Algorithmes sur les graphes#
Les graphes sont l’une des structures de données les plus puissantes et les plus polyvalentes de l’informatique. Ils modélisent des réseaux de transport, des circuits électroniques, des relations sociales, des dépendances entre tâches, des cartes géographiques et bien d’autres systèmes où des entités sont reliées par des connexions. Les algorithmes que nous étudions dans ce chapitre — Dijkstra, Bellman-Ford, Kruskal, Prim et le tri topologique — constituent le cœur de la théorie algorithmique des graphes et interviennent dans d’innombrables applications pratiques.
Nous supposons que le lecteur est familier avec les définitions de base (graphe orienté, non orienté, pondéré, connexe, cycle, chemin) présentées dans le chapitre 7. Nous nous concentrons ici sur les algorithmes qui résolvent les problèmes les plus importants : le plus court chemin, l”arbre couvrant minimal et le tri topologique.
Représentation des graphes#
class Graph:
"""
Graphe pondéré représenté par liste d'adjacence.
Supporte les graphes orientés et non orientés.
"""
def __init__(self, directed=True):
self.directed = directed
self.adj = defaultdict(list) # {nœud: [(voisin, poids), ...]}
self.nodes = set()
def add_edge(self, u, v, weight=1):
"""Ajoute une arête u -> v de poids weight."""
self.adj[u].append((v, weight))
self.nodes.add(u)
self.nodes.add(v)
if not self.directed:
self.adj[v].append((u, weight))
def add_node(self, u):
self.nodes.add(u)
if u not in self.adj:
self.adj[u] = []
def neighbors(self, u):
return self.adj[u]
def all_edges(self):
"""Retourne toutes les arêtes comme liste de (u, v, poids)."""
edges = []
for u in self.adj:
for v, w in self.adj[u]:
edges.append((u, v, w))
return edges
Algorithme de Dijkstra#
Principe et invariant#
L’algorithme de Dijkstra résout le problème du plus court chemin depuis une source unique dans un graphe pondéré à poids non négatifs.
Définition 70 (Algorithme de Dijkstra)
L”algorithme de Dijkstra maintient un ensemble S de nœuds dont la distance minimale depuis la source est définitivement connue, et une file de priorité (tas min) contenant les nœuds candidats. À chaque itération :
On extrait le nœud u de distance minimale du tas.
On le marque comme traité (ajouté à S).
Pour chaque voisin v de u, on met à jour la distance estimée : \(\mathit{dist}[v] = \min(\mathit{dist}[v], \mathit{dist}[u] + w(u, v))\).
Invariant : À chaque itération, pour tout nœud \(u \in S\), \(\mathit{dist}[u]\) est la longueur du plus court chemin depuis la source.
Complexité : O((V + E) log V) avec un tas binaire, ou O(E + V log V) avec un tas de Fibonacci.
Précondition : tous les poids doivent être non négatifs.
Remarque 31
La correction de Dijkstra repose sur le fait que, si tous les poids sont non négatifs, le premier chemin trouvé vers un nœud est nécessairement le plus court. En effet, tout autre chemin passant par des nœuds non encore traités est nécessairement plus long, car leurs distances estimées sont supérieures ou égales à celle du nœud extrait (propriété du tas min et non-négativité des poids).
Avec des poids négatifs, l’invariant est brisé : un chemin passant par un arc négatif peut être plus court même si le nœud intermédiaire a une grande distance estimée. On utilise alors Bellman-Ford.
Implémentation Python#
def dijkstra(graph, source):
"""
Algorithme de Dijkstra avec tas min (heapq).
Paramètres
----------
graph : Graph
Graphe orienté pondéré à poids non négatifs.
source : nœud
Nœud de départ.
Retourne
-------
dist : dict
dist[v] = longueur du plus court chemin source -> v
(math.inf si inaccessible).
prev : dict
prev[v] = prédécesseur de v dans le plus court chemin.
"""
dist = {node: math.inf for node in graph.nodes}
dist[source] = 0
prev = {node: None for node in graph.nodes}
# Tas min : (distance_estimée, nœud)
heap = [(0, source)]
visited = set()
while heap:
d, u = heapq.heappop(heap)
if u in visited:
continue
visited.add(u)
for v, weight in graph.neighbors(u):
if v not in visited:
new_dist = dist[u] + weight
if new_dist < dist[v]:
dist[v] = new_dist
prev[v] = u
heapq.heappush(heap, (new_dist, v))
return dist, prev
def reconstruct_path(prev, source, target):
"""Reconstruit le chemin depuis source jusqu'à target via prev."""
path = []
node = target
while node is not None:
path.append(node)
node = prev[node]
path.reverse()
if path[0] == source:
return path
return [] # Pas de chemin
# Construction d'un graphe exemple
g = Graph(directed=True)
edges = [
('A', 'B', 4), ('A', 'C', 2), ('B', 'C', 5), ('B', 'D', 10),
('C', 'E', 3), ('E', 'D', 4), ('D', 'F', 11), ('E', 'F', 7),
('B', 'E', 8),
]
for u, v, w in edges:
g.add_edge(u, v, w)
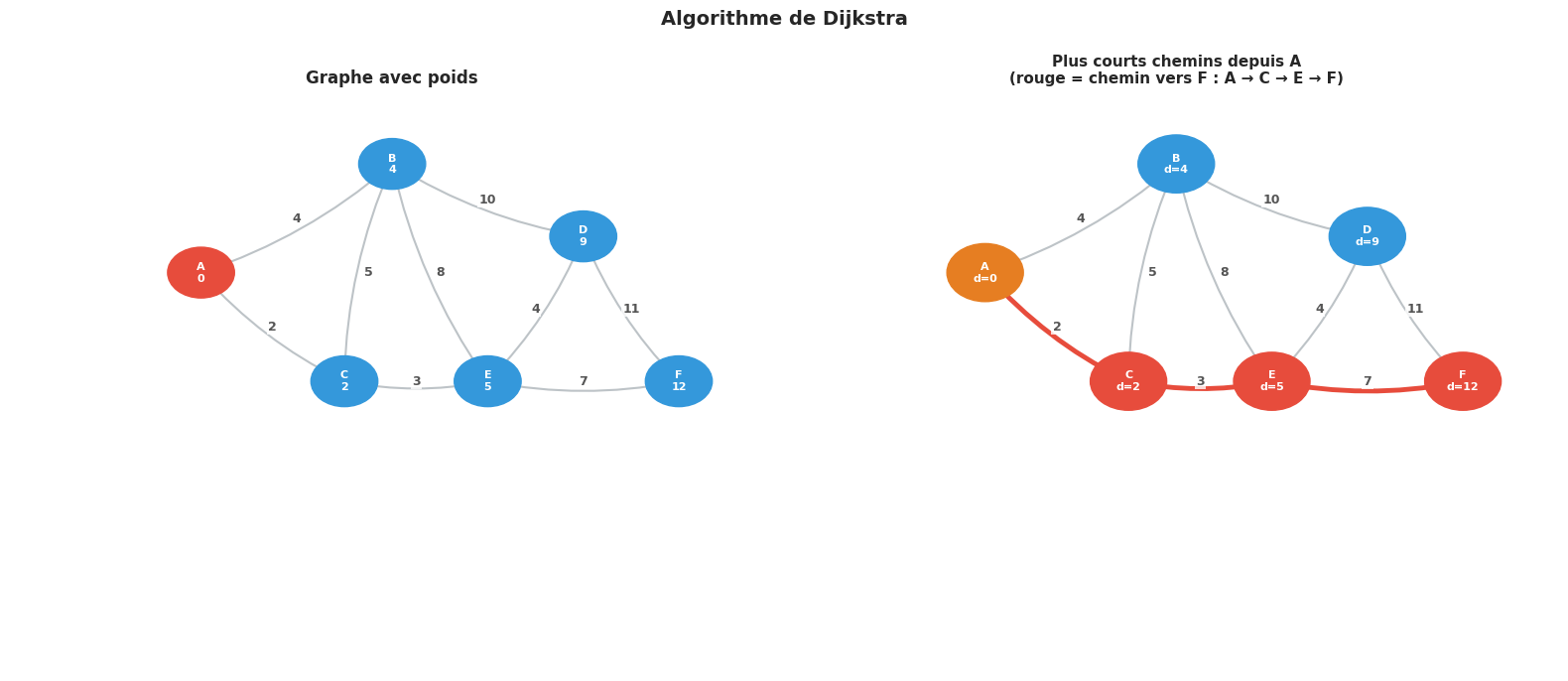
dist, prev = dijkstra(g, 'A')
print("Distances depuis A :")
for node in sorted(dist):
path = reconstruct_path(prev, 'A', node)
print(f" A -> {node} : {dist[node]:5.1f} chemin = {' -> '.join(path)}")
Distances depuis A :
A -> A : 0.0 chemin = A
A -> B : 4.0 chemin = A -> B
A -> C : 2.0 chemin = A -> C
A -> D : 9.0 chemin = A -> C -> E -> D
A -> E : 5.0 chemin = A -> C -> E
A -> F : 12.0 chemin = A -> C -> E -> F
Algorithme de Bellman-Ford#
Principe et détection de cycles négatifs#
Définition 71 (Algorithme de Bellman-Ford)
L”algorithme de Bellman-Ford calcule les plus courts chemins depuis une source unique dans un graphe pondéré pouvant contenir des poids négatifs, à condition qu’il n’y ait pas de cycle négatif accessible depuis la source.
L’algorithme effectue V-1 relaxations de toutes les arêtes (V = nombre de nœuds). Après k relaxations, dist[v] contient la longueur du plus court chemin utilisant au plus k arêtes. Après V-1 relaxations, si le graphe ne contient pas de cycle négatif, toutes les distances sont optimales.
Détection de cycle négatif : Si une V-ième relaxation modifie encore une distance, il existe un cycle négatif accessible depuis la source.
Complexité : O(V · E) en temps, O(V) en espace.
def bellman_ford(graph, source):
"""
Algorithme de Bellman-Ford.
Paramètres
----------
graph : Graph
Graphe orienté pondéré (poids éventuellement négatifs).
source : nœud
Retourne
-------
dist : dict ou None
dist[v] = distance minimale depuis source jusqu'à v.
None si un cycle négatif est détecté.
prev : dict
Prédécesseurs pour reconstruire les chemins.
"""
nodes = list(graph.nodes)
edges = graph.all_edges()
dist = {node: math.inf for node in nodes}
dist[source] = 0
prev = {node: None for node in nodes}
V = len(nodes)
# V-1 passes de relaxation
for iteration in range(V - 1):
updated = False
for u, v, w in edges:
if dist[u] != math.inf and dist[u] + w < dist[v]:
dist[v] = dist[u] + w
prev[v] = u
updated = True
if not updated:
break # Convergence prématurée
# Vème passe : détection de cycle négatif
for u, v, w in edges:
if dist[u] != math.inf and dist[u] + w < dist[v]:
return None, None # Cycle négatif détecté
return dist, prev
# Test sur graphe avec poids négatifs (mais sans cycle négatif)
g_neg = Graph(directed=True)
neg_edges = [
('A', 'B', -1), ('A', 'C', 4), ('B', 'C', 3),
('B', 'D', 2), ('B', 'E', 2), ('D', 'B', 1),
('D', 'C', 5), ('E', 'D', -3),
]
for u, v, w in neg_edges:
g_neg.add_edge(u, v, w)
dist_bf, prev_bf = bellman_ford(g_neg, 'A')
if dist_bf is not None:
print("Bellman-Ford (poids négatifs, pas de cycle négatif) :")
for node in sorted(dist_bf):
d = dist_bf[node]
print(f" A -> {node} : {d if d != math.inf else '∞'}")
else:
print("Cycle négatif détecté !")
# Test avec cycle négatif
g_neg_cycle = Graph(directed=True)
for u, v, w in [('A', 'B', 1), ('B', 'C', -3), ('C', 'A', 1)]:
g_neg_cycle.add_edge(u, v, w)
result, _ = bellman_ford(g_neg_cycle, 'A')
print(f"\nGraphe avec cycle négatif A->B->C->A (coût -1) :")
print(f" Résultat : {'cycle négatif détecté' if result is None else result}")
Bellman-Ford (poids négatifs, pas de cycle négatif) :
A -> A : 0
A -> B : -1
A -> C : 2
A -> D : -2
A -> E : 1
Graphe avec cycle négatif A->B->C->A (coût -1) :
Résultat : cycle négatif détecté
Algorithme de Kruskal et structure Union-Find#
L’arbre couvrant minimal#
Définition 72 (Arbre couvrant minimal)
Étant donné un graphe non orienté connexe pondéré G = (V, E, w), un arbre couvrant minimal (ACM, ou Minimum Spanning Tree, MST) est un sous-graphe T ⊆ E tel que :
T connecte tous les nœuds (T est un arbre couvrant).
Le poids total \(\sum_{e \in T} w(e)\) est minimal parmi tous les arbres couvrants.
Un graphe connexe à V nœuds possède un ACM avec exactement V-1 arêtes.
Définition 73 (Structure Union-Find (DSU))
La structure Union-Find (ou Disjoint Set Union, DSU) maintient une partition d’un ensemble en sous-ensembles disjoints et supporte deux opérations efficacement :
find(x): retourne le représentant (racine) de la composante contenant x.union(x, y): fusionne les composantes de x et de y.
Avec les deux optimisations — compression de chemin (path compression) dans find et union par rang (union by rank) dans union —, la complexité amortie de chaque opération est quasi-constante : O(α(n)), où α est la fonction inverse d’Ackermann, qui est inférieure à 5 pour toutes les valeurs pratiques de n.
class UnionFind:
"""
Structure Union-Find avec compression de chemin et union par rang.
Complexité amortie : O(α(n)) par opération.
"""
def __init__(self, elements):
self.parent = {x: x for x in elements}
self.rank = {x: 0 for x in elements}
self.n_components = len(elements)
def find(self, x):
"""Retourne la racine de x avec compression de chemin."""
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x]) # Compression
return self.parent[x]
def union(self, x, y):
"""
Fusionne les composantes de x et y.
Retourne True si une fusion a eu lieu (x et y étaient distincts).
"""
rx, ry = self.find(x), self.find(y)
if rx == ry:
return False # Déjà dans la même composante
# Union par rang : on attache le plus petit arbre sous le plus grand
if self.rank[rx] < self.rank[ry]:
rx, ry = ry, rx
self.parent[ry] = rx
if self.rank[rx] == self.rank[ry]:
self.rank[rx] += 1
self.n_components -= 1
return True
def connected(self, x, y):
return self.find(x) == self.find(y)
Algorithme de Kruskal#
Définition 74 (Algorithme de Kruskal)
L”algorithme de Kruskal construit un ACM par ajout glouton d’arêtes. Il trie les arêtes par poids croissant, puis les parcourt dans cet ordre : une arête est ajoutée à l’ACM si et seulement si elle ne crée pas de cycle (c’est-à-dire si ses deux extrémités appartiennent à des composantes connexes distinctes dans l’Union-Find courant).
Complexité : O(E log E) pour le tri des arêtes, O(E · α(V)) pour les opérations Union-Find. La complexité totale est dominée par le tri : O(E log E) = O(E log V).
Correction : repose sur la propriété de la coupe (cut property) : l’arête de poids minimal traversant une coupe quelconque appartient à tout ACM.
def kruskal(nodes, edges):
"""
Algorithme de Kruskal pour l'arbre couvrant minimal.
Paramètres
----------
nodes : iterable
Ensemble des nœuds du graphe.
edges : list of (u, v, weight)
Arêtes non orientées.
Retourne
-------
mst_edges : list of (u, v, weight)
Arêtes de l'ACM.
total_weight : float
Poids total de l'ACM.
"""
uf = UnionFind(nodes)
sorted_edges = sorted(edges, key=lambda e: e[2])
mst_edges = []
total_weight = 0
for u, v, w in sorted_edges:
if uf.union(u, v): # Pas de cycle
mst_edges.append((u, v, w))
total_weight += w
if len(mst_edges) == len(list(nodes)) - 1:
break # ACM complet
return mst_edges, total_weight
# Exemple
undirected_edges = [
('A', 'B', 4), ('A', 'H', 8), ('B', 'C', 8), ('B', 'H', 11),
('C', 'D', 7), ('C', 'F', 4), ('C', 'I', 2), ('D', 'E', 9),
('D', 'F', 14), ('E', 'F', 10), ('F', 'G', 2), ('G', 'H', 1),
('G', 'I', 6), ('H', 'I', 7),
]
nodes_mst = set('ABCDEFGHI')
mst, total = kruskal(nodes_mst, undirected_edges)
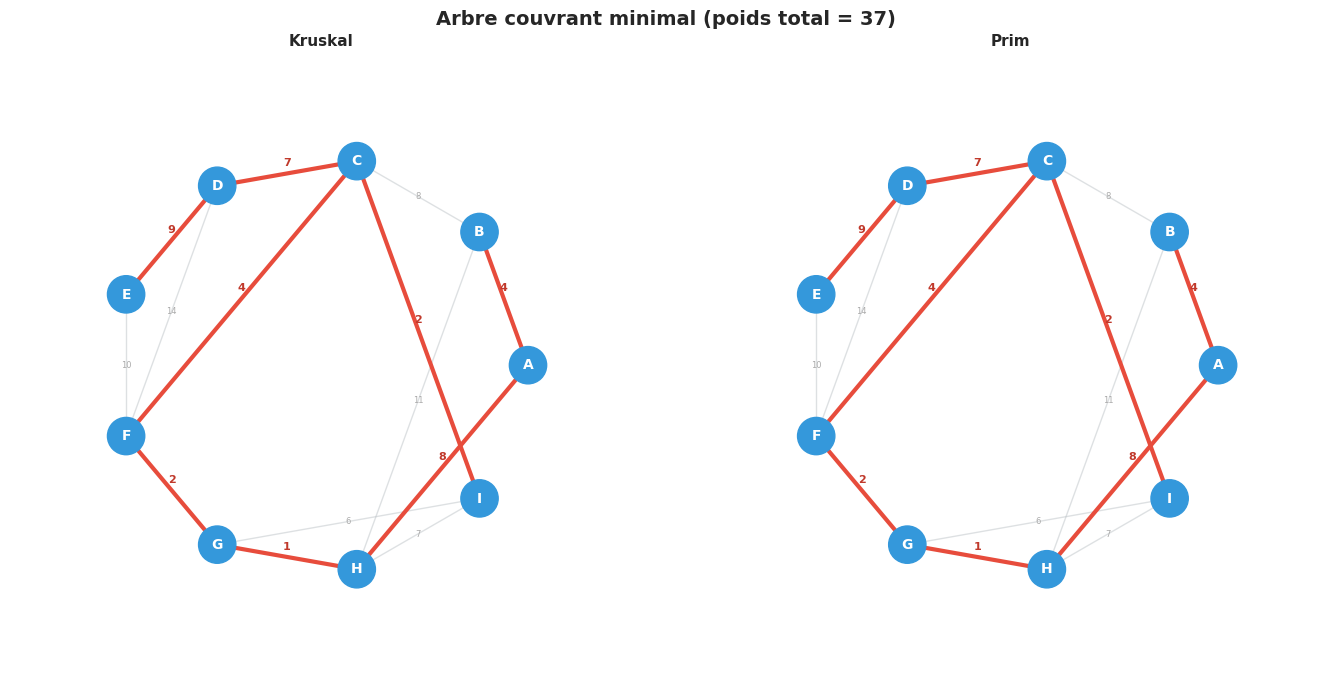
print("Arbre couvrant minimal (Kruskal) :")
for u, v, w in mst:
print(f" {u} -- {v} : {w}")
print(f"Poids total : {total}")
Arbre couvrant minimal (Kruskal) :
G -- H : 1
C -- I : 2
F -- G : 2
A -- B : 4
C -- F : 4
C -- D : 7
A -- H : 8
D -- E : 9
Poids total : 37
Algorithme de Prim#
Définition 75 (Algorithme de Prim)
L”algorithme de Prim construit un ACM en partant d’un nœud arbitraire et en ajoutant à chaque étape l’arête de poids minimal reliant l’arbre en construction à un nœud non encore inclus. Il utilise un tas min pour trouver efficacement cette arête.
Complexité : O((V + E) log V) avec un tas binaire, ou O(E + V log V) avec un tas de Fibonacci.
La différence avec Kruskal est que Prim étend un arbre connexe à chaque étape (approche locale), tandis que Kruskal fusionne des forêts (approche globale). Les deux produisent un ACM optimal.
def prim(nodes, adj):
"""
Algorithme de Prim avec tas min.
Paramètres
----------
nodes : iterable
Ensemble des nœuds.
adj : dict
adj[u] = liste de (v, poids) — liste d'adjacence du graphe non orienté.
Retourne
-------
mst_edges : list of (u, v, weight)
total_weight : float
"""
nodes = list(nodes)
if not nodes:
return [], 0
start = nodes[0]
in_mst = set()
# Tas min : (poids, nœud_destination, nœud_source)
heap = [(0, start, None)]
mst_edges = []
total_weight = 0
while heap and len(in_mst) < len(nodes):
w, u, parent = heapq.heappop(heap)
if u in in_mst:
continue
in_mst.add(u)
if parent is not None:
mst_edges.append((parent, u, w))
total_weight += w
for v, wv in adj.get(u, []):
if v not in in_mst:
heapq.heappush(heap, (wv, v, u))
return mst_edges, total_weight
# Construction de la liste d'adjacence pour le même graphe
adj_undirected = defaultdict(list)
for u, v, w in undirected_edges:
adj_undirected[u].append((v, w))
adj_undirected[v].append((u, w))
mst_prim, total_prim = prim(nodes_mst, adj_undirected)
print("Arbre couvrant minimal (Prim) :")
for u, v, w in sorted(mst_prim):
print(f" {u} -- {v} : {w}")
print(f"Poids total : {total_prim}")
print(f"\nKruskal = Prim ? {total == total_prim}")
Arbre couvrant minimal (Prim) :
A -- B : 4
C -- F : 4
C -- I : 2
D -- C : 7
D -- E : 9
F -- G : 2
G -- H : 1
H -- A : 8
Poids total : 37
Kruskal = Prim ? True
Tri topologique#
Définition et propriétés#
Définition 76 (Ordre topologique)
Un ordre topologique d’un graphe orienté acyclique (DAG, Directed Acyclic Graph) est une numérotation linéaire de ses nœuds telle que pour toute arête \((u, v)\), le nœud u apparaît avant le nœud v dans l’ordre. Autrement dit, toutes les dépendances d’un nœud apparaissent avant lui.
Un ordre topologique n’existe que pour les DAG : tout graphe orienté contenant un cycle ne peut pas être trié topologiquement, car le cycle crée une dépendance circulaire.
Remarque 32
Le tri topologique intervient dans de nombreuses applications pratiques :
Systèmes de build (Make, Gradle, Cargo) : déterminer l’ordre de compilation des modules selon leurs dépendances.
Planification de tâches : ordonner des tâches avec des contraintes de précédence.
Résolution de dépendances de paquets (apt, npm, pip).
Évaluation de formules dans un tableur : les cellules dépendantes sont calculées après les cellules dont elles dépendent.
Algorithme de Kahn (BFS)#
Définition 77 (Algorithme de Kahn)
L”algorithme de Kahn implémente le tri topologique par une approche BFS. Il repose sur le concept de degré entrant (in-degree) : le nombre d’arêtes pointant vers un nœud.
On calcule le degré entrant de chaque nœud.
On initialise une file avec tous les nœuds de degré entrant 0 (sans prédécesseur).
Tant que la file n’est pas vide, on extrait un nœud u, on l’ajoute à l’ordre, et pour chaque successeur v de u, on décrémente son degré entrant. Si le degré de v tombe à 0, on l’ajoute à la file.
Si l’ordre final contient V nœuds, le tri est réussi. Sinon, le graphe contient un cycle.
Complexité : O(V + E).
def topological_sort_kahn(graph):
"""
Tri topologique par l'algorithme de Kahn (BFS).
Paramètres
----------
graph : Graph
Graphe orienté.
Retourne
-------
order : list ou None
Ordre topologique des nœuds, ou None si le graphe contient un cycle.
"""
in_degree = {node: 0 for node in graph.nodes}
for u in graph.nodes:
for v, _ in graph.neighbors(u):
in_degree[v] += 1
# File des nœuds sans prédécesseur
queue = deque(node for node in graph.nodes if in_degree[node] == 0)
order = []
while queue:
u = queue.popleft()
order.append(u)
for v, _ in graph.neighbors(u):
in_degree[v] -= 1
if in_degree[v] == 0:
queue.append(v)
if len(order) == len(graph.nodes):
return order
else:
return None # Cycle détecté
def topological_sort_dfs(graph):
"""
Tri topologique par DFS postfixe.
Complexité : O(V + E).
"""
visited = set()
stack = []
in_stack = set()
has_cycle = [False]
def dfs(u):
if has_cycle[0]:
return
visited.add(u)
in_stack.add(u)
for v, _ in graph.neighbors(u):
if v not in visited:
dfs(v)
elif v in in_stack:
has_cycle[0] = True
return
in_stack.discard(u)
stack.append(u)
for node in graph.nodes:
if node not in visited:
dfs(node)
if has_cycle[0]:
return None
return stack[::-1]
# Exemple : dépendances de tâches
g_dag = Graph(directed=True)
task_edges = [
('vêtements', 'ceinture', 1), ('vêtements', 'chaussures', 1),
('ceinture', 'veste', 1), ('cravate', 'veste', 1),
('chemise', 'cravate', 1), ('chemise', 'ceinture', 1),
('chaussettes', 'chaussures', 1), ('pantalon', 'chaussures', 1),
('pantalon', 'ceinture', 1), ('montre', 'veste', 1),
]
for u, v, _ in task_edges:
g_dag.add_edge(u, v, 1)
order_kahn = topological_sort_kahn(g_dag)
order_dfs = topological_sort_dfs(g_dag)
print("Tri topologique (Kahn) :")
print(" " + " → ".join(order_kahn))
print("\nTri topologique (DFS) :")
print(" " + " → ".join(order_dfs))
# Test avec cycle
g_cycle = Graph(directed=True)
for u, v in [('A', 'B'), ('B', 'C'), ('C', 'A')]:
g_cycle.add_edge(u, v, 1)
print("\nGraphe avec cycle A->B->C->A :")
print(f" Kahn : {topological_sort_kahn(g_cycle)}")
print(f" DFS : {topological_sort_dfs(g_cycle)}")
Tri topologique (Kahn) :
pantalon → chemise → chaussettes → montre → vêtements → cravate → ceinture → chaussures → veste
Tri topologique (DFS) :
vêtements → montre → chaussettes → chemise → cravate → pantalon → chaussures → ceinture → veste
Graphe avec cycle A->B->C->A :
Kahn : None
DFS : None
Implémentation Rust#
use std::collections::{BinaryHeap, HashMap, VecDeque};
use std::cmp::Reverse;
/// Algorithme de Dijkstra en Rust.
/// Utilise BinaryHeap avec Reverse pour simuler un tas min.
pub fn dijkstra(
adj: &HashMap<usize, Vec<(usize, u64)>>,
source: usize,
n: usize,
) -> Vec<u64> {
let inf = u64::MAX / 2;
let mut dist = vec![inf; n];
dist[source] = 0;
// BinaryHeap est un tas max en Rust ; on utilise Reverse pour un tas min
let mut heap = BinaryHeap::new();
heap.push(Reverse((0u64, source)));
while let Some(Reverse((d, u))) = heap.pop() {
if d > dist[u] {
continue; // Entrée périmée
}
if let Some(neighbors) = adj.get(&u) {
for &(v, w) in neighbors {
let new_dist = dist[u].saturating_add(w);
if new_dist < dist[v] {
dist[v] = new_dist;
heap.push(Reverse((new_dist, v)));
}
}
}
}
dist
}
/// Structure Union-Find avec compression de chemin et union par rang.
pub struct UnionFind {
parent: Vec<usize>,
rank: Vec<u8>,
}
impl UnionFind {
pub fn new(n: usize) -> Self {
Self {
parent: (0..n).collect(),
rank: vec![0; n],
}
}
pub fn find(&mut self, x: usize) -> usize {
if self.parent[x] != x {
self.parent[x] = self.find(self.parent[x]); // Compression
}
self.parent[x]
}
pub fn union(&mut self, x: usize, y: usize) -> bool {
let rx = self.find(x);
let ry = self.find(y);
if rx == ry {
return false;
}
match self.rank[rx].cmp(&self.rank[ry]) {
std::cmp::Ordering::Less => self.parent[rx] = ry,
std::cmp::Ordering::Greater => self.parent[ry] = rx,
std::cmp::Ordering::Equal => {
self.parent[ry] = rx;
self.rank[rx] += 1;
}
}
true
}
}
/// Algorithme de Kruskal.
pub fn kruskal(n: usize, mut edges: Vec<(usize, usize, u64)>) -> (Vec<(usize, usize, u64)>, u64) {
edges.sort_by_key(|&(_, _, w)| w);
let mut uf = UnionFind::new(n);
let mut mst = Vec::new();
let mut total_weight = 0u64;
for (u, v, w) in edges {
if uf.union(u, v) {
mst.push((u, v, w));
total_weight += w;
if mst.len() == n - 1 {
break;
}
}
}
(mst, total_weight)
}
/// Tri topologique par l'algorithme de Kahn.
pub fn topological_sort(adj: &[Vec<usize>], n: usize) -> Option<Vec<usize>> {
let mut in_degree = vec![0usize; n];
for u in 0..n {
for &v in &adj[u] {
in_degree[v] += 1;
}
}
let mut queue: VecDeque<usize> = (0..n).filter(|&i| in_degree[i] == 0).collect();
let mut order = Vec::new();
while let Some(u) = queue.pop_front() {
order.push(u);
for &v in &adj[u] {
in_degree[v] -= 1;
if in_degree[v] == 0 {
queue.push_back(v);
}
}
}
if order.len() == n { Some(order) } else { None }
}
Résumé#
Ce chapitre a couvert cinq algorithmes fondamentaux sur les graphes :
Dijkstra résout le plus court chemin depuis une source dans un graphe à poids non négatifs. Il utilise un tas min pour extraire le nœud de distance minimale à chaque itération, avec une complexité de O((V + E) log V). Son invariant repose sur la non-négativité des poids.
Bellman-Ford est plus général : il tolère les poids négatifs et détecte les cycles négatifs. Sa complexité O(V · E) le rend plus lent que Dijkstra, mais il est irremplaçable lorsque des arêtes négatives sont présentes.
Kruskal construit l’arbre couvrant minimal de façon gloutonne en triant les arêtes et en les ajoutant sans créer de cycle. La structure Union-Find avec compression de chemin et union par rang est sa brique essentielle, offrant des opérations en temps quasi-constant O(α(V)).
Prim construit le même arbre couvrant minimal mais en étendant un arbre connexe à chaque étape, avec une efficacité comparable à Dijkstra grâce au tas min.
Le tri topologique ordonne les nœuds d’un DAG de sorte que toutes les dépendances précèdent leurs dépendants. L’algorithme de Kahn (BFS) et le DFS postfixe sont les deux approches classiques, toutes deux en O(V + E).
Le chapitre suivant aborde le paradigme diviser pour régner : nous formaliserons le master theorem, qui permet d’analyser la complexité de n’importe quel algorithme récursif divisant le problème en sous-problèmes de taille proportionnelle, et nous étudierons des applications telles que la multiplication de Karatsuba et l’algorithme quickselect.