Algorithmes sur les chaînes de caractères#
Introduction#
Les chaînes de caractères sont omniprésentes en informatique : moteurs de recherche, éditeurs de texte, outils bioinformatiques, détecteurs de plagiat, compilateurs, protocoles réseau. La recherche de motifs (pattern matching) — trouver toutes les occurrences d’un motif P de longueur m dans un texte T de longueur n — est l’opération fondamentale de ce domaine. Sa complexité peut varier de O(nm) pour l’approche naïve à O(n+m) pour les algorithmes sophistiqués que nous étudierons dans ce chapitre.
Définition 95 (Problème de recherche de motifs)
Étant donné un texte T[0..n-1] et un motif P[0..m-1] sur un alphabet Σ, le problème de recherche de motifs consiste à trouver toutes les positions i telles que T[i..i+m-1] = P. On appelle ces positions les occurrences du motif dans le texte.
Dans ce chapitre, nous étudierons les principaux algorithmes de recherche de motifs, leurs fondements théoriques et leurs domaines d’application.
Recherche naïve#
L’algorithme de recherche naïve est le plus simple : pour chaque position i du texte, on compare le motif avec le sous-texte T[i..i+m-1] caractère par caractère.
def recherche_naive(texte, motif):
"""
Recherche naïve : O(n·m) dans le pire cas.
Retourne la liste des positions de début des occurrences.
"""
n, m = len(texte), len(motif)
occurrences = []
comparaisons = 0
for i in range(n - m + 1):
j = 0
while j < m and texte[i + j] == motif[j]:
comparaisons += 1
j += 1
if j < m:
comparaisons += 1 # La comparaison qui a échoué
if j == m:
occurrences.append(i)
return occurrences, comparaisons
# Exemple simple
texte = "AABAACAADAABAABA"
motif = "AABA"
occ, cmp = recherche_naive(texte, motif)
print(f"Texte : '{texte}'")
print(f"Motif : '{motif}'")
print(f"Occurrences : {occ}")
print(f"Comparaisons : {cmp}")
# Pire cas : texte = "AAAA...A", motif = "AAAB"
print("\n--- Pire cas ---")
n = 100
texte_pire = 'A' * n
motif_pire = 'A' * 10 + 'B'
occ_pire, cmp_pire = recherche_naive(texte_pire, motif_pire)
print(f"Texte de {n} 'A', motif 'A'*10+'B' : {cmp_pire} comparaisons (attendu ≈ {n * 11})")
Texte : 'AABAACAADAABAABA'
Motif : 'AABA'
Occurrences : [0, 9, 12]
Comparaisons : 30
--- Pire cas ---
Texte de 100 'A', motif 'A'*10+'B' : 990 comparaisons (attendu ≈ 1100)
Remarque 42
Analyse de complexité. Dans le pire cas (texte et motif composés du même caractère répété, sauf le dernier), l’algorithme naïf effectue (n - m + 1) · m comparaisons, soit O(nm). Ce pire cas est atteint par exemple avec T = "AAAA...A" et P = "AAA...AB". Dans la pratique, pour des textes en langue naturelle et des motifs courts, la complexité est proche de O(n) car les premières comparaisons échouent rapidement.
Algorithme de Knuth-Morris-Pratt (KMP)#
L’algorithme KMP (1977) est la première amélioration fondamentale de la recherche naïve. Son idée clé : lorsqu’une correspondance partielle échoue, ne pas repartir de zéro, mais réutiliser l’information accumulée lors de la correspondance partielle.
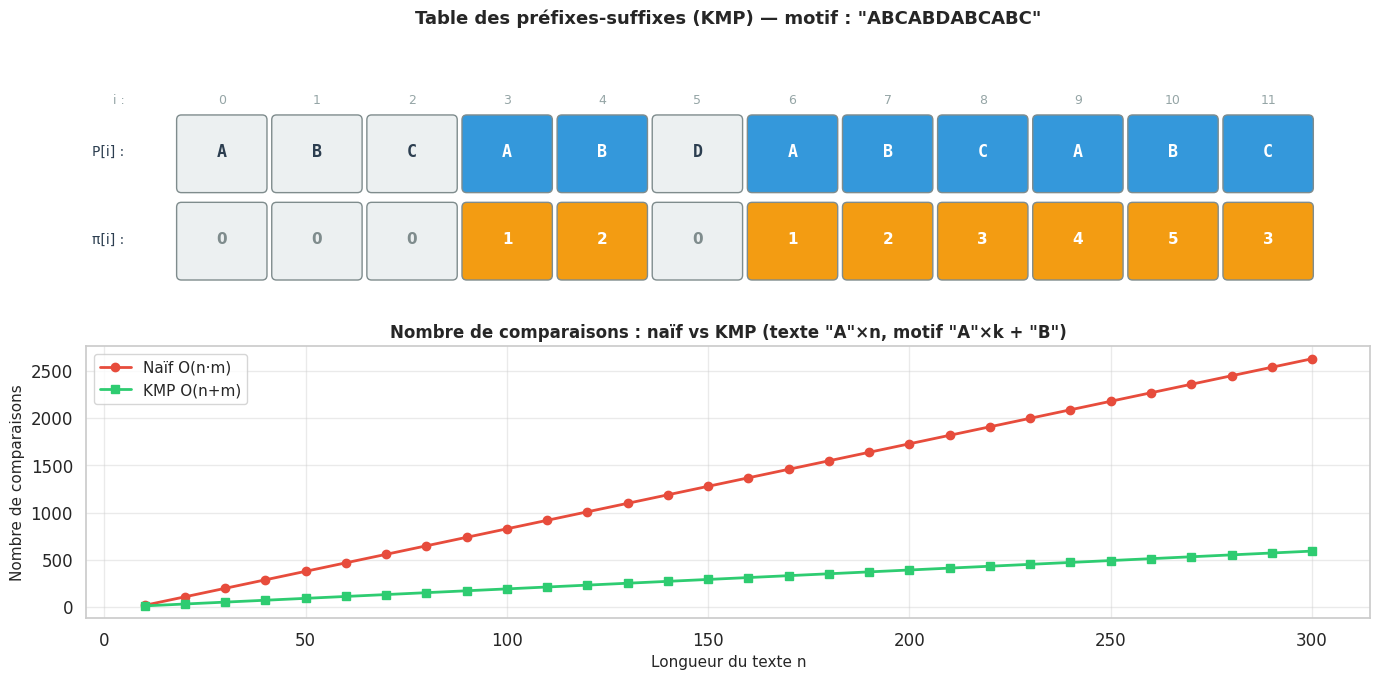
Définition 96 (Table des préfixes-suffixes (failure function))
La table des préfixes-suffixes pi d’un motif P[0..m-1] est définie par :
pi[i] = longueur du plus long préfixe propre de P[0..i] qui soit aussi un suffixe de P[0..i].
Par convention, pi[0] = 0. Cette table encode la structure interne du motif et permet, lors d’un échec à la position j, de sauter directement à la position pi[j-1] dans le motif plutôt que de revenir à 0.
def construire_table_kmp(motif):
"""
Construit la table des préfixes-suffixes (failure function) de KMP.
Complexité : O(m)
"""
m = len(motif)
pi = [0] * m
k = 0 # longueur du plus long préfixe-suffixe courant
for i in range(1, m):
# Réduire k jusqu'à trouver une correspondance ou k=0
while k > 0 and motif[k] != motif[i]:
k = pi[k - 1]
if motif[k] == motif[i]:
k += 1
pi[i] = k
return pi
def kmp_recherche(texte, motif):
"""
Algorithme de Knuth-Morris-Pratt. Complexité : O(n + m).
Retourne la liste des positions d'occurrence.
"""
n, m = len(texte), len(motif)
if m == 0:
return list(range(n + 1)), 0
pi = construire_table_kmp(motif)
occurrences = []
comparaisons = 0
q = 0 # nombre de caractères correspondants
for i in range(n):
comparaisons += 1
while q > 0 and motif[q] != texte[i]:
q = pi[q - 1]
comparaisons += 1
if motif[q] == texte[i]:
q += 1
if q == m:
occurrences.append(i - m + 1)
q = pi[q - 1]
return occurrences, comparaisons
# Démonstration de la table KMP
motifs_test = ["AAAB", "ABCABD", "AABAABAAB", "ABAB"]
for m in motifs_test:
pi = construire_table_kmp(m)
print(f"Motif : {m}")
print(f" pi : {pi}")
print()
# Comparaison naïf vs KMP
texte = "AABAACAADAABAABA"
motif = "AABA"
occ_kmp, cmp_kmp = kmp_recherche(texte, motif)
occ_nv, cmp_nv = recherche_naive(texte, motif)
print(f"Texte : '{texte}', motif : '{motif}'")
print(f"Naïf : {cmp_nv} comparaisons → {occ_nv}")
print(f"KMP : {cmp_kmp} comparaisons → {occ_kmp}")
Motif : AAAB
pi : [0, 1, 2, 0]
Motif : ABCABD
pi : [0, 0, 0, 1, 2, 0]
Motif : AABAABAAB
pi : [0, 1, 0, 1, 2, 3, 4, 5, 6]
Motif : ABAB
pi : [0, 0, 1, 2]
Texte : 'AABAACAADAABAABA', motif : 'AABA'
Naïf : 30 comparaisons → [0, 9, 12]
KMP : 20 comparaisons → [0, 9, 12]
Remarque 43
Analyse de la complexité de KMP. La construction de la table pi nécessite O(m) temps. La phase de recherche effectue au plus 2n comparaisons : on peut le montrer par un argument de potentiel — la valeur q (position dans le motif) ne peut augmenter que n fois au total (une fois par caractère du texte), et la somme totale des diminutions de q (via pi) est bornée par le total des augmentations. L’algorithme est donc O(n+m) temps et O(m) espace.
Algorithme de Rabin-Karp#
L’algorithme de Rabin-Karp (1987) adopte une approche radicalement différente : il calcule une empreinte (hash) du motif et compare cette empreinte avec celles des sous-chaînes successives du texte. La clé est de recalculer l’empreinte de chaque fenêtre glissante en O(1) grâce à un hachage glissant.
Définition 97 (Hachage glissant (rolling hash))
Pour un texte T et une fenêtre de taille m, le hachage glissant permet de calculer l’empreinte de T[i+1..i+m] à partir de celle de T[i..i+m-1] en O(1).
Avec un polynôme de hachage de base b et module q :
h(T[i..i+m-1]) = (T[i]·b^{m-1} + T[i+1]·b^{m-2} + ... + T[i+m-1]) mod q
La mise à jour glissante est :
h(T[i+1..i+m]) = (b·(h(T[i..i+m-1]) - T[i]·b^{m-1}) + T[i+m]) mod q
def rabin_karp(texte, motif, base=256, modulo=101):
"""
Algorithme de Rabin-Karp.
Complexité : O(n+m) en moyenne, O(nm) dans le pire cas (nombreuses collisions).
"""
n, m = len(texte), len(motif)
if m > n:
return [], 0
occurrences = []
comparaisons = 0
# Puissance b^(m-1) mod q
h_puissance = pow(base, m - 1, modulo)
# Calcul des empreintes initiales
hash_motif = 0
hash_texte = 0
for i in range(m):
hash_motif = (base * hash_motif + ord(motif[i])) % modulo
hash_texte = (base * hash_texte + ord(texte[i])) % modulo
for i in range(n - m + 1):
comparaisons += 1 # Comparaison des hash
if hash_motif == hash_texte:
# Vérification caractère par caractère (éviter les faux positifs)
match = True
for j in range(m):
comparaisons += 1
if texte[i + j] != motif[j]:
match = False
break
if match:
occurrences.append(i)
# Mise à jour glissante du hash
if i < n - m:
hash_texte = (base * (hash_texte - ord(texte[i]) * h_puissance) + ord(texte[i + m])) % modulo
hash_texte = (hash_texte + modulo) % modulo # Garantir la positivité
return occurrences, comparaisons
# Test
texte = "GEEKS FOR GEEKS"
motif = "GEEKS"
occ, cmp = rabin_karp(texte, motif)
print(f"Texte : '{texte}', motif : '{motif}'")
print(f"Occurrences : {occ}")
print(f"Comparaisons : {cmp}")
# Comparaison des trois algorithmes sur un texte long
import time
random.seed(42)
texte_long = ''.join(random.choices('ACGT', k=10000)) # ADN simulé
motif_test = 'ACGTACGT'
t0 = time.perf_counter()
occ_nv, cmp_nv = recherche_naive(texte_long, motif_test)
t_nv = time.perf_counter() - t0
t0 = time.perf_counter()
occ_kmp, cmp_kmp = kmp_recherche(texte_long, motif_test)
t_kmp = time.perf_counter() - t0
t0 = time.perf_counter()
occ_rk, cmp_rk = rabin_karp(texte_long, motif_test)
t_rk = time.perf_counter() - t0
print(f"\nTexte ADN ({len(texte_long)} bases), motif '{motif_test}' ({len(motif_test)} bases)")
print(f" Naïf : {cmp_nv:6d} comparaisons, {t_nv*1000:.2f} ms, {len(occ_nv)} occurrences")
print(f" KMP : {cmp_kmp:6d} comparaisons, {t_kmp*1000:.2f} ms, {len(occ_kmp)} occurrences")
print(f" R-K : {cmp_rk:6d} comparaisons, {t_rk*1000:.2f} ms, {len(occ_rk)} occurrences")
Texte : 'GEEKS FOR GEEKS', motif : 'GEEKS'
Occurrences : [0, 10]
Comparaisons : 21
Texte ADN (10000 bases), motif 'ACGTACGT' (8 bases)
Naïf : 13266 comparaisons, 2.39 ms, 0 occurrences
KMP : 12480 comparaisons, 1.92 ms, 0 occurrences
R-K : 10112 comparaisons, 3.89 ms, 0 occurrences
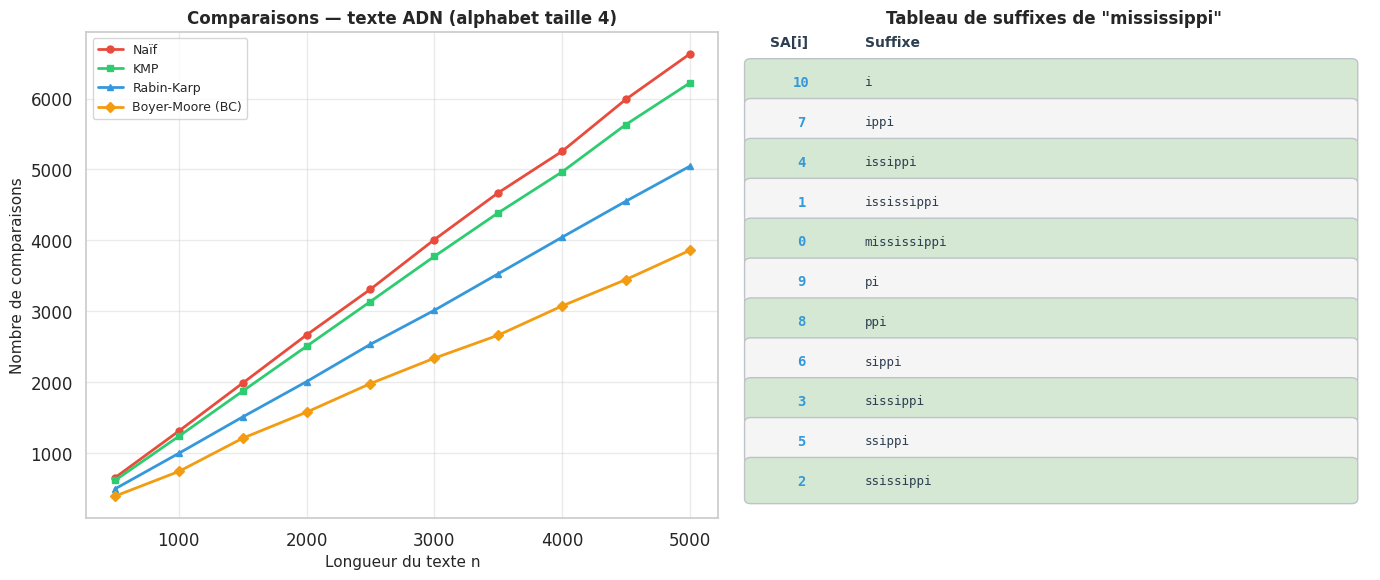
Remarque 44
Applications de Rabin-Karp. L’algorithme de Rabin-Karp brille dans deux scénarios où KMP est moins adapté :
Recherche de plusieurs motifs simultanément. On calcule les empreintes de tous les motifs et on les stocke dans une table de hachage. À chaque fenêtre glissante, une seule comparaison d’empreinte suffit pour tester tous les motifs en O(1). C’est la base des détecteurs de plagiat (MOSS, JPlag) qui recherchent de nombreux fragments de code simultanément.
Recherche bidimensionnelle. L’empreinte peut s’étendre à des matrices, permettant de rechercher un sous-tableau 2D dans un tableau 2D — application en traitement d’images.
Algorithme de Boyer-Moore#
L’algorithme de Boyer-Moore (1977) est en pratique le plus rapide pour la recherche de motifs, notamment pour des alphabets de grande taille (textes en langue naturelle). Contrairement à KMP et Rabin-Karp qui progressent de gauche à droite dans le motif, Boyer-Moore compare le motif de droite à gauche et utilise deux heuristiques pour effectuer des sauts importants.
Définition 98 (Heuristiques de Boyer-Moore)
Heuristique du mauvais caractère (bad character rule) : lors d’un désalignement entre P[j] et T[i+j], si le caractère T[i+j] n’apparaît pas dans P[0..j-1], on peut décaler le motif entièrement au-delà de T[i+j]. Sinon, on aligne la dernière occurrence de T[i+j] dans le motif avec T[i+j].
Heuristique du bon suffixe (good suffix rule) : si on a réussi à faire correspondre P[j+1..m-1] avec T[i+j+1..i+m-1] avant l’échec en j, on cherche la prochaine occurrence de ce suffixe dans le motif et on décale en conséquence.
Le décalage appliqué est le maximum des deux heuristiques.
def boyer_moore_bad_char(texte, motif):
"""
Implémentation simplifiée de Boyer-Moore (heuristique du mauvais caractère uniquement).
Sous-optimale mais illustrative.
"""
n, m = len(texte), len(motif)
occurrences = []
comparaisons = 0
# Table du mauvais caractère : dernière occurrence de chaque caractère dans le motif
bad_char = {}
for i, c in enumerate(motif):
bad_char[c] = i
s = 0 # décalage courant
while s <= n - m:
j = m - 1 # comparaison de droite à gauche
while j >= 0 and motif[j] == texte[s + j]:
comparaisons += 1
j -= 1
if j < 0:
occurrences.append(s)
# Décalage selon le bon suffixe ou la fin du texte
saut = m - bad_char.get(texte[s + m], -1) if s + m < n else 1
s += max(1, saut)
else:
comparaisons += 1
# Décalage selon le mauvais caractère
saut = j - bad_char.get(texte[s + j], -1)
s += max(1, saut)
return occurrences, comparaisons
# Test et comparaison
texte = "ABAAABCD"
motif = "ABC"
occ_bm, cmp_bm = boyer_moore_bad_char(texte, motif)
occ_kmp2, cmp_kmp2 = kmp_recherche(texte, motif)
print(f"Boyer-Moore : {occ_bm} ({cmp_bm} comparaisons)")
print(f"KMP : {occ_kmp2} ({cmp_kmp2} comparaisons)")
Boyer-Moore : [4] (5 comparaisons)
KMP : [4] (11 comparaisons)
Tri de suffixes#
Le tableau de suffixes (suffix array) est une structure de données permettant des requêtes de recherche de motifs extrêmement efficaces une fois le texte prétraité. Il est particulièrement utile en bioinformatique, pour l’indexation de textes, et pour calculer la plus longue sous-chaîne commune entre deux textes.
Définition 99 (Tableau de suffixes)
Le tableau de suffixes SA d’un texte T[0..n-1] est le tableau des indices de départ de tous les suffixes de T, triés par ordre lexicographique.
Par exemple, pour T = "banana" :
Suffixes : banana, anana, nana, ana, na, a
Triés : a, ana, anana, banana, na, nana
SA = [5, 3, 1, 0, 4, 2]
Une fois SA construit, on peut rechercher un motif P par recherche binaire en O(m log n), et avec le tableau LCP (Longest Common Prefix), en O(m + log n).
def construire_suffix_array_naive(texte):
"""Construction naïve du tableau de suffixes. Complexité O(n² log n)."""
n = len(texte)
suffixes = [(texte[i:], i) for i in range(n)]
suffixes.sort(key=lambda x: x[0])
return [i for _, i in suffixes]
def construire_lcp_array(texte, sa):
"""
Construction du tableau LCP (Longest Common Prefix) par l'algorithme de Kasai.
Complexité O(n).
"""
n = len(texte)
rank = [0] * n
for i, suffix_idx in enumerate(sa):
rank[suffix_idx] = i
lcp = [0] * n
k = 0
for i in range(n):
if rank[i] == n - 1:
k = 0
continue
j = sa[rank[i] + 1]
while i + k < n and j + k < n and texte[i + k] == texte[j + k]:
k += 1
lcp[rank[i]] = k
if k > 0:
k -= 1
return lcp
def recherche_suffix_array(texte, motif, sa):
"""
Recherche d'un motif par recherche binaire sur le tableau de suffixes. O(m log n).
"""
n, m = len(texte), len(motif)
# Borne inférieure : première position où motif <= suffixe
lo, hi = 0, n
while lo < hi:
mid = (lo + hi) // 2
if texte[sa[mid]:sa[mid]+m] < motif:
lo = mid + 1
else:
hi = mid
debut = lo
# Borne supérieure
lo, hi = debut, n
while lo < hi:
mid = (lo + hi) // 2
if texte[sa[mid]:sa[mid]+m] <= motif and texte[sa[mid]:sa[mid]+m] != motif or \
texte[sa[mid]:sa[mid]+m] > motif:
hi = mid
else:
lo = mid + 1
return sorted(sa[debut:lo])
# Démonstration
texte_demo = "banana"
sa = construire_suffix_array_naive(texte_demo)
lcp = construire_lcp_array(texte_demo, sa)
print(f"Texte : '{texte_demo}'")
print(f"\n{'Rang':>4} {'SA[i]':>5} {'LCP':>5} {'Suffixe'}")
print("-" * 35)
for i, (sa_i, lcp_i) in enumerate(zip(sa, lcp)):
print(f"{i:>4} {sa_i:>5} {lcp_i:>5} {texte_demo[sa_i:]}")
# Application : recherche
for motif in ['ana', 'an', 'na']:
occ = recherche_suffix_array(texte_demo, motif, sa)
print(f"\nMotif '{motif}' → occurrences : {occ}")
Texte : 'banana'
Rang SA[i] LCP Suffixe
-----------------------------------
0 5 1 a
1 3 3 ana
2 1 0 anana
3 0 0 banana
4 4 2 na
5 2 0 nana
Motif 'ana' → occurrences : [1, 3]
Motif 'an' → occurrences : [1, 3]
Motif 'na' → occurrences : [2, 4]
Implémentation Rust#
/// Construit la table des préfixes-suffixes (failure function) de KMP.
pub fn construire_table_kmp(motif: &[u8]) -> Vec<usize> {
let m = motif.len();
let mut pi = vec![0usize; m];
let mut k = 0usize;
for i in 1..m {
while k > 0 && motif[k] != motif[i] {
k = pi[k - 1];
}
if motif[k] == motif[i] {
k += 1;
}
pi[i] = k;
}
pi
}
/// Recherche KMP : retourne toutes les positions d'occurrence. O(n + m).
pub fn kmp_recherche(texte: &[u8], motif: &[u8]) -> Vec<usize> {
let (n, m) = (texte.len(), motif.len());
if m == 0 || m > n {
return vec![];
}
let pi = construire_table_kmp(motif);
let mut occurrences = Vec::new();
let mut q = 0usize;
for (i, &c) in texte.iter().enumerate() {
while q > 0 && motif[q] != c {
q = pi[q - 1];
}
if motif[q] == c {
q += 1;
}
if q == m {
occurrences.push(i + 1 - m);
q = pi[q - 1];
}
}
occurrences
}
/// Hachage glissant de Rabin-Karp.
pub fn rabin_karp(texte: &[u8], motif: &[u8]) -> Vec<usize> {
const BASE: u64 = 256;
const MOD: u64 = 101;
let (n, m) = (texte.len(), motif.len());
if m > n {
return vec![];
}
let h_puissance = (0..m - 1).fold(1u64, |acc, _| (acc * BASE) % MOD);
let hash_motif = motif.iter().fold(0u64, |acc, &c| (BASE * acc + c as u64) % MOD);
let mut hash_texte = texte[..m].iter().fold(0u64, |acc, &c| (BASE * acc + c as u64) % MOD);
let mut occurrences = Vec::new();
for i in 0..=(n - m) {
if hash_motif == hash_texte && &texte[i..i + m] == motif {
occurrences.push(i);
}
if i < n - m {
hash_texte = (BASE * (hash_texte + MOD - (texte[i] as u64 * h_puissance) % MOD)
+ texte[i + m] as u64) % MOD;
}
}
occurrences
}
/// Construction naïve du tableau de suffixes. O(n² log n).
pub fn suffix_array(texte: &[u8]) -> Vec<usize> {
let n = texte.len();
let mut indices: Vec<usize> = (0..n).collect();
indices.sort_by(|&a, &b| texte[a..].cmp(&texte[b..]));
indices
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_kmp() {
let texte = b"AABAACAADAABAABA";
let motif = b"AABA";
let occ = kmp_recherche(texte, motif);
assert_eq!(occ, vec![0, 9, 12]);
}
#[test]
fn test_rabin_karp() {
let texte = b"GEEKS FOR GEEKS";
let motif = b"GEEKS";
let occ = rabin_karp(texte, motif);
assert_eq!(occ, vec![0, 10]);
}
#[test]
fn test_suffix_array() {
let texte = b"banana";
let sa = suffix_array(texte);
// Les suffixes triés : a, ana, anana, banana, na, nana
assert_eq!(sa, vec![5, 3, 1, 0, 4, 2]);
}
}
Résumé#
Dans ce chapitre, nous avons parcouru les principaux algorithmes sur les chaînes de caractères :
L”algorithme naïf effectue O(nm) comparaisons dans le pire cas — acceptable pour des textes courts mais inadapté à grande échelle.
L”algorithme KMP atteint O(n+m) grâce à la table des préfixes-suffixes
pi, qui encode la structure interne du motif et permet d’éviter tout retour arrière dans le texte.L”algorithme de Rabin-Karp utilise le hachage glissant pour atteindre O(n+m) en moyenne ; il excelle pour la recherche simultanée de multiples motifs et la détection de plagiat.
L”algorithme de Boyer-Moore est le plus rapide en pratique pour les grands alphabets, grâce à ses heuristiques du mauvais caractère et du bon suffixe qui permettent des sauts de plusieurs positions à la fois.
Le tableau de suffixes permet, après un prétraitement O(n log n), des requêtes de recherche en O(m log n) et est fondamental en bioinformatique pour l’alignement de séquences.
Dans le chapitre suivant, nous aborderons les classes de complexité : les notions de P, NP et NP-complétude qui définissent les frontières du calculable et du tractable.