1NF : valeurs atomiques,
2NF : pas de dépendance partielle de la clé,
3NF : pas de dépendance transitive,
BCNF : tout déterminant est super-clé.
Anomalies : insertion, suppression, modification — conséquences d’une normalisation insuffisante.
Remarque 5
En pratique, la 3NF constitue le niveau de normalisation cible pour la majorité des applications transactionnelles. La BCNF est visée quand la robustesse est critique. Des dénormalisations contrôlées peuvent être justifiées pour des raisons de performance dans les entrepôts de données (data warehouses), où les lectures massives priment sur les mises à jour atomiques.