Agrégation et groupement#
Les requêtes vues jusqu’ici retournent des lignes individuelles. L’agrégation change de perspective : elle résume un ensemble de lignes en une seule valeur. C’est le fondement des rapports, tableaux de bord et analyses statistiques.
Fonctions d’agrégat#
Définition 55
Une fonction d’agrégat prend en entrée un ensemble de valeurs (une colonne sur plusieurs lignes) et retourne une valeur scalaire unique : un compte, une somme, une moyenne, un extremum ou une concaténation.
Les fonctions d’agrégat standard SQL sont :
Fonction |
Rôle |
Ignore NULL ? |
|---|---|---|
|
Nombre de lignes |
Non |
|
Nombre de valeurs non nulles |
Oui |
|
Somme |
Oui |
|
Moyenne arithmétique |
Oui |
|
Valeur minimale |
Oui |
|
Valeur maximale |
Oui |
|
Concaténation (SQLite) |
Oui |
Remarque 20
COUNT(*) compte toutes les lignes, y compris celles avec des NULL. COUNT(colonne) ne compte que les lignes où la colonne est non nulle. Ces deux formes donnent donc des résultats différents dès qu’il y a des valeurs manquantes.
Créons le jeu de données qui servira tout au long du chapitre.
conn = sqlite3.connect(":memory:")
conn.executescript("""
CREATE TABLE departements (
id INTEGER PRIMARY KEY,
nom TEXT NOT NULL
);
CREATE TABLE employes (
id INTEGER PRIMARY KEY,
nom TEXT NOT NULL,
departement INTEGER REFERENCES departements(id),
salaire REAL,
annee_entree INTEGER
);
CREATE TABLE ventes (
id INTEGER PRIMARY KEY,
employe_id INTEGER REFERENCES employes(id),
montant REAL NOT NULL,
trimestre INTEGER NOT NULL,
annee INTEGER NOT NULL
);
INSERT INTO departements VALUES
(1,'Informatique'),(2,'Marketing'),(3,'Finance'),(4,'RH');
INSERT INTO employes VALUES
(1,'Alice', 1, 62000, 2018),
(2,'Bob', 1, 58000, 2020),
(3,'Carla', 2, 52000, 2019),
(4,'David', 2, 49000, 2021),
(5,'Eva', 3, 71000, 2017),
(6,'Fabien', 3, 68000, 2019),
(7,'Gina', 4, 45000, 2022),
(8,'Hugo', 1, 55000, 2021),
(9,'Iris', NULL, NULL, 2023); -- salaire inconnu, dept inconnu
INSERT INTO ventes VALUES
(1,1,12400,1,2024),(2,1,15200,2,2024),(3,1,11000,3,2024),
(4,2, 9800,1,2024),(5,2,10500,2,2024),
(6,3,22000,1,2024),(7,3,19500,2,2024),(8,3,21000,3,2024),
(9,4,17000,1,2024),(10,4,14000,2,2024),
(11,5,31000,1,2024),(12,5,28500,2,2024),(13,5,33000,3,2024),
(14,6,26000,1,2024),(15,6,29000,2,2024),
(16,7, 5000,1,2024),(17,7, 6200,2,2024),
(18,8,13000,1,2024),(19,8,11500,3,2024);
""")
# Vérification des tables
pd.read_sql("SELECT * FROM employes", conn)
| id | nom | departement | salaire | annee_entree | |
|---|---|---|---|---|---|
| 0 | 1 | Alice | 1.0 | 62000.0 | 2018 |
| 1 | 2 | Bob | 1.0 | 58000.0 | 2020 |
| 2 | 3 | Carla | 2.0 | 52000.0 | 2019 |
| 3 | 4 | David | 2.0 | 49000.0 | 2021 |
| 4 | 5 | Eva | 3.0 | 71000.0 | 2017 |
| 5 | 6 | Fabien | 3.0 | 68000.0 | 2019 |
| 6 | 7 | Gina | 4.0 | 45000.0 | 2022 |
| 7 | 8 | Hugo | 1.0 | 55000.0 | 2021 |
| 8 | 9 | Iris | NaN | NaN | 2023 |
# Fonctions d'agrégat simples sur la table employes
pd.read_sql("""
SELECT
COUNT(*) AS nb_lignes,
COUNT(salaire) AS nb_salaires_renseignes,
ROUND(AVG(salaire),2) AS salaire_moyen,
MIN(salaire) AS salaire_min,
MAX(salaire) AS salaire_max,
ROUND(SUM(salaire),2) AS masse_salariale
FROM employes
""", conn)
| nb_lignes | nb_salaires_renseignes | salaire_moyen | salaire_min | salaire_max | masse_salariale | |
|---|---|---|---|---|---|---|
| 0 | 9 | 8 | 57500.0 | 45000.0 | 71000.0 | 460000.0 |
Exemple 16
GROUP_CONCAT permet d’agréger des chaînes. On peut personnaliser le séparateur avec un second argument.
pd.read_sql("""
SELECT
d.nom AS departement,
GROUP_CONCAT(e.nom, ', ') AS membres
FROM employes e
JOIN departements d ON e.departement = d.id
GROUP BY d.id, d.nom
ORDER BY d.nom
""", conn)
| departement | membres | |
|---|---|---|
| 0 | Finance | Eva, Fabien |
| 1 | Informatique | Alice, Bob, Hugo |
| 2 | Marketing | Carla, David |
| 3 | RH | Gina |
GROUP BY — regrouper les lignes#
Définition 56
La clause GROUP BY divise les lignes d’une table en groupes partageant les mêmes valeurs pour les colonnes spécifiées. Chaque groupe est ensuite réduit à une seule ligne par les fonctions d’agrégat.
La règle fondamentale est la suivante :
Théorème 1
Dans une requête avec GROUP BY, toute colonne du SELECT doit être soit :
une colonne listée dans le
GROUP BY,soit le résultat d’une fonction d’agrégat.
Toute autre colonne référencée dans le SELECT est une erreur logique (résultat non déterministe).
# Statistiques par département
pd.read_sql("""
SELECT
d.nom AS departement,
COUNT(e.id) AS nb_employes,
ROUND(AVG(e.salaire), 2) AS salaire_moyen,
MIN(e.salaire) AS salaire_min,
MAX(e.salaire) AS salaire_max,
ROUND(SUM(e.salaire), 2) AS masse_salariale
FROM departements d
LEFT JOIN employes e ON e.departement = d.id
GROUP BY d.id, d.nom
ORDER BY masse_salariale DESC
""", conn)
| departement | nb_employes | salaire_moyen | salaire_min | salaire_max | masse_salariale | |
|---|---|---|---|---|---|---|
| 0 | Informatique | 3 | 58333.33 | 55000.0 | 62000.0 | 175000.0 |
| 1 | Finance | 2 | 69500.00 | 68000.0 | 71000.0 | 139000.0 |
| 2 | Marketing | 2 | 50500.00 | 49000.0 | 52000.0 | 101000.0 |
| 3 | RH | 1 | 45000.00 | 45000.0 | 45000.0 | 45000.0 |
Remarque 21
On peut grouper sur plusieurs colonnes simultanément. Le groupe est alors défini par la combinaison unique de valeurs de toutes les colonnes listées dans GROUP BY.
# Ventes totales par employé et par trimestre
pd.read_sql("""
SELECT
e.nom AS employe,
v.trimestre,
ROUND(SUM(v.montant), 2) AS total_ventes
FROM ventes v
JOIN employes e ON v.employe_id = e.id
GROUP BY e.id, e.nom, v.trimestre
ORDER BY e.nom, v.trimestre
""", conn)
| employe | trimestre | total_ventes | |
|---|---|---|---|
| 0 | Alice | 1 | 12400.0 |
| 1 | Alice | 2 | 15200.0 |
| 2 | Alice | 3 | 11000.0 |
| 3 | Bob | 1 | 9800.0 |
| 4 | Bob | 2 | 10500.0 |
| 5 | Carla | 1 | 22000.0 |
| 6 | Carla | 2 | 19500.0 |
| 7 | Carla | 3 | 21000.0 |
| 8 | David | 1 | 17000.0 |
| 9 | David | 2 | 14000.0 |
| 10 | Eva | 1 | 31000.0 |
| 11 | Eva | 2 | 28500.0 |
| 12 | Eva | 3 | 33000.0 |
| 13 | Fabien | 1 | 26000.0 |
| 14 | Fabien | 2 | 29000.0 |
| 15 | Gina | 1 | 5000.0 |
| 16 | Gina | 2 | 6200.0 |
| 17 | Hugo | 1 | 13000.0 |
| 18 | Hugo | 3 | 11500.0 |
HAVING — filtrer les groupes#
Définition 57
La clause HAVING filtre les groupes après que GROUP BY les a formés. Elle s’applique donc sur des valeurs agrégées, contrairement à WHERE qui filtre les lignes individuelles avant tout regroupement.
Théorème 2
Ordre d’exécution logique d’une requête SQL :
FROM/JOIN— constitution des données sourcesWHERE— filtrage des lignes individuellesGROUP BY— regroupementCalcul des fonctions d’agrégat
HAVING— filtrage des groupesSELECT— projection des colonnesORDER BY— triLIMIT/OFFSET— pagination
WHERE ne peut donc pas référencer une valeur agrégée ; c’est le rôle de HAVING.
# Départements dont la masse salariale dépasse 120 000 €
pd.read_sql("""
SELECT
d.nom AS departement,
COUNT(e.id) AS nb_employes,
ROUND(SUM(e.salaire), 2) AS masse_salariale
FROM departements d
JOIN employes e ON e.departement = d.id
GROUP BY d.id, d.nom
HAVING SUM(e.salaire) > 120000
ORDER BY masse_salariale DESC
""", conn)
| departement | nb_employes | masse_salariale | |
|---|---|---|---|
| 0 | Informatique | 3 | 175000.0 |
| 1 | Finance | 2 | 139000.0 |
Exemple 17
Pour ne conserver que les employés ayant réalisé au moins 3 ventes distinctes, on utilise HAVING COUNT(...) >= 3.
pd.read_sql("""
SELECT
e.nom AS employe,
COUNT(v.id) AS nb_ventes,
ROUND(SUM(v.montant), 2) AS total
FROM ventes v
JOIN employes e ON v.employe_id = e.id
GROUP BY e.id, e.nom
HAVING COUNT(v.id) >= 3
ORDER BY total DESC
""", conn)
| employe | nb_ventes | total | |
|---|---|---|---|
| 0 | Eva | 3 | 92500.0 |
| 1 | Carla | 3 | 62500.0 |
| 2 | Alice | 3 | 38600.0 |
Différence WHERE vs HAVING#
Remarque 22
Une confusion fréquente consiste à utiliser HAVING à la place de WHERE pour filtrer sur des colonnes non agrégées. Si le filtre ne porte pas sur une agrégation, préférez WHERE : le moteur peut alors éliminer des lignes avant le regroupement, ce qui est plus efficace.
# WHERE filtre avant le GROUP BY (plus efficace)
pd.read_sql("""
SELECT
d.nom AS departement,
ROUND(AVG(e.salaire), 2) AS salaire_moyen
FROM employes e
JOIN departements d ON e.departement = d.id
WHERE e.annee_entree >= 2019 -- filtre sur ligne individuelle
GROUP BY d.id, d.nom
HAVING AVG(e.salaire) > 50000 -- filtre sur le groupe
ORDER BY salaire_moyen DESC
""", conn)
| departement | salaire_moyen | |
|---|---|---|
| 0 | Finance | 68000.0 |
| 1 | Informatique | 56500.0 |
| 2 | Marketing | 50500.0 |
Définition 58
Il est courant de combiner WHERE et HAVING dans la même requête : WHERE réduit le volume de données en amont, puis HAVING affine les groupes résultants. Les deux clauses jouent des rôles complémentaires.
NULL dans les agrégats#
Remarque 23
Toutes les fonctions d’agrégat (sauf COUNT(*)) ignorent automatiquement les NULL. Cela signifie que AVG(salaire) calcule la moyenne sur les seules valeurs connues, et non en comptant les NULL comme zéro. Ce comportement est conforme au standard SQL.
# Iris a salaire = NULL et departement = NULL
# COUNT(*) = 9, COUNT(salaire) = 8
pd.read_sql("""
SELECT
COUNT(*) AS nb_total,
COUNT(salaire) AS nb_avec_salaire,
COUNT(departement) AS nb_avec_dept,
ROUND(AVG(salaire), 2) AS moyenne_salaire
FROM employes
""", conn)
| nb_total | nb_avec_salaire | nb_avec_dept | moyenne_salaire | |
|---|---|---|---|---|
| 0 | 9 | 8 | 8 | 57500.0 |
Exemple 18
Pour traiter les NULL comme zéro dans une somme, utiliser COALESCE(colonne, 0) avant d’agréger. Mais attention : cela change la sémantique de la requête (valeur inconnue ≠ zéro).
pd.read_sql("""
SELECT
SUM(salaire) AS somme_sans_null,
SUM(COALESCE(salaire, 0)) AS somme_avec_zero
FROM employes
""", conn)
| somme_sans_null | somme_avec_zero | |
|---|---|---|
| 0 | 460000.0 | 460000.0 |
ROLLUP et totaux croisés#
Remarque 24
GROUP BY ROLLUP(...) est une extension SQL permettant de produire des sous-totaux automatiques à chaque niveau de regroupement. SQLite ne supporte pas ROLLUP. On peut en simuler l’effet avec UNION ALL en ajoutant une ligne de total global, ou utiliser PostgreSQL/MySQL/SQL Server qui l’implémentent nativement.
Exemple 19
Simulation d’un ROLLUP sur (département, employé) avec UNION ALL en SQLite.
# Simulation ROLLUP : total par département + total global
pd.read_sql("""
-- Sous-total par département
SELECT d.nom AS departement, ROUND(SUM(v.montant),2) AS total_ventes
FROM ventes v
JOIN employes e ON v.employe_id = e.id
JOIN departements d ON e.departement = d.id
GROUP BY d.id, d.nom
UNION ALL
-- Total global (simulant la ligne ROLLUP de niveau supérieur)
SELECT 'TOTAL' AS departement, ROUND(SUM(montant),2)
FROM ventes
ORDER BY departement
""", conn)
| departement | total_ventes | |
|---|---|---|
| 0 | Finance | 147500.0 |
| 1 | Informatique | 83400.0 |
| 2 | Marketing | 93500.0 |
| 3 | RH | 11200.0 |
| 4 | TOTAL | 335600.0 |
Remarque 25
En PostgreSQL, la syntaxe native est :
GROUP BY ROLLUP(departement, employe) et génère automatiquement les lignes de sous-totaux intermédiaires et la ligne grand-total.
Visualisation des agrégats#
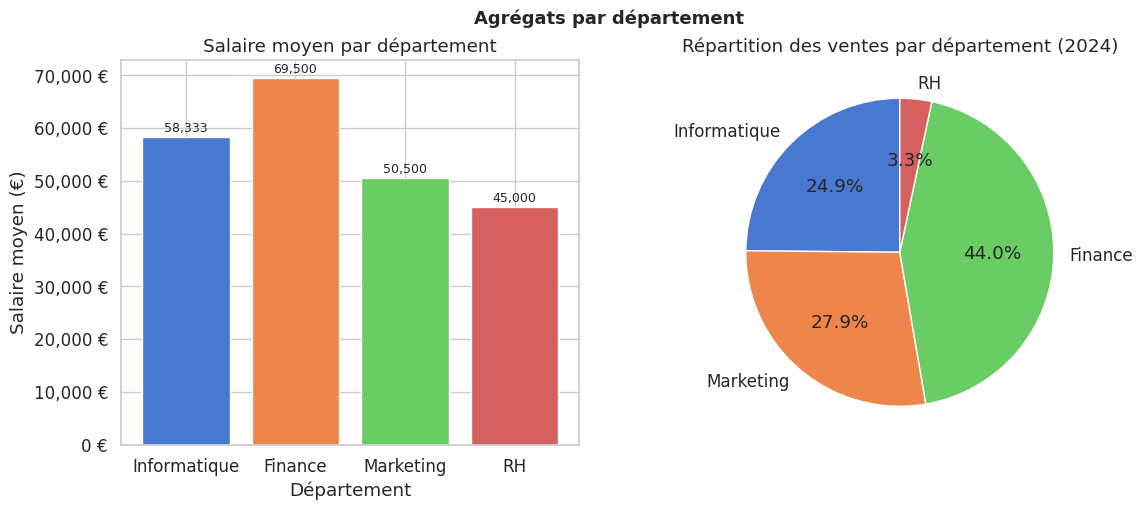
Remarque 26
La visualisation confirme que le département Finance concentre la majorité du chiffre d’affaires, tandis que les RH contribuent très peu aux ventes — ce qui est cohérent avec leurs rôles respectifs.
Résumé#
Définition 59
Récapitulatif des clauses d’agrégation :
COUNT,SUM,AVG,MIN,MAX,GROUP_CONCATrésument un ensemble de lignes en une valeur.GROUP BYpartitionne les lignes en groupes homogènes.HAVINGfiltre les groupes formés (équivalent deWHEREpour les agrégats).Les NULL sont ignorés par toutes les fonctions d’agrégat sauf
COUNT(*).ROLLUP(non supporté en SQLite) produit des sous-totaux automatiques.Préférer
WHEREpour les filtres pré-agrégation ; réserverHAVINGaux conditions sur valeurs agrégées.
Clause |
Moment d’application |
Sur quoi ? |
|---|---|---|
|
Avant |
Lignes individuelles |
|
Après |
Colonnes de regroupement |
|
Après |
Valeurs agrégées |
|
En dernier |
Tout (colonnes ou agrégats) |