Analyse de données avec DuckDB#
SQLite est excellent pour les applications transactionnelles légères. Pandas est puissant pour la manipulation de données en Python. Mais aucun des deux n’est optimisé pour les requêtes analytiques — ces agrégations, jointures et fenêtrages sur des millions de lignes qui caractérisent la business intelligence. DuckDB comble ce vide : c’est une base de données analytique embarquée, qui s’installe comme un package Python et s’utilise directement sur des DataFrames, des fichiers CSV ou Parquet, sans serveur.
DuckDB est orienté OLAP (Online Analytical Processing) : il lit les données colonne par colonne, applique des opérations vectorisées sur des blocs, et tire parti du parallélisme multi-cœurs — là où SQLite lit ligne par ligne et reste mono-thread pour les requêtes.
OLAP vs OLTP#
Définition 144
OLTP (Online Transaction Processing) optimise les opérations transactionnelles courtes : insertion, mise à jour, lecture de quelques lignes par identifiant. Les bases OLTP (PostgreSQL, MySQL, SQLite) utilisent un stockage en lignes (row-oriented) — toutes les colonnes d’une ligne sont stockées ensemble, ce qui est optimal pour SELECT * FROM commandes WHERE id = 42.
OLAP (Online Analytical Processing) optimise les requêtes analytiques qui balayent des millions de lignes mais n’accèdent qu’à quelques colonnes : SELECT region, SUM(montant) FROM ventes GROUP BY region. Les bases OLAP (DuckDB, ClickHouse, BigQuery) utilisent un stockage en colonnes (column-oriented) — chaque colonne est stockée séparément, ce qui réduit les lectures inutiles et améliore la compression.
Remarque 95
DuckDB est embarqué comme SQLite : aucun serveur, aucune configuration. Il s’installe avec pip install duckdb et s’importe en une ligne. Contrairement à SQLite, il supporte le parallélisme multi-thread et les opérations vectorisées sur des blocs de données. En pratique, DuckDB sur un laptop peut analyser plusieurs centaines de millions de lignes en quelques secondes.
Lire directement des fichiers#
Définition 145
DuckDB peut interroger des fichiers directement dans le SQL, sans les charger au préalable en mémoire :
CSV :
SELECT * FROM read_csv_auto('data.csv')Parquet :
SELECT * FROM read_parquet('data.parquet')(format columnar natif)JSON :
SELECT * FROM read_json_auto('data.json')Glob :
SELECT * FROM read_parquet('data/year=2024/month=*.parquet')
Cette fonctionnalité permet d’analyser des téraoctets de données sur disque sans les charger entièrement en mémoire — DuckDB pousse les filtres et les projections au niveau de la lecture.
Intégration pandas#
Remarque 96
DuckDB s’intègre nativement avec pandas et Arrow : il peut lire un DataFrame directement (zéro-copie avec Arrow), exécuter du SQL dessus, et retourner le résultat sous forme de DataFrame. On enregistre un DataFrame avec duckdb.register('nom_table', df) ou on l’utilise directement dans le SQL via son nom de variable Python.
Génération du dataset#
import duckdb
np.random.seed(42)
N = 500_000 # 500 000 lignes
regions = ['Nord', 'Sud', 'Est', 'Ouest', 'Centre']
categories = ['Électronique', 'Vêtements', 'Alimentation', 'Sport', 'Maison']
vendeurs = [f"V{i:03d}" for i in range(1, 51)]
dates = pd.date_range("2022-01-01", "2023-12-31", periods=N)
df_ventes = pd.DataFrame({
'date': dates,
'annee': dates.year,
'mois': dates.month,
'trimestre': dates.quarter,
'region': np.random.choice(regions, N),
'categorie': np.random.choice(categories, N),
'vendeur': np.random.choice(vendeurs, N),
'quantite': np.random.randint(1, 20, N),
'prix_unit': np.round(np.random.exponential(scale=45, size=N) + 5, 2),
'remise': np.round(np.random.choice([0, 0.05, 0.10, 0.15, 0.20], N,
p=[0.5, 0.2, 0.15, 0.1, 0.05]), 2),
})
df_ventes['montant'] = np.round(df_ventes['quantite'] * df_ventes['prix_unit'] * (1 - df_ventes['remise']), 2)
print(f"Dataset créé : {len(df_ventes):,} lignes, {df_ventes.memory_usage(deep=True).sum() / 1e6:.1f} Mo")
print(df_ventes.head(3).to_string())
Dataset créé : 500,000 lignes, 46.7 Mo
date annee mois trimestre region categorie vendeur quantite prix_unit remise montant
0 2022-01-01 00:00:00.000000 2022 1 1 Ouest Vêtements V029 9 11.31 0.05 96.70
1 2022-01-01 00:02:05.971451 2022 1 1 Centre Alimentation V047 4 30.88 0.05 117.34
2 2022-01-01 00:04:11.942903 2022 1 1 Est Sport V050 19 18.31 0.05 330.50
Requêtes analytiques DuckDB#
# Connexion DuckDB et enregistrement du DataFrame
conn = duckdb.connect()
conn.register("ventes", df_ventes)
# 1. Chiffre d'affaires par région et catégorie
print("=== CA par région (top 3 catégories) ===")
result1 = conn.execute("""
SELECT
region,
categorie,
ROUND(SUM(montant), 0) AS ca_total,
COUNT(*) AS nb_transactions,
ROUND(AVG(montant), 2) AS panier_moyen,
ROUND(MEDIAN(montant), 2) AS panier_median,
ROUND(QUANTILE_CONT(montant, 0.9), 2) AS p90_montant
FROM ventes
GROUP BY region, categorie
ORDER BY ca_total DESC
LIMIT 8
""").df()
print(result1.to_string(index=False))
=== CA par région (top 3 catégories) ===
region categorie ca_total nb_transactions panier_moyen panier_median p90_montant
Nord Maison 9709232.0 20131 482.30 286.37 1170.40
Nord Électronique 9593411.0 20062 478.19 283.58 1142.47
Est Alimentation 9588856.0 20077 477.60 284.14 1135.93
Centre Sport 9587414.0 20215 474.27 280.00 1150.96
Sud Alimentation 9572829.0 20045 477.57 288.05 1146.32
Ouest Sport 9542687.0 20198 472.46 281.25 1131.97
Sud Maison 9539471.0 20083 475.00 277.38 1151.54
Sud Sport 9533792.0 19750 482.72 281.11 1164.31
# 2. Tendance mensuelle avec window functions
print("\n=== Tendance mensuelle : CA et croissance MoM ===")
result2 = conn.execute("""
WITH ca_mensuel AS (
SELECT
annee,
mois,
ROUND(SUM(montant), 0) AS ca
FROM ventes
GROUP BY annee, mois
)
SELECT
annee,
mois,
ca,
LAG(ca) OVER (ORDER BY annee, mois) AS ca_mois_prec,
ROUND(
100.0 * (ca - LAG(ca) OVER (ORDER BY annee, mois))
/ NULLIF(LAG(ca) OVER (ORDER BY annee, mois), 0),
1) AS croissance_pct
FROM ca_mensuel
ORDER BY annee, mois
LIMIT 10
""").df()
print(result2.to_string(index=False))
=== Tendance mensuelle : CA et croissance MoM ===
annee mois ca ca_mois_prec croissance_pct
2022 1 10010984.0 NaN NaN
2022 2 9255255.0 10010984.0 -7.5
2022 3 10101511.0 9255255.0 9.1
2022 4 9651103.0 10101511.0 -4.5
2022 5 10071375.0 9651103.0 4.4
2022 6 9849915.0 10071375.0 -2.2
2022 7 10038908.0 9849915.0 1.9
2022 8 10154452.0 10038908.0 1.2
2022 9 9606324.0 10154452.0 -5.4
2022 10 10046438.0 9606324.0 4.6
Fonctions analytiques avancées#
Définition 146
La clause QUALIFY est l’équivalent de HAVING pour les fonctions fenêtrées. Elle filtre les lignes après application des window functions, évitant une sous-requête. Exemple : QUALIFY RANK() OVER (PARTITION BY region ORDER BY ca DESC) <= 3 sélectionne les 3 meilleurs vendeurs par région directement.
Définition 147
L”ASOF JOIN est une jointure temporelle qui associe chaque ligne de la table gauche à la ligne de la table droite dont la clé est la plus proche et inférieure ou égale. Typiquement utilisé pour joindre des événements à la cotation de prix valide à ce moment-là, ou pour associer des logs à la configuration active lors de l’événement.
Définition 148
PIVOT transforme des valeurs de lignes en colonnes — l’équivalent d’un tableau croisé dynamique en SQL. DuckDB supporte PIVOT table ON colonne USING AGG(col) GROUP BY .... L’opération inverse, UNPIVOT, transforme des colonnes en lignes.
# 3. QUALIFY : top 2 catégories par région
print("=== Top 2 catégories par région (QUALIFY) ===")
result3 = conn.execute("""
SELECT
region,
categorie,
ROUND(SUM(montant), 0) AS ca,
RANK() OVER (PARTITION BY region ORDER BY SUM(montant) DESC) AS rang
FROM ventes
GROUP BY region, categorie
QUALIFY rang <= 2
ORDER BY region, rang
""").df()
print(result3.to_string(index=False))
# 4. Statistiques de corrélation
print("\n=== Corrélation quantité / montant ===")
result4 = conn.execute("""
SELECT
categorie,
ROUND(CORR(quantite, montant), 3) AS corr_qte_montant,
ROUND(REGR_SLOPE(montant, quantite), 2) AS slope,
ROUND(REGR_R2(montant, quantite), 3) AS r_squared
FROM ventes
GROUP BY categorie
ORDER BY corr_qte_montant DESC
""").df()
print(result4.to_string(index=False))
=== Top 2 catégories par région (QUALIFY) ===
region categorie ca rang
Centre Sport 9587414.0 1
Centre Vêtements 9510976.0 2
Est Alimentation 9588856.0 1
Est Électronique 9508297.0 2
Nord Maison 9709232.0 1
Nord Électronique 9593411.0 2
Ouest Sport 9542687.0 1
Ouest Maison 9515952.0 2
Sud Alimentation 9572829.0 1
Sud Maison 9539471.0 2
=== Corrélation quantité / montant ===
categorie corr_qte_montant slope r_squared
Maison 0.467 47.43 0.218
Alimentation 0.467 47.25 0.218
Électronique 0.467 47.37 0.218
Sport 0.466 47.58 0.218
Vêtements 0.466 46.72 0.217
# 5. PIVOT : CA par catégorie x trimestre
print("=== PIVOT : CA par catégorie x trimestre ===")
result_pivot = conn.execute("""
PIVOT (
SELECT categorie, trimestre, ROUND(SUM(montant), 0) AS ca
FROM ventes
GROUP BY categorie, trimestre
)
ON trimestre
USING SUM(ca)
GROUP BY categorie
ORDER BY categorie
""").df()
result_pivot.columns = ['Catégorie', 'T1', 'T2', 'T3', 'T4']
print(result_pivot.to_string(index=False))
=== PIVOT : CA par catégorie x trimestre ===
Catégorie T1 T2 T3 T4
Alimentation 11651666.0 11892154.0 11862601.0 11955227.0
Maison 11779435.0 11874944.0 12072230.0 11830585.0
Sport 11826875.0 11751309.0 12010717.0 11952894.0
Vêtements 11586574.0 11782240.0 11920461.0 11851984.0
Électronique 11573473.0 11796845.0 11964448.0 12004227.0
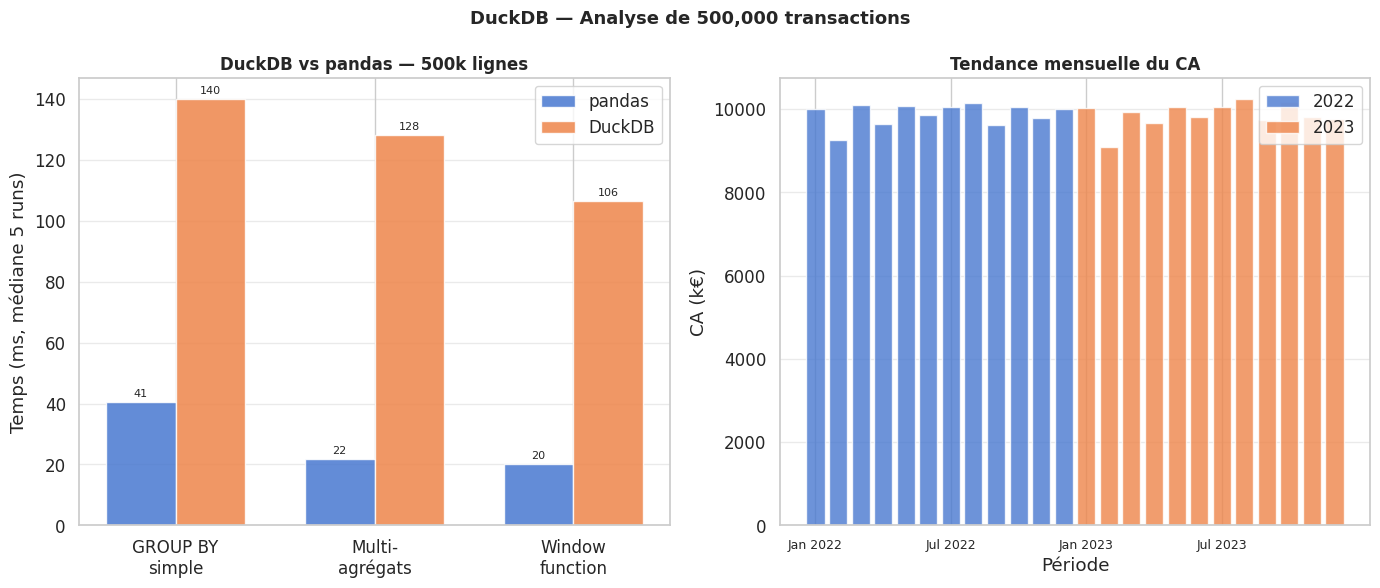
Benchmark DuckDB vs pandas#
Exemple 54
Pour les agrégations analytiques sur des DataFrames volumineux, DuckDB est systématiquement plus rapide que pandas pour deux raisons : (1) il accède aux données colonne par colonne (moins de mémoire lue), (2) il parallélise sur tous les cœurs CPU. L’avantage est particulièrement marqué sur les agrégations avec GROUP BY complexes et les window functions.
def benchmark(func, label, n_runs=5):
times = []
for _ in range(n_runs):
t0 = time.perf_counter()
func()
times.append((time.perf_counter() - t0) * 1000)
median_t = np.median(times)
print(f" {label:<45} : {median_t:7.1f} ms (médiane {n_runs} runs)")
return median_t
print(f"Benchmark sur {N:,} lignes\n")
results = {}
# --- Test 1 : GROUP BY simple ---
print("Test 1 : SUM(montant) GROUP BY region, categorie")
results['t1_pandas'] = benchmark(
lambda: df_ventes.groupby(['region', 'categorie'])['montant'].sum(),
"pandas groupby")
results['t1_duckdb'] = benchmark(
lambda: conn.execute("SELECT region, categorie, SUM(montant) FROM ventes GROUP BY region, categorie").df(),
"duckdb SQL")
# --- Test 2 : agrégation multiple ---
print("\nTest 2 : multi-agrégats (sum, mean, median, count)")
results['t2_pandas'] = benchmark(
lambda: df_ventes.groupby('region')['montant'].agg(['sum', 'mean', 'count']),
"pandas agg")
results['t2_duckdb'] = benchmark(
lambda: conn.execute("SELECT region, SUM(montant), AVG(montant), MEDIAN(montant), COUNT(*) FROM ventes GROUP BY region").df(),
"duckdb SQL")
# --- Test 3 : window function ---
print("\nTest 3 : rolling 3 mois + cumsum (window function)")
results['t3_pandas'] = benchmark(
lambda: (df_ventes.groupby(['annee', 'mois'])['montant'].sum()
.reset_index()
.assign(rolling=lambda d: d['montant'].rolling(3).mean())),
"pandas rolling")
results['t3_duckdb'] = benchmark(
lambda: conn.execute("""
SELECT annee, mois, SUM(montant) AS ca,
AVG(SUM(montant)) OVER (ORDER BY annee, mois ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS rolling3
FROM ventes GROUP BY annee, mois ORDER BY annee, mois
""").df(),
"duckdb window")
Benchmark sur 500,000 lignes
Test 1 : SUM(montant) GROUP BY region, categorie
pandas groupby : 40.6 ms (médiane 5 runs)
duckdb SQL : 139.9 ms (médiane 5 runs)
Test 2 : multi-agrégats (sum, mean, median, count)
pandas agg : 21.9 ms (médiane 5 runs)
duckdb SQL : 128.2 ms (médiane 5 runs)
Test 3 : rolling 3 mois + cumsum (window function)
pandas rolling : 20.2 ms (médiane 5 runs)
duckdb window : 106.4 ms (médiane 5 runs)
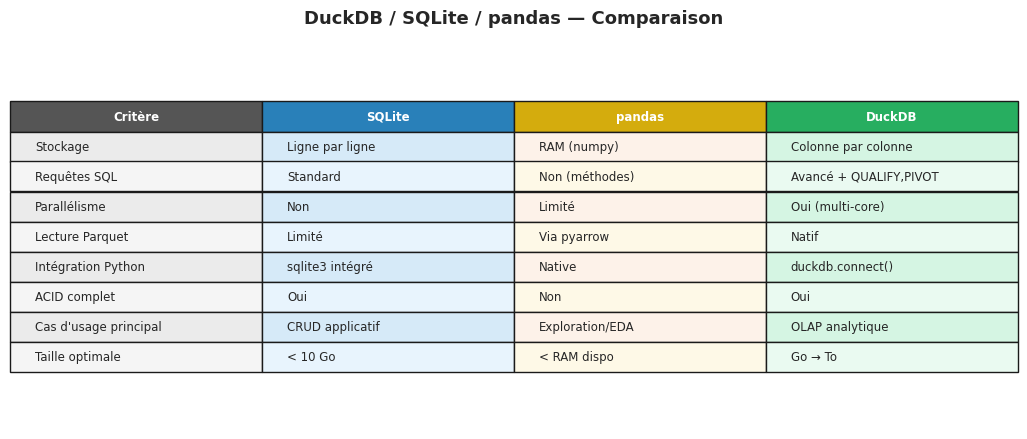
Comparaison DuckDB / SQLite / pandas#
Exemple 55
Choisir entre DuckDB, SQLite et pandas dépend du cas d’usage :
SQLite : CRUD transactionnel, données structurées < 10 Go, application légère. Accès ligne par ligne. Simple, fiable, universel.
pandas : manipulation exploratoire de DataFrames en mémoire, transformations complexes en Python, petits jeux de données (< quelques Go RAM).
DuckDB : requêtes analytiques SQL sur de grands jeux de données, lecture directe Parquet/CSV, intégration dans un pipeline data Python. Remplace avantageusement pandas pour les agrégations pures.
Lecture directe de Parquet et CSV#
# Exporter le dataset en Parquet et CSV, puis interroger directement
import tempfile, os
with tempfile.TemporaryDirectory() as tmpdir:
parquet_path = os.path.join(tmpdir, "ventes.parquet")
csv_path = os.path.join(tmpdir, "ventes.csv")
df_ventes.to_parquet(parquet_path, index=False)
df_ventes.to_csv(csv_path, index=False)
parquet_size = os.path.getsize(parquet_path) / 1e6
csv_size = os.path.getsize(csv_path) / 1e6
print(f"Taille CSV : {csv_size:.1f} Mo")
print(f"Taille Parquet : {parquet_size:.1f} Mo (compression {csv_size/parquet_size:.1f}x)")
# Requête directe sur Parquet (sans charger dans pandas)
result_pq = duckdb.execute(f"""
SELECT
region,
ROUND(SUM(montant), 0) AS ca,
COUNT(*) AS nb_ventes
FROM read_parquet('{parquet_path}')
GROUP BY region
ORDER BY ca DESC
""").df()
print("\nCA par région (lu depuis Parquet) :")
print(result_pq.to_string(index=False))
Taille CSV : 38.1 Mo
Taille Parquet : 7.8 Mo (compression 4.9x)
CA par région (lu depuis Parquet) :
region ca nb_ventes
Sud 47592152.0 100109
Nord 47525498.0 99881
Centre 47373092.0 100457
Ouest 47309948.0 99758
Est 47140199.0 99795
Remarque 97
Parquet est le format de fichier columnar standard de l’écosystème data. Il compresse typiquement 5 à 10 fois mieux que CSV (grâce au stockage colonne et aux codecs Snappy/Zstd), et DuckDB peut pousser les filtres directement dans la lecture Parquet (predicate pushdown) — seules les colonnes nécessaires et les lignes satisfaisant les WHERE sont lues depuis le disque. Un fichier Parquet de 1 Go en CSV peut se réduire à 100-150 Mo.
Exemple 56
DuckDB intègre des fonctions d’agrégation statistiques rarement disponibles en SQL standard :
MEDIAN(col): médiane exacte.QUANTILE_CONT(col, 0.9): quantile continu (interpolé).CORR(x, y): coefficient de corrélation de Pearson.REGR_SLOPE(y, x)etREGR_R2(y, x): régression linéaire simple.MODE(): valeur la plus fréquente.ENTROPY(col): entropie de Shannon.
Ces fonctions permettent des analyses statistiques complètes directement en SQL, sans passer par pandas ou scipy.
Résumé#
DuckDB représente une évolution majeure dans l’outillage analytique Python : la puissance SQL complète (fenêtrage, PIVOT, statistiques) appliquée à des données locales — DataFrames, Parquet, CSV — sans serveur et avec les performances d’une base OLAP.
Remarque 98
Les points clés à retenir :
DuckDB est une base OLAP embarquée : stockage columnar, exécution vectorisée, multi-thread — aucun serveur requis.
Il lit nativement CSV, Parquet et JSON en SQL, avec predicate pushdown pour ne lire que les données nécessaires.
duckdb.register('nom', df)ou l’interpolation directe du nom de variable Python permettent d’interroger des DataFrames sans copie.DuckDB est plus rapide que pandas pour les agrégations GROUP BY et les window functions sur de grandes tables.
QUALIFYfiltre après les window functions ;PIVOT/UNPIVOTcroise les dimensions ;ASOF JOINjoint par proximité temporelle.Parquet est le format de stockage recommandé : compression 5-10x, lecture partielle (predicate pushdown), interopérable avec Spark, Arrow, Polars.